ご利用のコパイロットの顧客満足度指標を分析する (プレビュー)
分析 ページの 顧客満足 タブでは、平均 CSAT スコア、主要なユーザー クエリ テーマ、コパイロットの応答に対する満足度や不満の要因に関する実用的な洞察など、顧客満足度 (CSAT) 調査データの詳細なビューが提供されます。
既定では、このページには、過去 7 日間の主要業績評価指標が表示されます。 期間を変更するには、ページ上部の日付ピッカーを使用します。 過去 45 日間の任意の期間のデータを取得できます。
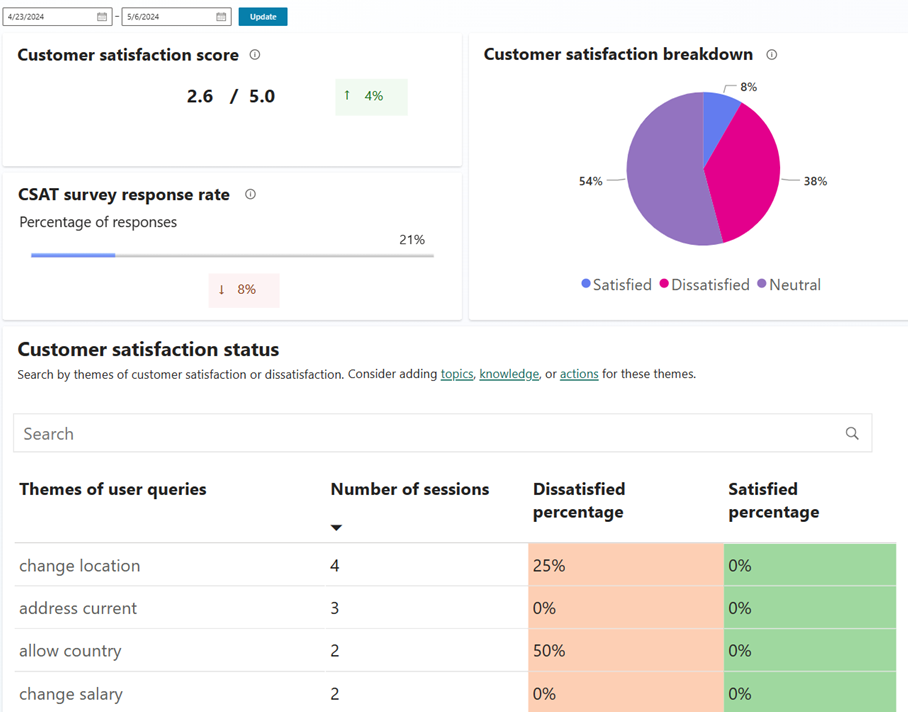
顧客満足度指標
顧客満足度スコア チャートは、顧客が 会話終了時 のアンケート依頼に応じたセッションの CSAT の平均スコアを示すグラフィカル表示を提供します。 CSAT 調査では、顧客に 1 から 5 のスケールで体験を評価するよう求めます。 エンドユーザーが同じセッションで複数のアンケートに回答した場合、最新のアンケートのみが使用されます。
このチャートには、前期比の変化を示す指標も表示されます。 たとえば、3 日間の期間を選択すると、インジケーターには、選択した期間の前の 3 日間と比較したパーセンテージの変化が表示されます。 前期比表示は、コパイロットに前期の CSAT 調査データがある場合にのみ表示されます。 フィルターで選択された期間と同じ期間の CSAT 調査データがない場合、期間ごとのインジケーターは表示されません。
CSAT 調査回答率
CSAT 調査回答率 グラフは、提示された会話終了時の CSAT 調査の数と完了した調査の割合を示します。
顧客満足度内訳
顧客満足度の内訳 グラフには、選択した期間内に満足、不満足、または中立だったセッションの割合が表示されます。 顧客満足度ステータスパネル は、セッション満足度ステータスを判断する際に使用できるさまざまなシグナルの詳細を提供します。
顧客満足度の状態
顧客満足度ステータス グラフは、ユーザーが検索したテーマと、コパイロットの応答に対するユーザーの満足度に関する重要な分析情報を提供します。 類似テーマのセッションは一緒にグループ化されます。 グラフには、選択した期間中の各テーマのセッション数と、満足または不満足だったセッションの割合が表示されます。 満足も不満もなかったセッションは中立セッションとみなされ、このグラフには表示されません。
特定のセッションのテーマは、ML モデルを使用して導出されます。 テーマは分析ダッシュボードに送信される前に、個人情報や電話番号などの機密情報を削除する処理が行われます。 さらに、テーマに卑猥な言葉や有害な言葉が含まれている場合、これらのテーマはマスクされます。
グラフの各セグメントにマウスを合わせると、満足度や不満足度の具体的な要因が表示されます。 特定のセッションでいずれかの基準が当てはまる場合、そのセッションは満足または不満足に分類されます。
セッションは 不満 もし:
- ユーザーは 会話の終わり 調査で 2 つ星以下を付けました。
- ユーザーは、(システムフォールバック トピック) の 2 回以上のクエリを言い換えるように要求されました。
- セッションを終了したユーザー。
- ユーザーはセッションをライブエージェントにエスカレーションしました。
- コパイロットとの会話に対するユーザーの全体的な感情は否定的であると分類されます。 感情は、感情分析用に微調整された公開 ML モデルを使用して決定されます。
セッションは 満足 と考えられます。もし:
- ユーザーは 会話の終わり 調査で 4 つ星以下を付けました。
- ユーザーは、(システムフォールバック トピック) の 1 回以上のクエリを言い換えるように要求されませんでした。
- このセッションは解決済みでした。
- コパイロットとの会話に対するユーザーの全体的な感情は肯定的であると分類されます。
上記の基準のいずれにも該当しないセッションは中立セッションとみなされ、このグラフには表示されません。
分析 ページの 概要タブ では、情報アイコンを使用して、エンゲージメント、エスカレーション、放棄、解決率の詳細を確認できます。
テーマとセッションの感情抽出
Copilot Studio は、自然言語処理 (NLP) 技術を使用してテーマを抽出し、特定のコパイロット セッションに感情を割り当てます。
すべてのセッションで、Copilot Studio は、最初のユーザーの発話からテーマを抽出します。 同様のテーマを持つ個々のセッションは集約され、顧客満足度ステータス チャートに 1 つの項目として表示されます。
セッションの感情を評価するために、基礎となる NLP モデルは公開されている英語のデータセットでトレーニングされます。 このプロセスでは、セッションのテキストを分析して、全体的な感情が肯定的、否定的、または中立的であるかを判断します。 このプロセスでは、ユーザークエリを前処理して誤検知を除去します。 たとえば、この前処理により、"最適なオプションは何ですか?" などのクエリが、クエリに "最適" という単語が含まれているという理由だけで肯定的であると分類されることがなくなります。