summarize 演算子
適用対象: ✅Microsoft Fabric✅Azure データ エクスプローラー✅Azure Monitor✅Microsoft Sentinel
入力テーブルの内容を集計したテーブルを生成します。
構文
T | summarize [ SummarizeParameters ] [ [Column =] Aggregation [, ...]] [by [Column =] GroupExpression [, ...]]
構文規則について詳しく知る。
パラメーター
| 件名 | タイプ | Required | 説明 |
|---|---|---|---|
| 列 | string |
結果の列の名前。 既定値は式から派生した名前です。 | |
| 集計 | string |
✔️ | 引数として列名が指定された count() や avg() などの集計関数の呼び出し。 |
| GroupExpression | スカラー型 | ✔️ | 入力データを参照できるスカラー式。 出力には、すべてのグループ式の個別の値と同じ数のレコードが含まれます。 |
| SummarizeParameters | string |
動作を制御する 0 個以上のスペース区切りパラメーター ( Name = Value の形式。 「サポートされているパラメーター」を参照してください。 |
Note
入力テーブルが空の場合、出力は GroupExpression が使用されているかどうかによって異なります。
- GroupExpression が指定されていない場合、出力は単一の (空の) 行になります。
- GroupExpression が指定されている場合、出力に行は含まれません。
サポートされているパラメーター
| Name | 説明 |
|---|---|
hint.num_partitions |
クラスター ノードでクエリ負荷を共有するために使用するパーティションの数を指定します。 クエリ*のシャッフルを参照 |
hint.shufflekey=<key> |
shufflekey クエリ*は、データ*をパーティション*化するキー*で、クラスター ノード*のクエリ*負荷*を共有*します。 クエリ*のシャッフルを参照 |
hint.strategy=shuffle |
shuffle 戦略クエリ*は、クラスター ノード*のクエリ*負荷*を共有*します。各ノード*で 1つずつ、データ*のパーティション*化を処理します。 クエリ*のシャッフルを参照 |
戻り値
入力列は、by 式の同じ値を持つグループにまとめられます。 次に、指定された集計関数によってグループごとに計算が行われ、各グループに対応する行が生成されます。 結果には、by 列のほか、計算された各集計に対応する 1 つ以上の列も含まれます (一部の集計関数は複数の列を返します)。
結果には、by 値の個別の組み合わせと同数の行が含まれます (0 の場合があります)。 グループ キーが指定されていない場合、結果には単一のレコードが含まれます。
数値の範囲をまとめるには、bin() を使って範囲を不連続値に減らします。
Note
- 集計式とグループ化式の両方に任意の式を指定できますが、単純な列名を使用するか、
bin()を数値列に適用する方がより効率的です。 - datetime 列の毎時の自動ビンはサポートされなくなりました。 代わりに、明示的なビン分割を使用してください。 たとえば、
summarize by bin(timestamp, 1h)のようにします。
集計の既定値
集計の既定値を以下の表にまとめます。
| 演算子 | 規定値 |
|---|---|
count()、 countif()、 dcount()、 dcountif()、 count_distinct()、 sum()、 sumif()、 variance()、 varianceif()、 stdev()、 stdevif() |
0 |
make_bag()、 make_bag_if()、 make_list()、 make_list_if()、 make_set()、 make_set_if() |
空の動的配列* ([]) |
| その他すべて | null |
Note
これらの集計を null 値を含むエンティティに適用すると、null 値は無視され、計算に考慮されません。 例については、「集計の既定値」を参照してください。
例
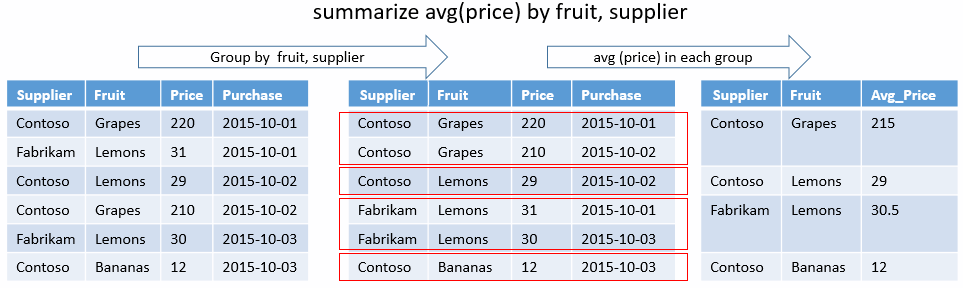
一意の組み合わせ
次のクエリでは、直接的な被害をもたらした嵐について、State と EventType の一意の組み合わせを決定します。 集計関数はなく、グループ別キーだけが使用されます。 出力には、これらの結果の列のみが表示されます。
StormEvents
| where InjuriesDirect > 0
| summarize by State, EventType
出力
次の表は、最初の 5 行のみを示しています。 完全な出力を表示するには、クエリを実行します。
| 状態 | EventType |
|---|---|
| テキサス州 | 雷雨風 |
| テキサス州 | 鉄砲水 |
| テキサス州 | 冬の天気 |
| テキサス州 | High Wind |
| テキサス州 | 洪水 |
| ... | ... |
最小と最大のタイムスタンプ
ハワイで発生した暴風雨の最低値と最大値をみつけます。 group by 句はないため、以下のように出力には行が 1 つしかありません。
StormEvents
| where State == "HAWAII" and EventType == "Heavy Rain"
| project Duration = EndTime - StartTime
| summarize Min = min(Duration), Max = max(Duration)
出力
| Min | Max |
|---|---|
| 01:08:00 | 11:55:00 |
個別のカウント
次のクエリは、各状態の一意の Storm イベントの種類の数を計算し、一意の Storm の種類の数で結果を並べ替えます。
StormEvents
| summarize TypesOfStorms=dcount(EventType) by State
| sort by TypesOfStorms
出力
次の表は、最初の 5 行のみを示しています。 完全な出力を表示するには、クエリを実行します。
| State | TypesOfStorms |
|---|---|
| テキサス州 | 27 |
| CALIFORNIA | 26 |
| ペンシルベニア | 25 |
| GEORGIA | 24 |
| ILLINOIS | 23 |
| ... | ... |
ヒストグラム
以下の例では、暴風雨が 1 日以上続いた暴風雨イベントの種類のヒストグラムを算出しています。 Duration には多くの値があるため、bin() を使用して、その値を 1 日間隔にグループ化します。
StormEvents
| project EventType, Duration = EndTime - StartTime
| where Duration > 1d
| summarize EventCount=count() by EventType, Length=bin(Duration, 1d)
| sort by Length
出力
| EventType | 長さ | EventCount |
|---|---|---|
| 干ばつ | 30.00:00:00 | 1646 |
| Wildfire | 30.00:00:00 | 11 |
| 暖房 | 30.00:00:00 | 14 |
| 洪水 | 30.00:00:00 | 20 |
| Heavy Rain | 29.00:00:00 | 42 |
| ... | ... | ... |
既定値を集計する
summarize 演算子の入力に少なくとも 1 つの空のグループ別キーがある場合は、その結果も空になります。
summarize 演算子の入力に空の group-by キーがない場合、結果は summarize で使用される集計の既定値になります。詳細については、「集計の既定値」を参照してください。
datatable(x:long)[]
| summarize any_x=take_any(x), arg_max_x=arg_max(x, *), arg_min_x=arg_min(x, *), avg(x), buildschema(todynamic(tostring(x))), max(x), min(x), percentile(x, 55), hll(x) ,stdev(x), sum(x), sumif(x, x > 0), tdigest(x), variance(x)
出力
| any_x | arg_max_x | arg_min_x | avg_x | schema_x | x/x | min_x | percentile_x_55 | hll_x | stdev_x | sum_x | sumif_x | tdigest_x | variance_x |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| NaN | 0 | 0 | 0 | 0 |
0 で除算するため、avg_x(x) の結果は NaN です。
datatable(x:long)[]
| summarize count(x), countif(x > 0) , dcount(x), dcountif(x, x > 0)
出力
| count_x | countif_ | dcount_x | dcountif_x |
|---|---|---|---|
| 0 | 0 | 0 | 0 |
datatable(x:long)[]
| summarize make_set(x), make_list(x)
出力
| set_x | list_x |
|---|---|
| [] | [] |
集計の avg では、null 以外のすべての値が集計され、計算の対象になった値のみがカウントされます (null 値は考慮されません)。
range x from 1 to 4 step 1
| extend y = iff(x == 1, real(null), real(5))
| summarize sum(y), avg(y)
出力
| sum_y | avg_y |
|---|---|
| 15 | 5 |
通常の count では、null がカウントされます。
range x from 1 to 2 step 1
| extend y = iff(x == 1, real(null), real(5))
| summarize count(y)
出力
| count_y |
|---|
| 2 |
range x from 1 to 2 step 1
| extend y = iff(x == 1, real(null), real(5))
| summarize make_set(y), make_set(y)
出力
| set_y | set_y1 |
|---|---|
| [5.0] | [5.0] |