Apache Spark を使用してデータを変換し、SQL を使用してクエリを実行する
このガイドで行うこと:
OneLake ファイル エクスプローラーを使用して OneLake にデータをアップロードします。
Fabric ノートブックを使用して OneLake 上のデータを読み取り、Delta テーブルとして書き戻します。
Fabric ノートブックを使用して Spark でデータを分析および変換します。
SQL を使用して OneLake 上のデータの 1 つのコピーに対してクエリを実行します。
前提条件
開始する前に、次の操作を行う必要があります。
OneLake エクスプローラーをダウンロードしてインストールします。
レイクハウス項目を含むワークスペースを作成します。
WideWorldImportersDW データセットをダウンロードします。 Azure Storage Explorer を使用して
https://azuresynapsestorage.blob.core.windows.net/sampledata/WideWorldImportersDW/csv/full/dimension_cityに接続し、csv ファイルのセットをダウンロードできます。 あるいは、独自の csv データを使用し、必要に応じて詳細を更新することもできます。
Note
レイクハウスの [テーブル] セクションの "すぐ" 下に、Delta-Parquet データ ショートカットを作成、読み込み、または作成します。 [テーブル] セクションの下のサブフォルダーにテーブルを入れ子にしないでください。レイクハウスでテーブルとして認識されず、"不明" としてラベル付けされてしまうためです。
データのアップロード、読み取り、分析、クエリ
OneLake エクスプローラーで、レイクハウスに移動し、
/Filesディレクトリの下にdimension_cityという名前のサブディレクトリを作成します。
OneLake エクスプローラーを使用して、サンプルの csv ファイルを OneLake ディレクトリ
/Files/dimension_cityにコピーします。
Power BI サービスで Lakehouse に移動し、ファイルを表示します。
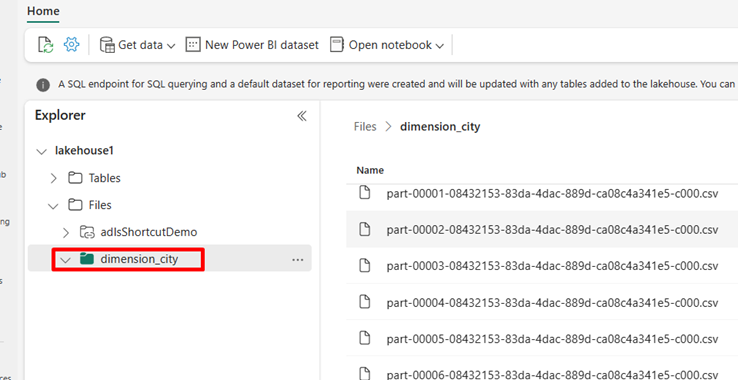
[ノートブックを開く] を選択し、[新しいノートブック] を選択してノートブックを作成します。
Fabric ノートブックを使用して、csv ファイルを Delta 形式に変換します。 次のコード スニペットは、ユーザーが作成したディレクトリ
/Files/dimension_cityからデータを読み取り、Delta テーブルdim_cityに変換します。import os from pyspark.sql.types import * for filename in os.listdir("/lakehouse/default/Files/<replace with your folder path>"): df=spark.read.format('csv').options(header="true",inferSchema="true").load("abfss://<replace with workspace name>@onelake.dfs.fabric.microsoft.com/<replace with item name>.Lakehouse/Files/<folder name>/"+filename,on_bad_lines="skip") df.write.mode("overwrite").format("delta").save("Tables/<name of delta table>")新しいテーブルを表示するには、
/Tablesディレクトリのビューを更新します。
同じ Fabric ノートブック内で SparkSQL を使用してテーブルのクエリを実行します。
%%sql SELECT * from <replace with item name>.dim_city LIMIT 10;整数データ型を持つ newColumn という名前の新しい列を追加して、Delta テーブルを変更します。 この新しく追加された列のすべてのレコードの値を 9 に設定します。
%%sql ALTER TABLE <replace with item name>.dim_city ADD COLUMN newColumn int; UPDATE <replace with item name>.dim_city SET newColumn = 9; SELECT City,newColumn FROM <replace with item name>.dim_city LIMIT 10;また、SQL 分析エンドポイントを介して OneLake 上の任意の Delta テーブルにアクセスすることもできます。 この SQL 分析エンドポイントは、OneLake 上の Delta テーブルの同じ物理コピーを参照し、T-SQL エクスペリエンスを提供します。 lakehouse1 の SQL 分析エンドポイントを選択し、[新しい SQL クエリ] を選択して T-SQL を使用してテーブルに対してクエリを実行します。
SELECT TOP (100) * FROM [<replace with item name>].[dbo].[dim_city];
