Power BI の Q&A を最適化するためのベスト プラクティス
データに関する質問に、一般的な語句と自然言語を使うのは効果的です。 データが回答になる場合にはさらに効果的です。それが Power BI の Q&A 機能の特長です。
Q&A が回答可能な質問の大規模なコレクションを正常に解釈できるようにするために、Q&A はモデルについて推測を行います。 ご使用のモデルの構造がこれらの推測の 1 つ以上に該当しない場合は、モデルを調整する必要があります。 Q&A のこれらの調整は、Q&A を使うかどうかに関係なく、Power BI のどのモデルに対しても同じ最適化のベスト プラクティスです。
Q&A ツールを使用して質問を修正する
次のセクションでは、Power BI の Q&A でうまく機能するためにモデルを調整する方法について説明します。 Q&A ツールを使うと、主要なビジネス用語を Q&A に教えて、エンド ユーザーからの質問を修正することができます。 データの形が正しくない、またはデータが欠落しているために、質問によっては対処できない場合があります。 この場合は、以下のセクションを読んで Q&A を最適化してください。 詳細については、Q&A ツールの概要に関する記事を参照してください。
欠落しているリレーションシップを追加する
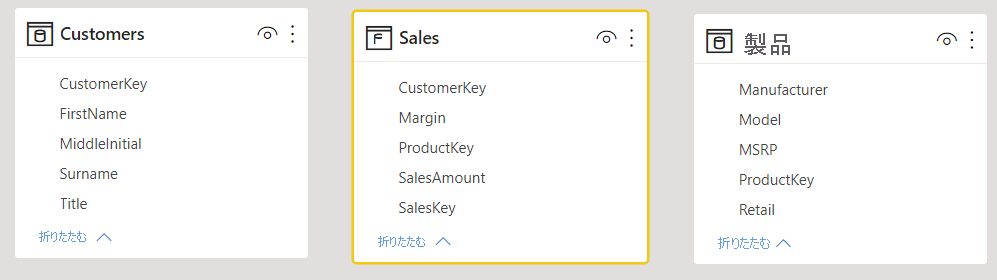
モデルでテーブル間のリレーションシップが欠落している場合、Power BI レポートと Q&A はそれらのテーブルを結合する方法を解釈できません。 リレーションシップは、優れたモデルの基礎となります。 たとえば、orders (注文) テーブルと customers (顧客) テーブルとの間のリレーションシップが欠落している場合、"total sales for Seattle customers" (シアトルの顧客の総売上) という質問をすることはできません。 次の画像では、作業を必要とするモデルと、Q&A の準備ができているモデルを示します。
作業が必要
最初の画像では、Customers (顧客) テーブル、Sales (売上高) テーブル、Products (製品) テーブルの間にリレーションシップはありません。
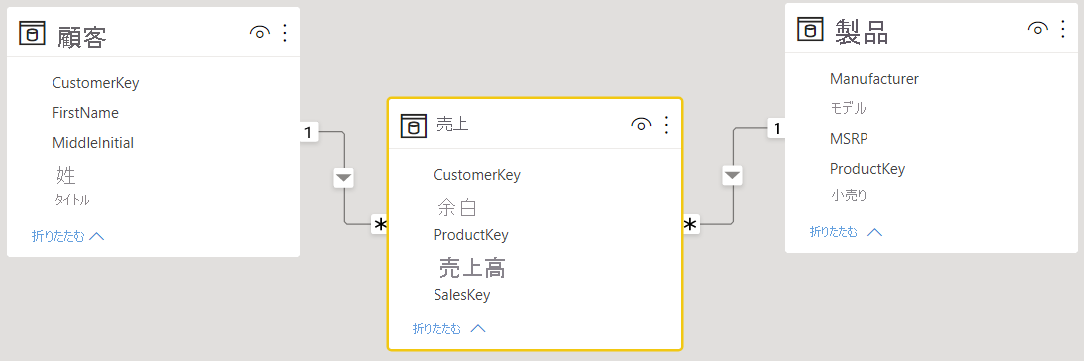
Q&A の準備がてきている
2 番目の画像では、テーブル間にリレーションシップが定義されています。
テーブルと列の名前を変更する
テーブルと列の選択は Q&A にとって重要です。 たとえば、ご自身の顧客のリストが含まれる CustomerSummary という名前のテーブルがあるとします。 "List the customers in Chicago" (シカゴの顧客を一覧表示する) ではなく、"List the customer summaries in Chicago" (シカゴの顧客の概要を一覧表示する) などと質問する必要があります。
Q&A では、いくつかの基本的な単語区切りと複数形の検出は実行できますが、テーブル名と列名がそのコンテンツを正確に反映していることを前提とします。
別の例として、従業員の氏名と従業員番号が含まれる Headcount という名前のテーブルがあるとします。 もう 1 つのテーブルは、従業員番号、ジョブ番号、開始日が含まれる Employees という名前のテーブルです。 そのモデルに詳しい人は、この構造を理解できる可能性があります。 誰かが "従業員の数は" と質問すると、"Employees" テーブルからその行の数を取得します。 これは、今まで各従業員が受け持ったことのあるすべてのジョブの数であるため、この結果はおそらく意図していたものではありません。 内容をきちんと反映するようにテーブルの名前を変更することをお勧めします。
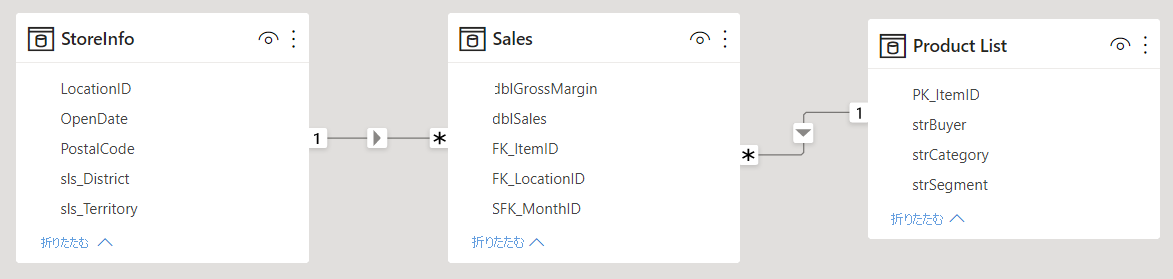
作業が必要
StoreInfo(店舗情報) や Product List (製品リスト) などのテーブル名は作業が必要です。
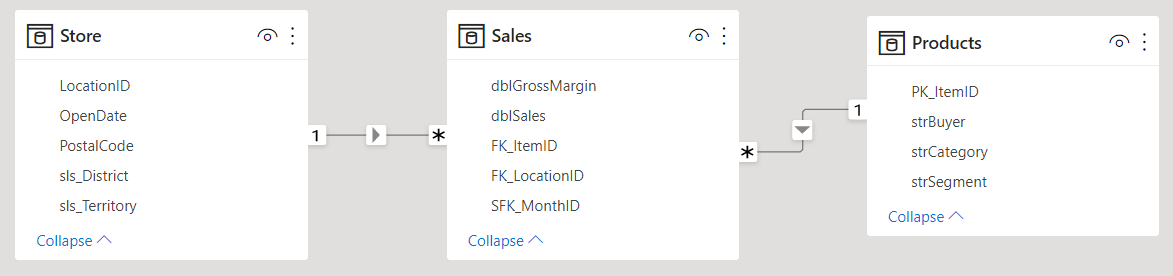
Q&A の準備がてきている
Store (店舗) および Products (製品) という名前のテーブルはより効果的に機能します。
不正なデータ型を修正する
インポートされたデータが不正なデータ型の場合があります。 特に、string としてインポートされた date と number の列は、Q&A で date や number として解釈されません。 ご利用の Power BI モデルで正しいデータ型を選びます。

年と識別子の列の設定を変更する
Power BI では、既定で数値列が集計されるため、"total sales by year" (年ごとの総売上) といった質問には、年の総合計とともに、売上の総合計も返される場合があります。 特定の列で Power BI がこのように動作しないようにする必要がある場合は、その列の [既定の概要] プロパティを [集計しない] に設定します。 年、月、日、ID の列は、よく問題になる列なので、注意してください。 集計しても意味がないその他の列 (年齢など) も、[既定の集計] を [集計しない] または [平均] に設定しておくとよいでしょう。 この設定は、列を選んだ後の [プロパティ] セクションにあります。

日付と地理の各列にデータ カテゴリを選択する
[データ カテゴリ] には、データ型以外に、列のコンテンツに関する情報が表示されます。 たとえば、整数型の列を郵便番号としてマークし、文字列型の列を市区町村、国/地域としてマークすることができます。 この情報は、Q&A では 2 つの重要な使い道があります。視覚化の選択と言語の偏りです。
最初に、Q&A はデータ カテゴリの情報を使用して、使用するビジュアル表示の種類を選択します。 たとえば、日付または時刻のデータ カテゴリの列は、線グラフの横軸またはバブル チャートの再生軸に適していると認識します。 地理的なデータ カテゴリの列を含む結果は、マップでの表示が適していると判断します。
次に、Q&A は、特定の種類の質問を理解するのに役立てるため、ユーザーが日付と地理の列についてどのように話すかについて、経験に基づく推測を行います。 たとえば、"John Smith が入社したのはいつか" の "いつ" は、 日付列にほぼ確実にマップされ、"ブラウンの顧客をカウントする" の "ブラウン" は、髪の色よりも都市にマップされる可能性がより高くなります。

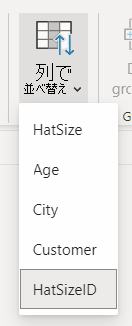
関連する列に [列で並べ替え] を選択する
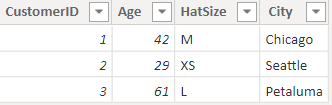
[列で並べ替え] プロパティは、1 つの列を並べ替えることで、代わりに別の列を自動的に並べ替えることができます。 たとえば、"帽子のサイズで顧客を並べ替える" という場合は、帽子のサイズの列をアルファベット順 (L、M、S、XL、XS) ではなく、基になるサイズ番号 (XS、S、M、L、XL) で並べ替えることができます。
モデルの正規化
モデル全体を整形し直す必要はありません。 ただし、各構造は非常に難しく、Q&A で適切に処理されないことがあります。 モデルの構造の基本的な正規化をいくつか実行すると、Power BI レポートの使いやすさと、Q&A の結果の精度が大幅に向上します。
次の一般規則に従います。ユーザーが話す一意の "もの" それぞれを 1 つのモデル オブジェクト (テーブルまたは列) で表す必要があります。 そのため、ユーザーが顧客について話す場合は、顧客オブジェクトが 1 つ必要です。 ユーザーが売上について話す場合は、売上オブジェクトが 1 つ必要です。 クエリ エディターでは、必要に応じて豊富なデータ整形機能を使用できます。 Power BI モデルで計算を使うと、より単純な変換を調整できます。
次のセクションでは、実行が必要な場合がある一般的な変換のいくつかを紹介します。 モデルの正規化の詳細については、「スター スキーマと Power BI での重要性を理解する」の正規化と非正規化に関する記事を参照してください。
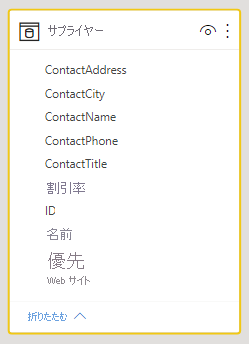
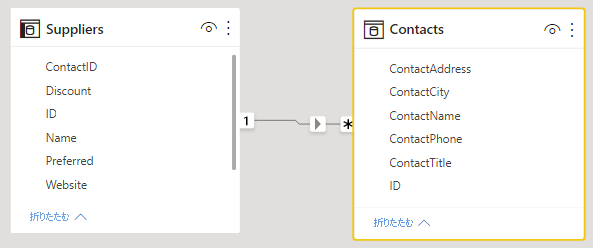
複数列エンティティ用に新しいテーブルを作成する
大きなテーブル内の 1 つの個別単位として機能する複数の列がある場合、それらの列を分割して、独自のテーブルにする必要があります。 たとえば、Companies テーブル内に Contact Name (担当者の名前)、Contact Title (担当者の肩書)、Contact Phone (担当者の電話番号) の列があるとします。 Name (名前)、Title (肩書)、Phone (電話番号) が含まれる Contacts テーブルを別途作成し、Companies テーブルにリンクで戻るほうがより優れた設計です。 連絡先の会社に関する質問とは別に、連絡先に関する質問がしやすくなり、表示の柔軟性も向上します。
作業が必要
Q&A の準備がてきている
プロパティ バッグを排除するピボット
モデルにプロパティ バッグがある場合は、プロパティごとに 1 つの列になるように再構成する必要があります。 プロパティ バッグは、多数のプロパティを管理するのに便利ですが、固有の制限があり、Power BI レポートと Q&A の設計ではこれらを回避できません。
たとえば、CustomerID、Property、Value の列があり、各行が顧客の異なるプロパティ (年齢、結婚歴、または市区町村) を表す CustomerDemographics というテーブルについて考えてみましょう。 Property (プロパティ) 列のコンテンツに基づいて Value (値) 列の意味を多重定義すると、Q&A がそれを参照するほとんどのクエリを解釈できなくなります。 "各顧客の年齢を表示する" などの単純な質問は機能するかもしれません。それは "プロパティが年齢の顧客と顧客層を表示する" と解釈される可能性があるからです。 しかし、このモデルの構造では、"average age of customers in Chicago" (シカゴの顧客の平均年齢) などのもう少し複雑な質問はまったくサポートされません。 Power BI レポートを直接作成しているユーザーは、場合によっては探しているデータを取得する巧妙な方法を見つけることができますが、Q&A は各列に 1 つの意味がある場合に機能します。
作業が必要
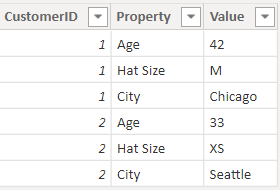
Q&A の準備がてきている
結合してパーティション分割を排除する
複数のテーブル間でデータをパーティション分割している場合、または複数の列にまたがるピボット値がある場合、ユーザーにとって一部の一般的な操作が困難になるか、まったく実行できなくなります。 最初に、Sales2000-2010 テーブルと Sales2011-2020 テーブルという、一般的なテーブルのパーティション分割を考えてみましょう。 重要なレポートのすべてが特定の 10 年間に限定されている場合は、Power BI レポート用にこのまま残しておくことができます。 しかし、Q&A の柔軟性を高めることにより、ユーザーは "total sales by year" (年別の総売上) などの質問に対する回答を期待できるようになります。 このクエリが機能するには、データを 1 つの Power BI モデル テーブルに結合する必要があります。
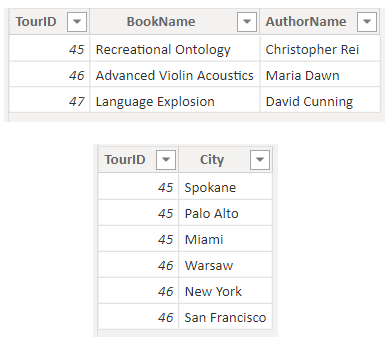
同様に、一般的なピボット値の列を考えてみましょう。BookTour テーブルには、Author (著者)、Book (書籍)、City1 (市区町村1)、City2 (市区町村2)、および City3 (市区町村3) の列が含まれています。 このような構造では、"count books by city" (市区町村ごとの書籍をカウントする) といった単純な質問でも、正しく解釈できません。 このクエリを機能させるには、City の値を 1 つの列に結合した BookTourCities テーブルを個別に作成します。
作業が必要

Q&A の準備がてきている
書式設定された列の分割
書式設定された列がデータのインポート元に含まれている場合、Power BI レポート (および Q&A) は列内に到達できず、そのコンテンツを解析できません。 そのため、たとえば、番地、市区町村、国/地域を含む Full Address 列がある場合、それも Address、City、CountryRegion の列に分割して、ユーザーがそれらに対して個別に照会できるようにします。
作業が必要
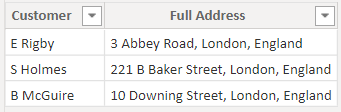
Q&A の準備がてきている

同様に、人のフルネームの列がある場合、ユーザーが名前の一部を使用して質問したい場合に備えて、First Name (姓) とLast Name (名) の列を追加します。
複数値の列用に新しいテーブルを作成する
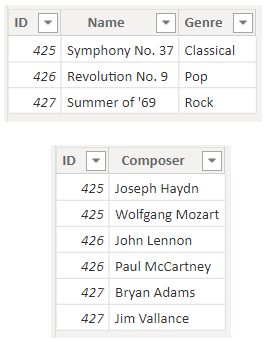
データのインポート元に複数値の列が含まれている場合も同様に、Power BI レポート (および Q&A) は列内に到達できず、その内容を解析できません。 そのため、たとえば、1 つの曲に対して複数の作曲家の名前を含む Composer (作曲家) 列がある場合、それを別の Composer テーブルの複数の行に分割します。
作業が必要

Q&A の準備がてきている
非正規化して非アクティブなリレーションシップを削除する
"正規化の方が適している" という規則の 1 つの例外は、あるテーブルから別のテーブルに到達するために複数のパスがある場合です。 たとえば、それぞれが Cities (都市) テーブルに関連付けられている SourceCityID (出発地 ID) 列と DestinationCityID (目的地 ID) 列の両方がある Flights (フライト) テーブルがあるとします。 これらのリレーションシップの 1 つを非アクティブとしてマークする必要があります。 Q&A ではアクティブなリレーションシップしか使用できないため、選択に応じて、出発地または目的地のいずれかに関する質問ができません。 代わりに、都市名の列を Flights テーブルに非正規化すると、"ist the flights for tomorrow with a source city of Seattle and a destination city of San Francisco" (出発地がシアトルで目的地がサンフランシスコの明日のフライトを一覧表示する) といった質問ができます。
作業が必要
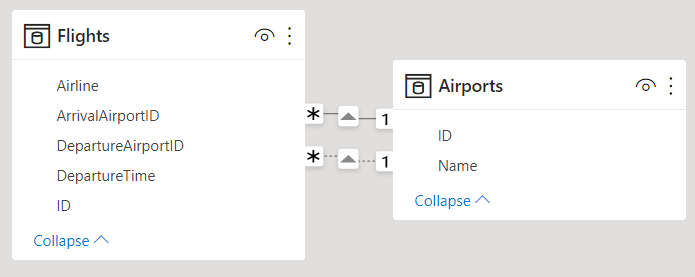
Q&A の準備がてきている
テーブルと列にシノニムを追加する
この手順は、特に Q&A に適用され、Power BI レポートには通常適用されません。 たとえば、総売上高、正味売上高、正味総売上高のように、同じものを指すのに多数の用語を使うことがよくあります。 これらのシノニムを Power BI モデルのテーブルおよび列に追加できます。
この手順は重要である場合があります。 テーブル名や列名が単純であっても、Q&A のユーザーは、最初に思いついたボキャブラリを使用して質問をします。 ユーザーは、定義済みの列の一覧から選択することはありません。 より実際的な同意語を追加するほど、レポートでのユーザーのエクスペリエンスが向上します。 同意語を追加するには、Power BI Desktop で [モデル] タブを選んで [モデル] ビューに移動してから、フィールドまたはテーブルを選びます。 [プロパティ] ペインに [シノニム] ボックスが表示されます。このボックスでシノニムを追加できます。
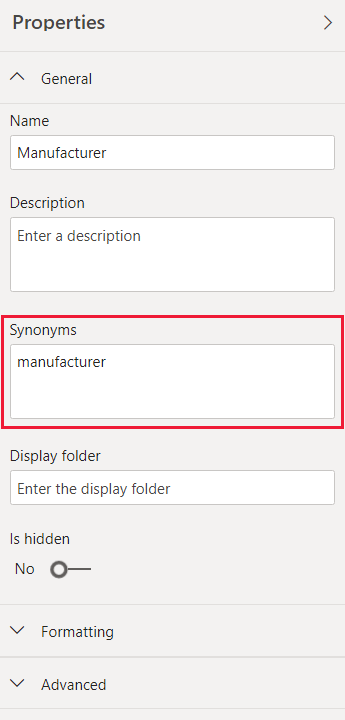
同じ同意語を複数の列またはテーブルに追加すると、あいまいさが生じるので注意してください。 Q&A は、あいまいなシノニムの中から選択できる場合はコンテキストを使用しますが、すべての質問に十分なコンテキストがあるとは限りません。 たとえば、ユーザーが "count the customers" (顧客をカウントする) と質問した場合、モデル内に "顧客" の同意語が 3 つあると、ユーザーが探している回答を取得できない可能性があります。 このような場合は、プライマリ同意語を一意にします。その同意語は言い換えで使われるものだからです。 こうすることで、ユーザーにあいまいさを警告して、別の言い方 (たとえば、"アーカイブされた顧客レコードの数を表示する" といった言い換え) で質問できる可能性を示唆することができます。