Azure Event Hubs からデータを取得する
この記事では、Event Hubs から Microsoft Fabric の KQL データベースにデータを取得する方法について説明します。 Azure Event Hubs はビッグ データ ストリーミング プラットフォームであり、毎秒数百万のイベントを受け取って処理できるイベント インジェスト サービスです。
Event Hubs からリアルタイムインテリジェンスにデータをストリーミングするには、2 つのメイン手順を実行します。 最初の手順は、Azure portal で実行します。イベント ハブ インスタンスに対して共有アクセス ポリシーを定義し、後でこのポリシーによって接続するために必要な詳細を記録します。
2 番目の手順は、ファブリックのリアルタイムインテリジェンスで行われ、KQL データベースをイベント ハブに接続し、受信データのスキーマを構成します。 この手順では、2 つの接続が作成されます。 "クラウド接続" と呼ばれる最初の接続では、Microsoft Fabric をイベント ハブ インスタンスに接続します。 2 つ目の接続は、「クラウド接続」を KQL データベースに接続します。 イベント データとスキーマの構成が完了すると、ストリーミング データを KQL クエリセット を使用してクエリを実行できるようになります。
Eventstream を使用して Event Hubs からデータを取得するには、「Azure Event Hubs のソースをイベントストリームに追加する」を参照してください。
前提条件
- Azure サブスクリプション。 無料の Azure アカウントを作成してください
- イベント ハブ
- Microsoft Fabric 対応の容量を持つワークスペース
- 編集アクセス許可を持つ KQL データベース
警告
イベント ハブをファイアウォールの内側に置くことはできません。
イベント ハブで共有アクセス ポリシーを設定する
Event Hubs データへの接続を作成する前に、イベント ハブに共有アクセス ポリシー (SAS) を設定し、後で接続の設定で使用する情報を収集する必要があります。 Event Hubs リソースへのアクセスを承認する方法の詳細については、「Shared Access Signatures」 を参照してください。
Azure portal で、接続するイベント ハブ インスタンスを参照します。
[設定] で、[共有アクセス ポリシー] を選択します
[+追加] を選択して新しい SAS ポリシーを追加するか、 管理 アクセス許可を持つ既存のポリシーを選択します。
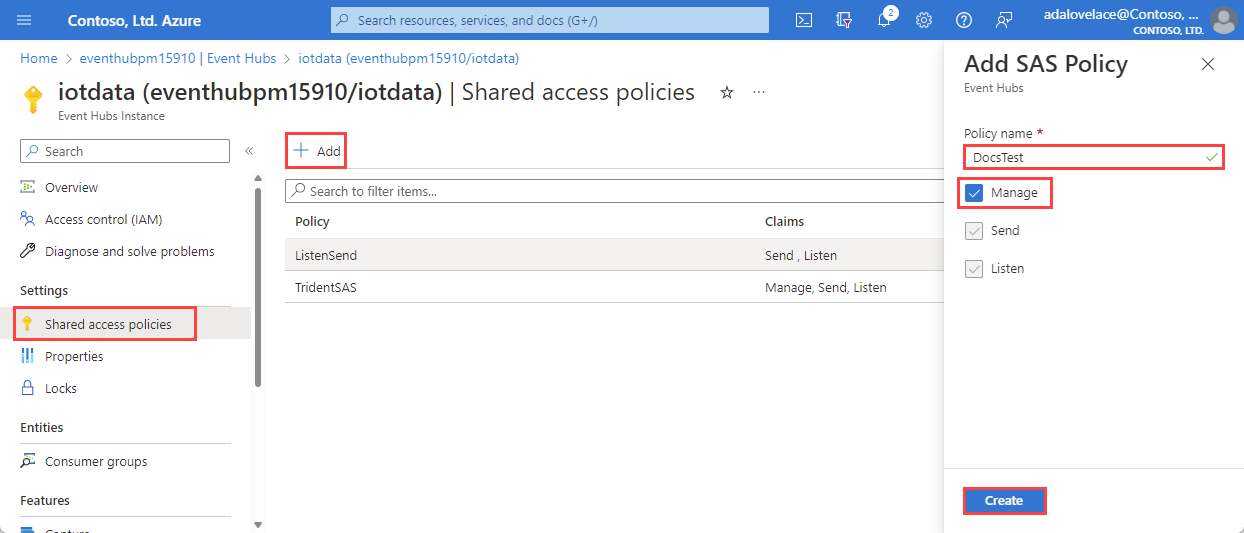
ポリシー名 を入力します。
[管理] を選択し、[作成] を選択します。

クラウド接続の情報を収集する
[SAS ポリシー] ウィンドウで、次の 4 つのフィールドをメモします。 これらのフィールドをコピーしてメモ帳などのどこかに貼り付けておくと、後の手順で使用できます。

| フィールド参照 | フィールド | 説明 | 例 |
|---|---|---|---|
| a | Event Hubs インスタンス | イベント ハブ インスタンスの名前。 | iotdata |
| b | SAS ポリシー | 前の手順で作成した SAS ポリシー名 | DocsTest |
| c | 主キー | SAS ポリシーに関連付けられているキー | この例では、 PGGIISb009... で始まります。 |
| d | 接続文字列 - 主キー | このフィールドでは、接続文字列の一部として見つかるイベント ハブ名前空間のみをコピーします。 | eventhubpm15910.servicebus.windows.net |
ソース
KQL データベースの下部のリボンで、[データの取得] を選択します。
[データの取り込み] ウィンドウで [ソース] タブが選択されます。
使用可能な一覧からデータ ソースを選択します。 この例では Event Hubs からデータを取り込みます。
![[ソース] タブが選択されている [データの取得] ウィンドウのスクリーンショット。](media/get-data-kql/select-data-source.png)
![[ソース] タブが選択されている [データの取得] ウィンドウのスクリーンショット。](media/get-data-kql/select-data-source.png#lightbox)
構成
ターゲット テーブルを選択します。 新しいテーブルにデータを取り込む場合は、[+ 新しいテーブル] を選択し、テーブル名を入力します。
Note
テーブル名には、スペース、英数字、ハイフン、アンダースコアを含め、最大 1024 文字を使用できます。 特殊文字はサポートされていません。
[新しい接続を作成] を選択するか、[既存の接続] を選択して、次の手順に進みます。
新しい接続を作成します。
次の表に従って、接続設定 を入力します:
![[ソース] タブのスクリーンショット。](media/get-data-event-hub/source.png)
設定 説明 例値 イベント ハブの名前空間 上の表 のフィールド d。 eventhubpm15910.servicebus.windows.net イベント ハブ 上の表 のフィールド a。 イベント ハブ インスタンスの名前。 iotdata つながり Fabric と Event Hubs の間の既存のクラウド接続を使用するには、この接続の名前を選択します。 それ以外の場合は、[新しい接続を作成する] を選択します。 新しい接続を作成します。 [接続名] 新しいクラウド接続の名前。 この名前は自動生成されますが、上書きできます。 ファブリックテナント内で一意である必要があります。 接続 認証の種類 自動で入力されます。 現在、共有アクセス キーのみがサポートされています。 共有アクセス キー 共有アクセス キー名 上の表 のフィールド b。 共有アクセス ポリシーに付けた名前。 DocsTest 共有アクセス キー 上の表 のフィールド c。 SAS ポリシーの主キー。 [保存] を選択します。 Fabric と Event Hubs の間に新しいクラウド データ接続が作成されます。
![[ソース] タブのスクリーンショット。](media/get-data-event-hub/source.png#lightbox)
クラウド接続を KQL データベースに接続する
新しいクラウド接続を作成した場合でも、既存のものを使おうとしている場合でも、コンシューマー グループを定義する必要があります。 必要に応じて、KQL データベースとクラウド接続の間の接続について、さらに複数の側面を定義するパラメーターを設定できます。
テーブルに従って、次のフィールドに入力します:
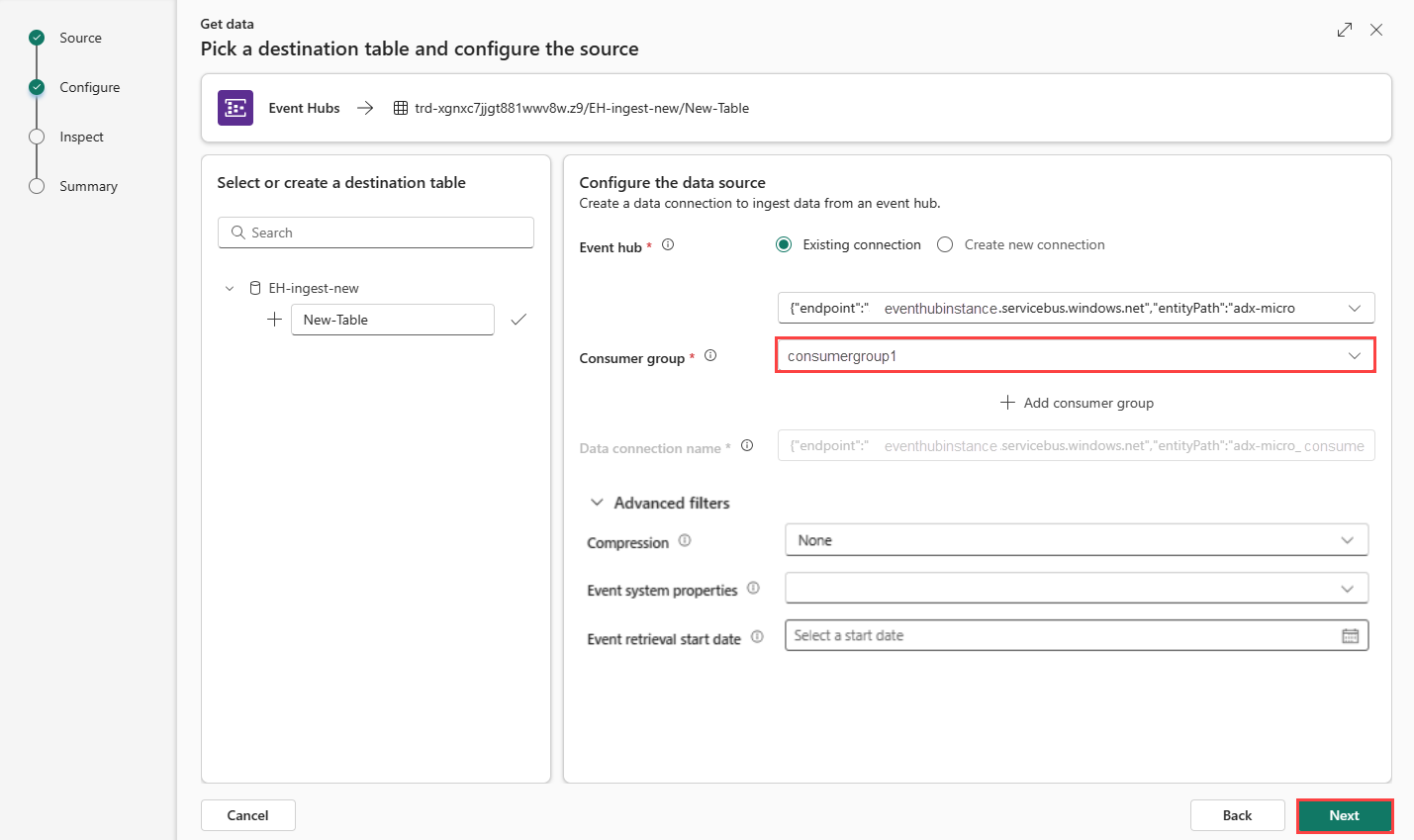
設定 説明 例値 コンシューマー グループ イベント ハブに定義されているコンシューマー グループ。 詳細については、「コンシューマー グループ」 を参照してください。 新しいコンシューマー グループを追加した後、ドロップダウンからこのグループを選択する必要があります。 NewConsumer その他のパラメーター 圧縮 イベント ハブからの送信としてのイベントのデータ圧縮。 オプションは None (既定値)、または GZip 圧縮です。 なし イベント システム プロパティ 詳細については、イベントハブ システムのプロパティ を参照してください。 イベント メッセージごとに複数のレコードがある場合、システム プロパティは最初のものに追加されます。 イベント システムのプロパティ を参照してください。 イベント取得の開始日 データ接続は、イベント取得開始日以降に作成された既存のイベント ハブ イベントを取得します。 保持期間に基づいて、イベント ハブによって保持されるイベントのみを取得できます。 タイム ゾーンは UTC です。 時刻を指定しない場合、既定の時刻はデータ接続が作成される時刻です。 [次へ] を選択して [検査] タブに進みます。
イベント システム プロパティ
イベントがエンキューされるときに、Event Hubs サービスによって設定されたプロパティがシステム プロパティに格納されます。 イベント ハブへのデータ接続では、選択した一連のシステム プロパティを、特定のマッピングに基づいてテーブルに読み込まれたデータに埋め込むことができます。
| プロパティ | データ型 | 説明 |
|---|---|---|
| x-opt-enqueued-time | datetime | イベントがエンキューされた UTC 時刻。 |
| x-opt-sequence-number | long | イベント ハブのパーティション ストリーム内のイベントの論理シーケンス番号。 |
| x-opt-offset | string | イベント ハブのパーティション ストリームからのイベントのオフセット。 このオフセット識別子は、イベント ハブ ストリームのパーティション内で一意です。 |
| x-opt-publisher | string | 発行元の名前 (発行元のエンドポイントにメッセージが送信された場合)。 |
| x-opt-partition-key | string | イベントが格納されている、対応するパーティションのパーティション キー。 |
検査
インジェスト プロセスを完了するには、[完了] を選択します。
![[検査] タブのスクリーンショット。](media/get-data-azure-storage/inspect-data.png#lightbox)
必要に応じて、次の操作を行います。
[コマンド ビューアー] を選択し、入力から生成される自動コマンドを表示してコピーします。
ドロップダウンから必要な形式を選択して、自動的に推論されるデータの形式を変更します。 データは EventData オブジェクトの形式でイベント ハブから読み取られます。 サポートされている形式は、CSV、JSON、PSV、SCsv、SOHsv、TSV、TXT、TSVE です。
データ型に基づく [詳細] オプションを確認します。
プレビュー ウィンドウに表示されるデータが完全でない場合は、必要なすべてのデータ フィールドを含むテーブルを作成するために、さらにデータが必要になることがあります。 次のコマンドを使用して、イベント ハブから新しいデータをフェッチします。
- Discard and fetch new data (破棄して新しいデータをフェッチする) : 表示されたデータを破棄し、新しいイベントを検索します。
- Fetch more data (さらにデータをフェッチする) :既に見つかったイベントに加えて、さらにイベントを検索します。
列の編集
Note
- 表形式 (CSV、TSV、PSV) では、列を 2 回マップすることはできません。 既存の列にマップするには、最初に新しい列を削除します。
- 既存の列の型を変更することはできません。 異なる形式の列にマップしようとすると、空の列になってしまう場合があります。
テーブルに加えることができる変更は、次のパラメーターによって異なります。
- テーブルの種類が新規かまたは既存か
- マッピングの種類が新規かまたは既存か
| テーブルの種類です。 | マッピングの種類 | 使用可能な調整 |
|---|---|---|
| 新しいテーブル | 新しいマッピング | 列の名前変更、データ型の変更、データ ソースの変更、マッピング変換、列の追加、列の削除 |
| 既存のテーブル | 新しいマッピング | 新しい列の追加 (その後、データ型の変更、名前変更、更新が可能) |
| 既存のテーブル | 既存のマッピング | なし |

マッピング変換
一部のデータ形式マッピング (Parquet、JSON、Avro) では、簡単な取り込み時の変換がサポートされています。 マッピング変換を適用するには、[列の編集] ウィンドウで列を作成または更新します。
マッピング変換は、データ型が int または long であるソースを使用して、string または datetime 型の列に対して実行できます。 サポートされているマッピング変換は次のとおりです。
- DateTimeFromUnixSeconds
- DateTimeFromUnixMilliseconds
- DateTimeFromUnixMicroseconds
- DateTimeFromUnixNanoseconds
Event Hubs Capture Avro ファイルのスキーマ マッピング
Event Hubs データを使う方法の 1 つは、Azure Blob Storage または Azure Data Lake Storage の Azure Event Hubs を通じてイベントをキャプチャすることです。 その後、Event Grid のデータ接続を使い、書き込まれたキャプチャ ファイルを取り込めます。
キャプチャしたファイルのスキーマは、Event Hubs に送信された元のイベントのスキーマとは異なります。 この違いを考慮した上で、宛先テーブルのスキーマを設計する必要があります。 具体的には、イベントのペイロードはキャプチャ ファイルではバイト配列で表され、この配列は Event Grid の Azure Data Explorer データ接続では自動的にデコードされません。 Event Hubs Avro キャプチャ データのファイル スキーマに関する具体的な情報については、「Azure Event Hubs でキャプチャされた Avro ファイルの操作」を参照してください。
イベント ペイロードを正しくデコードするには:
- キャプチャしたイベントの
Bodyフィールドを、宛先テーブルの型dynamicの列にマップします。 - unicode_codepoints_to_string() 関数を使ってバイト配列を読み取り可能な文字列に変換する更新ポリシーを適用します。
データ型に基づく [詳細] オプション
表形式 (CSV、TSV、PSV):
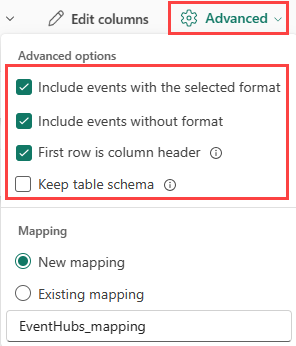
表形式を "既存のテーブル" に取り込もうとしている場合は、[詳細]> を選択できます。 表形式データには、ソース データを既存の列にマップするために使用される列名が必ずしも含まれるとは限りません。 このオプションをオンにすると、マッピングは順番に行われ、テーブル スキーマは同じままになります。 このオプションをオフにすると、データ構造に関係なく、受信するデータに対して新しい列が作成されます。
最初の行を列名として使用するには、[詳細]>[最初の行を列ヘッダーにする] を選択します。
JSON:
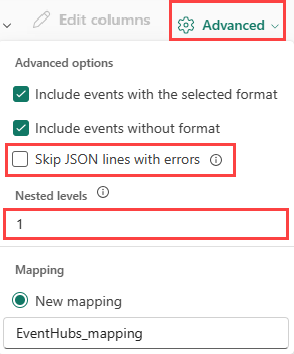
JSON データの列分割を指定するには、[詳細]>[入れ子のレベル] を 1 から 100 までで選択します。
[詳細]>[エラーのある JSON 行をスキップする] を選択すると、データは JSON 形式で取り込まれます。 このチェック ボックスをオフのままにすると、データは multijson 形式で取り込まれます。
まとめ
[データ準備] ウィンドウでは、データ インジェストが正常に終了した場合、3 つのステップすべてに緑色のチェックマークが表示されます。 カードを選択してクエリを実行すること、取り込まれたデータを削除すること、インジェストの概要のダッシュボードを表示することができます。
