Azure Data Factory でエクスポートした Dataverse データを取り込む
Microsoft Dataverse から Azure Synapse Link for Dataverse を使ってAzure Data Lake Storage Gen2 にデータをエクスポートした後、Azure Data Factory を使ってデータフローを作成し、データを変換し、分析を実行することができます。
注意
Azure Synapse Link for Dataverse は以前は、Data Lake へのエクスポートと呼ばれていました。 このサービスは、2021 年 5 月より名称が変更され、Azure Synapse Analytics だけでなく、Azure Data Lake へのデータのエクスポートも継続されます。
この記事では、次のタスクを実行する方法を示します:
Data Lake Storage Gen2 ストレージ アカウントに Data Factory データフローの ソース として Dataverse データを設定します。
データフローを使い、Data Factory で Dataverse データを変換します。
Data Lake Storage Gen2 ストレージ アカウントに Data Factory データフローの シンク として Dataverse データを設定します。
パイプラインを作成してデータフローを実行します。
前提条件
このセクションでは、Data Factory でエクスポートした Dataverse データを取り込むために必要な前提条件について説明します。
Azure ロール。 Azure へのサインインに使用されるユーザー アカウントは、共同作成者、所有者 ロール、または Azure サブスクリプションの 管理者 のメンバーである必要があります。 サブスクリプションで持っているアクセス許可を確認するには、 Azure portal に移動し、右上隅にあるユーザー名を選択し、...、次に アクセス許可 を選択します。 複数のサブスクリプションにアクセスできる場合は、適切なサブスクリプションを選択してください。 Azure portal で Data Factory の子リソース—データセット、リンクされたサービス、パイプライン、トリガー、Integration Runtime を含む—を作成および管理するには、リソース グループレベル 以上の Data Factory 共同作成者 ロールに属している必要があります。
Azure Synapse Link for Dataverse. このガイドでは、Azure Synapse Link for Dataverse を使用して Dataverse のデータをすでにエクスポートしていることを前提としています。 この例では、取引先企業テーブル データが Data Lake にエクスポートされます。
Azure Data Factory。 このガイドは、Dataverse データをエクスポートしたストレージ アカウントと同じサブスクリプションおよびリソース グループの下にデータ ファクトリをすでに作成したことを前提としています。
Data Lake Storage Gen2 ストレージ アカウントをソースとして設定する
Azure Data Factory を開き、Dataverse データをエクスポートしたストレージ アカウントと同じサブスクリプションおよびリソース グループにあるデータ ファクトリを選択します。 そして、ホーム ページからデータ フローを作成を選択します。
Data Flow デバッグモードをオンにし、希望する存続時間を選択します。 これには最大 10 分かかる場合がありますが、次の手順に進むことができます。

ソースの追加 を選択します。

ソース設定で、次の手順を実行します。
- 出力ストリーム名: 希望する名前を入力します。
- ソースの種類: インラインを選択します。
- インライン データセット タイプ: Common Data Model を選択します。
- リンクされたサービス: ドロップダウン メニューからストレージ アカウントを選択し、サブスクリプションの詳細を入力し、すべての既定の構成をそのまま使用して、新しいサービスをリンクします。
- サンプリング: すべてのデータを使用する場合は、無効 を選択します。
ソース オプション で、次の手順を実行します:
メタデータ形式: Model.json を選択します。
ルートの場所: 最初のボックス (コンテナ) またはコンテナ名の参照にコンテナ名を入力し、OK を選択します。
エンティティ: テーブル名またはテーブルの参照を入力します。

プロジェクションタブをクリックして、スキーマが正常にインポートされたことを確認します。 列が表示されない場合は、スキーマ オプションを選び、ドリフトした列タイプを推測オプションを確認します。 データ セットに一致するようにフォーマット オプションを構成し、適用を選択します。
データ プレビュータブで自分のデータを表示し、ソース作成が完全かつ正確であることを確認できます。
Dataverse データを変換
Azure Data Lake Storage Gen2 アカウントにエクスポートされた Dataverse のデータを、Data Factory のデータフローでソースとして設定した後は、データを変換するための様々な可能性があります。 詳細: Azure Data Factory
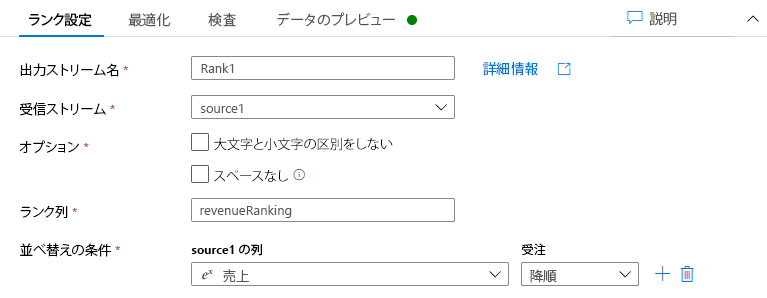
次の手順に従って、取引先企業テーブルの売上フィールドで各行のランクを作成します。
以前の変換の右下隅で + を選び、検索してランクを選択します。
ランク設定 タブで、次項を行います。
出力ストリーム名: ランク 1 のような希望する名前を入力します。
受信ストリーム: 希望するソース名を選択します。 この場合、前のステップからのソース名です。
オプション: オプションをオフのままにします。
ランク列: 生成されたランク列の名前を入力します。
並べ替え条件: 売上列を選び、降順で並べ替えます。
一番右の位置に新しい revenueRank 列があるデータ プレビューで、自分のデータを表示できます。
Data Lake Storage Gen2 ストレージ アカウントをシンクとして設定
最終的に、データフローのシンクを設定する必要があります。 次の手順に従って、区切りのあるテキスト ファイルとして変換されたデータを Data Lake に配置します。
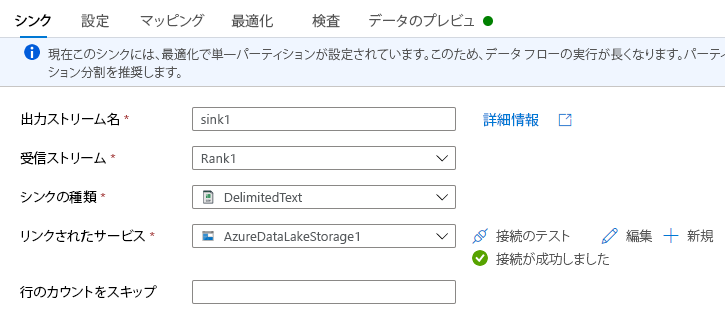
以前の変換の右下隅で + を選び、検索してシンクを選択します。
シンク タブで、次の手順を実行します:
出力ストリーム名: 希望する名前 (シンク1 など) を入力します。
受信ストリーム: 希望するソース名を選択します。 この場合、前のステップからのソース名です。
シンク タイプ: DelimitedText を選択します。
リンクされたサービス: Azure Synapse Link for Dataverse サービスを使ってエクスポートしたデータがある Data Lake Storage Gen2 ストレージ コンテナーを選択します。
設定 タブで、次の操作を行います:
フォルダー パス: 最初のボックス (ファイル システム) またはコンテナ名の参照にコンテナ名を入力し、OK を選択します。
ファイル名のオプション: 単一ファイルへの出力を選択します。
単一ファイルへの出力: ADFOutput のようなファイル名を入力
他のすべてのデフォルト設定のままにします。
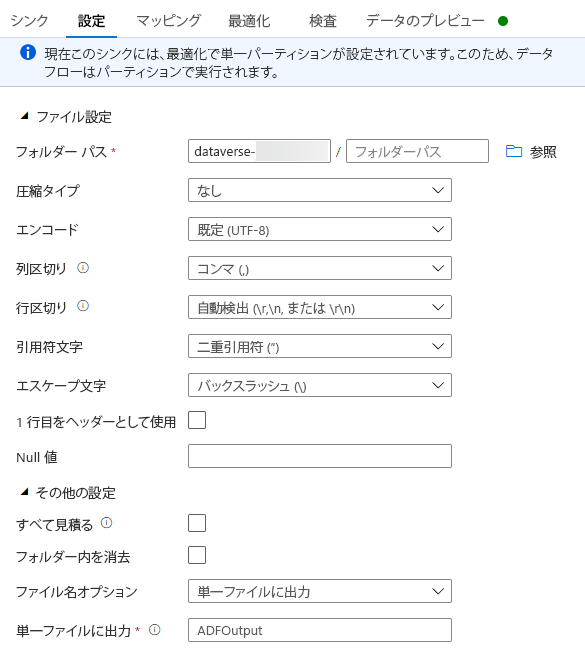
最適化タブで、パーティションのオプションを単一パーティションに設定します。
データ プレビュー タブで、自分のデータを表示できます。
データフローを実行する
左側のペインの ファクトリ リソース で + を選択し、次に パイプライン を選択します。

活動 で、移動と変換 を選択し、次に データ フロー をワークスペースにドラッグします。
既存のデータ フローの使用を選択し、前の手順で作成したデータフローを選択します。
コマンド バーから デバッグ を選択します。
完了したことが下部ビューに表示されるまで、データフローを実行します。 この処理には数分かかる場合があります。
最終移動先のストレージ コンテナーに移動して、変換されたテーブル データ ファイルを検索します。
関連項目
Azure Data Lake を使用して Azure Synapse Link for Dataverse を構成する
Power BI による Azure Data Lake Storage Gen2 の Dataverse データの分析
注意
ドキュメントの言語設定についてお聞かせください。 簡単な調査を行います。 (この調査は英語です)
この調査には約 7 分かかります。 個人データは収集されません (プライバシー ステートメント)。