データの変換とマッピング
使用するデータ ソースを選択すると、Power Query エディターが表示されます。 Query Editor は、データを変換するための強力なツールです。 詳細については、Power Query ユーザー インターフェイスを参照してください。
データを変換する理由のいくつかは次のとおりです。
ログに記録されるすべてのアクティビティ名に関心があるとは限らないため、マイニングしようとしているプロセスにとって重要な特定のアクティビティ名をフィルタリングする必要があります。
説明的かつ理解しやすいように、一部のアクティビティ名の名前を変更することをお勧めします。 これは、データベース内の名前でないことがよくあります。
データの履歴全体ではなく、特定のデータ範囲のみに関心がある可能性もあります。
複数の ID 列を組み合わせてケース ID を作成することをお勧めします。 これは、プロセス マイニングに使用する ID が存在しない場合、またはアプリケーション内の複数の ID の組み合わせである場合によく行われます。 たとえば、顧客がサポート チケットを提出すると、サポート チケットが複数の顧客サービス エージェントに割り当てられる場合があります。 各エージェントが各チケットをどのように処理するかを分析する場合は、エージェント ID とチケット ID を組み合わせてケース ID にします。
アクティビティ名をフィルターする
アクティビティ名列の横にあるカラットを選択して、並べ替えとフィルターのメニューを表示します。
リストが完全でない可能性がありますというメッセージがある場合、さらに読み込むを選択します。
分析するアクティビティ名のみを選択します。 除外する名前のチェックを解除します。
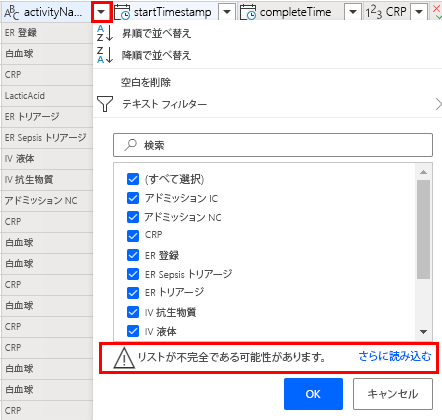
または、高度なフィルタリングのためにテキスト フィルター メニューを使用できます。 値によるフィルタリングの詳細については、列の値でフィルタリングするにアクセスしてください。
アクティビティの名前変更
- アクティビティ名列が選択されていることをを確認してください。
- ツール バーの上で、変換タブを選択します。
- ツールバーで、フィールドを 値の置換を選択します。
- 検索する値の下で、置き換えるデータ ソースに表示されるアクティビティ名を入力します。
- 置換先の下に、プロセス マップに表示するアクティビティ名を入力します。
- 置き換えるすべての値に対してこのプロセスを繰り返します。
合計レコード数を減らす
レコードの合計数を減らすための 1 つの戦略は、最新のレコードのみを使用することです。 これを行うには、最初にデータを時間で並べ替える必要があります。
startTimestamp 列の横にあるカラットを選択して、並べ替えとフィルターのメニューを開きます。
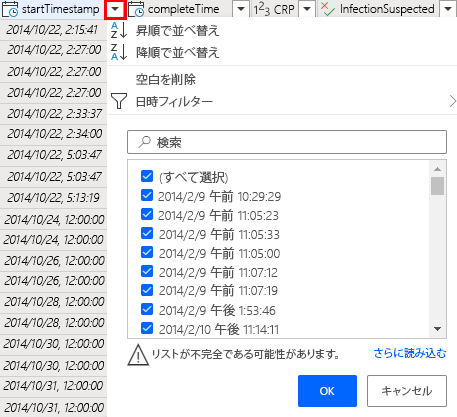
最新のレコードを最初に表示するには、降順で並べ替えを選択します。
OK を選択してから、ツールバーで行の保持を選択します。
行数の下に 150000 を入力します。
OK を選択して、上位 15 万行のフィルタリングを行います。
複数の ID を結合する
Ctrl + クリックを使用して、結合する複数列を選択します。
- [変換] タブ ツールバーで、列のマージを選択します。
- (オプション) ドロップダウン リストから区切り記号を選択します。 または、なしを選択できます。
- 名前を変更して (または生成されたデフォルト名をメモして)、ケース ID にマッピングするときに名前を選択できるようにします。
データをマップする
マッピングは、どの列がどの属性タイプ (たとえば、ケース ID、アクティビティ名、タイムスタンプ) にマッピングされているかをプロセス マイニング機能に伝えます。
- マッピング画面に移動するには、次へを選択します。
- それぞれの列の横にあるドロップダウン メニューを使用して、属性タイプを選択します。 詳細については、属性タイプの説明を参照してください。
- CSV ファイル形式を使用して Azure Data Lake Gen2 からデータが取り込まれる場合、データの種類 列のドロップダウン メニューを使用して、インポートのデータの種類を変更できます。 数値を持つ列の場合、属性が連続値 (たとえば、請求書金額が Number に設定) であるか、カテゴリ値 (たとえば、品目コードが Text に設定) であるかの分析的使用法を検討します。
- ケース ID、アクティビティ、開始タイムスタンプは、分析を続行するための必須属性です。
- プロセスの分析を開始するには、保存と分析 を選択します。
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示