Azure Data Lake の変更データ
ノート
この 12 か月間、ギャップを埋め、ユーザー コミュニティのメンバが強調表示した新しい機能を追加しました。 Power Apps に搭載された Dataverse サービスの Synapse Link は、財務と運用アプリの データレイクへのエクスポート機能 の後継機能が一般的に利用可能になり、準備が整いました。 Synapse Link は、すべての Microsoft Dynamics 365 アプリのデータを 1 つのエクスペリエンスで操作できます。
一日も早く、Synapse Link が提供するパフォーマンス、柔軟性、およびユーザー エクスペリエンスの向上のメリットを得る必要があります。 そのため、2023 年 10 月 15 日をもって データレイクへのエクスポート 機能を廃止することを発表しました。 すでに データ レイクへのエクスポート機能を使用している場合は、2024 年 11 月 1 日まで引き続き使用できます。 データレイクへのエクスポート 機能を初めてご利用になる場合、または今後数カ月以内にこの機能を採用する予定の場合は、代わりに Synapse Link を使用することをお勧めします。
この移行が困難に困難が伴い可能性は理解していますが、よりスムーズな経験を提供し、ガイダンスを提供したいと考えています。 開始するには、 Synapse Link 移行ガイド を参照してください。 コミュニティーの声に耳を傾け、よりスムーズな移行ができるよう、複数の機能に取り組んでいます。 移行プロセスに関するこの他の改善点については、新機能をオンライン化する際にお知らせします。 連絡を取り合う場合は、https://aka.ms/SynapseLinkforDynamics のコミュニティに参加してください。
ほぼリアルタイムのデータ変更を有効にするオプションを選択した場合、データは Data Lake でほぼリアルタイムで挿入、更新、および削除されます。 データが財務と運用環境内で変更されると、数分以内に Data Lake 内のデータが更新されます。 データの変更は、別の変更フィード フォルダーでも取得できます。
Data Lake のデータ変更により、財務と運用アプリのデータ変更に反応するほぼリアルタイムのデータ パイプラインを構築できます。 変更フィード フォルダーには、財務と運用アプリでデータを変更するごとに格納されます。 このフォルダーは、Data Lake へのエクスポート機能により自動的に作成され、管理されます。
Data Lake のデータを変更する必要があるのはなぜですか?
Data Lake のデータは、レポートの目的でよく使用されます。 Data Lake のテーブル データを使用してレポートを作成できますが、データの追加コピーを作成してレポートを改善することもできます。 たとえば、パワーユーザーを有効にするように設計されたデータ マートがあるとします。 このデータ マートでは、簡略化された、多くの場合集約されたファクト テーブルと分析コード テーブルを使用している可能性があります。
Data Lake のテーブル データが更新される場合は、対応するファクト テーブルおよび分析コード テーブルを更新した Data Lake に保持する必要があります。 それ以外の場合、レポートには最新のデータが反映されません。
ファクト テーブルと分析コード テーブルを更新する最も簡単な方法は、テーブルを使用して完全なコピーを定期的に作成することです。 ただし、この方法は非効率的です。 テーブルが大きい場合 (たとえば、数千万や数千万の行がある場合) は、完全なコピーを作成してファクト テーブルを更新するプロセスには数時間かかり、大量の計算リソースが消費される場合があります。 したがって、ユーザーが時間内にレポートを作成していない場合があります (つまり、レポートの最新データを表示するために数時間待たなければならない場合があります)。 データが再処理されるたびに計算リソースが消費されるため、消費したサービスからより大きな請求書を受け取る場合があります。
ファクト テーブルと分析コード テーブルの差分更新は、両方の問題 (時間の消費と計算リソースの消費) に対する答えを提供します。 差分更新では、変更されたレコードのみをソース テーブルから選択し、対応するファクト テーブルおよび分析コード テーブルで更新します。
差分更新は、Azure Data Factory などの多くのデータ変換ツール の標準機能です。 ただし、差分更新機能を使用するには、ソース テーブルで変更されたレコードを識別する必要があります。
変更フィード フォルダーには、Data Lake内のテーブル データ変更の履歴が表示されます。 この履歴は、差分更新を使用するデータ パイプラインに使用できます。
変更フィード フォルダーの詳細
変更フィード機能は、変更データ キャプチャ (CDC) という名前の SQL Server 機能に依存します。 CDC は、財務と運用アプリの背後にあるデータ ストアである SQL Server データベースの変更データをキャプチャするネイティブな方法です。 変更フィード機能を使用すると、Data Lake の CDC 変更ログにアクセスできます。
次の図は、財務と運用アプリでの変更フィードの機能を示しています。
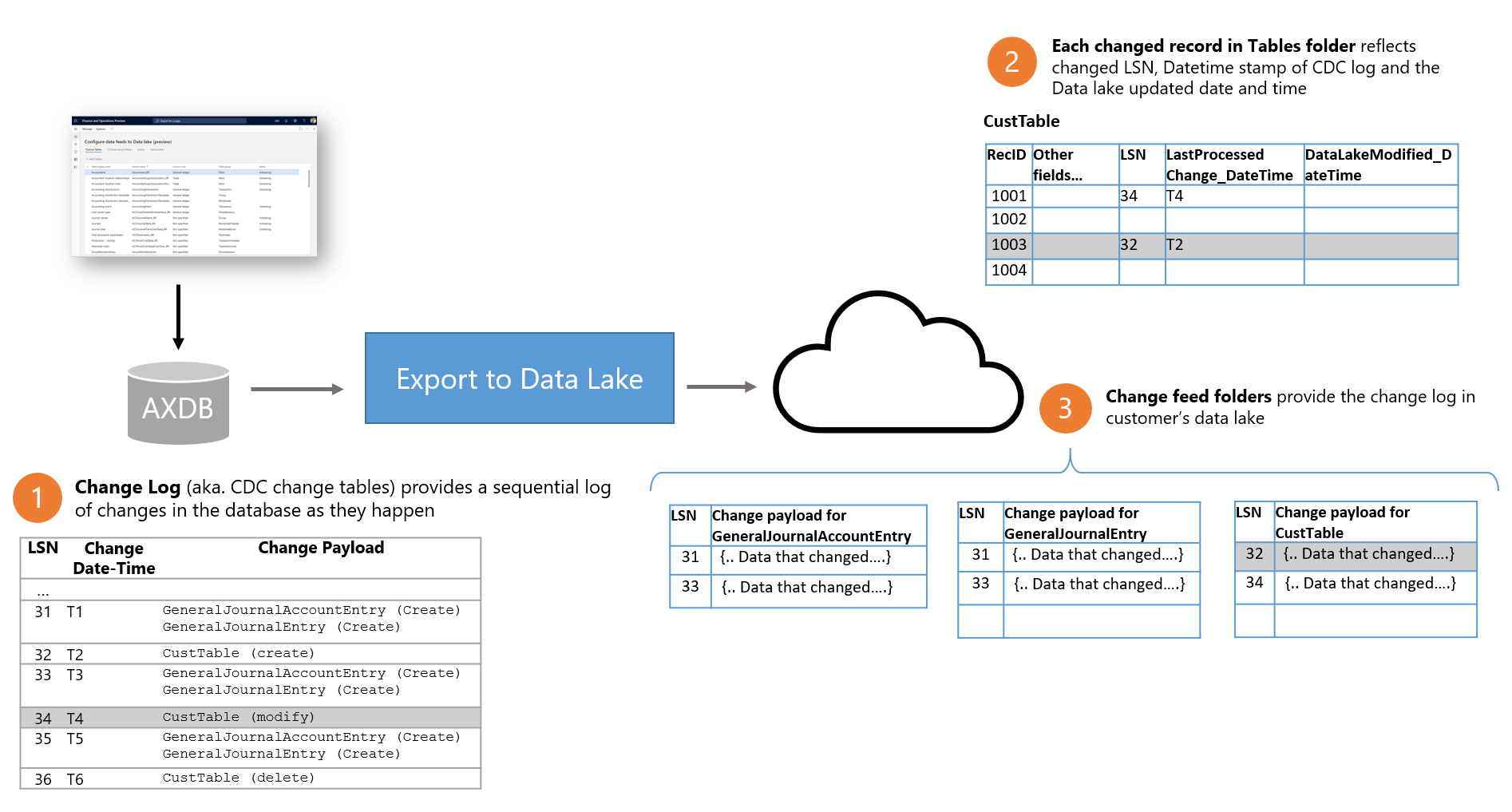
- 財務と運用アプリでデータが変更されるたびに、基になるデータベース (AXDB) が更新されます。 CDC 機能は、更新がデータベースに反映されることを保証します。 CDC は、論理シーケンス番号 (LSN 値)、日付/タイム スタンプ (日時変更 値)、および変更されたデータを識別するペイロード変更値とともに、ログ (変更ログ) に変更をキャプチャします。
- Data Lake へのエクスポート マイクロサービスはデータベース内の変更をキャプチャし、変更ログを顧客の Data Lake に書き込みます。 Data Lake の変更フィード フォルダーはテーブルごとに整理されます。 各フォルダーには、特定のテーブルの変更ログが含まれます。
- さらに、テーブル フォルダー、変更された各行にはいくつかの新しいフィールドも含まれます。 各行には、対応する変更レコードの LSN 値と日時変更値が含まれています。 テーブル フォルダーの LSN フィールドと日時変更フィールドを使用して、行が変更されたかどうかを識別できますが、最新の変更のみが含まれています。 同じ行が複数回変更された場合は、最新の変更だけがテーブル フォルダーに表示されます。
- 変更は、データベースでコミットされるのと同じ順序で (つまり、LSN) 変更フィード フォルダーに書き込まれます。 変更フィード ファイルは Data Lake にバッチに書き込まれるので、そのサイズは読み取り用に最適化されます。 変更フィード ファイルが書き込まれた後は、更新されません。
Data Lake 内の変更フィード フォルダを検索
ほぼリアルタイムのデータ変更を有効にする機能を有効にした場合、テーブルを Data Lake に追加すると、変更フィードが自動的に追加されます。
Data Lake にテーブルを追加する場合、または非アクティブ化されたテーブルをアクティブ化すると、システムは Data Lake 内のデータの初期コピーを作成します。 この時点で、テーブルの状態は初期化と表示されます。 初期コピーが完了すると、状態が実行中に変更されます。 テーブルの実行中状態の場合は、財務と運用データベース内の変更が Data Lake に反映され、変更フィードが追加されます。 変更フィード フォルダーは、初期化後、テーブルに変更が加えられていない場合、空である場合があります。
変更フォルダーにアクセスするには、Azure ポータルを開き、財務と運用環境に関連付けられているストレージ アカウントを見つけて選択します。 Data Lake 構造内の変更フィード フォルダーが表示されます。 次の図は、例を示します。
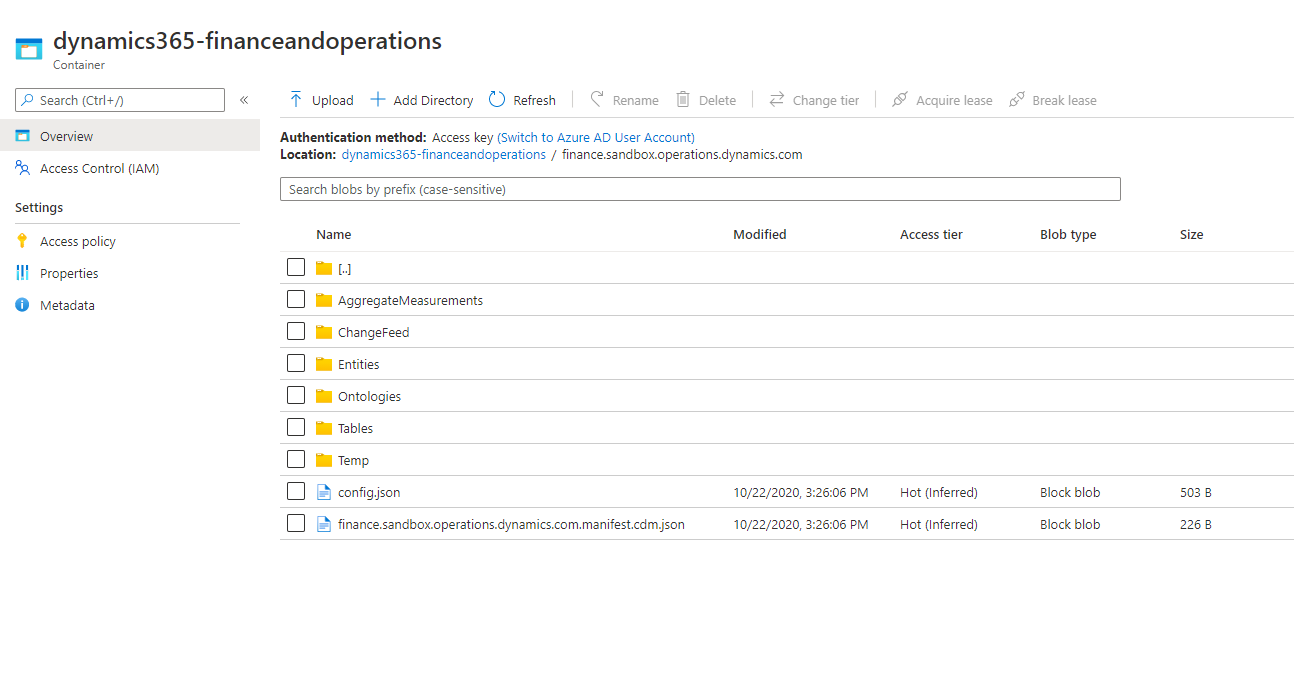
変更フィード フォルダーを開くと、Data Lake に追加したテーブルに対応するフォルダーが表示されます。 変更フォルダー データを説明する CDM メタデータ ファイルも表示されます。 次の図は、例を示します。
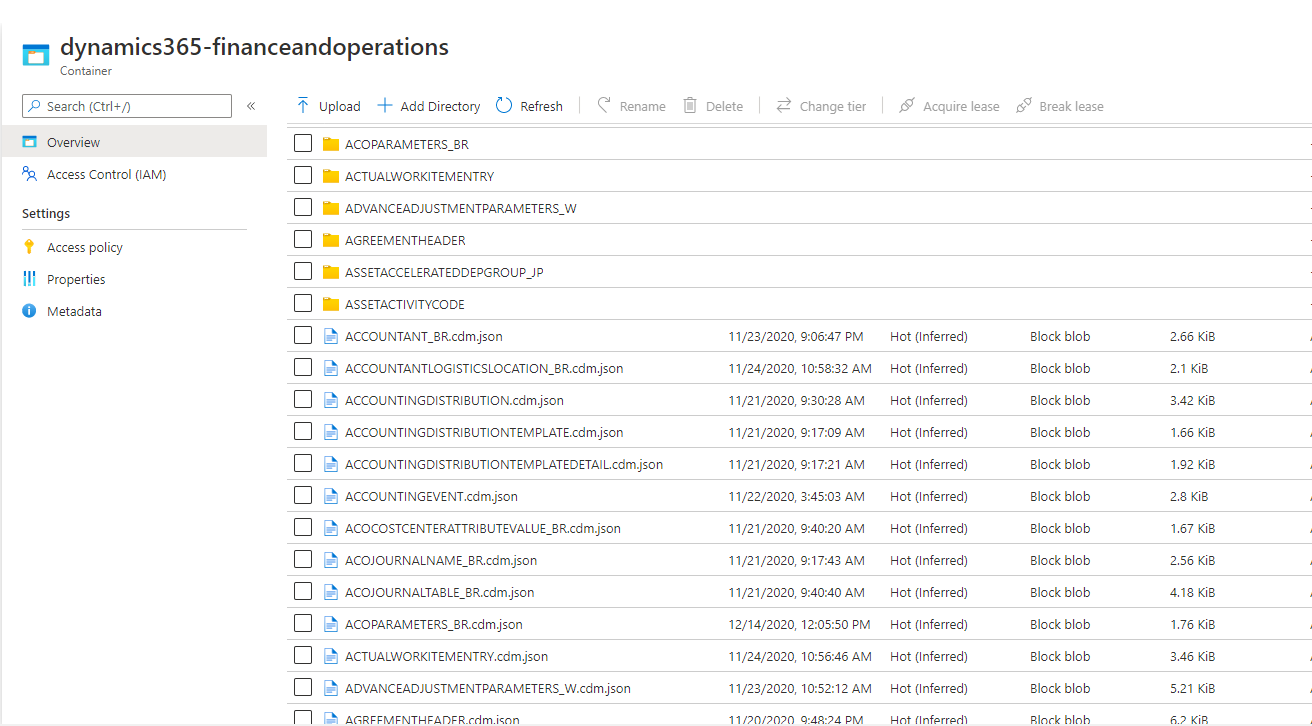
CDM メタデータ ファイルは、フォルダーに含まれる変更フィード データの構造を記述します。 CDM メタデータ ファイルや Data Factory などのデータ変換ツールを使用すると、生のカンマ区切り値 (CSV) ファイルを読み取ることなく、変更フィード データを読み取ることができます。 メタデータを調べるには、メタデータ ファイルを選択し、テキスト エディターで開きます。
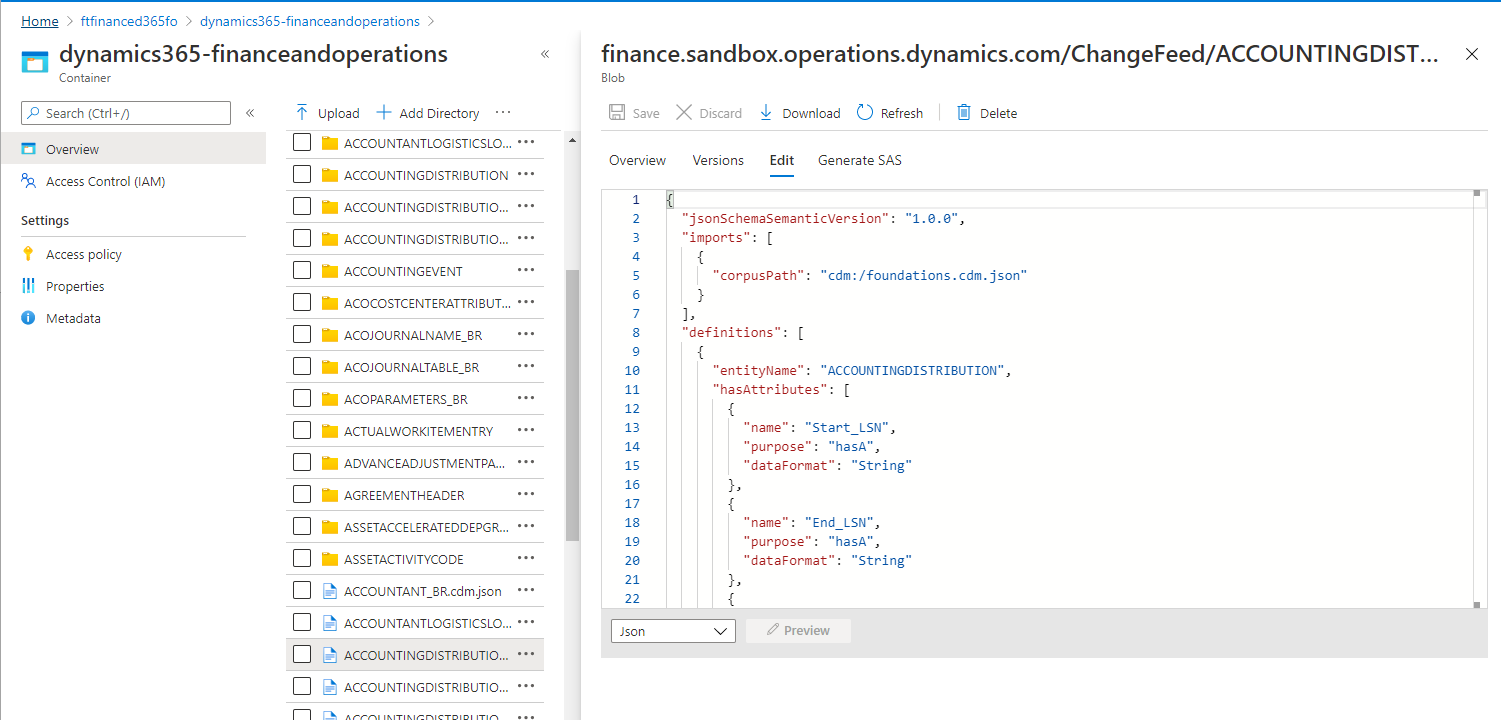
メタデータ定義から通知されるため、変更フィード フォルダーには、追加のフィールドとともに CDC 変更ログの詳細が含まれています。 次の図と表は、変更フォルダーの変更の形式に関する詳細を示しています。

| フィールド名 | コンテンツ |
|---|---|
| Start_LSN | このフィールドは、財務と運用データベースのソース データを変更したトランザクションの LSN を識別します。 注記:Start_LSN 値は、CSV ファイルでは二重引用符で囲まれていません。 これは、SQL Server データベースに示されている 16 進値です。 サンプル値: 0X00011E9F00000FB00001. |
| End_LSN | このフィールドは使用されません。 |
| DML_Action | 各変更は個別のレコードとして格納されます。 DML_Action フィールドは、レコードに対する変更を識別します。
注記: システムは BEFORE_UPDATE レコードを変更フィードに追加されません。 |
| Seq_Val | このフィールドは、ソースのデータを変更した LSN 内のシーケンス番号を識別します。 トランザクションは財務と運用データベース内の複数のテーブルを更新する可能性があるため、Seq_Val フィールドは CDC がテーブルに割り当てたシーケンス番号を示します。 変更レコードは、トランザクションのテーブルに対して行われたすべての変更に対して追加されます。 同じレコードが 1 つのトランザクションで複数回更新された場合、個別のシーケンス番号を持つ複数の変更レコードが見つかります。 将来、極端な場合 (たとえば、1 つのトランザクションで同じレコードに数千の更新がある場合)、システムは最新の更新レコードを格納する可能性があります。 |
| Update_Mask | 変更されたフィールドを識別するビットマップ。 このビットマップは、変更追跡の更新マスクに似ています。 ただし、ビットマップを調べることで、変更したフィールドを識別できます。 |
| フィールドおよび値の一覧 | 残りの列は、値とともに、テーブルに存在するフィールドのリストを提供します。 トランザクションの一部として変更されたフィールドを識別するには、更新マスクを使用する必要があります。 |
| LastProcessedChange_DateTime | このフィールドは、財務と運用データベースの CDC 日時変更フィールドの値を提供します。 日付/時刻は、ISO 8601 あたりの協定世界時 (UTC) で表されます。 サンプル値: 「2020-08-24T05:26:03.8622647Z」. この値は二重引用符で囲まれていることに注意してください。 2 番目の値の後の既定の 7 桁の精度と、UTC を表す Z が含まれます。 |
| DataLakeModified_DateTime | このフィールドは、Data Lake への書き込みの日時を提供します。 日付/時刻は、ISO 8601 あたりの UTC で表されます。 サンプル値: 「2020-08-24T05:26:03.8622647Z」. この値は二重引用符で囲まれていることに注意してください。 2 番目の値の後の既定の 7 桁の精度と、UTC を表す Z が含まれます。 |
変更フィードを使用する場合のベスト プラクティス
変更フィードは、財務と運用アプリの Data Lake へのエクスポート機能によって有効になる強力な機能です。 このセクションでは、変更フィードを使用するときに従う必要のあるいくつかのベスト プラクティスについて説明します。
ほぼリアルタイムのデータ マートの更新
データ ウェアハウスまたはデータ マートをほぼリアルタイムで更新する必要がある場合 (つまり、財務と運用アプリでデータが変更されてから数分以内に更新する必要がある場合)、変更フィードを使用する必要があります。
ただし、理解する必要のある重要な概念がいくつかあります。
- 変更レコードは、サイズが約 4 メガバイト (MB) または 8 MB のファイルにグループ化されます。 Microsoft は、ファイルが Synapse SQL Serverless によってクエリされるときに最適なクエリ応答時間を提供するように、ファイル サイズを最適化しました。 最適化されたファイル サイズ (およびバッチ書き込み) により、Data Lake の更新時に発生する可能性のある Azure の料金も削減されます。
- 変更レコードは追加されるだけです。 変更フィード フォルダー内のファイルは更新されません。 各変更レコードには変更の LSN 番号と日時が含まれますが、CSV ファイルの日時スタンプを使用して変更を識別することもできます。
- 財務と運用でテーブルを再有効化する場合、変更フィード フォルダーがクリアされ、システムは次に使用可能な変更から変更フィードを開始します。 この動作によって、変更はテーブル フォルダーと一貫しています。 テーブルが再有効化された場合、下流のデータ パイプラインに対する完全な更新をトリガーする必要があります。
- 下流のジョブは、定期的に (10 分ごとなど) 調整したり、新しい変更フィード ファイルがフォルダーに追加されるときにトリガーすることができます。
- いずれの場合でも、下流のデータ パイプラインには、最後に処理されたマーカー (透かしとも呼ばれる) があります。 可能な限り、透かしとしてレコードの LSN フィールドを使用する必要があります。 ただし、ファイルの日時スタンプを透かしとして使用することもできます。 LSN に依存することにより、財務と運用データベースで確定されたのと同じ順序で変更を確実に消費することができます。
下流のパイプラインをビルドする方法を示す例については、Synapse データ インジェスト テンプレートを参照してください。 これを使用して、SQL ベースのデータ ウェアハウスにデータを段階的に取り込むことができます。
BYOD ベースの ETL パイプラインの簡略化
現在自分のデータベースの持ち込み (BYOD) 機能を使用している場合は、データ管理フレームワーク (DMF) のシステム テーブルまたはバッチ テーブルに基づくエンティティのエクスポートに依存できます。 DMF システム テーブルのエクスポート ジョブ実行データを使用して、エクスポート ジョブの期間を特定している可能性があります。 下流のジョブは、ジョブの実行状態および、DMF テーブルから取得された詳細を介してトリガーされる場合があります。
変更フィードを消費することで、オーケストレーション パイプラインを簡略化できます。
データ マートを毎日または 1 日に何度か更新する必要がある場合にテーブル フォルダーを使用する
変更フィードは強力な機能ですが、ほぼリアルタイムのデータ パイプラインを構築および管理するプロセスは複雑です。 最新のデータ変換ツールと既製のテンプレートはこのプロセスを簡素化するのに役立ちますが、パイプラインの構築と実行に投資する必要がある場合があります。
ユーザーがデータ マートを毎日または 1 日に数回更新することを期待している場合、特にデータの量が少ないか中程度の場合は、完全な更新をトリガーすることが経済的な代替になる可能性があります。 小さなテーブルを定期的に完全更新するよう選択することもできますが、頻繁に更新される大きなテーブルに対してほぼリアルタイムのパイプラインを作成することもできます。
マスター データの更新を監査および検証するための変更フィード
変更フィード フォルダーは、財務と運用データベースによって管理される CDC 変更ログの完全な複製です。 財務と運用アプリのマスター データに加えた変更は CDC に反映されます。 したがって、拡張機能として、Data Lake の変更フィード フォルダーにも反映されます。
変更フィード フォルダー上に構築されたレポートを使用して、システム内のマスター データの変更を監査および検証できます。
変更フィード フォルダーを定期的に削除する
変更フィード フォルダーは、エラーから回復するためにデータを再初期化しない限り、Data Lake へのエクスポート プロセスによって削除されません。
テーブルは 実行 状態の間、変更を追加し続けるため、変更フィード フォルダーは Data Lake 内で拡大し続けます。 (ただし、Data Lake にデータを維持するための費用は、SQL データベースのコストのわずかな一部であることに注意してください。したがって、データ拡大のコストは大きな問題ではない可能性があります。)
Data Lake に格納されるデータの量を減らしたい場合は、Data Lake から変更ログを定期的に削除できます。 たとえば、90 日または 180 日間変更されていない変更ログ ファイルを削除するジョブを実行できます。
変更ログを定期的に削除しても、テーブル フォルダー内のデータには影響しません。 ただし、この記事で前述されているように、整合性チェックを実行する場合は、それらのチェックを容易にするために、変更ログをより長く保持することをお勧めします。
ヘッダーと明細行の一貫性を持つレポートを作成する
財務と運用環境で発注書を作成すると、複数のテーブルが更新されることがあります。 便宜上、ヘッダー テーブルにレコードを追加し、複数の注文明細行を明細行テーブルに追加したとします。 システムはヘッダー テーブルと明細行テーブルの両方を Data Lake にエクスポートし、対応する変更レコードは変更フィード フォルダーに追加されます。
ただし、Data Lake へのエクスポート プロセスは、ヘッダーと複数の明細行が Data Lake に書き込まれる正確な時間は同期しません。 ヘッダー テーブルには変更が 1 行しか含まれていないので、最初に Data Lake で更新されることがあります。 その後、少ししてから明細行テーブルが更新される場合があります。 変更フィードによって、テーブル内の変更が確実にデータベースでコミットされた順序で書き込まれますが、テーブル間の変更について同様の保証はありません。
一方、一部の明細行のみを含む購買レポートはユーザーに表示する必要がないので、ヘッダー テーブルと明細行テーブルの両方から一貫したデータを反映するレポートを作成する必要がある場合があります。 このパターンは、データ マート デザインでは一般的です。 変更フィード フォルダーにより、LSN を使用してこのシナリオを処理できます。
下流のデータ パイプラインが、ヘッダーと明細行レコードを一貫した方法でデータ マートに挿入する必要がある場合、LSN に一致するヘッダーと明細行を展開することを検討してください。 データ パイプラインにヘッダー行があるものの、同じ LSN 番号を持つ明細行が一致しない場合、対応する LSN が明細行テーブルに存在するようになるまで待つ必要があります。
また、データ パイプラインは、ヘッダーと明細行間の一貫性を待たずに Data Lake に到着した時にヘッダーと明細行を挿入することができます。 代わりに、レポートのヘッダー テーブルと明細行テーブルの間で結合を実行することができます。 このようにして、一貫したデータについてのみレポートします。