Microsoft Fabric でのノートブックの視覚化
Microsoft Fabric は、データウェアハウスとビッグ データ分析システム全体でインサイトを得るまでの時間を短縮する、統合型の分析サービスです。 ノートブックのデータの視覚化は、データから知見を得るための主なコンポーネントです。 大規模および小規模のデータを、人間が理解しやすくするのに役立ちます。 また、データのグループ内のパターン、傾向、および外れ値を容易に検出できるようになります。
Fabric の Apache Spark には、Fabric ノートブック グラフ オプションや人気のあるオープンソース ライブラリへのアクセスを含むデータの視覚化を実現する、さまざまな組み込みオプションがあります。
Fabric ノートブックを使用する際、グラフ オプションを用いて表形式の結果ビューをカスタマイズされたグラフに変換できます。 なお、データの視覚化はコードを記述しなくても行うことができます。
ビルトイン視覚化コマンド - ()関数の表示
ファブリックのビルトイン視覚化関数は、Apache Spark DataFrame、Pandas DataFrame、SQL クエリ結果をリッチ形式のデータ視覚化に変換できるようにします。
Spark DataFrame または Resilient Distributed Datasets(RDD)関数で PySpark と Scala を作成した DataFrame の[表示]関数を使用し、リッチ データフレーム テーブル ビューとグラフ ビューを生成できます。
SQL ステートメントの出力は、既定でレンダリングされたテーブル ビューに表示されます。
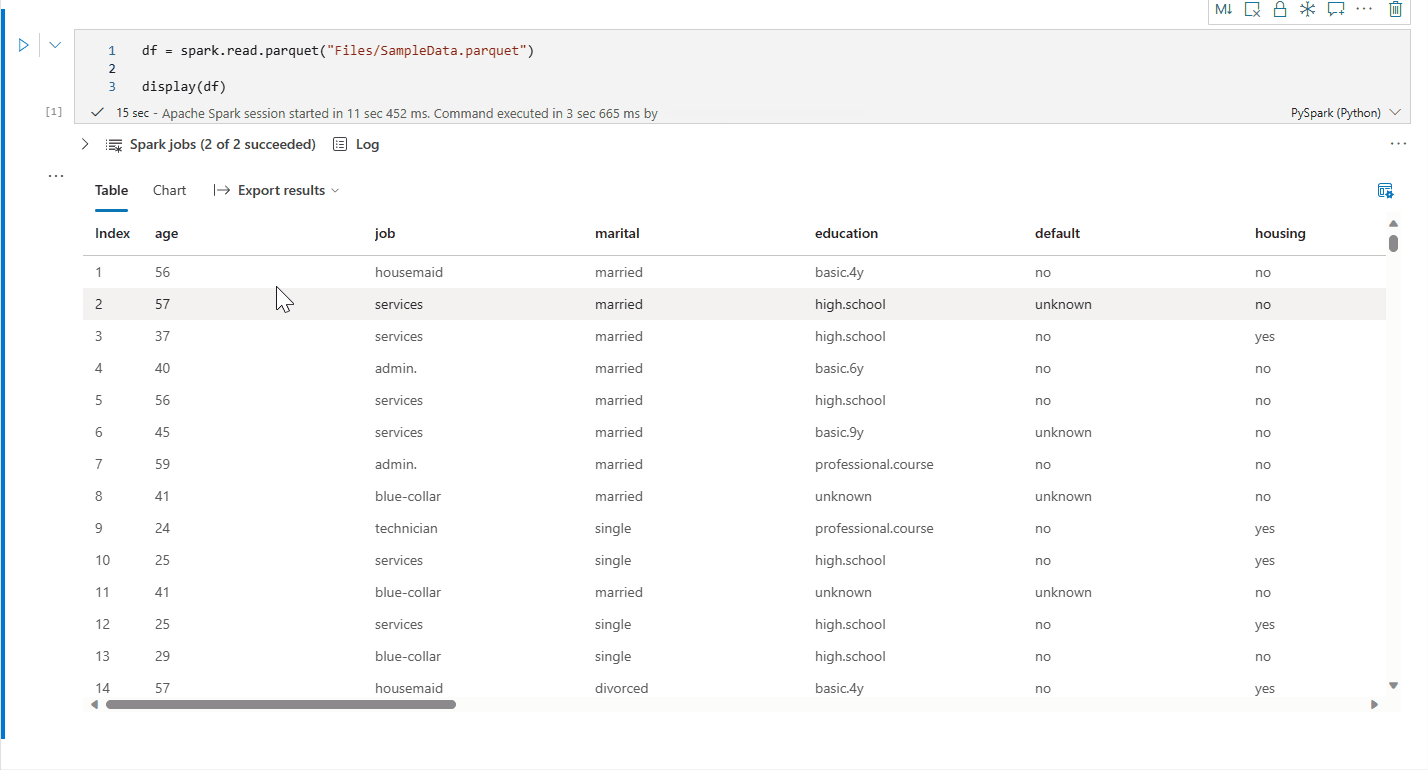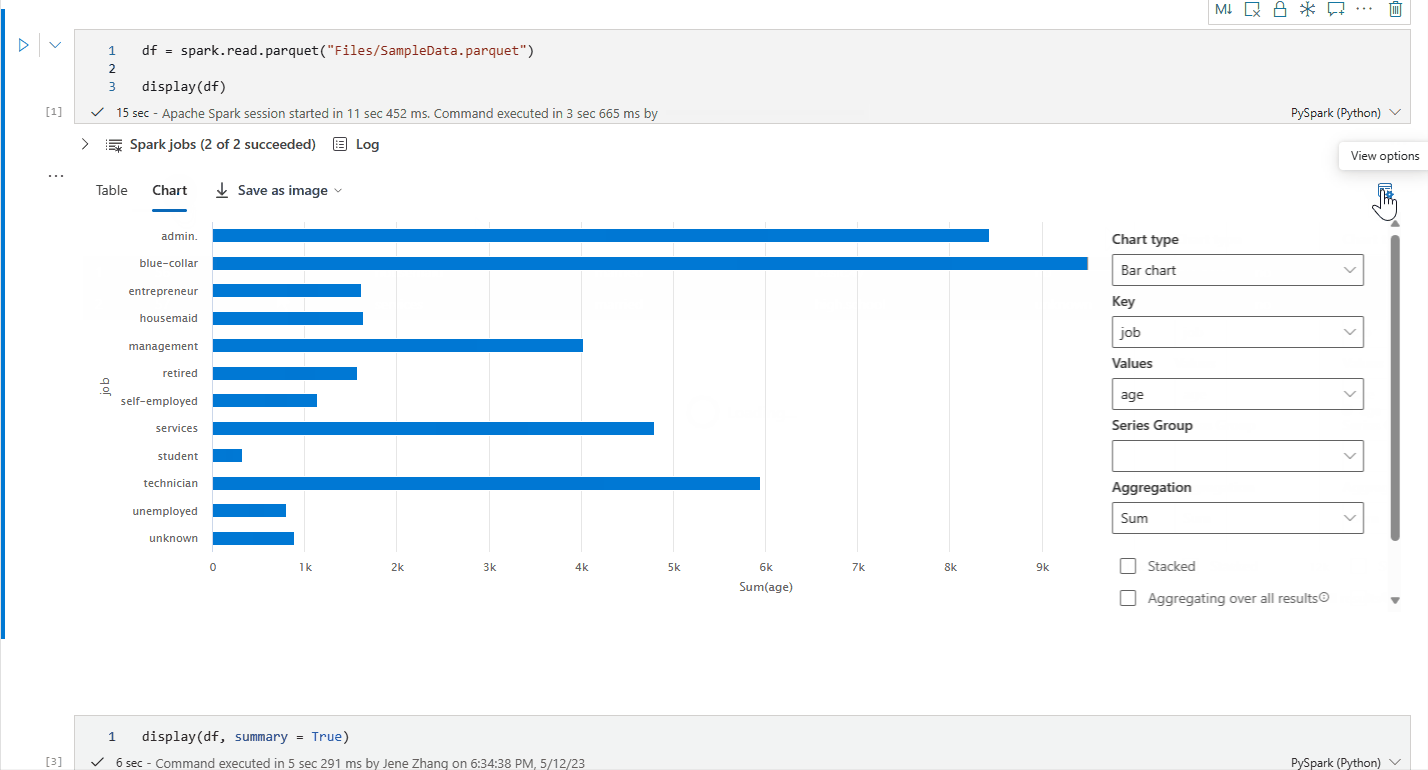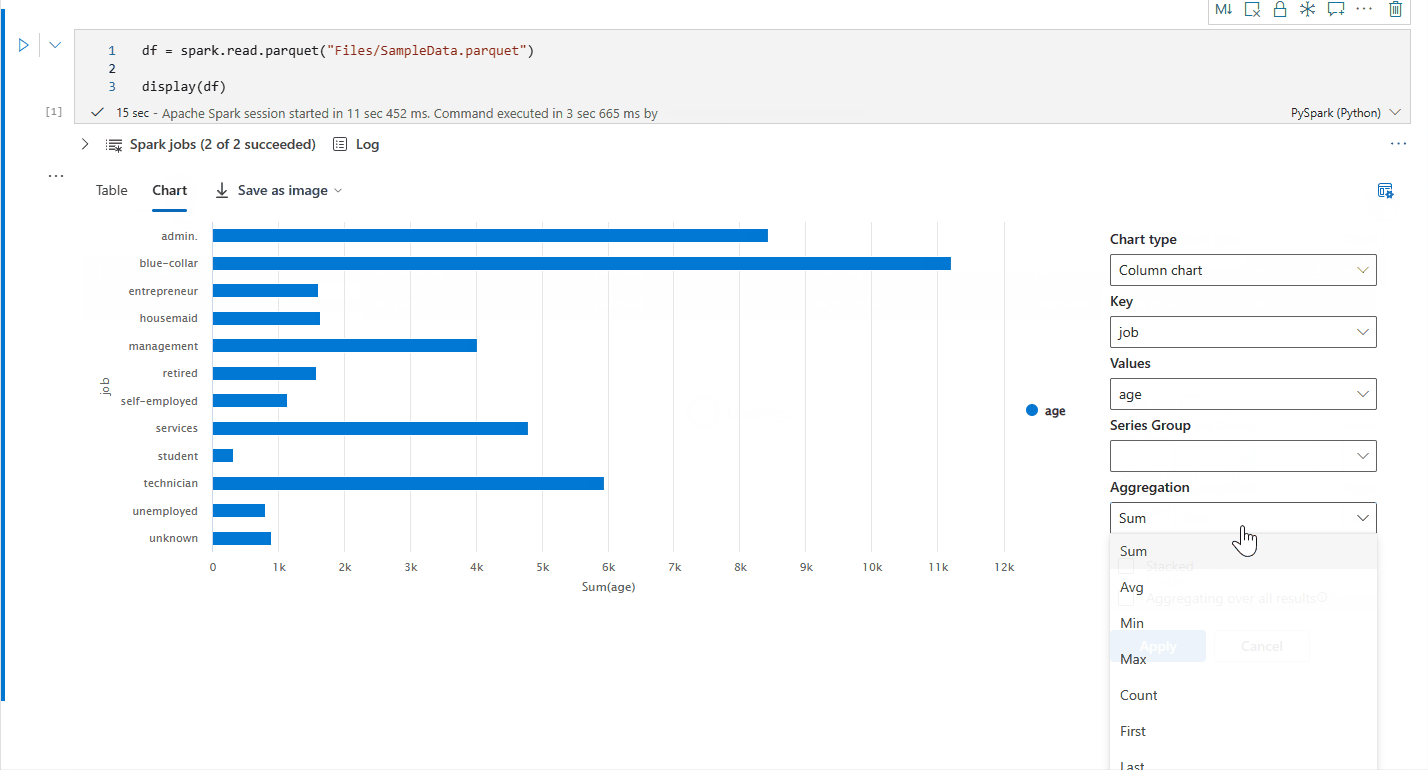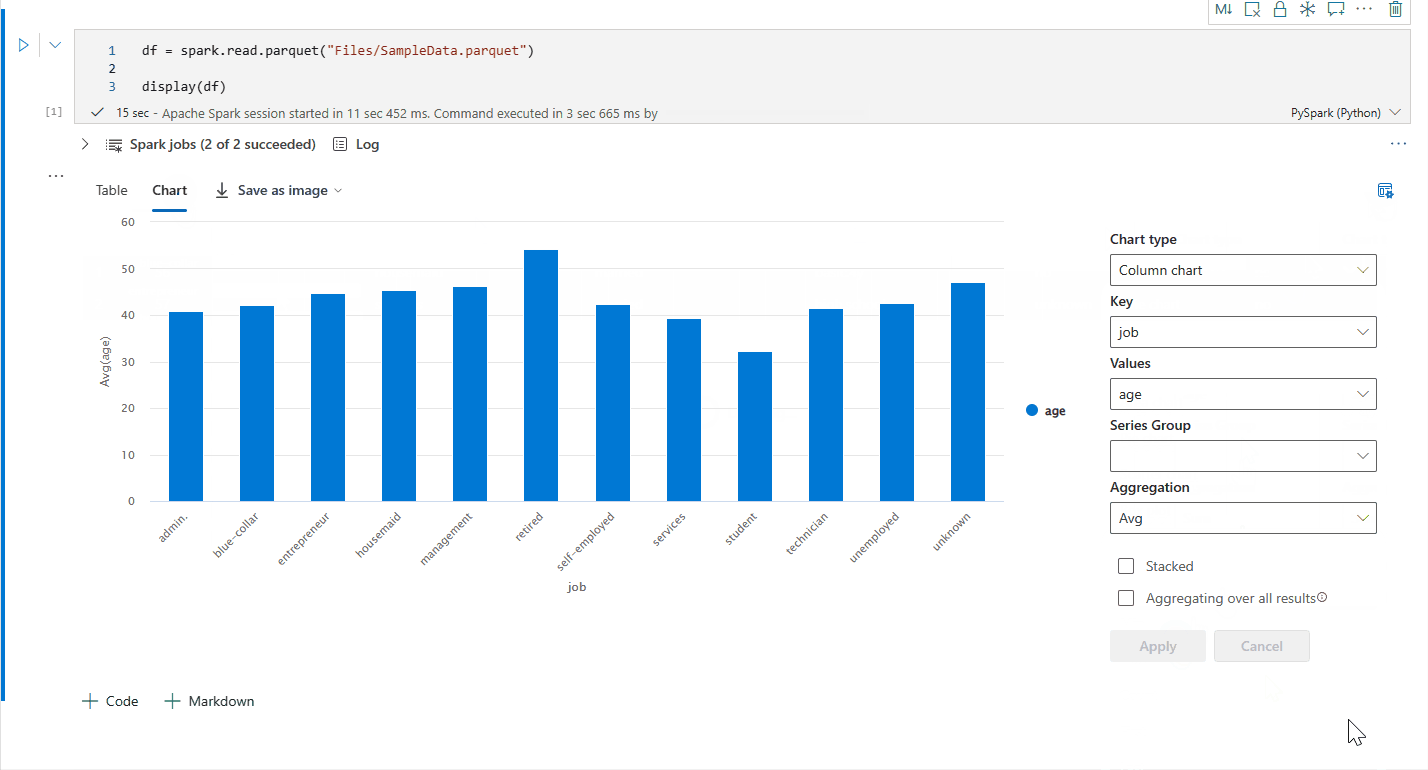
リッチ DataFrame テーブル ビュー
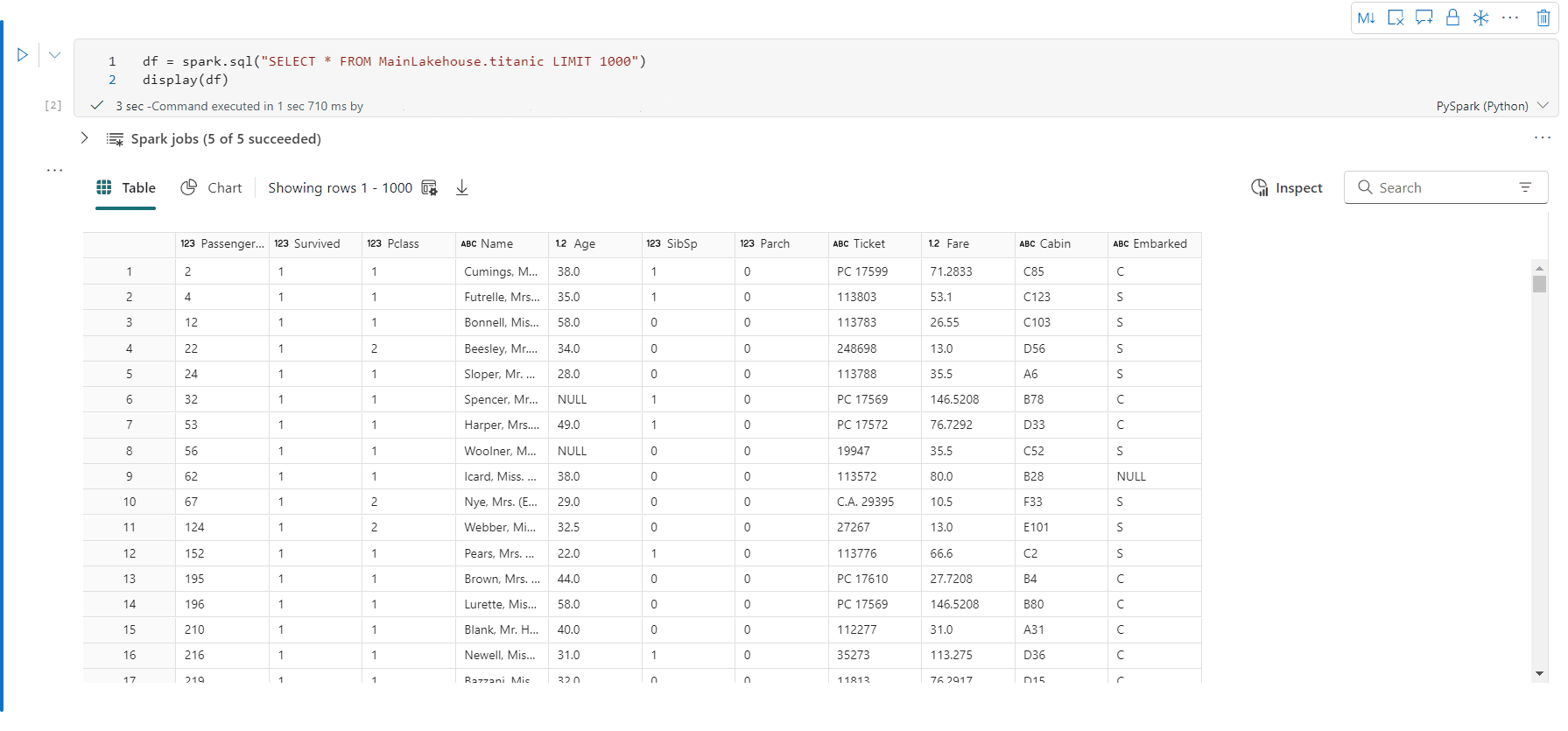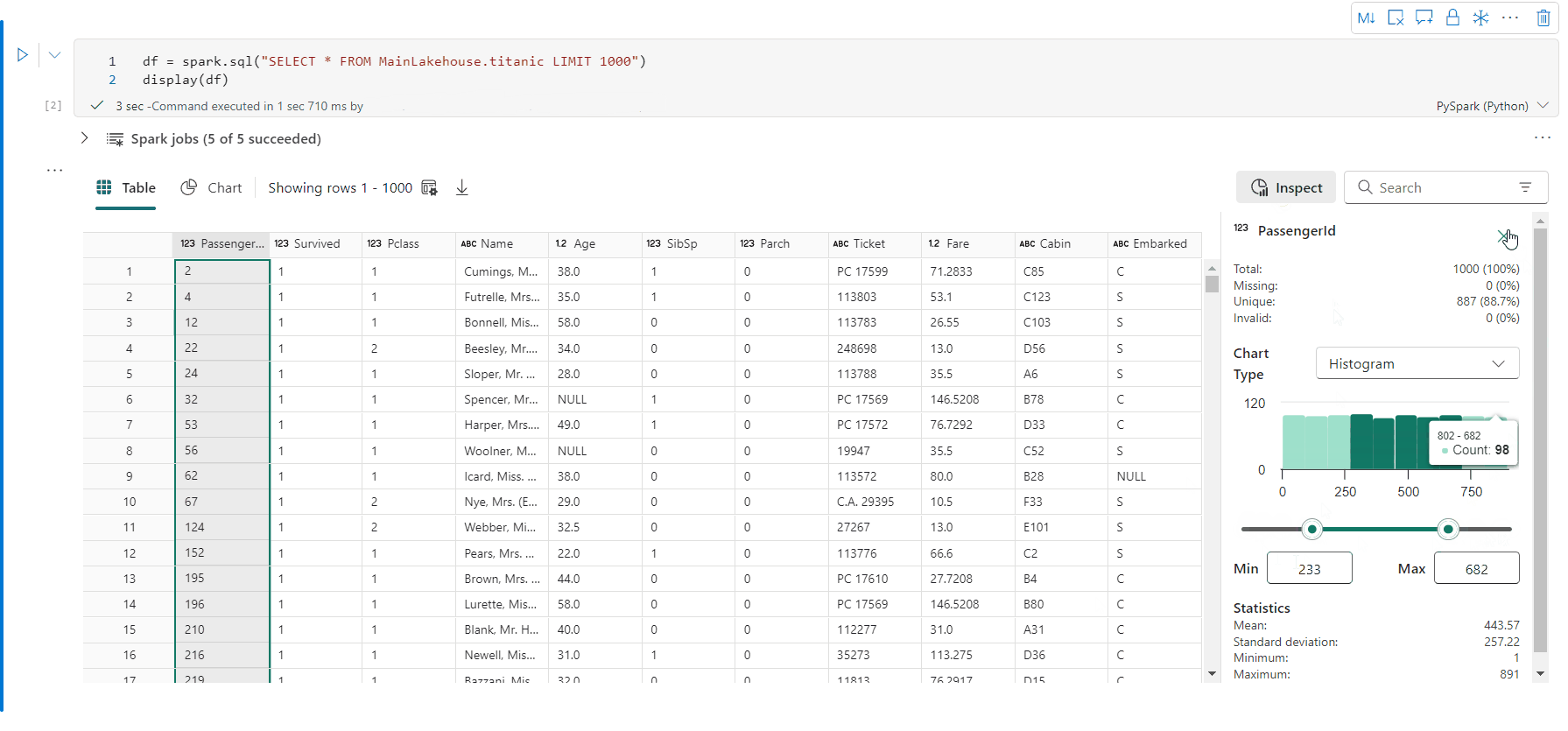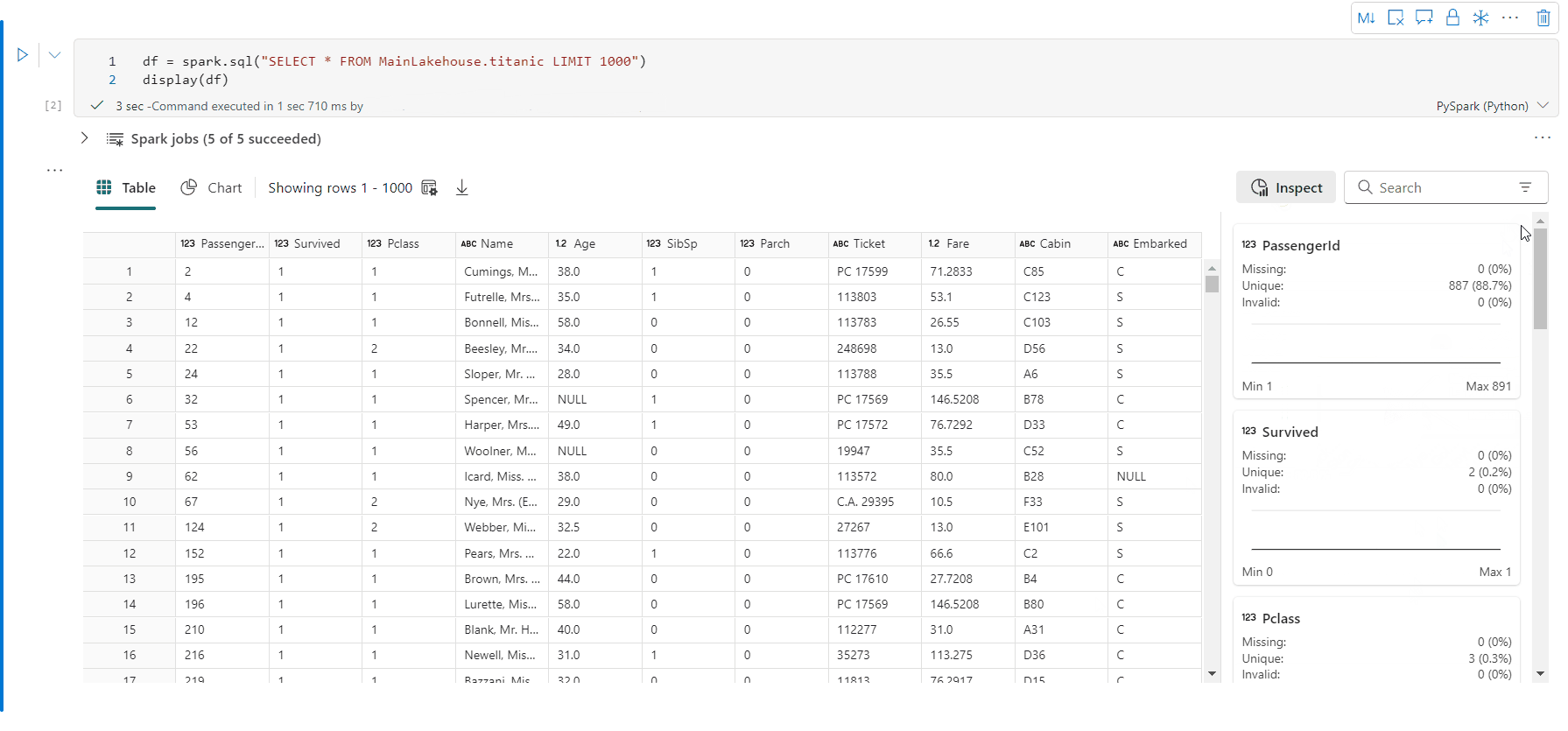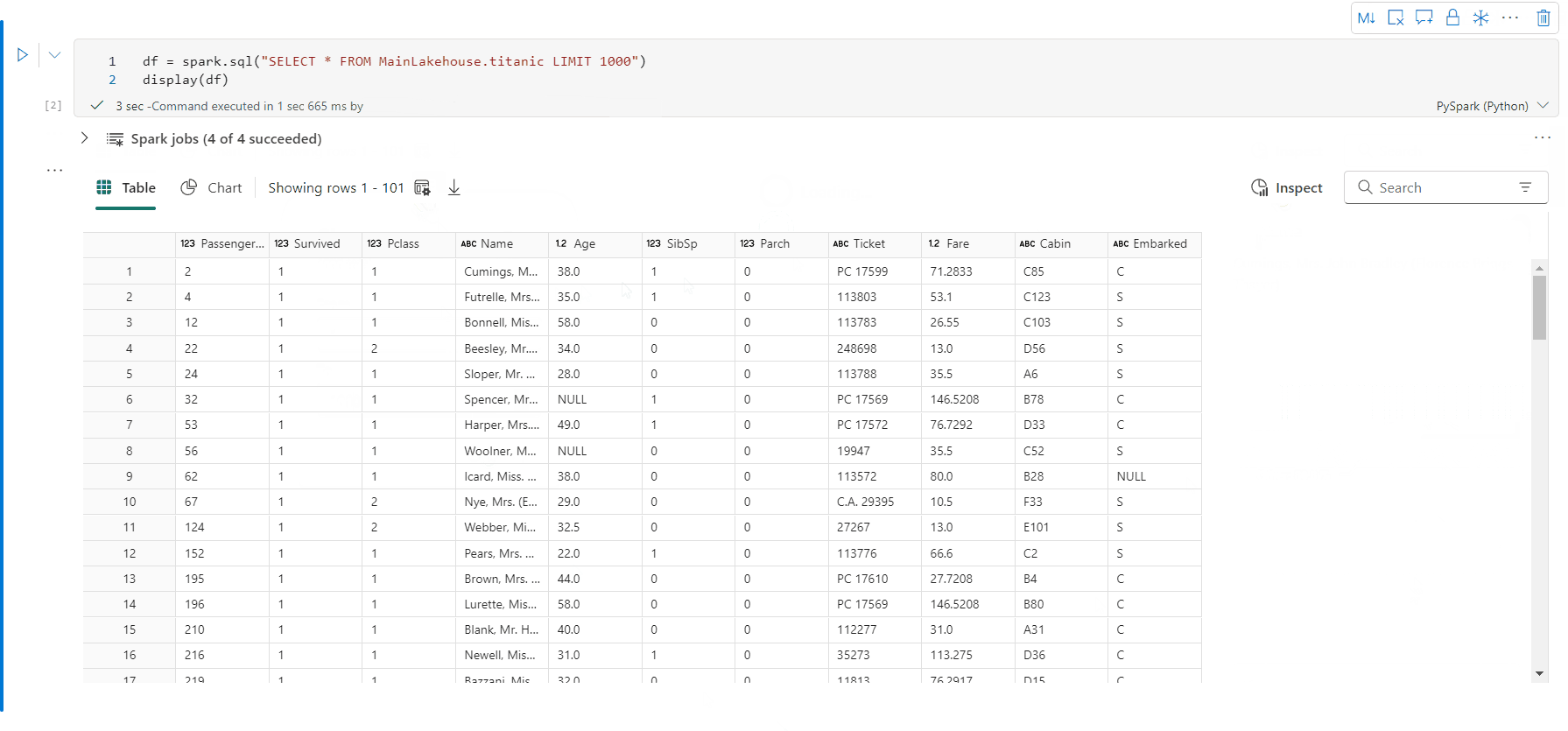
- テーブル ビューは、[()表示]コマンドを使用するときにデフォルトでレンダリングされます。
- [検査]ボタンをクリックして DataFrame をプロファイルできます。 要約されたデータ分布と各列の統計情報が表示されます。
- [検査] 作業ウィンドウの各カードは、DataFrame の列にマッピングします。カードをクリックするか、テーブルの列を選択して詳細を表示できます。
- テーブルのセルをクリックすると、セルの詳細を表示できます。 これは、DataFrame に長い文字列タイプのコンテンツが含まれている場合に便利です。
- テーブル ビューの行数を指定できます。既定値は 1000 であり、ノートブックでは最大で 10000 行の DataFrame の表示とプロファイルがサポートされます。
リッチ DataFrame グラフ ビュー
レンダリングされたテーブル ビューを用意できたら、グラフ ビューに切り替えます。
Fabric ノートブックは、対象の DataFrame に基づいて "キー" "値" ペアを自動的に推奨し、デフォルトのグラフをデータ分析情報で明確にします。
これで、次の値を指定して、視覚化をカスタマイズできるようになりました。
Configuration 説明 グラフの種類 display 関数では、棒グラフ、散布図、折れ線グラフなど、さまざまな種類のグラフがサポートされています。 キー X 軸の値の範囲を指定します。 値 Y 軸の値の範囲を指定します。 系列グループ この構成を使用して、集約のグループを決定できます。 集計 この方法を使用して、視覚化でデータを集約します。 構成はノートブックの出力コンテンツに自動保存されます。
Note
既定では、display(df) 関数は、グラフをレンダリングするためにデータの最初の 1000 行のみを取得します。 [すべての結果の集約] を選択してから [適用] を選択して、セマンティック モデル全体からグラフ生成を適用します。 グラフの設定が変更されると、Spark ジョブがトリガーされます。 計算が完了してグラフがレンダリングされるまでに数分かかる場合があることに注意してください。
ジョブが完了すると最終の視覚化を表示し、通信できます。
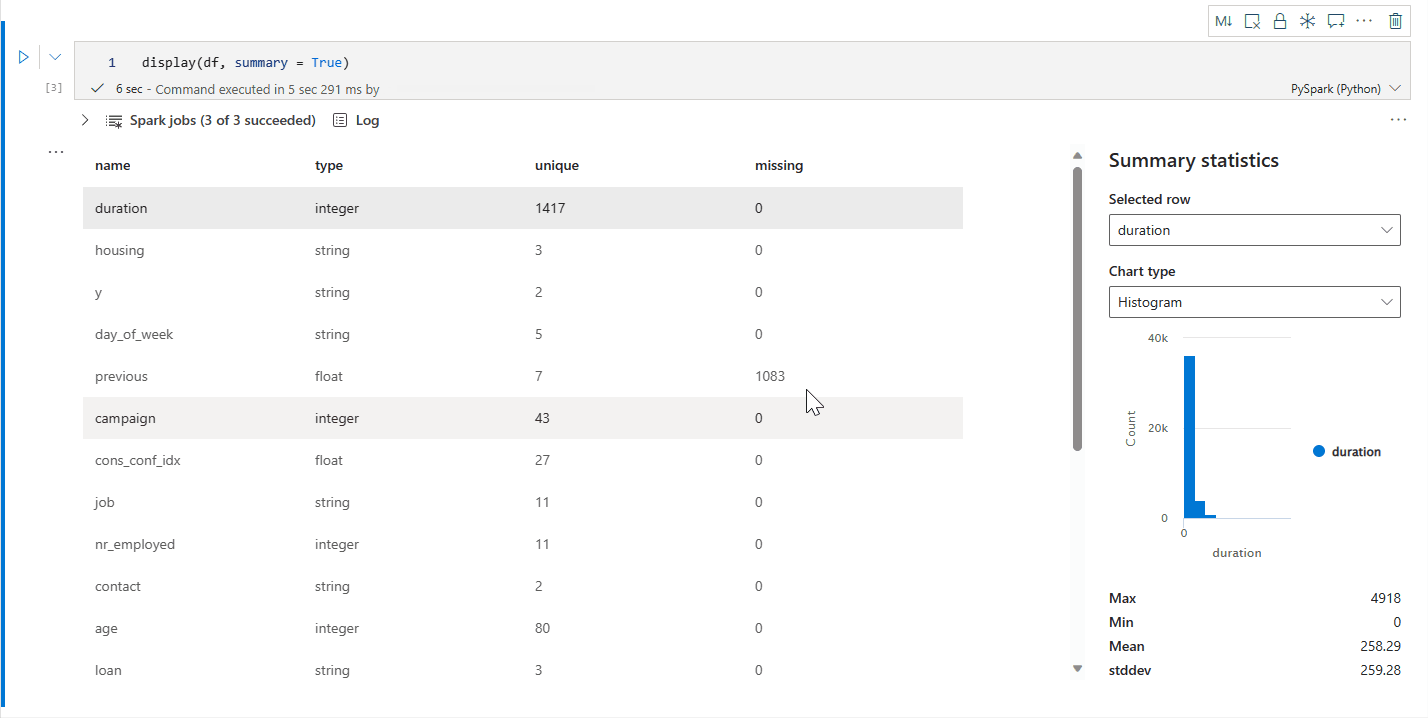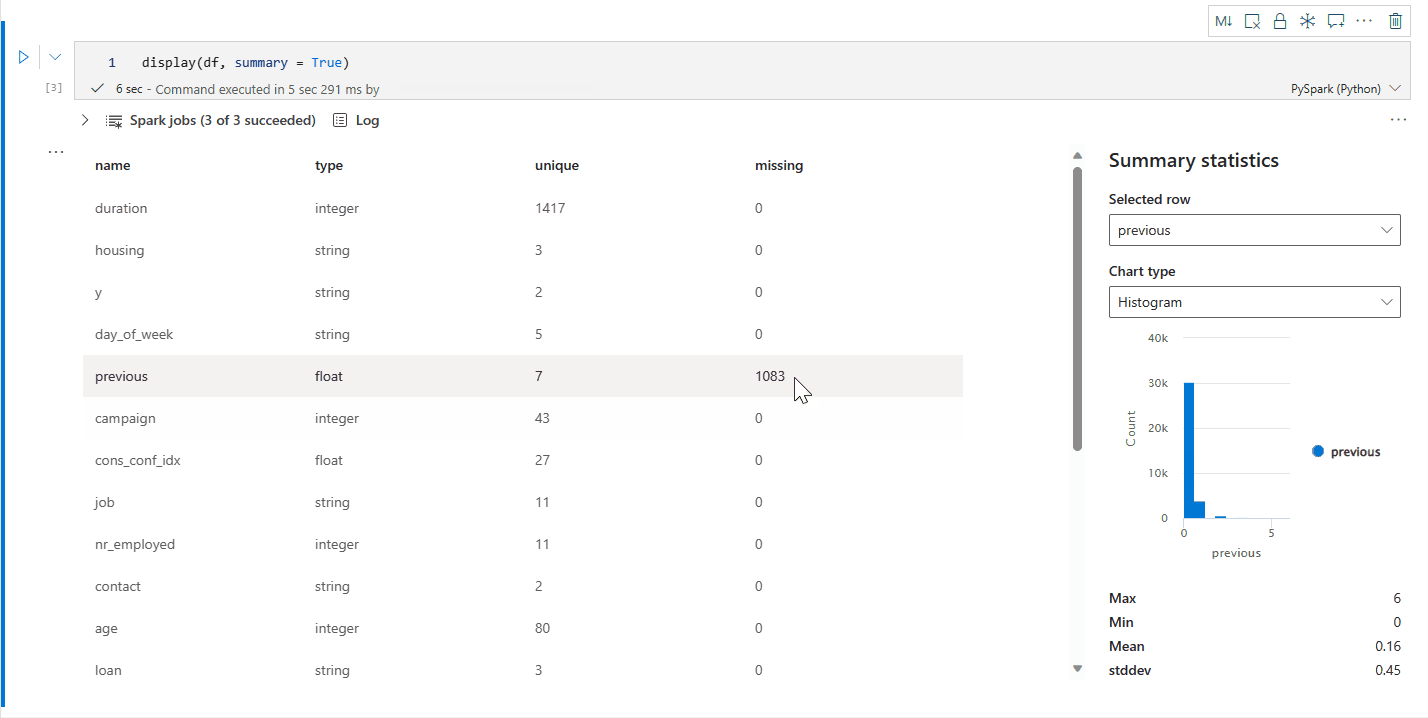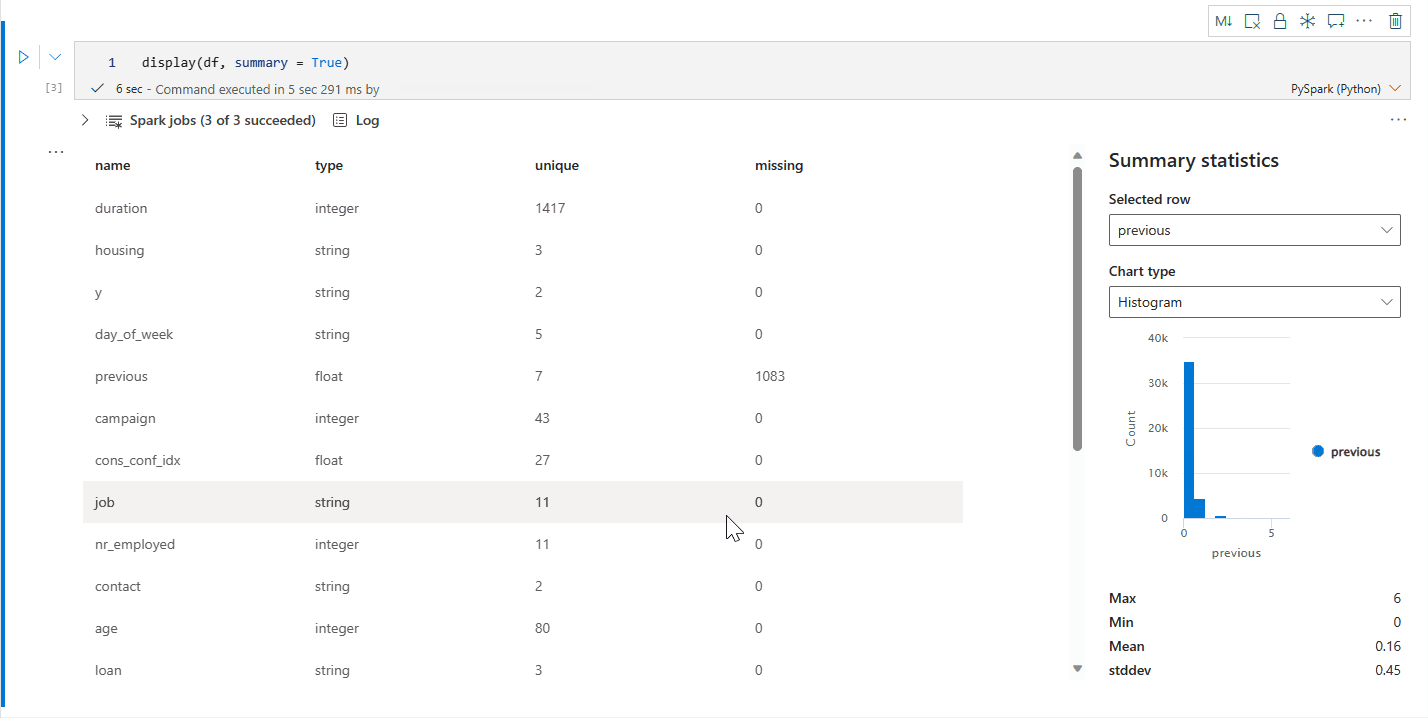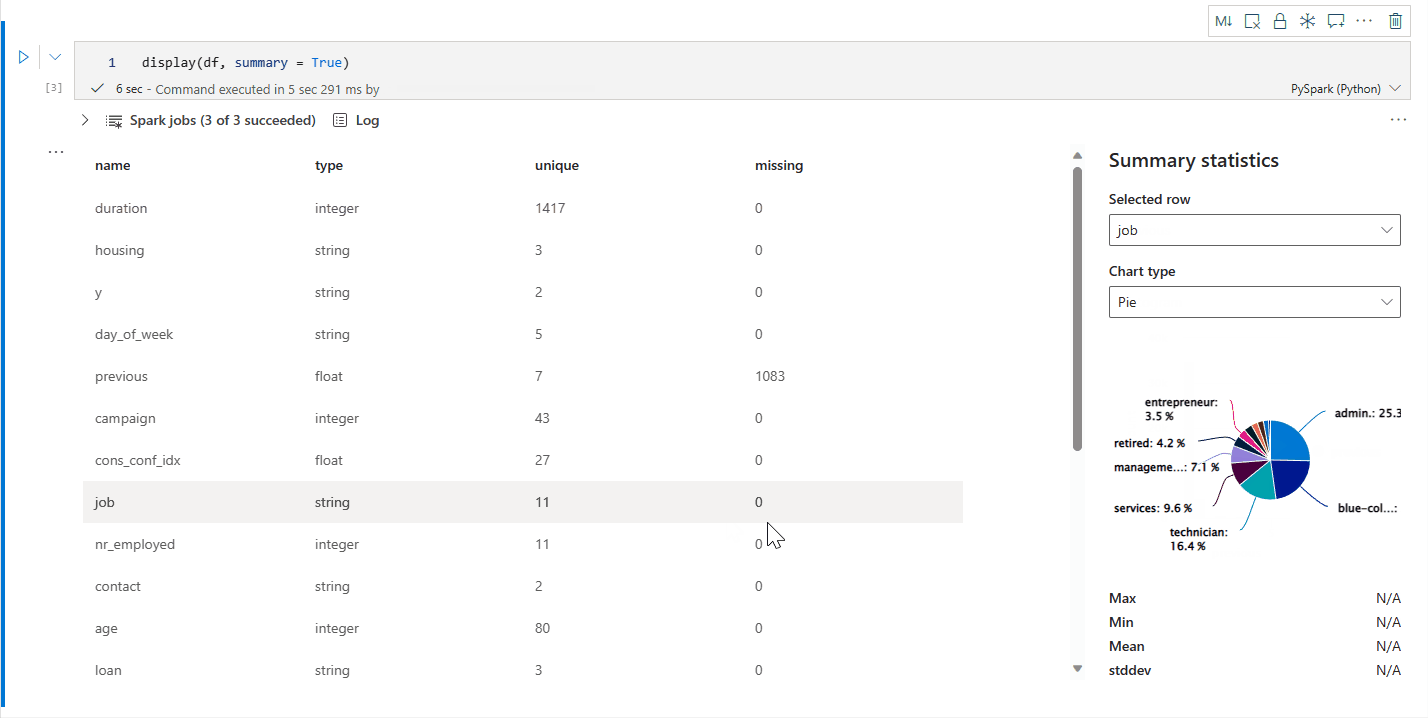
display(df) の概要ビュー
display(df, summary = true) を使用して、特定の Apache Spark DataFrame の統計概要を確認できます。 概要には列名、列タイプ、一意の値、各行で欠損している値が含まれます。 また、特定の列を選択して、その列の最小値、最大値、平均値、標準偏差を表示することもできます。
displayHTML() option
Fabric ノートブックは displayHTML 関数を使用して HTML グラフィックをサポートします。
次の図は、D3.js を使用して視覚化を作成する例です。

この視覚化を作成するには、次のコードを実行します。
displayHTML("""<!DOCTYPE html>
<meta charset="utf-8">
<!-- Load d3.js -->
<script src="https://d3js.org/d3.v4.js"></script>
<!-- Create a div where the graph will take place -->
<div id="my_dataviz"></div>
<script>
// set the dimensions and margins of the graph
var margin = {top: 10, right: 30, bottom: 30, left: 40},
width = 400 - margin.left - margin.right,
height = 400 - margin.top - margin.bottom;
// append the svg object to the body of the page
var svg = d3.select("#my_dataviz")
.append("svg")
.attr("width", width + margin.left + margin.right)
.attr("height", height + margin.top + margin.bottom)
.append("g")
.attr("transform",
"translate(" + margin.left + "," + margin.top + ")");
// Create Data
var data = [12,19,11,13,12,22,13,4,15,16,18,19,20,12,11,9]
// Compute summary statistics used for the box:
var data_sorted = data.sort(d3.ascending)
var q1 = d3.quantile(data_sorted, .25)
var median = d3.quantile(data_sorted, .5)
var q3 = d3.quantile(data_sorted, .75)
var interQuantileRange = q3 - q1
var min = q1 - 1.5 * interQuantileRange
var max = q1 + 1.5 * interQuantileRange
// Show the Y scale
var y = d3.scaleLinear()
.domain([0,24])
.range([height, 0]);
svg.call(d3.axisLeft(y))
// a few features for the box
var center = 200
var width = 100
// Show the main vertical line
svg
.append("line")
.attr("x1", center)
.attr("x2", center)
.attr("y1", y(min) )
.attr("y2", y(max) )
.attr("stroke", "black")
// Show the box
svg
.append("rect")
.attr("x", center - width/2)
.attr("y", y(q3) )
.attr("height", (y(q1)-y(q3)) )
.attr("width", width )
.attr("stroke", "black")
.style("fill", "#69b3a2")
// show median, min and max horizontal lines
svg
.selectAll("toto")
.data([min, median, max])
.enter()
.append("line")
.attr("x1", center-width/2)
.attr("x2", center+width/2)
.attr("y1", function(d){ return(y(d))} )
.attr("y2", function(d){ return(y(d))} )
.attr("stroke", "black")
</script>
"""
)
ノートブックに Power BI レポートを埋め込む
重要
現在、この機能はプレビュー段階にあります。 この情報はプレリリース製品に関連するものであり、リリース前に大幅に変更される可能性があります。 ここに記載された情報について、Microsoft は明示または黙示を問わずいかなる保証をするものでもありません。
Powerbiclient Python パッケージが Fabric ノートブックでネイティブでサポートされるようになりました。 Fabric ノートブック Spark ランタイム 3.4 で追加の設定 (認証プロセスなど) を行う必要はありません。 powerbiclient をインポートして、引き続き機能を確認するだけです。 powerbiclient パッケージの使用方法について詳しくは、powerbiclient ドキュメントをご覧ください。
Powerbiclient は次の主な機能をサポートしています。
既存の Power BI レポートをレンダリングする
ノートブックの Power BI レポートでは、ほんの数行のコードを使用するだけで簡単に埋め込み、通信できます。
次の画像は既存の Power BI レポートのレンダリングの例です。

既存の Power BI レポートをレンダリングするには、次のコードを実行します。
from powerbiclient import Report
report_id="Your report id"
report = Report(group_id=None, report_id=report_id)
report
Spark DataFrame からレポート ビジュアルを作成する
ノートブックで Spark DataFrame を使用して、すばやくインサイト豊富な視覚化を生成できます。 また、埋め込まれたレポートで [保存] を選択し、対象のワークスペースでレポート アイテムを作成することもできます。
次の画像は Spark DataFrame の QuickVisualize() の例です。

Spark DataFrame からレポートをレンダリングするには、次のコードを実行します。
# Create a spark dataframe from a Lakehouse parquet table
sdf = spark.sql("SELECT * FROM testlakehouse.table LIMIT 1000")
# Create a Power BI report object from spark data frame
from powerbiclient import QuickVisualize, get_dataset_config
PBI_visualize = QuickVisualize(get_dataset_config(sdf))
# Render new report
PBI_visualize
pandas DataFrame からレポート ビジュアルを作成する
また、ノートブックで pandas DataFrame に基づくレポートを作成することもできます。
次の画像は、pandas DataFrame の QuickVisualize() の例です。

Spark DataFrame からレポートをレンダリングするには、次のコードを実行します。
import pandas as pd
# Create a pandas dataframe from a URL
df = pd.read_csv("https://raw.githubusercontent.com/plotly/datasets/master/fips-unemp-16.csv")
# Create a pandas dataframe from a Lakehouse csv file
from powerbiclient import QuickVisualize, get_dataset_config
# Create a Power BI report object from your data
PBI_visualize = QuickVisualize(get_dataset_config(df))
# Render new report
PBI_visualize
人気の高いライブラリ
データの視覚化に関して言えば、Python には、さまざまな機能を多数備えた複数のグラフ ライブラリが用意されています。 Fabric のすべての Apache Spark プールには、キュレーションされた人気のあるオープンソース ライブラリのセットがデフォルトで含まれています。
Matplotlib
各ライブラリの組み込みのレンダリング関数を使用すれば、Matplotlib のような標準のプロット ライブラリをレンダリングすることができます。
次の図は、Matplotlib を使用して横棒グラフを作成する例を示しています。


この棒グラフを描画するには、次のサンプル コードを実行します。
# Bar chart
import matplotlib.pyplot as plt
x1 = [1, 3, 4, 5, 6, 7, 9]
y1 = [4, 7, 2, 4, 7, 8, 3]
x2 = [2, 4, 6, 8, 10]
y2 = [5, 6, 2, 6, 2]
plt.bar(x1, y1, label="Blue Bar", color='b')
plt.bar(x2, y2, label="Green Bar", color='g')
plt.plot()
plt.xlabel("bar number")
plt.ylabel("bar height")
plt.title("Bar Chart Example")
plt.legend()
plt.show()
Bokeh
displayHTML(df) を使用して、HTML や対話型のライブラリ (bokeh など) をレンダリングできます。
次の図は、ボケを使用して、マップ上にグリフをプロットする例です。

この画像を描くには、次のサンプル コードを実行します。
from bokeh.plotting import figure, output_file
from bokeh.tile_providers import get_provider, Vendors
from bokeh.embed import file_html
from bokeh.resources import CDN
from bokeh.models import ColumnDataSource
tile_provider = get_provider(Vendors.CARTODBPOSITRON)
# range bounds supplied in web mercator coordinates
p = figure(x_range=(-9000000,-8000000), y_range=(4000000,5000000),
x_axis_type="mercator", y_axis_type="mercator")
p.add_tile(tile_provider)
# plot datapoints on the map
source = ColumnDataSource(
data=dict(x=[ -8800000, -8500000 , -8800000],
y=[4200000, 4500000, 4900000])
)
p.circle(x="x", y="y", size=15, fill_color="blue", fill_alpha=0.8, source=source)
# create an html document that embeds the Bokeh plot
html = file_html(p, CDN, "my plot1")
# display this html
displayHTML(html)
Plotly
displayHTML() を使用して、HTML または対話型のライブラリ (Plotly など) をレンダリングすることができます。
この画像を描くには、次のサンプル コードを実行します。

from urllib.request import urlopen
import json
with urlopen('https://raw.githubusercontent.com/plotly/datasets/master/geojson-counties-fips.json') as response:
counties = json.load(response)
import pandas as pd
df = pd.read_csv("https://raw.githubusercontent.com/plotly/datasets/master/fips-unemp-16.csv",
dtype={"fips": str})
import plotly
import plotly.express as px
fig = px.choropleth(df, geojson=counties, locations='fips', color='unemp',
color_continuous_scale="Viridis",
range_color=(0, 12),
scope="usa",
labels={'unemp':'unemployment rate'}
)
fig.update_layout(margin={"r":0,"t":0,"l":0,"b":0})
# create an html document that embeds the Plotly plot
h = plotly.offline.plot(fig, output_type='div')
# display this html
displayHTML(h)
Pandas
pandas DataFrames の HTML 出力をデフォルトの出力として表示できます。 Fabric ノートブックは自動的にスタイル設定された HTML コンテンツを表示します。

import pandas as pd
import numpy as np
df = pd.DataFrame([[38.0, 2.0, 18.0, 22.0, 21, np.nan],[19, 439, 6, 452, 226,232]],
index=pd.Index(['Tumour (Positive)', 'Non-Tumour (Negative)'], name='Actual Label:'),
columns=pd.MultiIndex.from_product([['Decision Tree', 'Regression', 'Random'],['Tumour', 'Non-Tumour']], names=['Model:', 'Predicted:']))
df