Use DICOM data transformation in healthcare data solutions
Note
This content is currently being updated.
The DICOM data transformation capability in healthcare data solutions allows you to ingest, store, and analyze Digital Imaging and Communications in Medicine (DICOM) data from various sources. To learn more about the capability and understand how to deploy and configure it, see:
- Overview of DICOM data transformation
- DICOM metadata transformation
- Deploy and configure DICOM data transformation
DICOM data transformation is an optional capability with healthcare data solutions in Microsoft Fabric.
Prerequisites
Before you run the DICOM data transformation pipeline, make sure you complete the prerequisites, deployment process, and configuration steps explained in Deploy and configure DICOM data transformation.
Data ingestion options
This article provides step-by-step guidance on how to use the DICOM ingestion capability to ingest, transform, and unify the DICOM imaging dataset. The capability supports the following two execution options:
Option 1: End to end ingestion of DICOM files. The DICOM files, either in the native (DCM) or compressed (ZIP) formats, are ingested into the lakehouse. This option is called the Ingest option.
Option 2: End to end integration with the DICOM service. The ingestion is facilitated through native integration with the DICOM service in Azure Health Data Services. In this option, the DCM files are first transferred from the Azure Health Data Services DICOM service to Data Lake Storage Gen2. The pipeline then follows the Bring Your Own Storage execution. This option is called the Azure Health Data Services (AHDS) option.
Option 1: End to end ingestion of DICOM files
In this option, we ingest the imaging data from DICOM files into the healthcare data solutions lakehouses using the prebuilt data pipeline. You can use the imaging sample dataset that has both ZIP and native DCM files. The end-to-end execution consists of the following consecutive steps:
- Ingest DICOM files into OneLake
- Organize DICOM files in OneLake
- Extract DICOM metadata into the bronze lakehouse
- Convert DICOM metadata to the FHIR (Fast Health Interoperability Resources) format
- Ingest data into the ImagingStudy delta table in the bronze lakehouse
- Flatten and transform data into the ImagingStudy delta table in the silver lakehouse
- Convert and ingest data into the Image_Occurrence table in the gold lakehouse (optional)
Ingest DICOM files into OneLake
The Ingest folder in the bronze lakehouse represents a drop (queue) folder. You can drop the DICOM files inside this folder. The files then move to an organized folder structure within the bronze lakehouse.
Navigate to the Ingest\Imaging\DICOM\DICOM-HDS folder in the bronze lakehouse.
Select ... (ellipsis) > Upload > Upload files.
Select and upload the imaging dataset from the SampleData folder. The Deploy sample data step should automatically deploy the sample data to this folder.
There's no limitation on the number of DCM files or the number, depth, and nesting of subfolders within the ingested ZIP files. For information on the file size limitation, see Ingestion file size.
Organize DICOM files in OneLake
After the sample data moves to the bronze lakehouse folders, the pipeline organizes the files for processing. It uses the ImagingRawDataMovementService module in the healthcare data solutions library to move the imaging files to an optimized folder structure for further processing:
Transfer files from the Ingest folder to a new optimized folder structure
Files\Process\Imaging\DICOM\yyyy\mm\ddinside the bronze lakehouse. This scalable, data lake friendly folder structure follows Best practices for Azure Data Lake Storage directory structure. For source files in ZIP format with multiple DCM files, the notebook extracts and moves each DCM file to the optimized folder structure, regardless of the original folder hierarchy inside the source ZIP files.Add a Unix timestamp prefix to the file names. The timestamp generates at the millisecond level to ensure uniqueness across file names. This feature is useful for environments with multiple Picture Archiving and Communication System (PACS) and Vendor Neutral Archive (VNA) systems, where file name uniqueness isn't guaranteed.
If a date movement fails, the failed files (with the Unix timestamp prefix) are saved under the Failed folder within the following optimized folder structure:
Files\Failed\Imaging\DICOM\DICOM-HDS\yyyy\mm\dd\.
Extract DICOM metadata into the bronze lakehouse
This step uses the healthcare#_msft_imaging_dicom_extract_bronze_ingestion notebook to track and process the newly moved files in the Process folder using Structured streaming in Spark. The notebook uses the MetadataExtractionOrchestrator module in the healthcare data solutions library to perform the following actions:
Extract the DICOM tags (DICOM data elements) available in the Process folder DCM files and ingest them into the dicomimagingmetastore delta table in the bronze lakehouse. For more information about this transformation process, go to Transformation mapping for DICOM metadata to bronze delta table.
For data extraction failures, the notebook saves the failed file with the Unix timestamp prefix under the Failed folder in the bronze lakehouse within the following optimized folder structure
Files\Failed\Imaging\DICOM\DICOM-HDS\yyyy\mm\dd\.Data extraction might fail for several reasons:
- File parsing fails due to unknown or unexpected errors.
- The DCM files have invalid content that isn't compliant with the DICOM standard format.
Convert DICOM metadata to the FHIR format
After ingesting the files and populating the dicomimagingmetastore delta table with the DICOM tags, the next step is to convert the DICOM metadata to the FHIR format.
The healthcare#_msft_imaging_dicom_fhir_conversion notebook uses Structured streaming in Spark to track and process recently modified delta tables in the bronze lakehouse, including dicomimagingmetastore. It uses the MetadataToFhirConvertor module in the healthcare data solutions library to convert the DICOM metadata in the dicomimagingmetastore bronze delta table. The conversion process involves transforming metadata from the dicomimagingmetastore table into FHIR ImagingStudy in the FHIR resource R4.3 format and saving the output as NDJSON files. For more information about the transformation, go to Transformation mapping for DICOM metadata to bronze delta table.
The notebook converts the DICOM metadata to FHIR ImagingStudy and writes the NDJSON files in another optimized folder structure for FHIR files in the bronze lakehouse. The folder structure is Files\Process\Clinical\FHIR NDJSON\yyyy\mm\dd\ImagingStudy. The notebook generates only one NDJSON file for all the DICOM metadata processed in a single notebook execution. If you can't find the new folders, Refresh the Fabric UI and OneLake file explorer.
Ingest data into the bronze lakehouse ImagingStudy delta table
After ingesting the DICOM data and converting it to the FHIR format, the pipeline runs a simple FHIR data ingestion pipeline, similar to ingesting any other FHIR resource. This step converts the data in the FHIR ImagingStudy NDJSON file to an ImagingStudy delta table in the bronze lakehouse. This delta table maintains the raw state of the data source.
The execution groups the instance-level data of the same study into one DICOM study record. For more information on this grouping pattern, see Group pattern in the bronze lakehouse.
Ingest data into the silver lakehouse ImagingStudy delta table
In this step, the data pipeline runs the healthcare#_msft_bronze_silver_flatten notebook to track and process the newly added records in the bronze lakehouse. The notebook flattens and transforms data from the ImagingStudy delta table in the bronze lakehouse to the ImagingStudy delta table in the silver lakehouse, in accordance with the FHIR resource (R4.3) format.
The notebook upserts the ImagingStudy records from the bronze to the silver lakehouse. To learn more about the upsert pattern, go to Upsert pattern in the silver lakehouse. Transformation mapping for bronze to silver delta table explains this transformation process in detail.
After the notebook completes execution, you can see nine records in the ImagingStudy delta table in the silver lakehouse.

Convert and ingest data into the gold lakehouse
Important
Follow this optional execution step only if you've deployed and configured the OMOP transformations capability in healthcare data solutions. Otherwise, you can skip this step.
For the final step, follow this guidance to convert and ingest data into the Image_Occurrence delta table in the gold lakehouse:
In your healthcare data solutions environment, go to the healthcare#_msft_omop_silver_gold_transformation notebook and open it.
This notebook uses the healthcare data solutions OMOP APIs to transform resources from the silver lakehouse into OMOP Common Data Model delta tables in the gold lakehouse. By default, you don't need to make any changes to the notebook configuration.
Select Run all to run the notebook.
The notebook implements the OMOP tracking approach to track and process newly inserted or updated records in the ImagingStudy delta table in the silver lakehouse. It converts data in the FHIR delta tables in the silver lakehouse (including the ImagingStudy table) to the respective OMOP delta tables in the gold lakehouse (including the Image_Occurrence table). For more information on this transformation, go to Transformation mapping for silver to gold delta table.
Refer FHIR to OMOP mapping for the mapping details for all the supported OMOP tables.
After the notebook completes execution based on the imaging sample dataset, you can query and find 24 records in the Image_Occurrence delta table in the gold lakehouse. Each record represents a series object in the DICOM hierarchy.

Option 2: End to end integration with the DICOM service
Important
Follow this execution pipeline only if you're using the Azure Health Data Services DICOM service and have deployed the DICOM API. Otherwise, you can skip this option.
Review and complete the deployment procedure in Deploy the DICOM API in Azure Health Data Services.
After deploying the Azure DICOM service, ingest DCM files through the Store (STOW-RS) API.
Depending on your preferred language, upload the sample data files using one of the following options:
- Use DICOMweb standard APIs with C#
- Use DICOMweb standard APIs with cURL
- Use DICOMweb standard APIs with Python
If using Python, you can:
- Create a .PY file.
- Follow the instructions and the code snippet in Use DICOMweb standard APIs with Python.
- Upload a DCM file from a local machine location to the DICOM server.
- Use the Retrieve (WADO-RS) API to verify a successful file upload operation.
You can also verify successful file upload using the following steps:
- On the Azure portal, select the Azure storage account linked to the DICOM service.
- Navigate to Containers and follow the path
[ContainerName]/AHDS/[AzureHealthDataServicesWorkspaceName]/dicom/[DICOMServiceName]. - Verify if you can see the DCM file uploaded here.
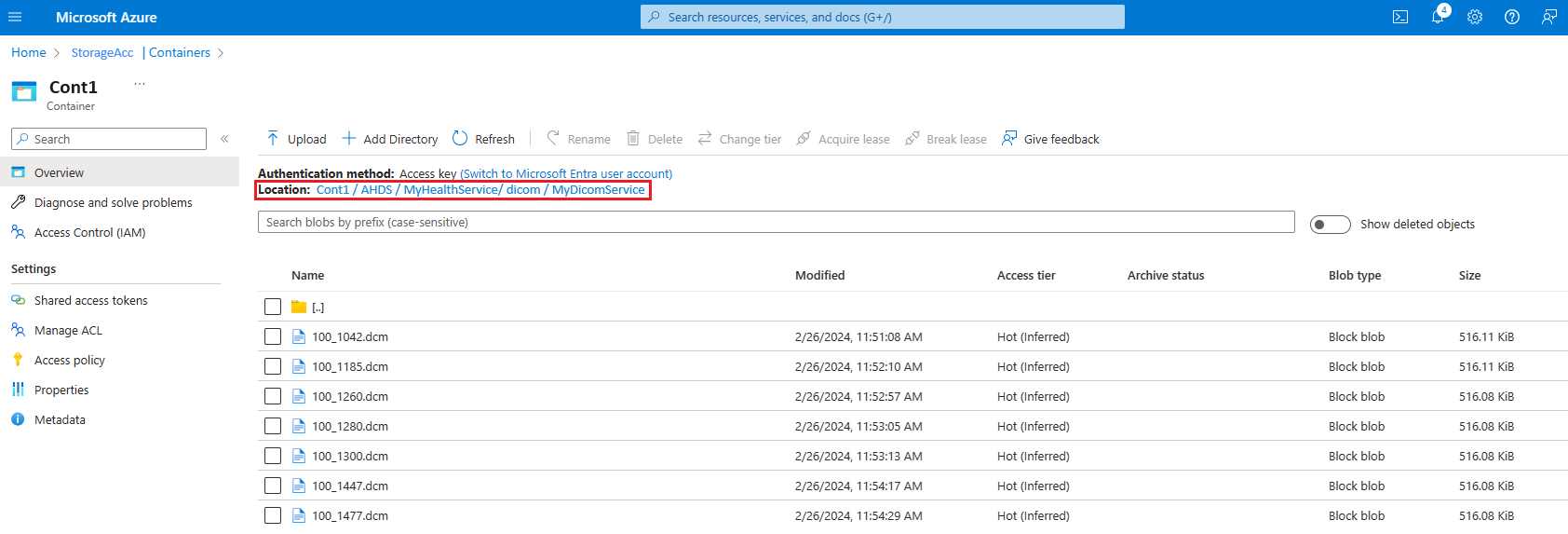
After successfully uploading the data to the DICOM service and verifying the file in your Data Lake Storage Gen2 location, proceed to the next step.
Create a shortcut for the DICOM file from their location in the Azure Data Lake Storage Gen2 location. If you aren't using an Azure Health Data Services DICOM service, make sure to use the shortcut created in Configure Azure Data Lake Storage ingestion. For consistency, we recommend using the following folder structure to create the shortcut:
Files\External\Imaging\DICOM\[Namespace]\[BYOSShortcutName].

Note
For details on integration limitations with the Azure Health Data Services DICOM service, see Integration with DICOM service.