Dataflow Gen2 の高速コピー
この記事では、Microsoft Fabric の Data Factory 用 Dataflow Gen2 の高速コピー機能について説明します。 データフローは、データの取り込みと変換を支援します。 SQL DW コンピューティングを使用したデータフロー スケール アウトの導入により、データを大規模に変換できます。 ただし、最初にデータを取り込む必要があります。 高速コピーを導入すると、データフローの簡単なエクスペリエンスによってテラバイト単位のデータを取り込むことができますが、パイプライン コピー アクティビティのスケーラブルなバックエンドを使用します。
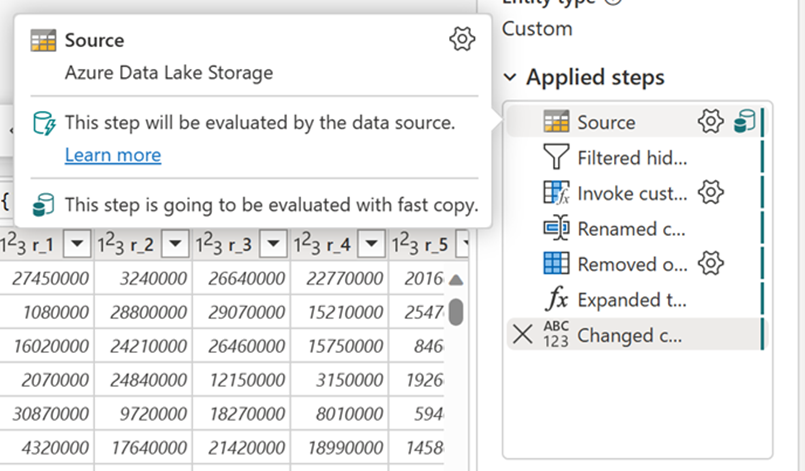
この機能を有効にすると、データ サイズが特定のしきい値を超えたとき、データフローはバックエンドを自動的に切り替えます。データフローの作成中に何も変更する必要はありません。 データフローの更新後、更新履歴をチェックして表示されるエンジンの種類を調べることで、実行中に高速コピーが使用されたかどうかを確認できます。
高速コピーが必要オプションを有効にすると、高速コピーが使用されていない場合、データフローの更新はキャンセルされます。 更新タイムアウトが続くのを待つことを避けられるようにします。 この動作はデバッグ セッションで待機時間を短縮しながらデータフロー動作をデータでテストするときにも役立ちます。 クエリ手順ウィンドウの高速コピー インジケーターを使用すると、高速コピーでクエリを実行できるかどうかを簡単に確認できます。
前提条件
- Fabric 容量が必要です。
- ファイル データの場合、ファイルは少なくとも 100 MB (メガバイト) の .csvまたは Parquet 形式で、Azure Data Lake Storage (ADLS) Gen2 または BLOB ストレージ アカウントに格納されます。
- Azure SQL DB とPostgreSQL の場合、データ ソース内の 500 万行以上のデータ。
Note
[高速コピーが必要] 設定を選択すると、しきい値をバイパスして高速コピーを強制できます。
コネクタのサポート
現在、高速コピーは次の Dataflow Gen2 コネクタでサポートされています。
- ADLS Gen2
- Blob Storage
- Azure SQL DB
- レイクハウス
- PostgreSQL
- オンプレミスの SQL Server
ファイル ソースに接続するとき、コピー アクティビティはいくつかの変換のみをサポートします。
- ファイルの結合
- 列を選択する
- データ型を変更する
- 列の名前変更
- 列の削除
インジェストと変換の手順を個別のクエリに分割することにより、他の変換を適用することができます。 最初のクエリは実際にデータを取得し、2 番目のクエリはその結果を参照して DW コンピューティングを使用できるようにします。 SQL ソースの場合、ネイティブ クエリの一部であるすべての変換がサポートされます。
出力先にクエリを直接読み込む場合、現在サポートされているのは Lakehouse 出力先のみです。 別の出力先を使用する場合、最初にクエリをステージングして後で参照することができます。
高速コピーを使用する方法
適切な Fabric エンドポイントに移動します。
Premium ワークスペースに移動し、Dataflow Gen2 を作成します。
新規データフローの [ホーム] タブで、[オプション] を選択します。
![[ホーム] タブで Dataflow Gen2 の [オプション] を選択する位置を示すスクリーンショット。](media/dataflows-gen2-fast-copy/options.png)
次に、[オプション] ダイアログで [スケール] タブを選択し、[高速コピー コネクタの使用を許可する] チェックボックスを選択し、高速コピーを有効にします。 次に、[オプション] ダイアログを閉じます。
![[オプション] ダイアログの [スケール] タブで高速コピーを有効にする位置を示すスクリーンショット。](media/dataflows-gen2-fast-copy/enable-fast-copy.png)
[データの取得] を選択したら、ADLS Gen2 ソースを選択してコンテナーの詳細を入力します。
[ファイルの結合] 機能を使用します。
![[結合] オプションが強調表示された [フォルダー データのプレビュー] ウィンドウを示すスクリーンショット。](media/dataflows-gen2-fast-copy/preview-folder-data.png)
高速コピーを確実に行うには、この記事の「コネクタのサポート」セクションに記載されている変換のみを適用します。 変換の適用を追加する必要がある場合、最初にデータをステージングして後でクエリを参照します。 参照先のクエリに他の変換を行います。
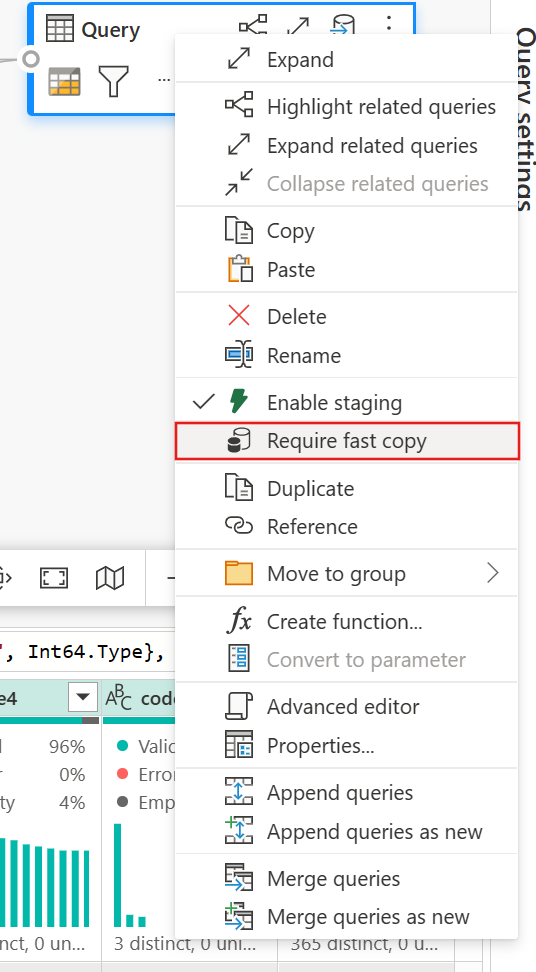
(省略可能) [高速コピーが必要] オプションを右クリックして選択し、クエリに設定して有効にできます。
(省略可能) 現在、出力先として Lakehouse のみを構成できます。 その他の出力先については、クエリをステージングし、後で任意のソースに出力できる別のクエリで参照します。
高速コピー インジケーターを確認し、高速コピーでクエリを実行できるかどうかを確認します。 その場合、エンジンの種類には CopyActivity が表示されます。

データフローを発行します。
更新が完了したら、高速コピーが使用されたことを確認します。
![[結合] オプションが強調表示された [フォルダー データのプレビュー] ウィンドウを示すスクリーンショット。](media/dataflows-gen2-fast-copy/preview-folder-data.png#lightbox)