Data, privacy, and security for text to speech
This article provides details regarding how data provided by you is processed, used, and stored by Azure AI Speech text to speech. As an important reminder, you are responsible for your use and the implementation of this technology and are required to obtain all necessary permissions, including, if applicable, from voice and avatar talent (and, if applicable, users of your personal voice integration(s)) for the processing of their voice, image, likeness and/or other data to develop synthetic voices and/or avatars.
You are also responsible for obtaining any licenses, permissions, or other rights necessary for the content you input to the text to speech service to generate audio, image, and/or video output. Some jurisdictions may impose special legal requirements for the collection, processing, and storage of certain categories of data, such as biometric data, and mandate disclosing the use of synthetic voices, images, and/or videos to users. Before using text to speech to process and store data of any kind and, if applicable, to create custom neural voice, personal voice, or custom avatar models, you must ensure that you are in compliance with all legal requirements that may apply to you.
What data do text to speech services process?
Prebuilt neural voice and prebuilt avatar process the following types of data:
- Text input for speech synthesis. This is the text you select and send to the text to speech service to generate audio output using a set of prebuilt neural voices, or to generate a prebuilt avatar that utters audio generated from either prebuilt or custom neural voices.
Recorded voice talent acknowledgement statement file. Customers are required to upload a specific recorded statement spoken by the voice talent in which they acknowledge that you will use their voice to create synthetic voice(s).
Note
When preparing your recording script, make sure you include the required acknowledgement statement for the voice talent to record. You can find the statement in multiple languages here. The language of the acknowledgement statement must be the same as the language of the audio recording training data.
Training data (including audio files and related text transcripts). This includes audio recordings from the voice talent who has agreed to use their voice for model training and the related text transcripts. In a custom neural voice pro project, you can provide your own text transcriptions of audio or use the automated speech recognition transcription feature available within Speech Studio to generate a text transcription of the audio. Both the audio recordings and the text transcription files will be used as voice model training data. In a custom neural voice lite project, you will be asked to record the voice speaking the Microsoft defined script in Speech Studio. Text transcripts are not required for personal voice features.
Text as the test script. You can upload your own text-based scripts to evaluate and test the quality of the custom neural voice model by generating speech synthesis audio samples. This does not apply to personal voice features.
Text input for speech synthesis. This is the text you select and send to the text to speech service to generate audio output using your custom neural voice.
How do text to speech services process data?
Prebuilt neural voice
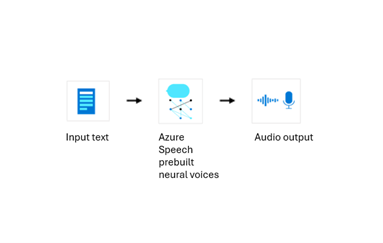
The diagram below illustrates how your data is processed for synthesis with prebuilt neural voice. The input is text, and the output is audio. Please note that neither input text nor output audio content will be stored in Microsoft logs.
Custom neural voice
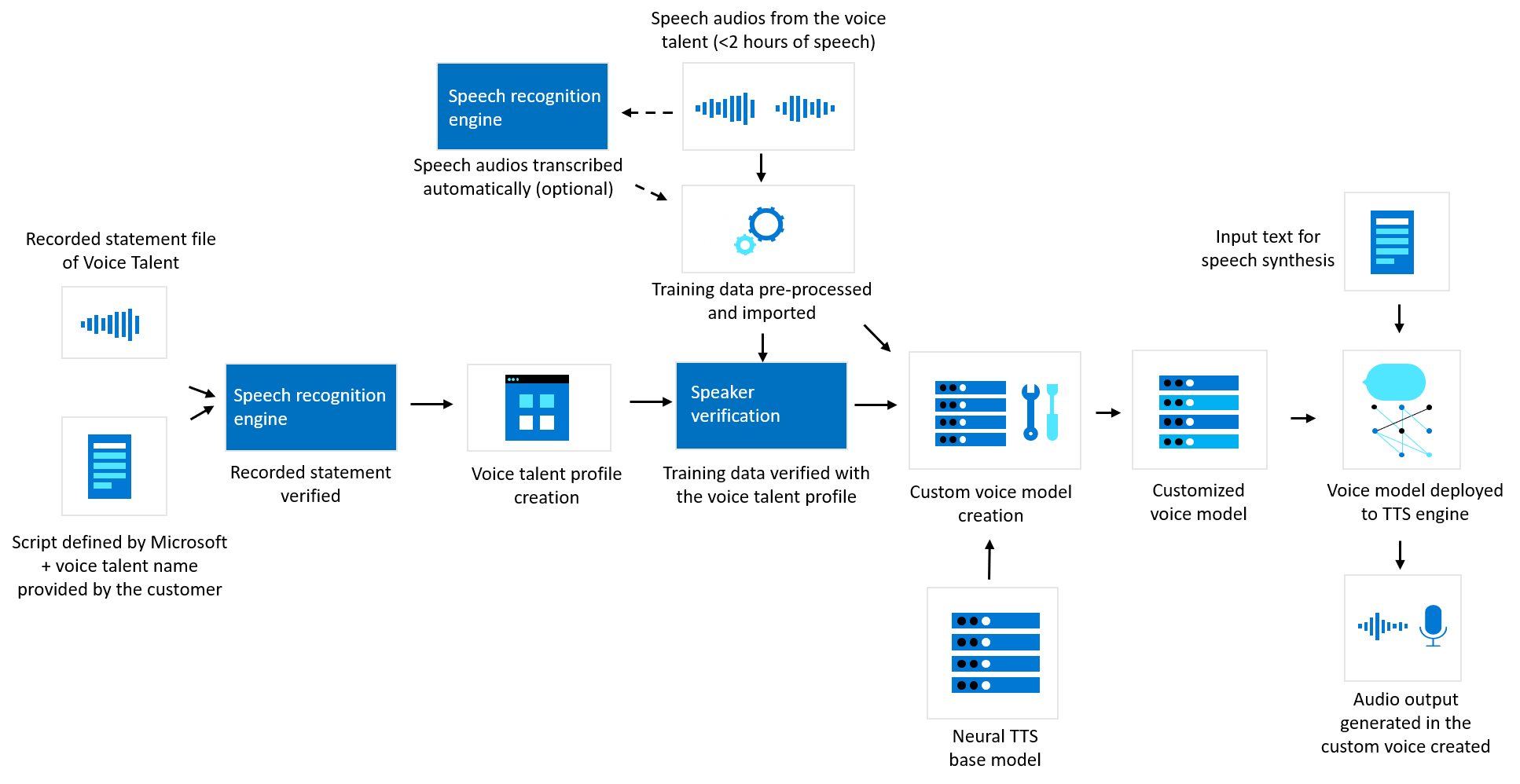
The diagram below illustrates how your data is processed for custom neural voice. This diagram covers three different types of processing: how Microsoft verifies recorded acknowledgement statement files of voice talent prior to custom neural voice model training, how Microsoft creates a custom neural voice model with your training data, and how text to speech processes your text input to generate audio content.
Text to speech avatar
The diagram below illustrates how your data is processed for synthesis with prebuilt text to speech avatar. There are three components in an avatar content generation workflow: text analyzer, the TTS audio synthesizer, and TTS avatar video synthesizer. To generate avatar video, text is first input into the text analyzer, which provides the output in the form of phoneme sequence. Then, the TTS audio synthesizer predicts the acoustic features of the input text and synthesize the voice. These two parts are provided by text to speech voice models. Next, the Neural text to speech Avatar model predicts the image of lip sync with the acoustic features, so that the synthetic video is generated.
![]()
Video translation (preview)
The diagram below illustrates how your data is processed with video translation. Customer uploads video as the input for video translation, dialogue audio is extracted and speech to text will transcribe the audio into text content. Then the text content will be translated to the target language content and, using text to speech capability, the translated audio will be merged with original video content as video output.

Recorded acknowledgement statement verification
Microsoft requires customers to upload an audio file to Speech Studio with a recorded statement of the voice talent acknowledging that the customer will use their voice to create a synthetic voice. Microsoft may use Microsoft’s speech to text and speech recognition technology to transcribe this recorded acknowledgement statement to text and verify that the content in the recording matches the pre-defined script provided by Microsoft. This acknowledgement statement, along with the talent information you provide with the audio, is used to create a voice talent profile. You must associate training data with the relevant voice talent profile when initiating custom neural voice training.
Microsoft may also process biometric voice signatures from the recorded acknowledgement statement file of the voice talent and from randomized audio from the training dataset(s) to confirm that the voice signature in the acknowledgement statement recording and the training data recordings match with reasonable confidence using Azure AI Speaker Verification. A voice signature may also be called a “voice template” or “voiceprint” and is a numeric vector that represents an individual’s voice characteristics that is extracted from audio recordings of a person speaking. This technical safeguard is intended to help prevent misuse of custom neural voice, by, for example, preventing customers from training voice models with audio recordings and using the models to spoof a person’s voice without their knowledge or consent.
The voice signatures are used by Microsoft solely for the purposes of speaker verification or as otherwise necessary to investigate misuse of the services.
The Microsoft Products and Services Data Protection Addendum (“DPA”) sets forth customers’ and Microsoft’s obligations with respect to the processing and security of Customer Data and Personal Data in connection with Azure and is incorporated by reference into customers’ enterprise agreement for Azure services. Microsoft’s data processing in this section is governed under the Legitimate Interest Business Operations section of the Data Protection Addendum.
Training a custom neural voice model
The training data (speech audio) customers submit to Speech Studio is pre-processed using automated tools for quality checking, including data format check, pronunciation scoring, noise detection, script mapping, etc. The training data is then imported to the model training component of the custom voice platform. During the training process, the training data (both voice audio and text transcriptions) are decomposed into fine-grained mappings of voice acoustics and text, such as a sequence of phonemes. Through further complex machine leaning modeling, the service builds a voice model, which then can be used to generate audio that sounds similar to the voice talent and can even be generated in different languages from the training data recording. The voice model is a text to speech computer model that can mimic unique vocal characteristics of a particular speaker. It represents a set of parameters in binary format that is not human readable and does not contain audio recordings.
A customer’s training data is used only to develop that customer’s custom voice models and is not used by Microsoft to train or improve any Microsoft text to speech voice models.
Speech synthesis/audio content generation
Once the voice model is created, you can use it to create audio content through the text to speech service with two different options.
For real time speech synthesis, you send the input text to the text to speech service via the TTS SDK or RESTful API. Text to speech processes the input text and returns output audio content files in real time to the application that made the request.
For asynchronous synthesis of long audio (batch synthesis), you submit the input text files to the text to speech batch service via the Long Audio API to asynchronously create audios longer than 10 minutes (for example audio books or lectures). Unlike synthesis performed using the text to speech API, responses aren't returned in real time with the Long Audio API. Audios are created asynchronously, and you can access and download the synthesized audio files when they are made available from the batch synthesis service.
You can also use your custom voice model to generate audio content through a no-code Audio Content Creation tool, and choose to save your text input or output audio content with the tool in Azure storage.
Data processing for custom neural voice lite (Preview)
Custom neural voice lite is a project type in public preview that allows you to record 20-50 voice samples on Speech Studio and create a lightweight custom neural voice model for demonstration and evaluation purposes. Both the recording script and the testing script are pre-defined by Microsoft. A synthetic voice model you create using custom neural voice lite may be deployed and used more broadly only if you apply for and receive full access to custom neural voice (subject to applicable terms).
The synthetic voice and related audio recording you submit via Speech Studio will automatically be deleted within 90 days unless you gain full access to custom neural voice and choose to deploy the synthetic voice, in which case you will control the duration of its retention. If the voice talent would like to have the synthetic voice and the related audio recordings deleted before 90 days, they can delete them on the portal directly, or contact their enterprise to do so.
In addition, before you can deploy any synthetic voice model created using a custom neural voice lite project, the voice talent must provide an additional recording in which they acknowledge that the synthetic voice will be used for additional purposes beyond demonstration and evaluation.
Data processing for personal voice API (Preview)
Personal voice allows customers to create a synthetic voice using a short human voice sample. The verbal acknowledgement statement file described above is required from each user who uses the integration in your application. Microsoft may process biometric voice signatures from the recorded voice statement file of each user and their recorded training sample (a.k.a the prompt) to confirm that the voice signature in the acknowledgement statement recording and the training data recording matches with reasonable confidence using Azure AI Speaker Verification.
The training sample will be used to create the voice model. The voice model can then be used to generate speech with text input provided to the service via the API, with no additional deployment required.
Data storage and retention
All text to speech services
Text input for speech synthesis: Microsoft does not retain or store the text that you provide with the real-time synthesis text to speech API. Scripts provided via the Long Audio API for text to speech or via text to speech avatar batch API for text to speech avatar are stored in Azure storage to process the batch synthesis request. The input text can be deleted via the delete API at any time.
Output audio and video content: Microsoft does not store audio or video content generated with the real-time synthesis API. If you are using Video translation or the Long Audio API for text to speech avatar batch API, the output audio or video content is stored in Azure storage. These audios or videos can be removed at any time via the delete operation.
Recorded acknowledgement statement and Speaker Verification data: The voice signatures are used by Microsoft solely for the purposes of speaker verification or as otherwise necessary to investigate misuse of the services. The voice signatures will be retained only for the time necessary to perform speaker verification, which may occur from time to time. Microsoft may require this verification before allowing you to train or retrain custom neural voice models in Speech Studio, or as otherwise necessary. Microsoft will retain the recorded acknowledgement statement file and voice talent profile data for as long as necessary to preserve the security and integrity of Azure AI Speech.
Custom neural voice models: While you maintain the exclusive usage rights to your custom neural voice model, Microsoft may independently retain a copy of custom neural voice models for as long as necessary. Microsoft may use your custom neural voice model for the sole purpose of protecting the security and integrity of Microsoft Azure AI services.
Microsoft will secure and store copies of each voice talent's recorded acknowledgement statement and custom neural voice models with the same high-level security that it uses for its other Azure Services. Learn more at Microsoft Trust Center.
Training data: You submit voice training data of voice talent to generate voice models via Speech Studio, which will be retained and stored by default in Azure storage (See Azure Storage encryption for data at REST for details). You can access and delete any of the training data used to build voice models via Speech Studio.
You can manage storage of your training data via BYOS (Bring Your Own Storage). With this storage method, training data may be accessed only for the purposes of voice model training and will otherwise be stored via BYOS.
Note
Personal voice does not support BYOS. Your data will be stored in Azure storage managed by Microsoft. You can access and delete any of the training data (prompt audio) used to build voice models via API. Microsoft may independently retain a copy of personal voice models for as long as necessary. Microsoft may use your personal voice model for the sole purpose of protecting the security and integrity of Microsoft Azure AI services.