Azure HDInsight アクティビティを実行してデータを変換する
Data Factory for Microsoft Fabric の Azure HDInsight アクティビティでは、次のような Azure HDInsight ジョブタイプを調整できます。
- Hive クエリを実行する
- MapReduce プログラムを呼び出す
- Pig クエリを実行する
- Spark プログラムを実行する
- Hadoop Stream プログラムを実行する
この記事では、Data Factory インターフェイスを使用して Azure HDInsight アクティビティを作成するステップバイステップのチュートリアルを提供します。
前提条件
開始するには、次の前提条件を満たしている必要があります。
- アクティブなサブスクリプションが含まれるテナント アカウント。 無料でアカウントを作成できます。
- ワークスペースが作成されている。
UI を使用して Azure HDInsight (HDI) アクティビティをパイプラインに追加する
ワークスペースに新しいデータ パイプラインを作成します。
ホーム画面カードからAzure HDInsight を検索して選択するか、アクティビティ バーから [アクティビティ] を選択してパイプライン キャンバスに追加します。
ホーム画面のカードからアクティビティを作成:
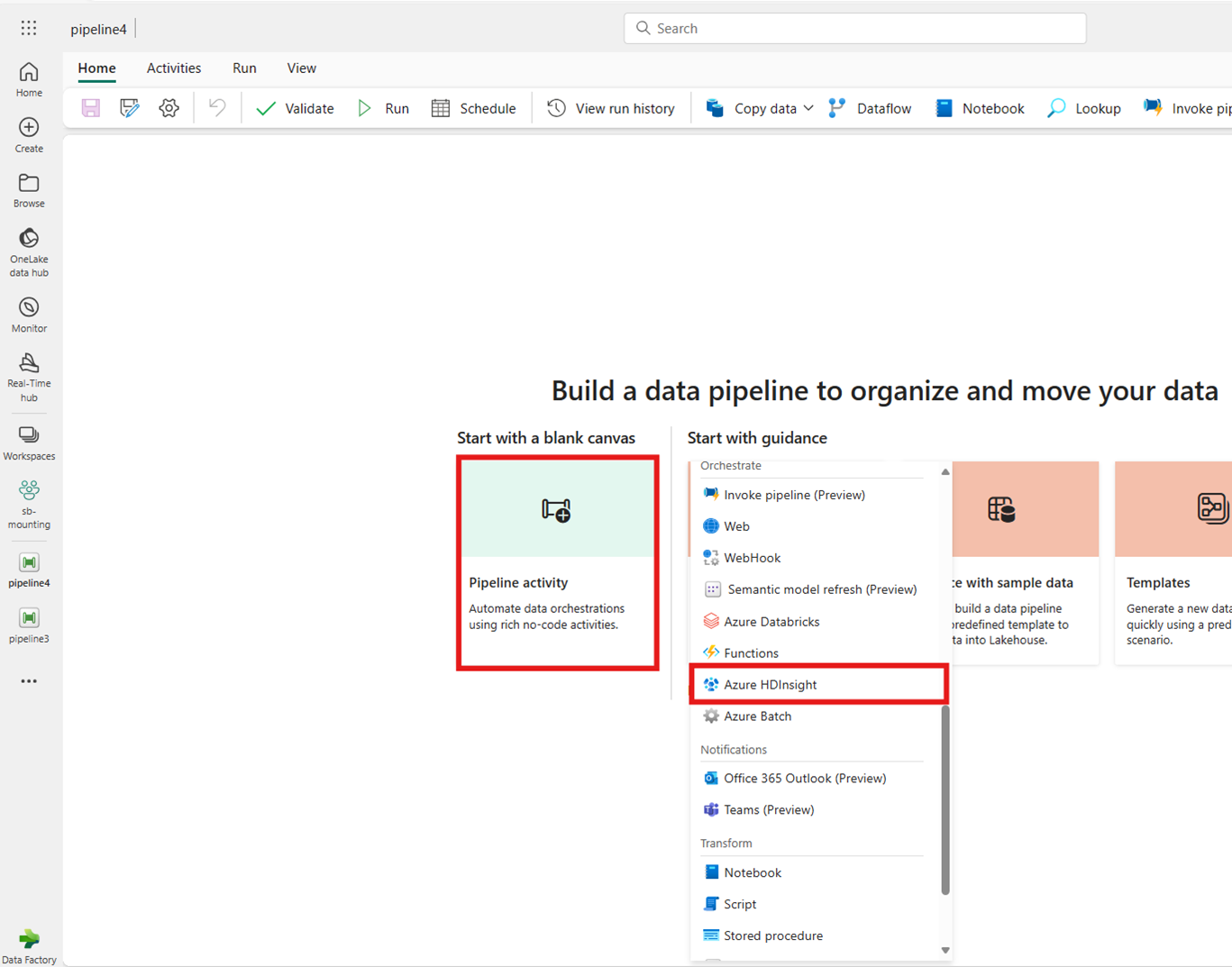
アクティビティバーからのアクティビティの作成:
![パイプライン エディター ウィンドウの [アクティビティ] バーから新しい Azure HDInsight アクティビティを作成する場所を示すスクリーンショット。](media/azure-hdinsight-activity/create-activity-from-activities-bar.png)
まだ選択されていない場合は、パイプライン エディターのキャンバスで新しい Azure HDInsight アクティビティを選択します。
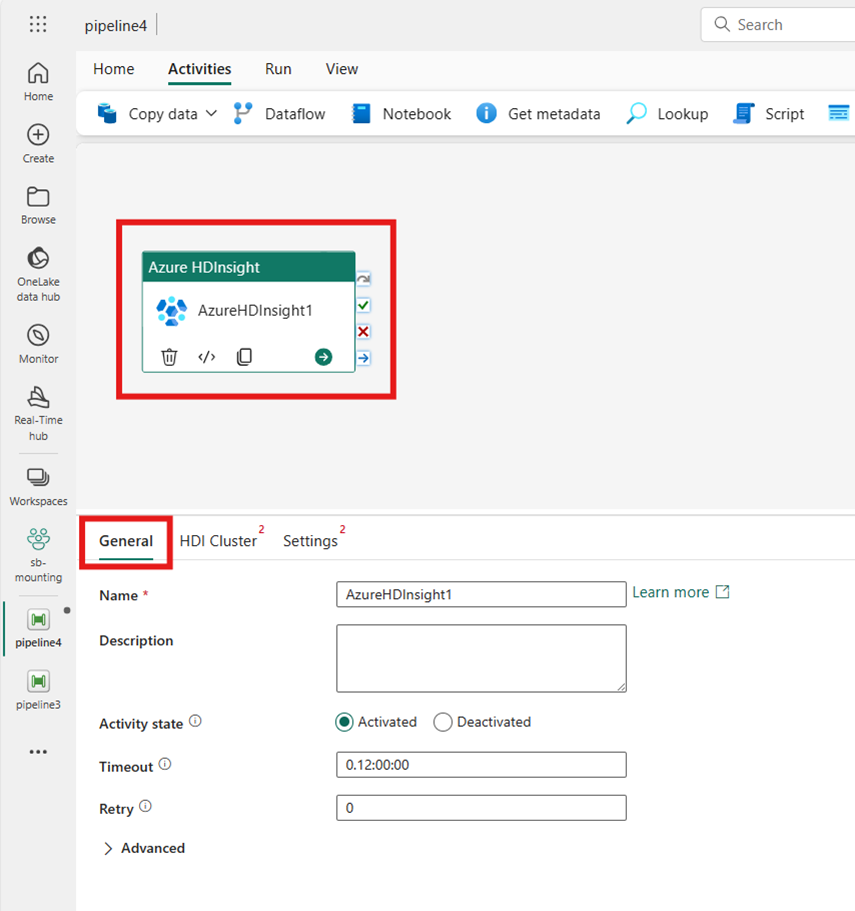
[全般設定] タブにあるオプションを構成するには、[全般設定] のガイダンスを参照してください。

HDI クラスターを構成する
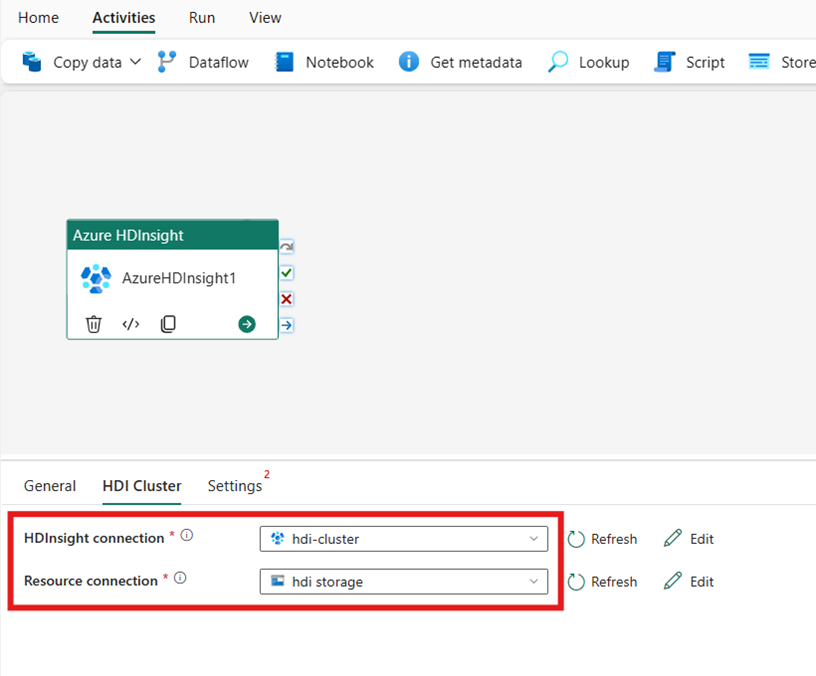
[HDI クラスター] タブを選択します。その後、既存の HDInsight 接続を選択するか、新しい [HDInsight 接続]を作成できます。
[リソース接続]では、Azure HDInsight クラスターを参照する Azure Blob Storage を選択します。 既存の Blob ストアを選択するか、または新しいものを作成できます。
設定の構成
[設定] タブを選択して、アクティビティの詳細設定を表示します。
![パイプライン エディター ウィンドウの Azure HDInsight アクティビティ プロパティの [設定] タブを示すスクリーンショット。](media/azure-hdinsight-activity/settings.png)
[Azure Data Factory および Synapse Analytics HDInsight のリンクされたサービス] でサポートされているすべての高度なクラスター プロパティと動的式は、UI の [詳細] セクションにおいて、Microsoft Fabric の Data Factory 用 Azure HDInsight アクティビティでもサポートされるようになりました。 これらのプロパティはすべて、動的コンテンツを含む使いやすくカスタム パラメーター化された式をサポートします。
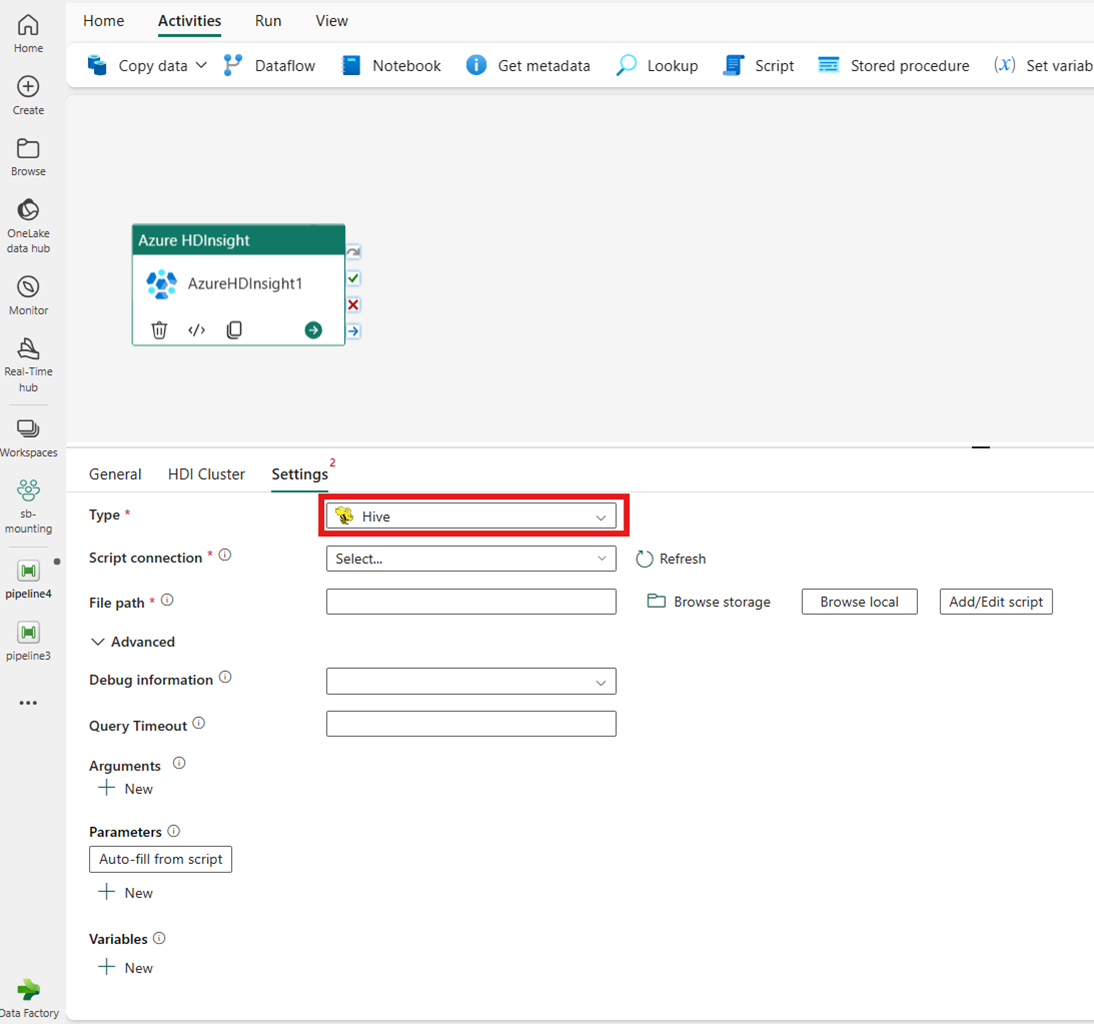
クラスターの種類
HDInsight クラスターの設定を行うには、まず、[Hive]、[Map Reduce]、[Pig]、[Spark]、[Streaming] などの使用可能なオプションからその[種類]を選択します。
Hive
[種類] として [Hive] を選択した場合、アクティビティは Hive クエリを実行します。 必要に応じて、Hive の種類を 保持するストレージ アカウントを参照する [スクリプト接続] を指定できます。 既定では、[HDI クラスター] タブで指定したストレージ接続が使用されます。 Azure HDInsight で実行する [ファイル パス] を指定する必要があります。 必要に応じて、[詳細設定] セクション、[デバッグ情報]、[クエリ タイムアウト]、[引数]、[パラメーター]、[変数] でさらに構成を指定できます。
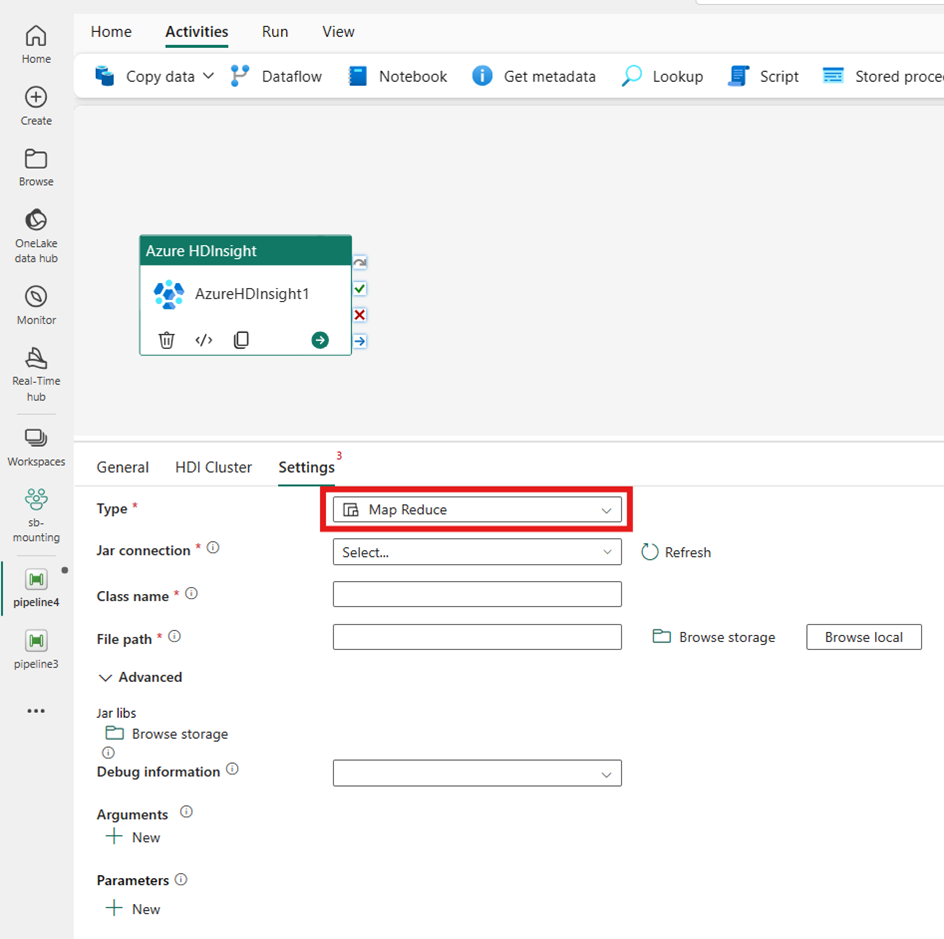
Map Reduce
[種類] に [Map Reduce] を選択すると、アクティビティによって Map Reduce プログラムが呼び出されます。 必要に応じて、Map Reduce の種類を保持するストレージ アカウントを参照する [Jar 接続] で指定できます。 既定では、[HDI クラスター] タブで指定したストレージ接続が使用されます。 Azure HDInsight で実行する [クラス名] および [ファイル パス] を指定する必要があります。 必要に応じて、Jar ライブラリのインポート、デバッグ情報、引数、パラメーターなど、詳細な構成の詳細を [詳細設定] セクションで指定できます。
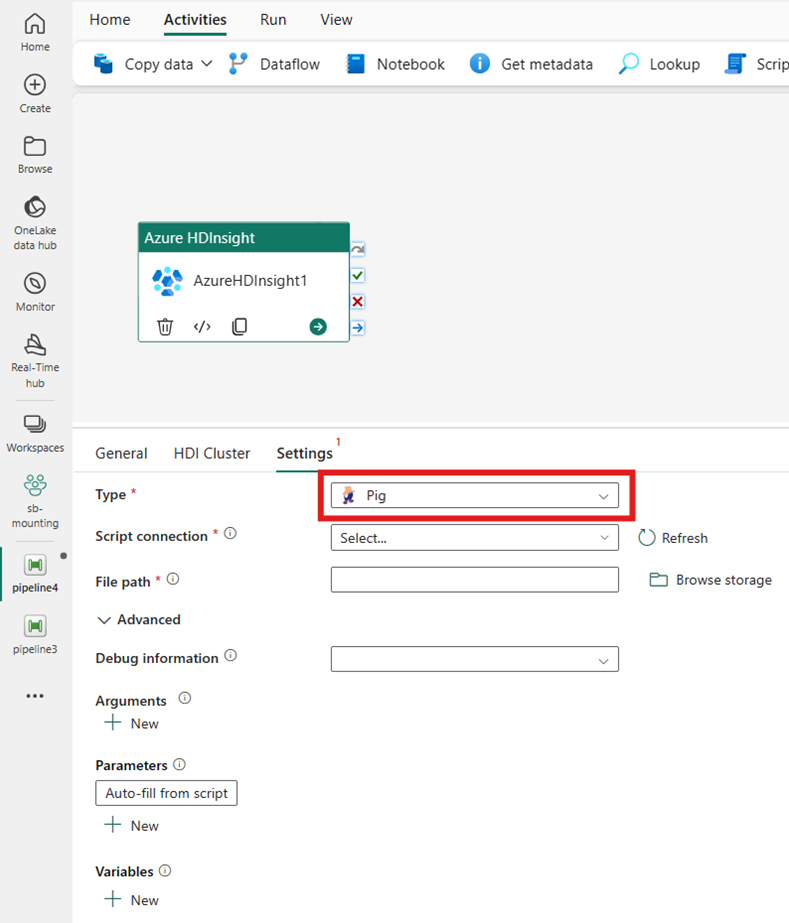
Pig
[種類] に [Pig] を選択すると、アクティビティによって Pig クエリが呼び出されます。 必要に応じて、Pig の種類を 保持するストレージ アカウントを参照する [スクリプト接続] 設定を指定できます。 既定では、[HDI クラスター] タブで指定したストレージ接続が使用されます。 Azure HDInsight で実行する [ファイル パス] を指定する必要があります。 必要に応じて、[詳細設定] セクションにて、[デバッグ情報]、[引数]、[パラメーター]、[変数] など、さらに構成を指定できます。
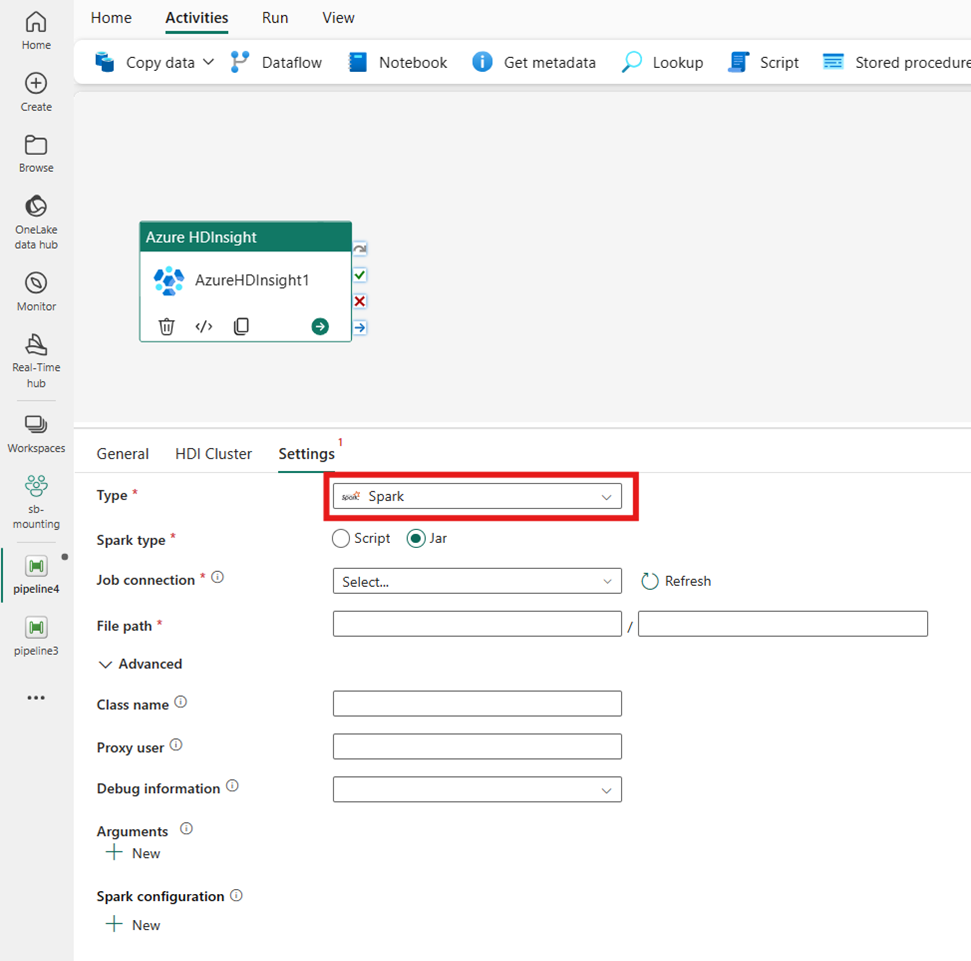
Spark
[種類] に [Spark] を選択すると、アクティビティによって Spark プログラムが呼び出されます。 [Spark の種類] として [スクリプト] または [Jar] を選択します。 必要に応じて、Spark の種類を 保持するストレージ アカウントを参照する [ジョブ接続] を指定できます。 既定では、[HDI クラスター] タブで指定したストレージ接続が使用されます。 Azure HDInsight で実行する [ファイル パス] を指定する必要があります。 必要に応じて、[詳細設定] セクションで、クラス名、プロキシ ユーザー、デバッグ情報、引数、Spark 構成などの追加の構成を指定できます。
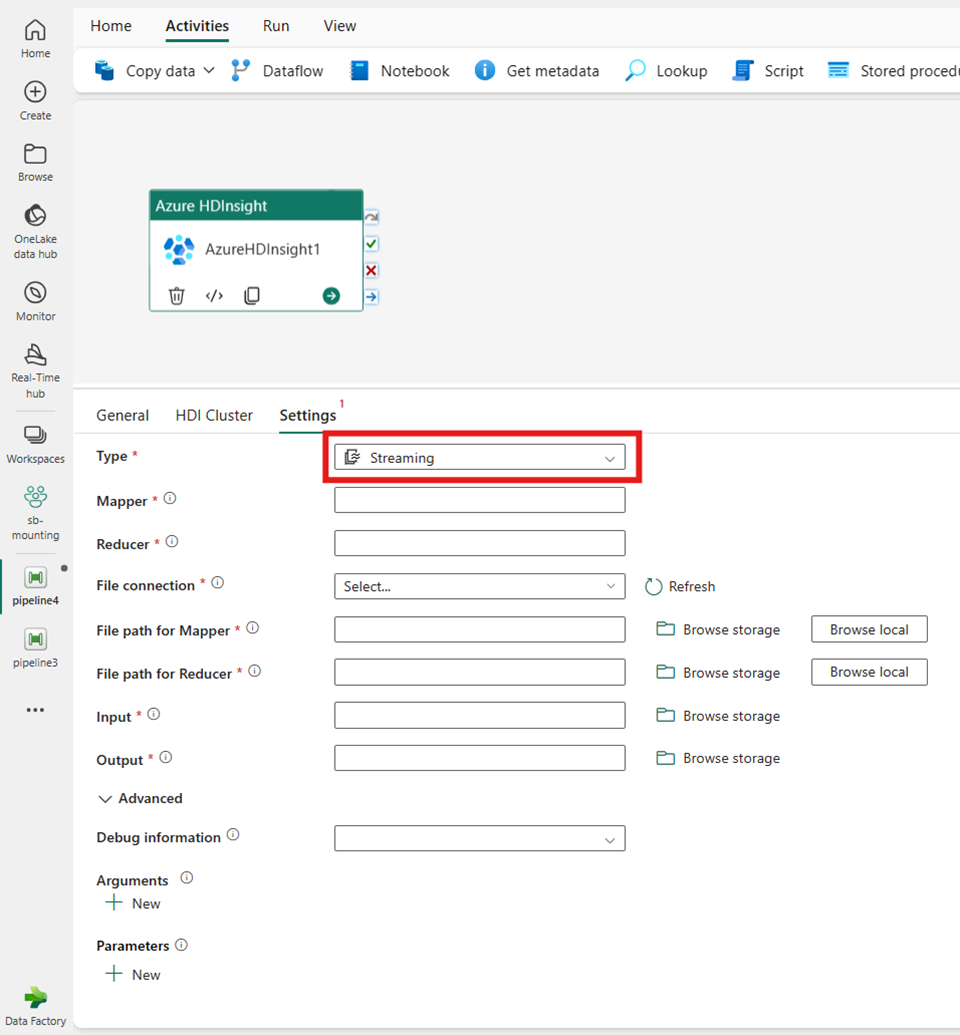
ストリーミング
[種類] に [ストリーミング] を選択すると、アクティビティによってストリーミング プログラムが呼び出されます。 [Mapper] と [Reducer] の名前を指定します。必要に応じて、ストリーミングの種類を保持するストレージ アカウントを参照する [ファイル接続] を指定できます。 既定では、[HDI クラスター] タブで指定したストレージ接続が使用されます。 Azure HDInsight で実行する [Mapper 用のファイル パス] と[Reducer 用のファイル パス]を指定する必要があります。 WASB パスの [入力] オプションと [出力] オプションも含めます。 必要に応じて、[詳細設定] セクションにて、[デバッグ情報]、[引数]、[パラメーター] など、さらに構成を指定できます。
プロパティ リファレンス
| プロパティ | 内容 | 必須 |
|---|---|---|
| type | Hadoop Streaming アクティビティの場合、アクティビティの種類は HDInsightStreaming です。 | はい |
| mapper | mapper 実行可能ファイルの名前を指定します。 | はい |
| reducer | reducer 実行可能ファイルの名前を指定します。 | はい |
| combiner | combiner 実行可能ファイルの名前を指定します。 | いいえ |
| file connection | 実行されるマッパー、コンバイナー、レジューサの各プログラムを格納するために使用される Azure Storage のリンクされたサービスへの参照。 | いいえ |
| ここでは Azure Blob Storage および ADLS Gen2 の接続のみがサポートされています。 この接続を指定しない場合は、HDInsight 接続で定義されているストレージ接続が使用されます。 | ||
| filePath | ファイル接続によって参照される、Azure Storage に格納された マッパー、コンバイナー、レジューサ の各プログラムのパスの配列を指定します。 | はい |
| input | マッパーの入力ファイルの WASB パスを指定します。 | はい |
| output | レジューサの出力ファイルの WASB パスを指定します。 | はい |
| getDebugInfo | HDInsight クラスターで使用されている Azure Storage または scriptLinkedService で指定された Azure Storage にログ ファイルがコピーされるタイミングを指定します。 | いいえ |
| 使用できる値は以下の通りです。None、Always、または Failure。 既定値:[なし] : | ||
| arguments | Hadoop ジョブの引数の配列を指定します。 引数はコマンド ライン引数として各タスクに渡されます。 | いいえ |
| defines | Hive スクリプト内で参照するキーと値のペアとしてパラメーターを指定します。 | いいえ |
パイプラインを保存して実行またはスケジュールする
パイプラインに必要なその他のアクティビティを構成したら、パイプライン エディターの上部にある [ホーム] タブに切り替え、[保存] ボタンを選択してパイプラインを保存します。 [実行] を選択して直接実行するか、[スケジュール] を選択してスケジュールを設定します。 ここで実行履歴を表示したり、他の設定を構成したりすることもできます。
![[保存]、[実行]、[スケジュール] ボタンが強調されている、パイプライン エディターの [ホーム] タブのスクリーンショット。](media/azure-hdinsight-activity/save-run-schedule.png)