ベクトル データベース
ベクター データベースは、データをベクター形式、つまりデータ ポイントの数値配列として格納および管理するツールです。
ベクターを使用することで、ベクター類似性検索、量子化、クラスタリングなどの高度な手法によりベクターを比較および分析できるようになり、複雑なクエリや分析が可能になります。 従来のデータベースは、データ分析でますます一般的になっている高次元データを処理するのに適していません。 いっぽうベクター データベースは、テキスト、画像、音声などの高次元データをベクターとして表して処理するように設計されています。 ベクター データベースは、機械学習、自然言語処理、画像認識など、大規模なデータセットのパターンや類似点の特定を目的とするタスクに役立ちます。
この記事では、ベクター データベースの背景について説明し、Microsoft Fabric のリアルタイム インテリジェンスで Eventhouse をベクター データベースとして使用する方法について概念的に説明します。 実際の例については、「Tutorial: Eventhouse をベクター データベースとして使用する」を参照してください。
重要な概念
ベクター データベースでは、次のような基本概念を使用します。
ベクトルの類似性
ベクター類似性は、2つ以上のベクターが互いにどのように異なる (または類似している) かを示す尺度である。 ベクター類似性検索は、データセット内の類似ベクターを見つけるのに使用する手法である。 ベクターは、ユークリッド距離やコサイン類似性などの距離メトリックを使用して比較する。 2 つのベクター間の距離が近いほど、類似性は高い。
埋め込み
埋め込みは、ベクター データベース内でベクター形式でデータを表すのに使用する一般的な方法です。 埋め込みは、単語、テキスト ドキュメント、画像などのデータの数学的表現であり、そのセマンティックな意味をキャプチャするように設計されています。 埋め込みは、データを分析してその主な特徴を表す数値セットを生成するアルゴリズムを使用して作成されます。 たとえば、単語の埋め込みは、その単語の意味、コンテキスト、および他の単語との関係を表すことができます。 埋め込みを作成するプロセスはシンプルです。 標準の Python パッケージ (spaCy、sent2vec、Gensim など) を使用して作成することもできますが、大規模言語モデル (LLM) では、セマンティック テキスト検索向けに最高品質の埋め込みを生成します。 たとえば、Azure OpenAI の埋め込みモデルにテキストを送信するとベクター表現を生成するので、これを格納して分析することができます。 詳細については、「Azure OpenAI Service での埋め込みについて理解する」を参照してください。
一般的なワークフロー

ベクター データベースを使用するための一般的なワークフローは次のとおりです。
- データの埋め込み: 埋め込みモデルを使用してデータをベクター形式に変換します。 たとえば、OpenAI モデルを使用してテキスト データを埋め込むことができます。
- ベクターの格納: 埋め込まれたベクターをベクター データベースに格納します。 埋め込みデータを Eventhouse に送信して、ベクターを格納および管理できます。
- クエリの埋め込み: 格納されたデータの埋め込みに使用するのと同じ埋め込みモデルを使用して、クエリ データをベクター形式に変換します。
- ベクターのクエリ: ベクター類似性検索を使用して、クエリに類似したデータベース内のエントリを検索します。
ベクター データベースとしての Eventhouse
ベクター類似性検索のコアとなるのは、ベクター データを格納してインデックス化し、クエリできるようにする機能です。 Eventhouse は、特にリアルタイムの分析と探索を必要とするシナリオにおいて、大量のデータを処理および分析するのに適したソリューションで、ベクターの格納や検索に非常に優れています。
Eventhouse アーキテクチャの次のコンポーネントを使用すると、Eventhouse をベクター データベースとして使用できます。
- 動的データ型。配列やプロパティ バッグなどの非構造化データを格納できます。 したがって、ベクター値を格納する際にはデータ型の使用をお勧めします。 元のオブジェクトに関連するメタデータをテーブル内の個別の列として格納することで、ベクター値をさらに拡張できます。
- エンコード型
Vector16は浮動小数点のベクターを 16 ビット精度で格納するように設計されており、既定の 64 ビットではなくBfloat16を使用します。 このエンコード型は、ML ベクター埋め込みの格納時に推奨されます。エンコード型の使用により格納要件が 4 分の 1 に減り、series_dot_product() や series_cosine_similarity() などのベクター処理関数が桁違いに高速化されます。 - series_cosine_similarity関数。Eventhouse に格納されているベクター上でベクター類似性検索を実行できます。
スケーリング向けに最適化
コサイン類似性検索の最適化のために、ベクター テーブルを、すべてのクラスター ノードに均等に分配される多数のエクステントに分割できます。 次の例では、パーティション分割がクエリ時間に及ぼす影響を確認できます。 この例では、最大 1M の埋め込みベクターを含む複数のテーブルを使用して、1 ノード、2 ノード、4 ノード、8 ノード、20 ノードのクラスターでコサイン類似性のパフォーマンスをテストします。 次のグラフは、パーティション分割前とパーティション分割後の検索パフォーマンス (秒単位) を比較しています。
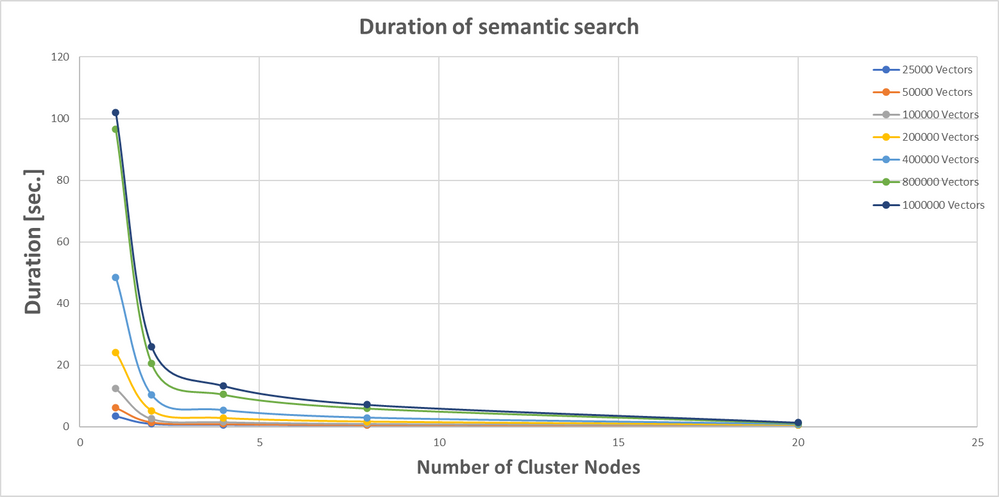
最小のクラスター数であっても、検索速度は 4 倍以上スピードアップします。 一般に、速度はノード数に反比例します。 LLM (大規模言語モデル) の一般的なシナリオ (検索拡張生成など) に必要な埋め込みベクターの数が 10万個 を超えることはめったにないため、8 ノードであれば検索は 1 秒で完了します。
スケーリング向けに最適化されたパーティション 分割ポリシーを作成する
埋め込みテーブルのパーティション 分割ポリシーを設定するには、.alter-merge policy partitioning コマンドを次のように使用します。
.alter-merge table TABLENAME policy partitioning
```
{
"PartitionKeys": [
{
"ColumnName": "vector_id_str",
"Kind": "Hash",
"Properties": {
"Function": "XxHash64",
"MaxPartitionCount": 2048, // set it to max value create smaller partitions thus more balanced spread among all cluster nodes
"Seed": 1,
"PartitionAssignmentMode": "Uniform"
}
}
],
"EffectiveDateTime": "2000-01-01" // set it to old date in order to apply partitioning on existing data
}
```
Note
クラスターには 2 つのノードがありますが、テーブルは 1 つのノードに格納されます。 これは、パーティション分割ポリシーを適用する前のベースラインです。
パーティション分割プロセスではカーディナリティが高い文字列キーが必要であるため、一意の vector_id が投影され、string データ型に変換されます。 ベスト プラクティスは、空のテーブルを作成し、そのパーティション ポリシーを変更してからデータを取り込む方法です。 その場合、前のコマンドのように古い EffectiveDateTime を定義する必要はありません。 データ インジェスト後にポリシーが適用されるまで、しばらく時間がかかります。