チュートリアル パート 3: 機械学習モデルをトレーニングして登録する
このチュートリアルでは、離れる可能性の高い銀行顧客を予測するために、複数の機械学習モデルをトレーニングして最適なものを選ぶ方法について学習します。
このチュートリアルでは、次のことについて説明します。
- ランダム フォレストと LightGBM モデルをトレーニングします。
- Microsoft Fabric の MLflow フレームワークとのネイティブ統合を使用して、トレーニング済みの機械学習モデル、使用されたハイパーパラメーター、評価メトリックをログに記録する。
- トレーニング済みの機械学習モデルを登録する。
- 検証データセットでトレーニング済みの機械学習モデルのパフォーマンスを評価する。
MLflow は、追跡、モデル、モデル レジストリなどの機能を使用して機械学習のライフサイクルを管理するためのオープン ソース プラットフォームです。 MLflow は、Fabric Data Science エクスペリエンスとネイティブに統合されています。
前提条件
Microsoft Fabric サブスクリプションを取得します。 または、無料の Microsoft Fabric 試用版にサインアップします。
Microsoft Fabric にサインインします。
ホーム ページの左側にある環境スイッチャーを使って、Synapse Data Science 環境に切り替えます。
![[エクスペリエンス スイッチャー メニュー] で Data Science を選択するところを示すスクリーンショット。](media/tutorial-data-science-prepare-system/switch-to-data-science.png)
これは、5 部構成チュートリアル シリーズの第 3 部です。 このチュートリアルを完了するには、最初に次の手順を完了します。
- パート 1: Apache Spark を使用して Microsoft Fabric レイクハウスにデータを取り込む。
- パート 2: Microsoft Fabric ノートブックを使用してデータを探索して視覚化し、データの詳細を確認する。
ノートブックで作業を進める
3-train-evaluate.ipynb は、このチュートリアルに付属するノートブックです。
このチュートリアルに付随するノートブックを開くには、「データ サイエンス用にシステムを準備する」チュートリアル の手順に従い、ノートブックをお使いのワークスペースにインポートします。
このページからコードをコピーして貼り付ける場合は、[新しいノートブックを作成する] ことができます。
コードの実行を開始する前に、必ずレイクハウスをノートブックにアタッチしてください。
重要
パート 1 とパート 2 で使用したのと同じレイクハウスをアタッチします。
カスタム ライブラリをインストールする
このノートブックでは、%pip install を使用して、imbalanced-learn (imblearn としてインポート) をインストールします。 imbalanced-learn は、不均衡なデータセットを処理するときに使用される SMOTE (Synthetic Minority Oversampling Technique) のライブラリです。 PySpark カーネルは %pip install の後に再起動されるため、他のセルを実行する前にライブラリをインストールする必要があります。
imblearn ライブラリを使用して、SMOTE にアクセスします。 ここでは、インライン インストール機能 (%pip、%conda など) を使用してインストールします。
# Install imblearn for SMOTE using pip
%pip install imblearn
重要
このインストールは、ノートブックを再起動するたびに実行します。
ノートブックにライブラリをインストールする場合、そのライブラリはノートブックのセッション中のみ使用でき、ワークスペースでは利用できません。 ノートブックを再起動した場合は、ライブラリをもう一度インストールする必要があります。
よく使用するライブラリがあり、ワークスペース内のすべてのノートブックで使用できるようにする場合は、その目的に Fabric 環境を使用できます。 環境を作成してライブラリをインストールすると、ワークスペース管理者は既定の環境としてワークスペースに環境をアタッチできます。 ワークスペースの既定値として環境を設定する方法の詳細については、管理者がワークスペースの既定のライブラリを設定するに関する記事を参照してください。
既存のワークスペース ライブラリと Spark プロパティを環境に移行する方法については、「ワークスペース ライブラリと Spark プロパティを既定の環境に移行する」を参照してください。
データの読み込み
機械学習モデルをトレーニングする前に、前のノートブックで作成したクリーンアップされたデータを読み取るために、レイクハウスからデルタ テーブルを読み込む必要があります。
import pandas as pd
SEED = 12345
df_clean = spark.read.format("delta").load("Tables/df_clean").toPandas()
MLflow を使用したモデルの追跡とログ記録のための実験を生成する
このセクションでは、実験の生成、機械学習モデルとトレーニングのパラメーターの指定、メトリックのスコア付け、機械学習モデルのトレーニング、ログ記録、後で使用するためにトレーニング済みのモデルの保存を行う方法について説明します。
import mlflow
# Setup experiment name
EXPERIMENT_NAME = "bank-churn-experiment" # MLflow experiment name
MLflow 自動ログ機能を拡張すると、トレーニング中の機械学習モデルの入力パラメーターと出力メトリックの値を自動的にキャプチャすることによって自動ログ機能が機能します。 その後、この情報はワークスペースに記録され、MLflow API またはワークスペース内の対応する実験を使用してアクセスおよび視覚化できます。
それぞれの名前が付いたすべての実験がログに記録され、パラメーターとパフォーマンス メトリックを追跡できます。 自動ログ機能の詳細については、「Microsoft Fabric での自動ログ記録」を参照してください。
実験と自動ログ機能の仕様を設定する
mlflow.set_experiment(EXPERIMENT_NAME)
mlflow.autolog(exclusive=False)
scikit-learn と LightGBM をインポートする
データを配置したので、機械学習モデルを定義できるようになりました。 このノートブックでは、ランダム フォレストと LightGBM の各モデルを適用します。 scikit-learn と lightgbm を使用して、数行のコード内でモデルを実装します。
# Import the required libraries for model training
from sklearn.model_selection import train_test_split
from lightgbm import LGBMClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, f1_score, precision_score, confusion_matrix, recall_score, roc_auc_score, classification_report
トレーニング、検証、テストのデータセットを準備する
scikit-learn の train_test_split 関数を使用して、データをトレーニング、検証、およびテスト セットに分割します。
y = df_clean["Exited"]
X = df_clean.drop("Exited",axis=1)
# Split the dataset to 60%, 20%, 20% for training, validation, and test datasets
# Train-Test Separation
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=SEED)
# Train-Validation Separation
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.25, random_state=SEED)
テスト データをデルタ テーブルに保存する
次のノートブックで使用するために、テスト データをデルタ テーブルに保存します。
table_name = "df_test"
# Create PySpark DataFrame from Pandas
df_test=spark.createDataFrame(X_test)
df_test.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark test DataFrame saved to delta table: {table_name}")
SMOTE をトレーニング データに適用して、マイノリティ クラスの新しいサンプルを合成する
パート 2 のデータ探索では、10,000 人の顧客に対応する 10,000 個のデータ ポイントのうち、銀行を離れた顧客は 2,037 人 (約 20%) に過ぎないことがわかりました。 これは、データセットが非常に不均衡であることを示します。 不均衡な分類の問題は、モデルが決定境界を効果的に学習するには、少数派クラスの例が少なすぎることです。 SMOTE は、マイノリティ クラスの新しいサンプルを合成するために最も広く使用されているアプローチです。 SMOTE の詳細については、こちらとこちらを参照してください。
ヒント
SMOTE はトレーニング データセットにのみ適用する必要があることに注意してください。 運用環境の状況を表す元のデータに対する機械学習モデルのパフォーマンスの有効な近似を得るには、テスト データセットを元の不均衡な分布のままにしておく必要があります。
from collections import Counter
from imblearn.over_sampling import SMOTE
sm = SMOTE(random_state=SEED)
X_res, y_res = sm.fit_resample(X_train, y_train)
new_train = pd.concat([X_res, y_res], axis=1)
ヒント
このセルの実行時に表示される MLflow 警告メッセージは、無視しても問題ありません。
ModuleNotFoundError メッセージが表示された場合は、imblearn ライブラリをインストールする、このノートブックの最初のセルが実行されていません。 ノートブックを再起動するたびにこのライブラリをインストールする必要があります。 前に戻って、このノートブックの最初のセルから始めて、すべてのセルを再実行します。
モデル トレーニング
- 最大深度が 4 で 4 つの特徴を持つランダム フォレストを使用して、モデルをトレーニングする
mlflow.sklearn.autolog(registered_model_name='rfc1_sm') # Register the trained model with autologging
rfc1_sm = RandomForestClassifier(max_depth=4, max_features=4, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc1_sm") as run:
rfc1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc1_sm_run_id, run.info.status))
# rfc1.fit(X_train,y_train) # Imbalanaced training data
rfc1_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc1_sm.score(X_val, y_val)
y_pred = rfc1_sm.predict(X_val)
cr_rfc1_sm = classification_report(y_val, y_pred)
cm_rfc1_sm = confusion_matrix(y_val, y_pred)
roc_auc_rfc1_sm = roc_auc_score(y_res, rfc1_sm.predict_proba(X_res)[:, 1])
- 最大深度が 8 で 6 つの特徴を持つランダム フォレストを使用して、モデルをトレーニングする
mlflow.sklearn.autolog(registered_model_name='rfc2_sm') # Register the trained model with autologging
rfc2_sm = RandomForestClassifier(max_depth=8, max_features=6, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc2_sm") as run:
rfc2_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc2_sm_run_id, run.info.status))
# rfc2.fit(X_train,y_train) # Imbalanced training data
rfc2_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc2_sm.score(X_val, y_val)
y_pred = rfc2_sm.predict(X_val)
cr_rfc2_sm = classification_report(y_val, y_pred)
cm_rfc2_sm = confusion_matrix(y_val, y_pred)
roc_auc_rfc2_sm = roc_auc_score(y_res, rfc2_sm.predict_proba(X_res)[:, 1])
- LightGBM を使用してモデルをトレーニングする
# lgbm_model
mlflow.lightgbm.autolog(registered_model_name='lgbm_sm') # Register the trained model with autologging
lgbm_sm_model = LGBMClassifier(learning_rate = 0.07,
max_delta_step = 2,
n_estimators = 100,
max_depth = 10,
eval_metric = "logloss",
objective='binary',
random_state=42)
with mlflow.start_run(run_name="lgbm_sm") as run:
lgbm1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
# lgbm_sm_model.fit(X_train,y_train) # Imbalanced training data
lgbm_sm_model.fit(X_res, y_res.ravel()) # Balanced training data
y_pred = lgbm_sm_model.predict(X_val)
accuracy = accuracy_score(y_val, y_pred)
cr_lgbm_sm = classification_report(y_val, y_pred)
cm_lgbm_sm = confusion_matrix(y_val, y_pred)
roc_auc_lgbm_sm = roc_auc_score(y_res, lgbm_sm_model.predict_proba(X_res)[:, 1])
モデルのパフォーマンスを追跡するための実験成果物
実験の実行は、実験成果物に自動的に保存されます。これは、ワークスペースから見つけることができます。 これらは、実験の設定に使用される名前に基づいて名前が付けられます。 トレーニング済みのすべての機械学習モデル、それらの実行、パフォーマンス メトリック、モデル パラメーターがログに記録されます。
実験を表示するには:
左側のパネルで、ワークスペースを選択します。
右上でフィルター処理してテストのみを表示し、探しているテストを簡単に見つけられるようにします。

実験名 (この場合は、bank-churn-experiment) を見つけて選択します。 ワークスペースに実験が表示されない場合は、ブラウザーを更新します。



検証データセットでトレーニング済みモデルのパフォーマンスを評価する
機械学習モデルのトレーニングが完了したら、トレーニング済みのモデルのパフォーマンスを 2 つの方法で評価できます。
ワークスペースから保存した実験を開き、機械学習モデルを読み込み、読み込まれたモデルのパフォーマンスを検証データセットで評価する。
# Define run_uri to fetch the model # mlflow client: mlflow.model.url, list model load_model_rfc1_sm = mlflow.sklearn.load_model(f"runs:/{rfc1_sm_run_id}/model") load_model_rfc2_sm = mlflow.sklearn.load_model(f"runs:/{rfc2_sm_run_id}/model") load_model_lgbm1_sm = mlflow.lightgbm.load_model(f"runs:/{lgbm1_sm_run_id}/model") # Assess the performance of the loaded model on validation dataset ypred_rfc1_sm_v1 = load_model_rfc1_sm.predict(X_val) # Random Forest with max depth of 4 and 4 features ypred_rfc2_sm_v1 = load_model_rfc2_sm.predict(X_val) # Random Forest with max depth of 8 and 6 features ypred_lgbm1_sm_v1 = load_model_lgbm1_sm.predict(X_val) # LightGBM検証データセットでトレーニング済みの機械学習モデルのパフォーマンスを直接評価する。
ypred_rfc1_sm_v2 = rfc1_sm.predict(X_val) # Random Forest with max depth of 4 and 4 features ypred_rfc2_sm_v2 = rfc2_sm.predict(X_val) # Random Forest with max depth of 8 and 6 features ypred_lgbm1_sm_v2 = lgbm_sm_model.predict(X_val) # LightGBM
好みに応じて、どちらの方法を選んでもかまいません。どちらでも同じパフォーマンスが得られるはずです。 このノートブックでは、Microsoft Fabric の MLflow 自動ログ機能をより適切に示すために、最初の方法を選びます。
混同行列を使用して、真陽性、真陰性、偽陽性、偽陰性を表示する
次に、検証データセットを使用して分類の精度を評価するために、混同行列をプロットするスクリプトを開発します。 混同行列は、SynapseML ツールを使用してプロットすることもできます。これは、ここで入手できる不正検出サンプルに示されています。
import seaborn as sns
sns.set_theme(style="whitegrid", palette="tab10", rc = {'figure.figsize':(9,6)})
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
from matplotlib import rc, rcParams
import numpy as np
import itertools
def plot_confusion_matrix(cm, classes,
normalize=False,
title='Confusion matrix',
cmap=plt.cm.Blues):
print(cm)
plt.figure(figsize=(4,4))
plt.rcParams.update({'font.size': 10})
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45, color="blue")
plt.yticks(tick_marks, classes, color="blue")
fmt = '.2f' if normalize else 'd'
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt),
horizontalalignment="center",
color="red" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
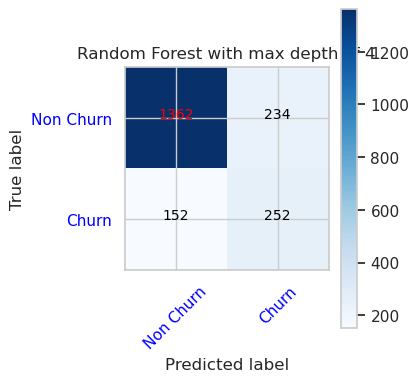
- 最大深度が 4 で 4 つの特徴を持つランダム フォレスト分類子の混同行列
cfm = confusion_matrix(y_val, y_pred=ypred_rfc1_sm_v1)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 4')
tn, fp, fn, tp = cfm.ravel()
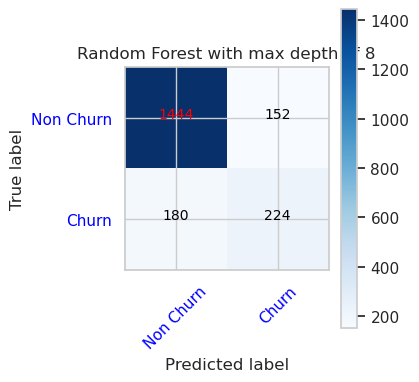
- 最大深度が 8 で 6 つの特徴を持つランダム フォレスト分類子の混同行列
cfm = confusion_matrix(y_val, y_pred=ypred_rfc2_sm_v1)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 8')
tn, fp, fn, tp = cfm.ravel()
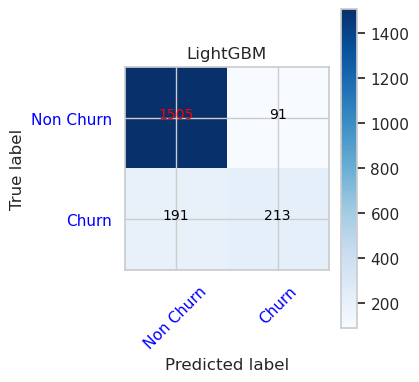
- LightGBM の混同行列
cfm = confusion_matrix(y_val, y_pred=ypred_lgbm1_sm_v1)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='LightGBM')
tn, fp, fn, tp = cfm.ravel()