データ統一のための顧客カラムの統合
統合プロセスのこのステップでは、統合プロファイル テーブル内でマージする列を選択し、除外します。 たとえば、3 つのテーブルに電子メール データがある場合、3 つの個別の電子メール列すべてを保持するか、統合プロファイルの単一の電子メール列にマージすることができます。 Dynamics 365 Customer Insights - Data は自動的にいくつかの列を結合します。 個々の顧客向けに、関連するプロファイルをクラスターにグループ化できます。
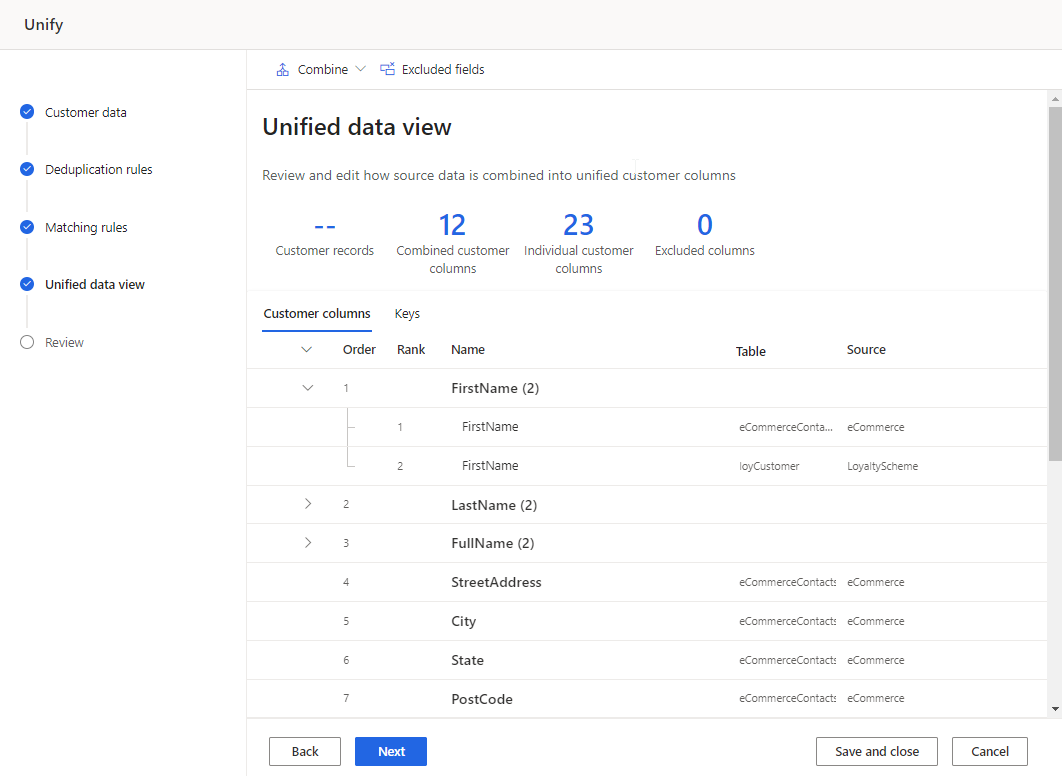
顧客列の見直しと更新
テーブルの 顧客列 タブで統一される列のリストを確認します。 該当する場合は変更を加えます。
オプションで、顧客 ID 構成の生成。
オプションで、プロファイルを世帯またはクラスターにグループ化 します。
マージされたフィールドを編集する
マージされた列を選択し、編集 を選択します。 列の結合ペインが表示されます。
フィールドの結合、あるいはマージする方法を、次の 3 つのオプションのいずれかから指定します:
重要性: 参加フィールドに指定された重要度ランクに基づいて勝者の値を識別します。 既定のマージ オプションです。 上/下に移動を選択し、重要度ランキングを設定します。
注意
システムは最初の非 null 値を使用します。 たとえば、テーブル A、B、C がこの順序でランク付けされている場合、A.Name と B.Name が null の場合は C.Name の値を使用します。
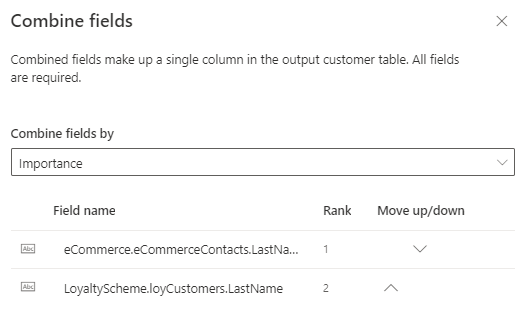
最新: 最新性に基づいて、勝者の値を特定します。 最新性の定義では、マージ フィールド スコープのすべての参加テーブルに日付または数値フィールドが必要です。
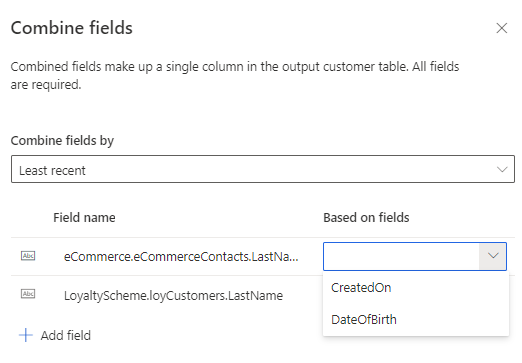
最も古い: 古さに基づいて、勝者の値を特定します。 最新性の定義では、マージ フィールド スコープのすべての参加テーブルに日付または数値フィールドが必要です。
マージ プロセスに参加するフィールドをさらに追加できます。
マージされた列の名前を変更することができます。
完了を選択して変更を適用します。
フィールド名の変更
マージされたフィールドまたは個別のフィールドの表示名を変更します。 出力テーブルの名前は変更できません。
列を選択し、名前の変更 を選択します。
新しい表示名を入力します。
完了を選択します。
マージされたフィールドの分離
マージされたフィールドを分離するには、テーブルの列を探します。 分離されたフィールドは、統合された顧客プロファイルの個別のデータ ポイントとして表示されます。
マージされた列を選択し、フィールドの分割 を選択します。
分離を確認します。
フィールドを除外する
統合された顧客プロファイルからマージされたフィールドまたは個別のフィールドを除外します。 フィールドがセグメントなどの他のプロセスで使用されている場合は、これらのプロセスから削除します。 次に、それをを顧客プロファイルから除外します。
マージされた列を選択し、除外 を選択します。
除外を確認します。
すべての除外フィールドのリストを表示するには、除外列 を選択します。 すべての除外フィールドのリストを表示するには、除外列を選択します。
フィールドの順序の変更
一部のテーブルには、他よりも多くの詳細が含まれています。 テーブルにフィールドに関する最新データが含まれている場合、値をマージするときに他のテーブルより優先できます。
フィールドを選択します。
上/下に移動を選択して順序を設定するか、目的の位置にドラッグ アンド ドロップします。
フィールドを手動で結合
分離されたフィールドを結合して、マージされた列を作成します。
結合>フィールドを選択します。 列の結合ペインが表示されます。
フィールドの結合方法 ドロップダウンでマージにおける勝者のポリシーを指定します。
フィールドの追加を選択して、さらにフィールドを組み合わせます。
名前 と 出力フィールド名 を指定します。
完了 を選択して変更を適用します。
フィールドのグループの結合
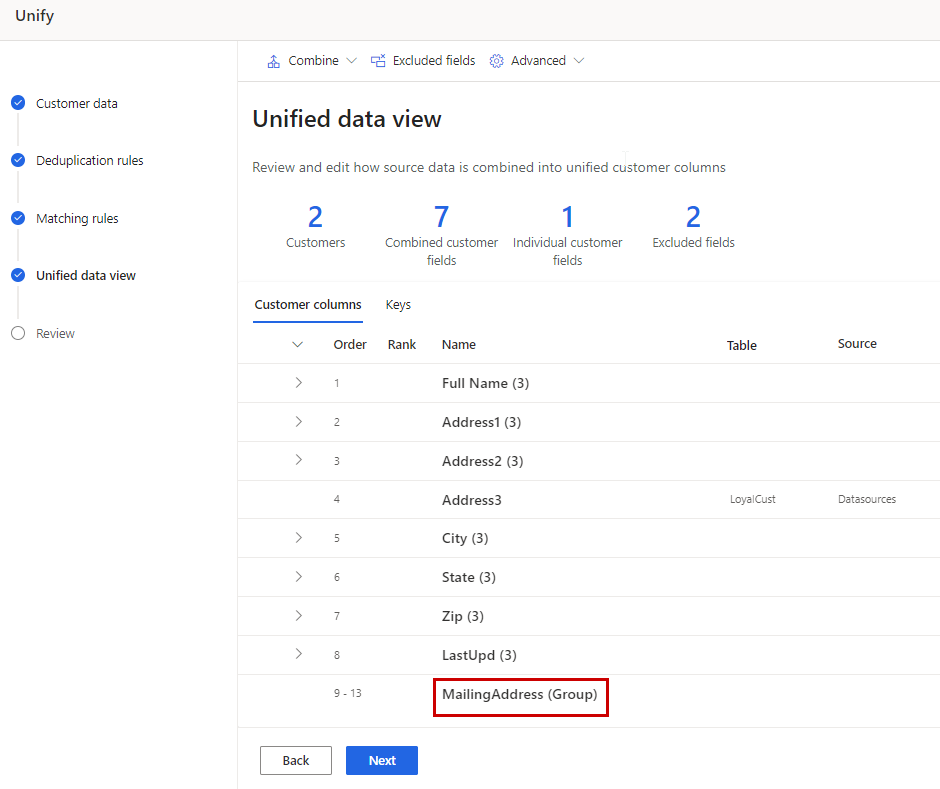
フィールドのグループを結合する場合、Customer Insights - Data はそのグループを 1 つの単位として扱い、結合ポリシーに基づいて勝者のレコードを選択します。 フィールドをグループにまとめずにマージする場合、システムは マッチング ルール ステップで設定したテーブル オーダーの順位に基づいて、各フィールドの勝者レコードを選択します。 フィールドに null 値がある場合、Customer Insights - Data は値が見つかるまで他のデータ ソースを調べ続けます。 これにより情報が不必要に混ざり合う場合や、統合ポリシーを設定したい場合は、フィールドのグループを結合します。
例
Monica Thomson は、ロイヤリティ、オンライン、POS の 3 つのデータ ソースを照合します。 Monica の郵送先住所フィールドを結合しない場合、各フィールドの勝者レコードは、null 値である Addr2を除いて、最初にランク付けされたデータ ソース (ロイヤルティ) に基づきます。 Addr2 の勝者レコードは Suite 950 であるため、住所フィールドの組み合わせが正しくありません (200 Cedar Springs Road, Suite 950, Dallas, TX 75255)。 データの整合性を確保するには、アドレス フィールドを 1 つのグループに結合します。
Table1 - ロイヤルティ
| Full_Name | 住所 1 | 住所 2 | 都市 | 状態 | 郵便番号 |
|---|---|---|---|---|---|
| Monica Thomson | 200 Cedar Springs Road | ダラス | TX | 75255 |
Table2 - オンライン
| 件名 | 住所 1 | 住所 2 | 都市 | 状態 | 郵便番号 |
|---|---|---|---|---|---|
| Monica Thomson | 5000 15th Street | Suite 950 | 東京 | WA | 98052 |
Table3 - POS
| Full_Name | Add1 | Add2 | 都市 | 状態 | 郵便番号 |
|---|---|---|---|---|---|
| Monica Thomson | 100 Main Street | Suite 100 | 世田谷区 | WA | 98121 |
フィールド グループの作成 (プレビュー)
結合>フィールドのグループを選択します。
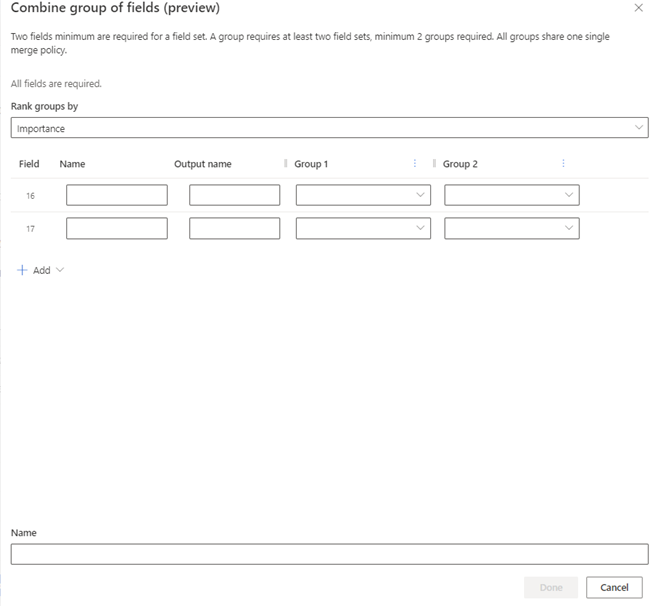
グループの順位付け ドロップダウンで、勝者として選択するフィールドのグループを指定します。 グループを構成するすべてのフィールドに同じ統合ポリシーが使用されます。
- 重要度: グループ 1 から順にグループを見て、勝者グループを特定します。 すべてのフィールドが null の場合、次のグループが考慮されます。 重要度は既定値です。
- 最新: 選択したグループ内のフィールドを参照して最新性を示すことにより、勝者グループを特定します。 フィールドは、最大から最小にランク付けできる限り、日付、時刻、または数値にすることができます。
- 最も古い: 選択したグループ内のフィールドを参照して最新性を示すことにより、勝者グループを特定します。 フィールドは、最小から最大にランク付けできる限り、日付、時刻、または数値にすることができます。
結合したグループに 3 つ以上のフィールドを追加するには、追加>フィールド を選択します。 最大 10 個のフィールド追加します。
結合したグループに 3 つ以上のデータ ソースを追加するには、追加>グループ を選択します。 最大 15 個のデータ ソースを追加します。
結合する各フィールドに次の情報を入力します。
- 名前: グループ化するフィールドの一意の名前。 データ ソースの名前は使用できません。
- 出力名: 自動的に入力され、顧客プロファイルに表示されます。
- グループ 1: 名前 に対応する最初の データ ソースのフィールド。 データ ソースのランキングは、システムが重要度によってレコードを識別してマージする順序を示します。
Note
グループのドロップダウンでは、フィールドのリストがデータ ソースで分類されています。
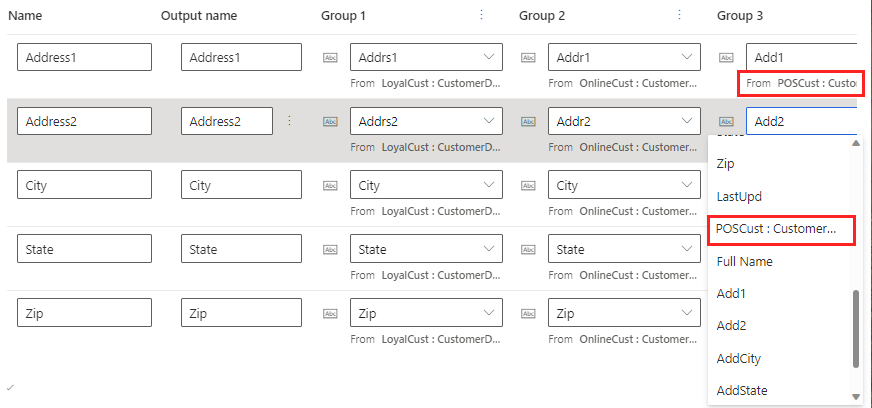
- グループ 2: 名前 に対応する次のデータ ソースのフィールド。 含めるデータ ソースごとに繰り返します。
郵送先住所など、組み合わせたフィールドのグループに 名前 を付けます。 この名前は 統合データ ビュー ステップに表示されますが、顧客プロファイルには表示されません。
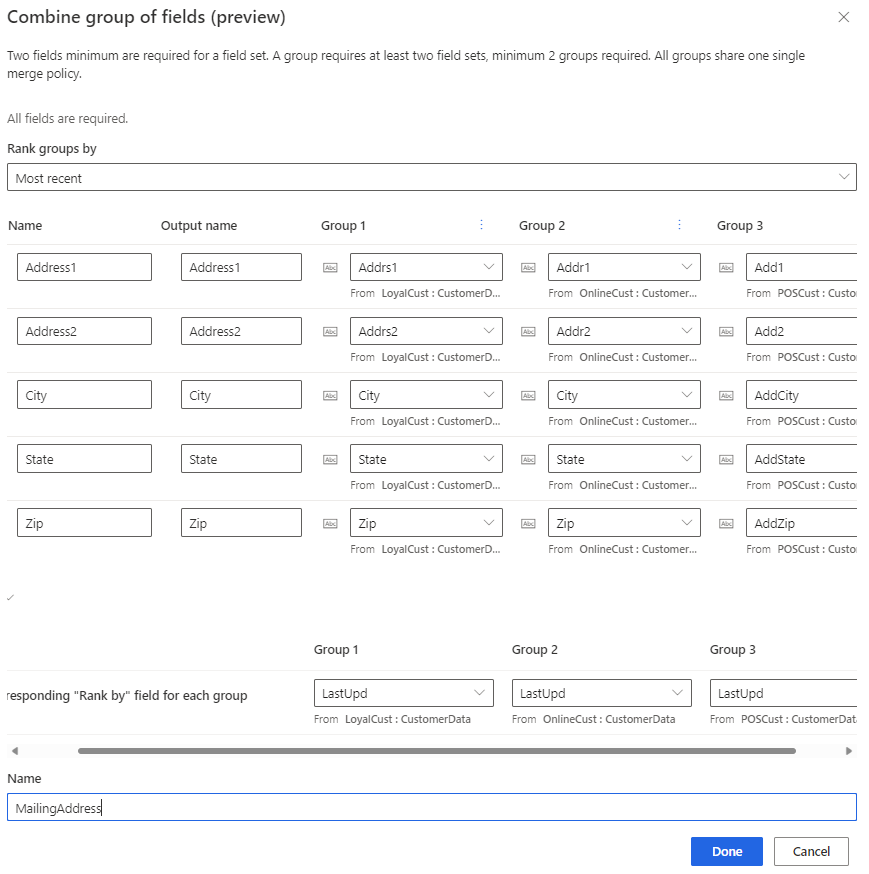
完了 を選択して変更を適用します。 結合されたグループの名前は、統合データ表示 ページに表示されますが、顧客プロファイルには表示されません。
プロファイルを世帯またはクラスターにグループ化します
個々の顧客の場合、関連するプロファイルをクラスターにグループ化するルールを定義できます。 現在利用可能なクラスターには、家庭用クラスターとカスタム クラスターの 2 種類があります。 Customer テーブルにセマンティック フィールド Person.LastName と Location.Address が含まれる場合、システムは事前定義されたルールを持つ世帯を自動的に選択します。 一致ルールのように、独自のルールと条件を使用してクラスターを作成することもできます。
共有グループ内のユーザー (姓 とアドレスが同じ) には、共通のクラスター ID がプロファイルに追加されます。 統合後、クラスター ID で検索すると、同じ世帯の他のメンバーを簡単に見つけることができます。 クラスターはセグメントと同じではありません。 クラスター ID は、少数の人々の間の関係を識別します。 セグメントは、多数の人々をグループ化します。 特定の顧客は、さまざまなセグメントに属することができます。
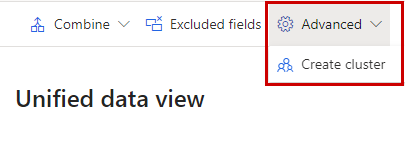
詳細>クラスターを作成を選択します。
世帯またはカスタム クラスターを選択します。 セマンティック フィールド Person.LastName と Location.Address が 顧客 テーブルに存在する場合、世帯が自動的に選択されます。
クラスターの名前を入力して、完了を選択します。
クラスター タブを選択して、作成したクラスターを検索します。
クラスターを定義するためのルールと条件を指定します。
完了 を選択します。 統合プロセスが完了すると、クラスターが作成されます。 クラスター識別子は、新しいフィールドとして顧客 テーブルに追加されます。
顧客 ID の生成を構成する
CustomerId フィールドは、統合された顧客プロファイルごとに自動的に生成される一意の GUID 値です。 この既定のロジックを使用することをお勧めします。 ただし、まれに、CustomerId を生成するための入力として使用するフィールドを指定できることがあります。
キー タブを選択します。
CustomerId 行にカーソルを合わせ、構成を選択します。
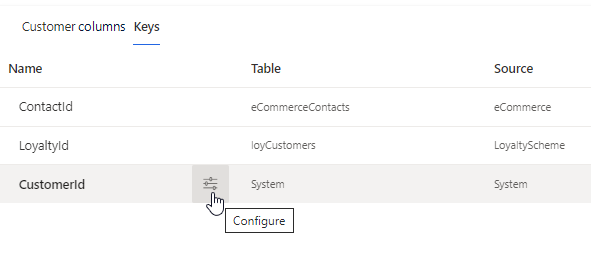
安定した一意の顧客 ID を構成するフィールドを 5 つまで選択します。 構成と一致しないレコードは、代わりにシステムが構成した ID を使用します。
政府発行の ID など、変更が予想されない列、または変更された場合に新しい CustomerId が適切な列のみを含めます。 電話番号、メールアドレス、住所など、変更される可能性のある列は避けてください。
完了を選択します。
CustomerId 生成への入力ごとに、最初の nul l以外の TableName + フィールド値が使用されます。 テーブルは、マッチング ルール 統合ステップで定義されたテーブル順序で null 以外の値がチェックされます。 ソース テーブルまたは入力フィールドの値が変更されると、結果の CustomerId も変更されます。