Microsoft Fabric でのスターター プールの構成
この記事では、分析ワークロード用に Microsoft Fabric でスターター プールをカスタマイズする方法について説明します。 スターター プールは、Microsoft Fabric プラットフォームで Spark を数秒以内に使用するための高速で簡単な方法です。 Spark セッションは、Spark によってノードが設定されるのを待機せず、すぐに使用できます。このため、データを使用してより多くの作業を行い、より迅速に分析情報を得ることができます。
スターター プールには、要求に対して常に有効で準備ができている Spark クラスターがあります。 中サイズのノードが使用され、ワークロードの要件に基づいてスケールアップできます。
ユーザーは、Data Engineering またはデータ サイエンスのワークロード要件に基づいて、自動スケーリングの最大ノードを指定できます。 構成された最大ノードに基づいて、システムはジョブのコンピューティング要件の変化に応じてノードを動的に取得および削除し、効率的なスケーリングとパフォーマンスの向上を実現します。
また、ユーザーはスターター プールの Executor の上限を設定でき、動的割り当てが有効になっていると、システムはデータ ボリュームとジョブ レベルのコンピューティング ニーズに応じて Executor の数を調整します。 このプロセスにより、ユーザーはパフォーマンスの最適化やリソース管理を気にすることなく、ワークロードに集中することができます。
Note
スターター プールをカスタマイズするには、ワークスペースへの管理者アクセス権が必要です。
スターター プールを構成する
ワークスペースに関連付けられているスターター プールを管理するには:
ワークスペースに移動し、[ワークスペース設定] を選択します。
![[ワークスペース設定] メニューで [Data Engineering]\(データ エンジニアリング\) を選択する場所を示すスクリーンショット。](media/configure-starter-pools/data-engineering-menu.png)
次に、[Data Engineering/Science](データ エンジニアリング/サイエンス) オプションを選択してメニューを展開します。
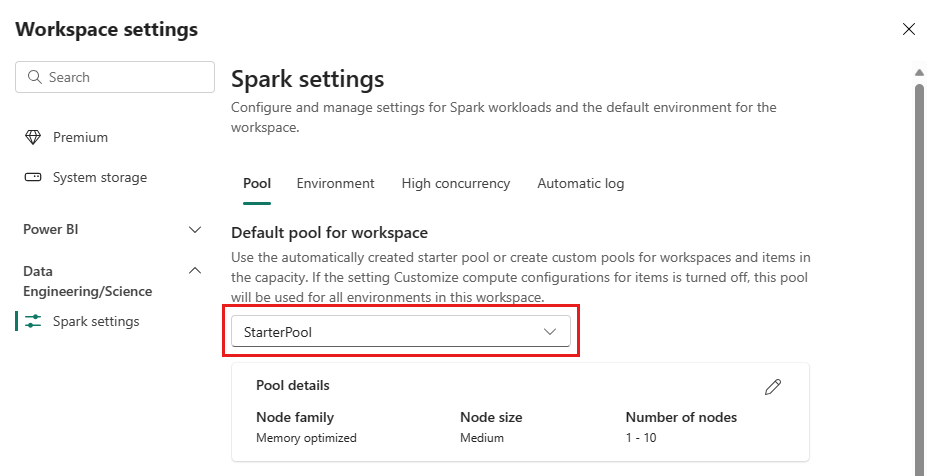
[StarterPool] オプションを選択します。
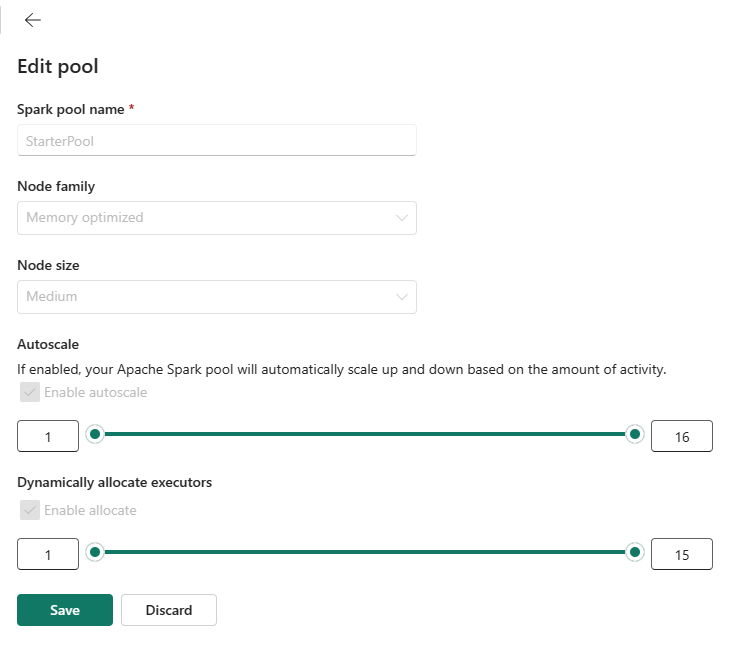
スターター プールの最大ノード構成を、購入した容量に基づいて許される数に設定したり、小さめのワークロードの実行時に既定の最大ノード構成を減らすことができます。
![[ワークスペース設定] メニューで [Data Engineering]\(データ エンジニアリング\) を選択する場所を示すスクリーンショット。](media/configure-starter-pools/data-engineering-menu.png#lightbox)
次のセクションでは、Microsoft Fabric 容量 SKU に基づいて、スターター プールでサポートされるさまざまな既定の構成と最大ノードの制限を一覧表示します:
| SKU 名 | 容量ユニット | Spark 仮想コア | ノード サイズ | 既定の最大ノード | ノードの最大数 |
|---|---|---|---|---|---|
| F2 | 2 | 4 | 中 | 1 | 1 |
| F4 | 4 | 8 | 中 | 1 | 1 |
| F8 | 8 | 16 | 中 | 2 | 2 |
| F16 | 16 | 32 | 中 | 3 | 4 |
| F32 | 32 | 64 | 中 | 8 | 8 |
| F64 | 64 | 128 | 中 | 10 | 16 |
| (試用版の容量) | 64 | 128 | 中 | 10 | 16 |
| F128 | 128 | 256 | 中 | 10 | 32 |
| F256 | 256 | 512 | 中 | 10 | 64 |
| F512 | 512 | 1024 | 中 | 10 | 128 |
| F1024 | 1024 | 2048 | 中 | 10 | 200 |
| F2048 | 2048 | 4096 | 中 | 10 | 200 |
Note
スターター プールをカスタマイズするには、ワークスペースへの管理者アクセス権が必要です。
関連するコンテンツ
- Apache Spark のパブリック ドキュメントで詳細を学習する。
- Microsoft Fabric の Spark ワークスペース管理設定の作業を開始する。