Fabric の Apache Spark Runtime
Microsoft Fabric Runtime は、Apache Spark に基づく Azure 統合プラットフォームであり、データ エンジニアリングとデータ サイエンスのエクスペリエンスの実行と管理を可能にします。 内部ソースとオープンソースの両方の主要コンポーネントを組み合わせ、包括的なソリューションを顧客に提供します。 わかりやすくするために、Apache Spark を利用する Microsoft Fabric Runtime のことを Fabric Runtime と呼びます。
Fabric Runtime の主なコンポーネントは以下のとおりです。
Apache Spark - 大規模なデータ処理と分析タスクを可能にする強力なオープンソースの分散コンピューティング ライブラリです。 Apache Spark は、データ エンジニアリングとデータ サイエンスのエクスペリエンスに適した、汎用的で高パフォーマンスのプラットフォームを提供します。
Delta Lake - ACID トランザクションやその他のデータ信頼性機能を Apache Spark に提供するオープンソースのストレージ レイヤー。 Fabric Runtime 内に統合された Delta Lake は、データ処理機能を強化し、複数の同時実行操作間でデータの一貫性を確保します。
デフォルトレベルの Java/Scala、Python、R 用のパッケージ - さまざまなプログラミング言語と環境をサポートするパッケージ。 これらのパッケージは自動的にインストールおよび構成されるため、開発者はデータ処理タスクに好みのプログラミング言語を適用できます。
Microsoft Fabric Runtime は堅牢なオープンソース オペレーティング システムに基づいて構築されているので、さまざまなハードウェア構成やシステム要件との互換性が確保されます。
Microsoft Fabric プラットフォーム内の Runtime 1.1 と Runtime 1.2 の両方について、Apache Spark のバージョン、サポートされるオペレーティング システム、Java、Scala、Python、Delta Lake、R などの主要コンポーネントの包括的な比較を次に示します。
ヒント
運用ワークロードには常に最新の GA ランタイム バージョン (現在はRuntime 1.2) を使用してください。
| Runtime 1.1 | Runtime 1.2 | ランタイム 1.3 | |
|---|---|---|---|
| Apache Spark | 3.3.1 | 3.4.1 | 3.5.0 |
| オペレーティング システム | Ubuntu 18.04 | Mariner 2.0 | Mariner 2.0 |
| Java | 8 | 11 | 11 |
| Scala | 2.12.15 | 2.12.17 | 2.12.17 |
| Python | 3.10 | 3.10 | 3.11 |
| Delta Lake | 2.2.0 | 2.4.0 | 3.1 |
| R | 4.2.2 | 4.2.2 | 4.3.3 |
Runtime 1.1、Runtime 1.2 またはRuntime 1.3 のページを参照して、特定の Runtime バージョンの詳細、新機能、改善点、移行シナリオを確認してください。
Fabric の最適化
Microsoft Fabric では、Spark エンジンと Delta Lake の両方の実装にプラットフォーム固有の最適化と機能が組み込まれています。 これらの機能は、プラットフォーム内でネイティブ統合を使うように設計されています。 標準の Spark と Delta Lake の機能を実現するために、これらの機能はすべて無効にできることに注意してください。 Apache Spark 用 Fabric Runtime には、以下が含まれます。
- Apache Spark の完全なオープンソース バージョン。
- 約 100 個の組み込みの個別のクエリ パフォーマンスに関する機能強化のコレクション。 これらの機能強化には、パーティション キャッシュ (FileSystem パーティション キャッシュを有効にしてメタストアの呼び出しを減らす) や、スカラー サブクエリのプロジェクションへのクロス結合などの機能があります。
- 組み込みのインテリジェント キャッシュ。
Apache Spark と Delta Lake 用 Fabric Runtime 内には、2 つの重要な目的を果たすネイティブ ライター機能があります。
- これらは書き込みワークロードに対して差別化されたパフォーマンスを提供し、書き込みプロセスを最適化します。
- デフォルトでは、Delta Parquet ファイルの V オーダー最適化が行われます。 Delta Lake の V オーダーの最適化は、すべての Fabric エンジンで優れた読み取りパフォーマンスを実現するために不可欠です。 その動作のしくみと管理方法についてより深く理解するには、「Delta Lake テーブルの最適化と V オーダー」の専門の記事を参照してください。
複数のランタイムのサポート
Fabric は複数のランタイムをサポートし、ユーザーがそれらをシームレスに切り替えられる柔軟性を提供し、非互換性や中断のリスクを最小限に抑えます。
デフォルトでは、すべての新規ワークスペースに最新のランタイム バージョン (現在は Runtime 1.2) が使われます。
ワークスペース レベルでランタイム バージョンを変更するには、[ワークスペース設定] > [Data Engineering/Science] > [Spark コンピューティング] > [ワークスペース レベルのデフォルト] に移動し、使用可能なオプションから目的のランタイムを選択します。
この変更を行うと、Lakehouse 、SJD、ノートブックなど、ワークスペース内にシステムによって作成されたすべての項目は、次の Spark Session から新しく選ばれたワークスペースレベルのランタイム バージョンを使って機能するようになります。 ジョブまたはLakehouse 関連のアクティビティに既存のセッションを含むノートブックを現在使っている場合、その Spark セッションはそのまま続行されます。 ただし、次のセッションまたはジョブから、選んだランタイム バージョンが適用されます。
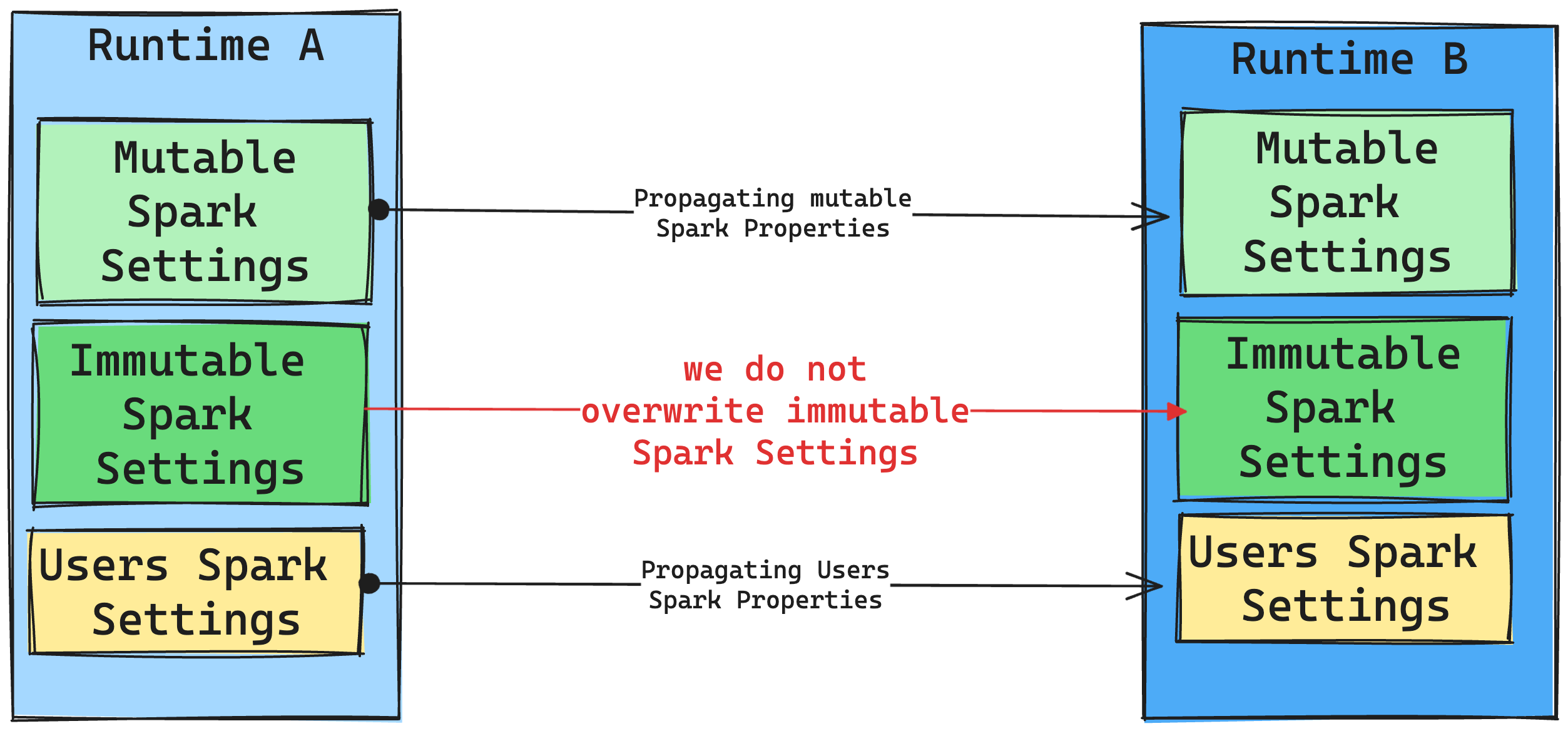
Spark 設定でのランタイム変更の結果
Microsoft は、一般に、すべての Spark 設定を移行することを目指しています。 ただし、Spark の設定がランタイム B と互換性がないことが判明した場合は、警告メッセージを発行し、その設定が実装されないようにしています。
ランタイムの変更がライブラリ管理に及ぼす影響
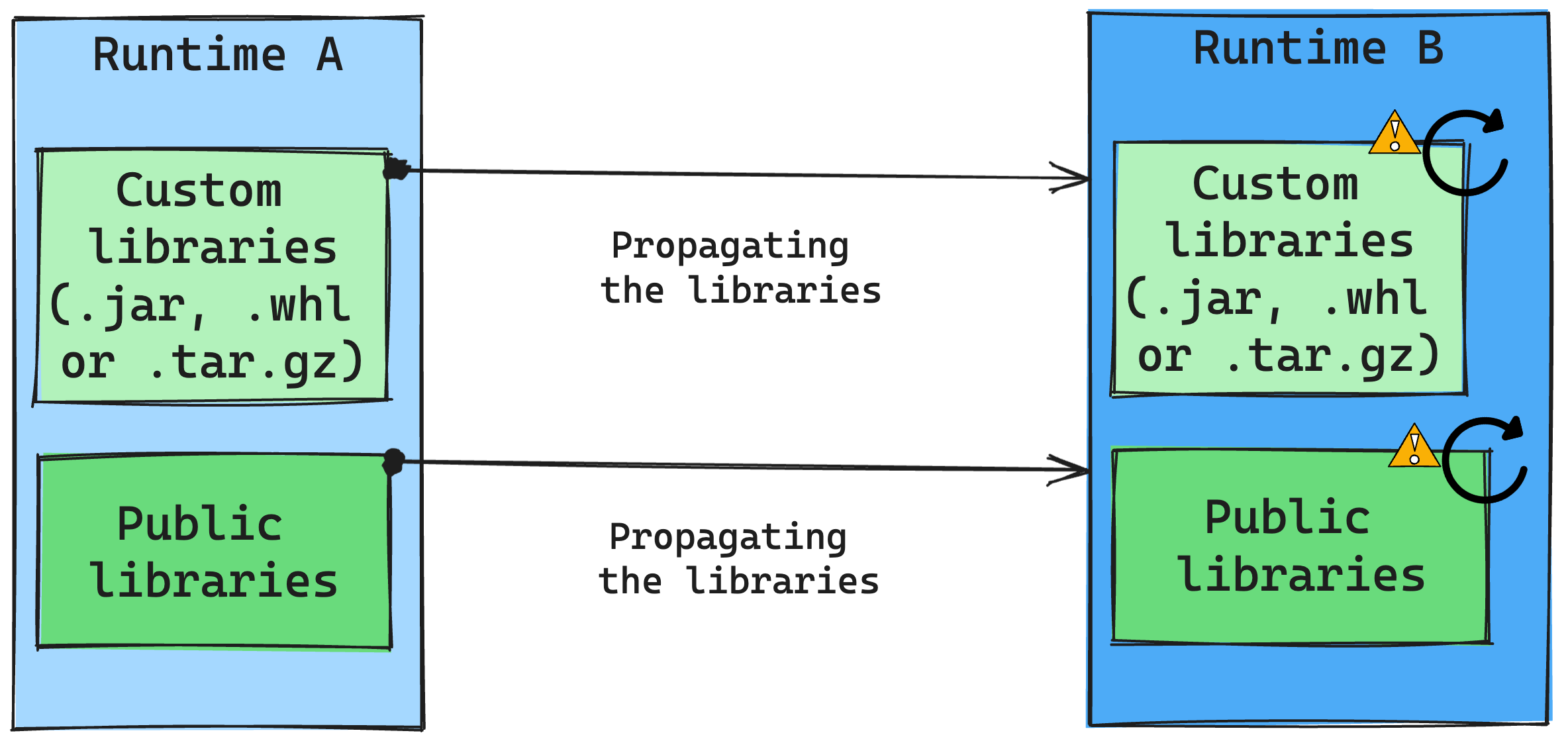
一般に、Microsoft のアプローチは、パブリック ランタイムとカスタム ランタイムの両方を含むすべてのライブラリをランタイム A からランタイム B に移行することです。 Python と R のバージョンが変更されていない場合、ライブラリは正しく機能するはずです。 ただし、Jars の場合、依存関係の変更や、Scala、Java、Spark、オペレーティング システムの変更などのその他の要因により、機能しなくなる可能性が非常に高くなります。
ランタイム B で動作しないライブラリの更新または置換は、ユーザーが行う必要があります。競合が発生した場合 (つまり、元々ランタイム A で定義されたライブラリがランタイム B に含まれている)、ライブラリ管理システムによって、ユーザーの設定に基づいてランタイム B に必要な依存関係を作成しようと試みられます。 しかし、競合が発生した場合、ビルド プロセスは失敗します。 エラー ログでは、競合の原因となっているライブラリを確認し、使用中のバージョンや仕様を調整できます。
Delta Lake プロトコルをアップグレードする
Delta Lake の機能は常に下位互換性があるため、Delta Lake の下位バージョンで作成されたテーブルは上位バージョンとシームレスに対話できます。 ただし、(たとえば、delta.upgradeTableProtocol(minReaderVersion, minWriterVersion) メソッドを使って) 特定の機能が有効になっている場合、下位バージョンの Delta Lake との上位互換性が損なわれる可能性があります。 そのような場合、互換性を維持する Delta Lake バージョンに合わせるために、アップグレードされたテーブルを参照するワークロードを変更することが重要です。
各 Delta テーブルは、サポートする機能を定義するプロトコル仕様に関連付けられています。 読み取りまたは書き込みのためにテーブルと対話するアプリケーションは、このプロトコル仕様を利用して、テーブルの機能セットと互換性があるかどうかを判断します。 アプリケーションが、テーブルのプロトコルでサポートされている機能を処理できない場合、そのテーブルに対して読み取りも書き込みも実行できません。
プロトコル仕様は、読み取りプロトコルと書き込みプロトコルという 2 つの個別のコンポーネントに分かれています。 詳細については、「How does Delta Lake manage feature compatibility」(Delta Lake で機能の互換性を管理する方法) のページを参照してください。

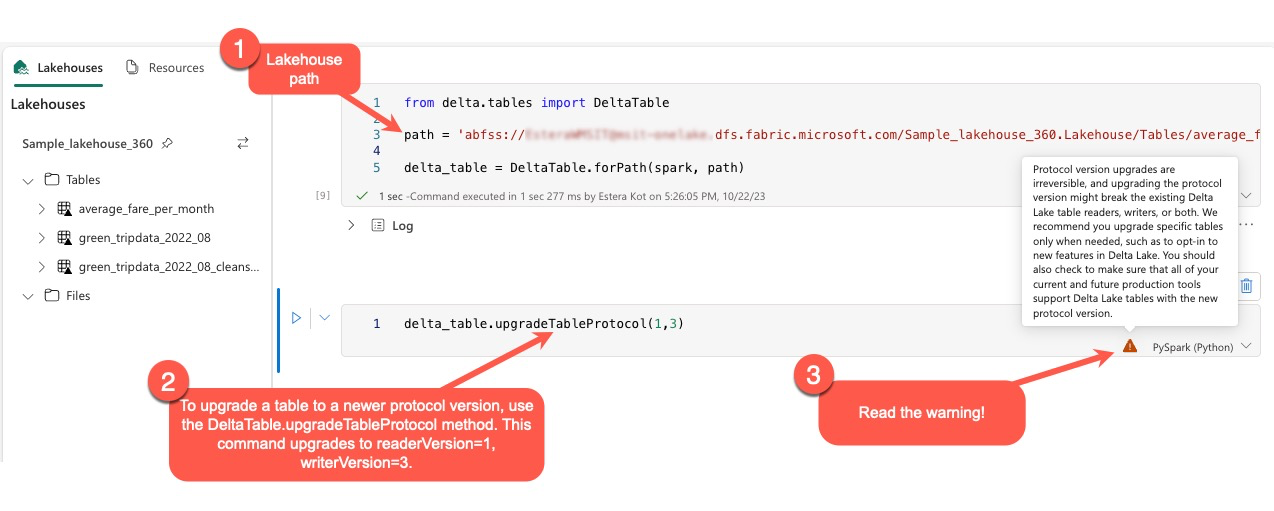
ユーザーは PySpark 環境、Spark SQL、Scala 内でコマンド delta.upgradeTableProtocol(minReaderVersion, minWriterVersion) を実行できます。 このコマンドにより、Delta テーブルの更新を開始することができます。
このアップグレードを実行するとき、Delta プロトコル バージョンのアップグレードは非可逆的なプロセスであることを示す警告がユーザーに表示されることに注意してください。 これは、更新が一度実行されると元に戻すことができないことを意味します。
プロトコル バージョンのアップグレードは、既存の Delta Lake テーブルの閲覧者、ライター、またはその両方の互換性に影響する可能性があります。 そのため、Delta Lake に新機能を採用する場合など、必要な場合にのみ、慎重にプロトコル バージョンをアップグレードすることをお勧めします。
さらに、ユーザーは、シームレスな移行を確実にし、潜在的な中断を防ぐために、現在と将来のすべての運用環境ワークロードとプロセスが、新規プロトコル バージョンを使っている Delta Lake テーブルと互換性があることを確認する必要があります。
Delta 2.2 と Delta 2.4 の変更
最新の Fabric Runtime, version 1.3 および Fabric Runtime, version 1.2 では、デフォルトのテーブル形式 (spark.sql.sources.default) は delta になりました。 以前のバージョンの Fabric Runtime バージョン 1.1、Spark 3.3 以前を含むすべての Synapse Runtime for Apache Spark では、デフォルトのテーブル形式は parquet と定義されていました。 Azure Synapse Analytics と Microsoft Fabric の違いについては、Apache Spark 構成の詳細を含むテーブルに関する記事を参照してください。
Spark SQL、PySpark、Scala Spark、Spark R を使って作成されたすべてのテーブルは、テーブルの種類が省略された場合、デフォルトで delta として作成されます。 スクリプトで明示的にテーブル形式を設定した場合は、それが尊重されます。 Spark のテーブル作成コマンドのコマンド USING DELTA は冗長になります。
Parquet テーブル形式を予想または想定しているスクリプトは修正する必要があります。 Delta テーブルでは、次のコマンドはサポートされていません。
ANALYZE TABLE $partitionedTableName PARTITION (p1) COMPUTE STATISTICSALTER TABLE $partitionedTableName ADD PARTITION (p1=3)ALTER TABLE DROP PARTITIONALTER TABLE RECOVER PARTITIONSALTER TABLE SET SERDEPROPERTIESLOAD DATAINSERT OVERWRITE DIRECTORYSHOW CREATE TABLECREATE TABLE LIKE