事前構築済みモデルを使用して Microsoft Syntex のドキュメントから機密情報を検出する
機密情報の事前構築済みモデルは、ドキュメントの重要な情報を分析して検出し、必要に応じて情報を抽出します。 このモデルは、さまざまな形式のドキュメントを認識し、個人と財務の識別番号、物理的および電子メール アドレス、電話番号などの 機密情報を検出します。
機密情報モデルを設定する
機密情報モデルを作成して構成するには、次の手順に従います。
「Syntex でモデルを作成する」の手順に従って、機密情報モデルを作成します。 次に、次の手順に進み、モデルを完了します。
注:
機密情報モデルを作成すると、他のモデルとは異なり、コンテンツ タイプを選択したり、秘密度ラベルや保持ラベルを適用したりするためのオプションがないことがわかります。 コンテンツ タイプを関連付ける必要がある場合は、別のモデル タイプを作成する必要があります。 セキュリティ ラベルを適用する機能は、今後のリリースで提供される予定です。
[ モデル ] ページの [ 検出するエンティティの追加] セクションで、[ エンティティの追加] を選択します。
![[検出するエンティティの追加] セクションを示す新しいモデル ページのスクリーンショット。](../media/content-understanding/prebuilt-add-file-to-analyze-sensitive-info.png)
[ 検出の構成] ページで、次の手順を実行します。
このモデルに使用する言語を選択します。 モデルごとに選択できる言語は 1 つだけです。
サポートされているエンティティの一覧から、検出する機密情報エンティティまたはエンティティを選択し、[ 次へ] を選択します。
![[検出の構成] ページのスクリーンショット。](../media/content-understanding/prebuilt-sensitive-configure-detection.png)
[ 抽出の構成] ページに、検出するために選択した機密情報エンティティの一覧が表示されます。 列に抽出するエンティティを選択し、[ 次へ] を選択します。
![[抽出の構成] ページのスクリーンショット。](../media/content-understanding/prebuilt-sensitive-select-extract.png)
[ モデルのテスト ] ページで、モデルをテストして、目的のエンティティが検出および抽出されていることを確認します。 [ + ファイルの追加] を選択して、モデルをテストするサンプル ファイルを選択します。
![[テスト モデル] ページのスクリーンショット。](../media/content-understanding/prebuilt-sensitive-test-model-2.png)
注:
このモデルでは、暗号化されたファイルから情報が検出または抽出されることはありません。
[ モデルの適用 ] ページで、[ + ライブラリの追加] を選択し、このモデルを適用するライブラリを選択し、[ 追加] を選択します。
![[モデルの適用] ページのスクリーンショット。](../media/content-understanding/prebuilt-sensitive-apply-model-2.png)
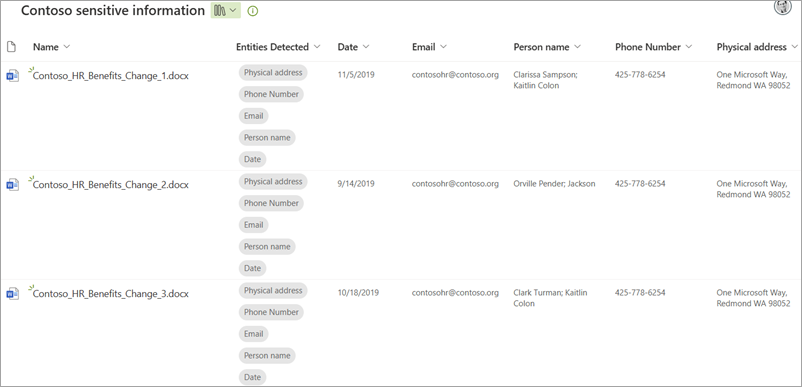
ドキュメント ライブラリでは、検出されたエンティティが [検出された エンティティ ] 列に表示され、抽出用に選択されたエンティティがそれぞれの列に表示されます。
ファイルの種類、言語、光学式文字認識、およびこのモデルに関するその他の考慮事項については、「 Microsoft Syntex のモデルの要件と制限事項」を参照してください。
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示