ユーザー定義集計
Power BI の集計を使用すると、大規模な DirectQuery セマンティック モデルに対するクエリのパフォーマンスを向上させることができます。 集計を使用することで、集計されたレベルのデータをメモリ内にキャッシュします。 Power BI の集計は、この記事で説明するように、データ モデルで手動で構成できます。 Premium サブスクリプションの場合は、モデル設定で 自動集計 機能を有効にして自動的に行います。
集計テーブルの作成
データ ソースの種類に応じて、集計テーブルをテーブルまたはビューのネイティブ クエリとしてデータ ソースに作成できます。 パフォーマンスを最大限に高めるには、Power Query で作成されたインポート テーブルとして集計テーブルを作成します。 次に、Power BI Desktop の [集計の管理] ダイアログを使用して、概要、詳細テーブル、詳細列のプロパティを持つ集計列の集計を定義します。
データ ウェアハウスやデータ マートなどのディメンション データ ソースでは、リレーションシップベースの集計を使用できます。 Hadoop ベースのビッグデータ ソースは、多くの場合、GroupBy 列での集計に基づきます。 この記事では、データ ソースの種類ごとに、一般的な Power BI データ モデリングの違いについて説明します。
集計を管理する
任意の Power BI Desktop ビューの [データ] ペインで、集計テーブルを右クリックし、[集計の管理] を選択します。
![[集計の管理] の選択のスクリーンショット。](media/aggregations-advanced/aggregations-06-2.png)
[集計の管理] ダイアログでは、テーブル内の各列の行が表示され、ここで集計動作を指定することができます。 次の例では、Sales 詳細テーブルに対するクエリが、内部的に Sales Agg 集計テーブルにリダイレクトされます。
![[集計の管理] ダイアログ ボックスが表示されているスクリーンショット。](media/aggregations-advanced/aggregations_07.png)
このリレーションシップベースの集計例では、GroupBy エントリは省略可能です。 DISTINCTCOUNT を除き、これらは集計の動作には影響せず、主に読みやすくするためのものです。 GroupBy エントリがなくても、集計には、リレーションシップに基づいてヒットします。 これは、この記事の後半の、GroupBy エントリを必要とする、ビッグ データの例とは異なります。
確認
[集計の管理] ダイアログでは、次の検証が適用されます。
- [詳細列] には、カウントとテーブル行数のカウントの概要関数を除き、 [集計列] と同じデータ型がある必要があります。 カウントおよびテーブル行数のカウントは、整数の集計列でのみ使用でき、一致するデータ型は必要ありません。
- 3 つ以上のテーブルをカバーするチェーン集計は許可されていません。 たとえば、テーブル A の集計では、テーブル C を参照する集計を含むテーブル B を参照することはできません。
- 2 つのエントリで同じ概要関数を使用し、同じ詳細テーブルと詳細列を参照する重複した集計は許可されません。
- 詳細テーブルでは、インポートではなく、DirectQuery ストレージ モードを使用する必要があります。
- 非アクティブなリレーションシップによって使用される外部キー列によるグループ化と、集計ヒットの USERELATIONSHIP 関数への依存はサポートされていません。
- GroupBy 列に基づく集計には、集計テーブル間のリレーションシップを活用できますが、Power BI Desktop では、集計テーブル間のリレーションシップの作成はサポートされていません。 必要な場合は、サードパーティ製ツールまたは XML for Analysis (XMLA) エンドポイントを介したスクリプト ソリューションを使用して、集計テーブル間のリレーションシップを作成することができます。
ほとんどの検証は、ドロップダウンの値が無効になり、ヒントに説明文が表示されるという方法で実施されます。
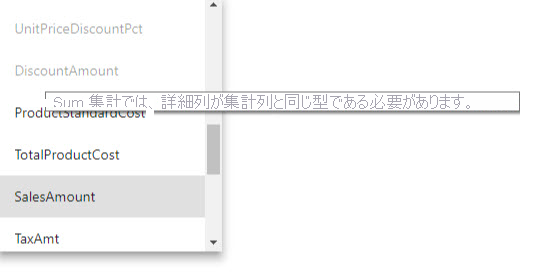
集計テーブルが非表示になっている
モデルへの読み取り専用アクセス権を持つユーザーは、集計テーブルにクエリを実行できません。 読み取り専用アクセスは、"行レベルのセキュリティ (RLS)" とともに使用する場合のセキュリティの問題が回避されます。 コンシューマーとクエリでは、集計テーブルではなく、詳細テーブルが参照されるため、集計テーブルについて知る必要はありません。
このため、集計テーブルは [レポート] ビューでは非表示になります。 テーブルがまだ非表示になっていない場合は、[集計の管理] ダイアログで [すべて適用] を選択したときに非表示に設定されます。
ストレージ モード
集計機能は、テーブルレベルのストレージ モードと連動します。 Power BI テーブルでは "DirectQuery"、"インポート"、または "デュアル" ストレージ モードを使用することができます。 DirectQuery ではバックエンドに直接クエリを実行し、インポートではメモリにデータをキャッシュし、キャッシュされたデータにクエリを送信します。 Power BI のインポートと非多次元の DirectQuery のすべてのデータ ソースは、集計で動作することができます。
クエリを高速化するために集計テーブルのストレージ モードをインポートに設定するには、Power BI Desktop の [モデル] ビューで集計テーブルを選択します。 [プロパティ] ペインで、 [詳細] を展開し、 [ストレージ モード] の下の選択肢をドロップダウンして、 [インポート] を選択します。 インポートの変更は元に戻すことができません。
![[ストレージ モード] プロパティの選択のスクリーンショット。](media/aggregations-advanced/aggregations-04-2.png)
テーブルのストレージ モードの詳細については、「Power BI Desktop でストレージ モードを管理する」を参照してください。
集計の RLS
集計を正しく機能させるには、RLS 式で集計テーブルと詳細テーブルをフィルター処理する必要があります。
以下の例では、集計で Geography テーブルの RLS 式が機能します。これは、Geography が、Sales テーブルと Sales Agg テーブルに対するリレーションシップをフィルター処理する側にあるためです。 集計テーブルにヒットしたクエリと、RLS が正常に適用されていないクエリ。
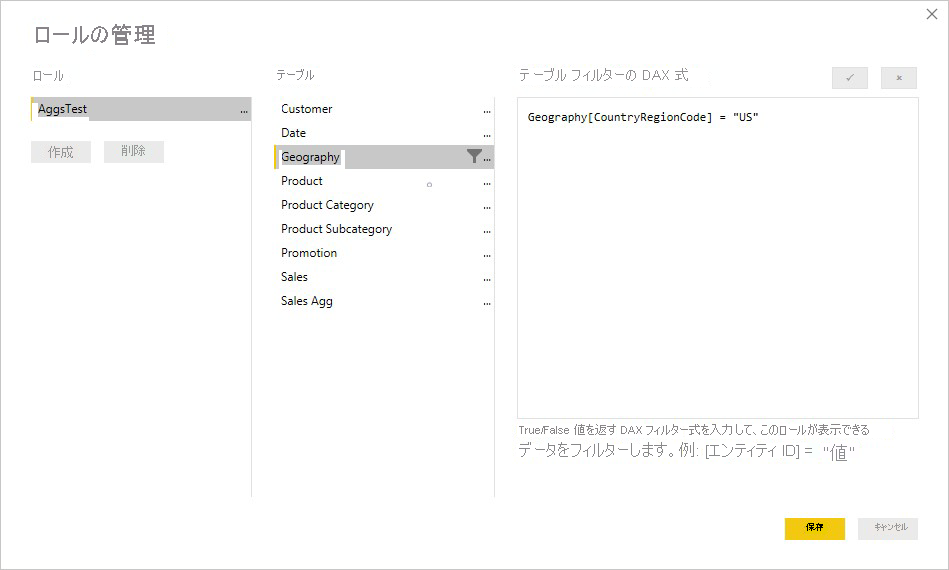
Product テーブルの RLS 式では、集計された Sales Agg テーブルではなく、詳細な Sales テーブルのみをフィルター処理します。 集計テーブルは詳細テーブルでデータを別の方法で表現したものであり、RLS フィルターを適用できない場合は、集計テーブルからのクエリに応答するのは安全ではありません。 詳細テーブルのみをフィルター処理することはお勧めできません。これは、このロールからのユーザー クエリでは、集計ヒットの利点が得られないためです。
Sales の詳細テーブルではなく、Sales Agg 集計テーブルのみをフィルター処理する RLS 式は許可されません。

GroupBy 列に基づく集計の場合、詳細テーブルに適用された RLS 式を使用して、集計テーブルをフィルター処理することができます。これは、集計テーブル内のすべての GroupBy 列が詳細テーブルの対象であるためです。 一方、集計テーブルの RLS フィルターは詳細テーブルに適用できないため、許可されません。
リレーションシップに基づく集計
ディメンション モデルでは通常、"リレーションシップに基づく集計" が使用されます。 データ ウェアハウスおよびデータ マートからの Power BI モデルは、ディメンション テーブルとファクト テーブル間のリレーションシップを持つ、スターまたはスノーフレーク スキーマと似ています。
次の例では、モデルにより、1 つのデータ ソースからデータが取得されます。 テーブルには DirectQuery ストレージ モードが使用されています。 Sales ファクト テーブルには、数十億の行が含まれています。 Sales のストレージ モードをキャッシュのためにインポートに設定すると、かなりの量のメモリが消費され、多額のリソース オーバーヘッドがかかります。
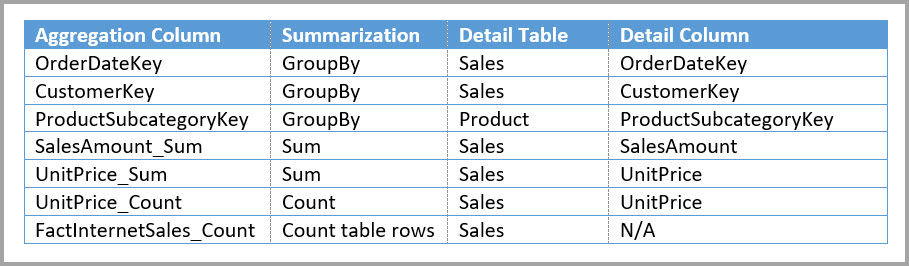
代わりに、Sales Agg 集計テーブルを作成します。 Sales Agg テーブルでは、行数は CustomerKey、DateKey、ProductSubcategoryKey でグループ化された SalesAmount の合計と等しくなります。 Sales Agg テーブルは Sales よりも粒度が高いので、数十億ではなく、数百万の行が含まれている可能性があり、管理が簡単です。
次のディメンション テーブルがビジネス価値の高いクエリで最もよく使用されている場合は、"一対多" または "多対一" のリレーションシップを使用して、Sales Agg をフィルター処理できます。
- 地理
- Customer
- 日付
- Product Subcategory
- 製品カテゴリ
次の図に、このモデルを示します。
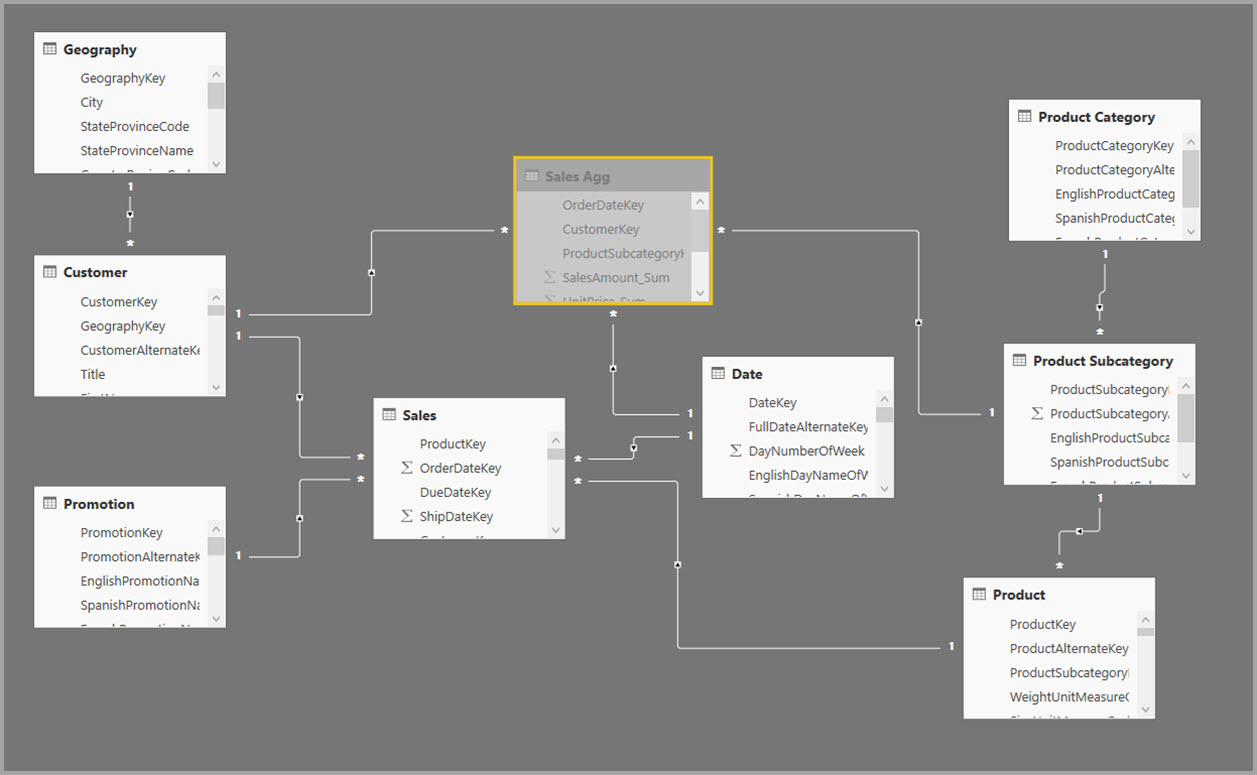
次のテーブルは、Sales Agg テーブルの集計を示しています。
注意
他のテーブルと同じように、Sales Agg テーブルには、さまざまな方法で読み込める柔軟性があります。 集計は、ソース データベースで ETL または ELT プロセスを使用するか、テーブルの M 式で実行できます。 集計テーブルでは、データベースの増分更新の有無にかかわらず、インポート ストレージ モードを使用できます。または DirectQuery を使用して、列ストア インデックスを使って高速クエリ用に最適化することもできます。 この柔軟性により、ボトルネックを避けるためにクエリの負荷を分散できる分散アーキテクチャが可能になります。
集計された Sales Agg テーブルのストレージ モードを [インポート] に変更すると、関連するディメンション テーブルを "デュアル" ストレージ モードに設定できることを示すダイアログ ボックスが開きます。
![[ストレージ モード] ダイアログ](media/aggregations-advanced/aggregations_05.png)
関連するディメンション テーブルを [デュアル] に設定すると、サブクエリに応じて、インポートまたは DirectQuery として機能させることができます。 この例では次のとおりです。
- インポート モードの Sales Agg テーブルからメトリックを集計し、関連するデュアル テーブルからの属性でグループ化するクエリは、メモリ内キャッシュから返すことができます。
- DirectQuery の Sales テーブルからメトリックを集計し、関連するデュアル テーブルからの属性でグループ化するクエリは、DirectQuery モードで返すことができます。 GroupBy 操作を含む、クエリ ロジックは、ソース データベースに渡されます。
デュアル ストレージ モードの詳細については、「Power BI Desktop でストレージ モードを管理する」を参照してください。
標準対制限付きリレーションシップ
リレーションシップに基づく集計ヒットには、標準リレーションシップを使用する必要があります。
標準リレーションシップにおけるストレージ モードは、両方のテーブルが単一ソースからのものである、以下の組み合わせになります。
| "多" 側のテーブル | 1 側のテーブル |
|---|---|
| デュアル | デュアル |
| インポート | インポートまたはデュアル |
| DirectQuery | DirectQuery またはデュアル |
"ソース間" のリレーションシップが標準と見なされる唯一のケースは、両方のテーブルがインポートに設定されている場合です。 多対多リレーションシップは常に制限付きと見なされます。
リレーションシップに依存しない "ソース間" の集計のヒットについては、「GroupBy 列に基づく集計」を参照してください。
リレーションシップベースの集計クエリの例
次のクエリでは、Date テーブル内の列が集計をヒットできる粒度であるため、集計がヒットされます。 SalesAmount 列では、Sum 集計が使用されます。

次のクエリでは、集計はヒットしません。 SalesAmount の合計を要求しているにもかかわらず、このクエリでは Product テーブル内の列に対する GroupBy 操作が実行されます。これは集計をヒットできる粒度ではありません。 モデル内のリレーションシップを監視する場合は、製品サブカテゴリに複数の Product 行を含めることができます。 クエリでは、集計する製品を特定できません。 このケースでは、クエリによって DirectQuery に戻され、データ ソースに SQL クエリが送信されます。

集計の目的は、わかりやすい合計を求める単純な計算だけではありません。 複雑な計算にも役立ちます。 概念的には、複雑な計算は、SUM、MIN、MAX、COUNT ごとにサブクエリに分割されます。 各サブクエリは、集計にヒットできるかどうかを判断するために評価されます。 クエリ プランの最適化のため、このロジックはすべてのケースには当てはまりませんが、大抵のものには当てはまります。 次の例では、集計がヒットします。

COUNTROWS 関数は集計を利用できます。 Sales テーブル用に定義されたテーブル行数のカウントの集計があるため、次のクエリでは集計にヒットします。

AVERAGE 関数は集計を利用できます。 AVERAGE が COUNT で除算される SUM に内部的に折りたたまれるため、次のクエリでは集計がヒットします。 UnitPrice 列には SUM と COUNT の両方に対して定義された集計があるため、集計がヒットします。

場合によっては、DISTINCTCOUNT 関数は集計を利用できます。 集計テーブルで CustomerKey の差異を維持する CustomerKey 用の GroupBy エントリがあるため、次のクエリでは集計がヒットします。 この手法でも、200 万から 500 万を超える個別値がクエリのパフォーマンスに影響する可能性がある、パフォーマンスしきい値に達する場合があります。 しかし、これは、詳細テーブルに数十億の行があるものの、列に 200 万から 500 万の個別値があるシナリオで役立ちます。 このケースでは、テーブルがメモリにキャッシュされている場合でも、数十億の行を含むものをスキャンするよりも、DISTINCTCOUNT の方が高速で実行できます。

Data Analysis Expressions (DAX) タイムインテリジェンス関数は集計に対応しています。 次のクエリでは集計が行われます。これは、DATESYTD 関数によって CalendarDay 値のテーブルが生成され、集計テーブルの粒度が Date テーブルの GroupBy 列でカバーされるためです。 これは、集計で利用できる、CALCULATE 関数のテーブル値フィルターの例です。

GroupBy 列に基づく集計
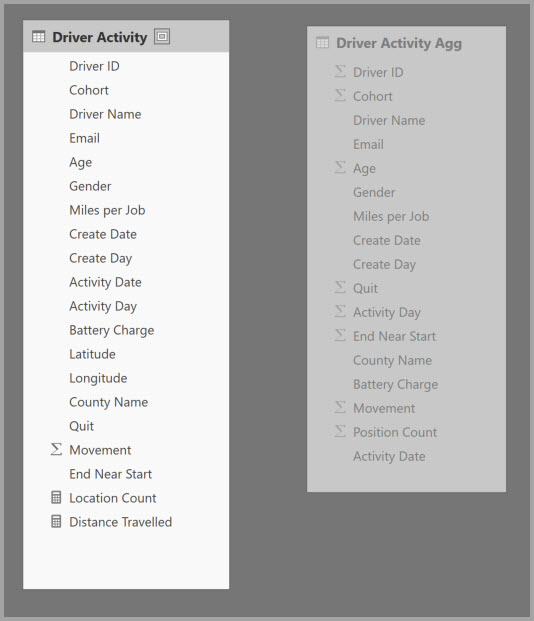
Hadoop ベースのビッグ データ モデルには、ディメンション モデルとは異なる特性があります。 大きなテーブル間の結合を避けるために、ビッグ データ モデルでは多くの場合、リレーションシップを使用しませんが、ファクト テーブルに対してディメンション属性を非正規化します。 このようなビッグ データ モデルは、"GroupBy 列に基づく集計" を使用して、対話型の分析のためにロックを解除することができます。
次のテーブルには、集計対象の Movement の数値列が含まれています。 その他のすべての列は、グループ化する属性です。 このテーブルには、IoT データと多数の行が含まれています。 ストレージ モードは、DirectQuery です。 モデル全体を集計するデータ ソースに対するクエリは、その膨大な量により低速になります。

このモデルで対話型の分析を有効にするために、経度と緯度などの高いカーディナリティ属性を除いた、ほとんどの属性でグループ化される集計テーブルを追加することができます。 これにより行数が大幅に削減され、メモリ内キャッシュに余裕で収まるサイズに縮小されます。
[集計の管理] ダイアログで、Driver Activity Agg テーブルの集計マッピングを定義します。
![Driver Activity Agg テーブルの [集計の管理] ダイアログ](media/aggregations-advanced/aggregations_11.png)
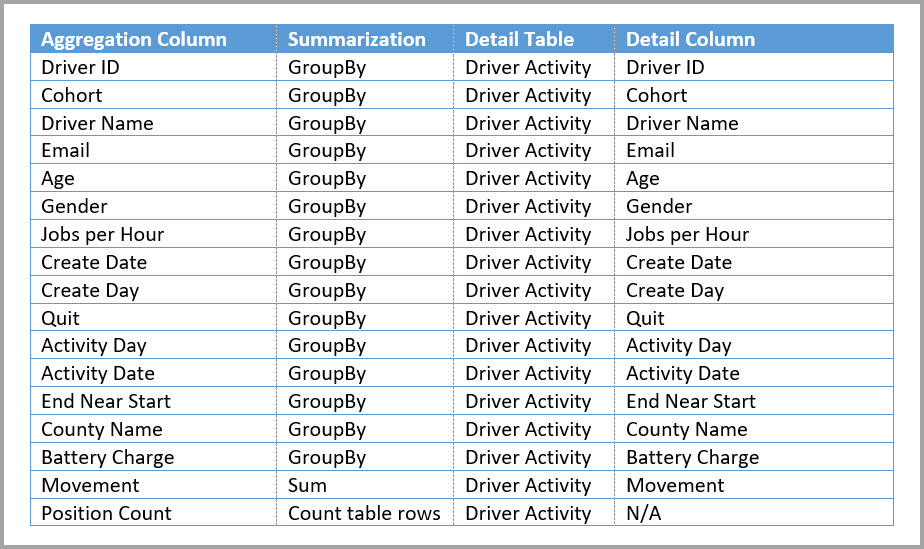
GroupBy 列に基づく集計では、GroupBy エントリを省略することはできません。 これらがないと、集計にヒットしません。 これは、GroupBy エントリを省略できる、リレーションシップに基づく集計の使用とは異なります。
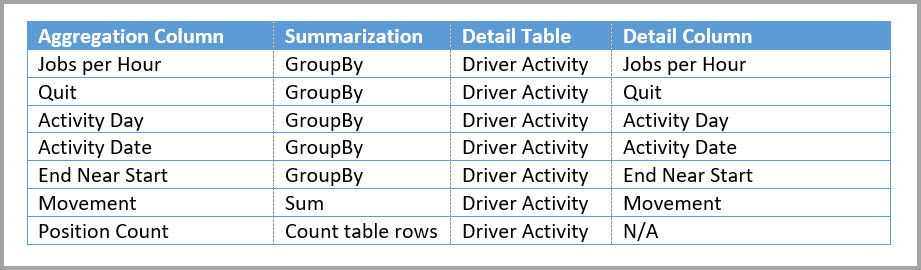
次のテーブルは、Driver Activity Agg テーブルの集計を示しています。
集計された Driver Activity Agg テーブルのストレージ モードを、[インポート] に設定することができます。
GroupBy 集計クエリの例
Activity Date 列が集計テーブルの対象であるため、次のクエリでは集計にヒットします。 COUNTROWS 関数では、カウントされたテーブル行数の集計が使用されます。

ファクト テーブルにフィルター属性が含まれているモデルには特に、テーブル行数のカウントの集計を使用することをお勧めします。 Power BI では、ユーザーによって明示的に要求されていない場合に、COUNTROWS を使用してモデルにクエリを送信することができます。 たとえば、[フィルター] ダイアログには、各値の行数が表示されます。
![[フィルター] ダイアログ](media/aggregations-advanced/aggregations-12.png)
集計手法の組み合わせ
集計では、リレーションシップと GroupBy 列の手法を組み合わせることができます。 リレーションシップに基づく集計では、非正規化されたディメンション テーブルを複数のテーブルに分割する必要がある場合があります。 これにコストがかかる場合、または特定のディメンション テーブルでは実行が難しい場合は、これらのディメンションでは集計テーブルの必要な属性をレプリケートし、その他ではリレーションシップを使用することができます。
たとえば、次のモデルでは、Sales Agg テーブル内の Month、Quarter、Semester、Year をレプリケートします。 Sales Agg と Date のテーブルの間にリレーションシップはありませんが、Customer と Product Subcategory に対するリレーションシップがあります。 Sales Agg のストレージ モードはインポートです。
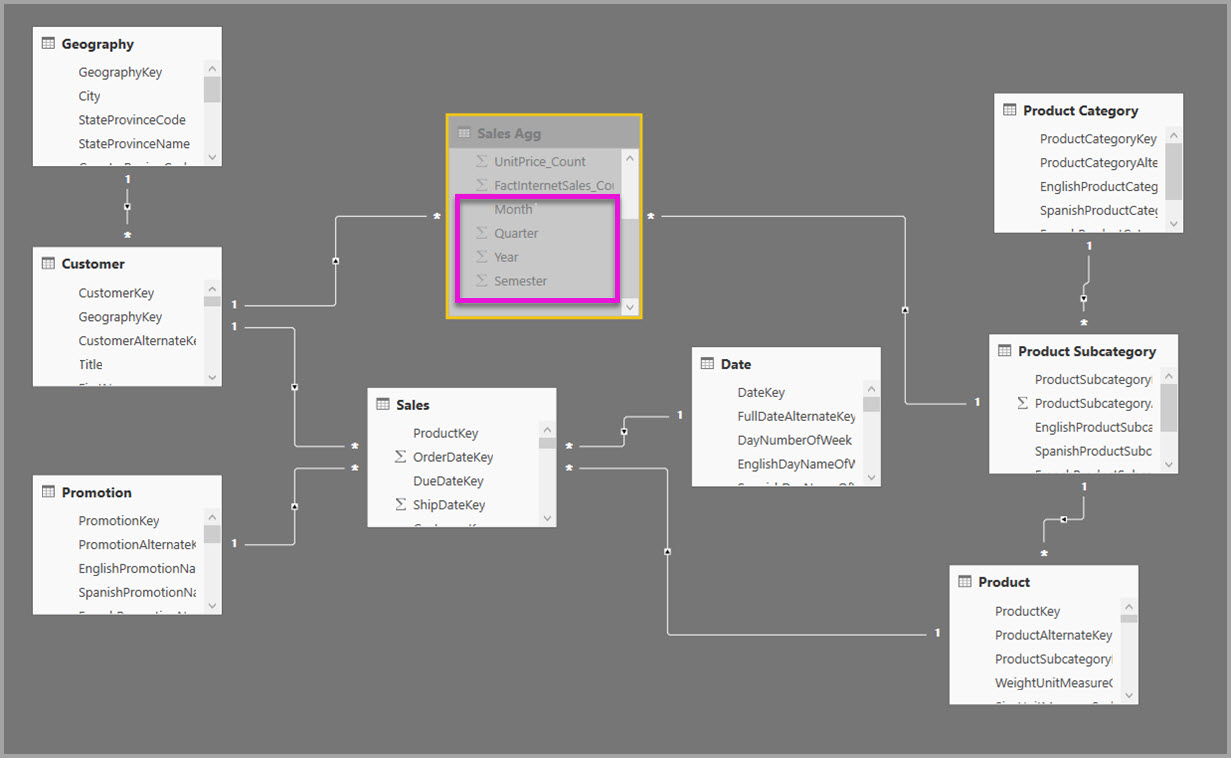
次のテーブルは、Sales Agg テーブルの [集計の管理] ダイアログ内のエントリ セットを示しています。 Date が詳細テーブルである GroupBy エントリは、Date 属性でグループ化するクエリでは、集計にヒットするために必須となります。 前の例と同じように、リレーションシップが存在するため、CustomerKey と ProductSubcategoryKey の GroupBy エントリは、DISTINCTCOUNT を除いて集計のヒットには影響しません。
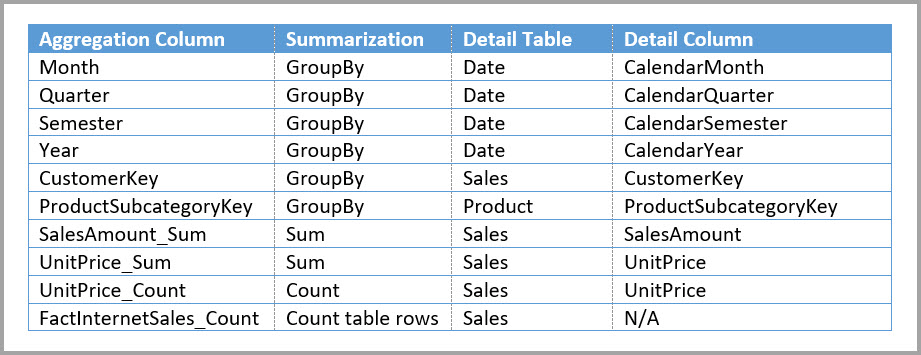
集計クエリの組み合わせ例
次のクエリでは、CalendarMonth が集計テーブルの対象であり、CategoryName は一対多リレーションシップを介してアクセスできるため、集計にヒットします。 SalesAmount では、SUM 集計が使用されます。

CalendarDay は集計テーブルの対象ではないため、次のクエリでは集計にヒットしません。

次のタイム インテリジェンス クエリでは、集計にヒットしません。これは、DATESYTD 関数では CalendarDay 値のテーブルが生成され、CalendarDay が集計テーブルの対象ではないためです。

集計の優先順位
集計の優先順位により、1 つのサブクエリで複数の集計テーブルを対象にすることができます。
以下の例は、複数のソースを含む複合モデルです。
- Driver Activity DirectQuery テーブルには、ビッグ データ システムをソースとする IoT データの数兆を超える行が含まれています。 これは、制御されたフィルター コンテキストで IoT の個別の読み取りを表示するドリルスルー クエリを提供します。
- Driver Activity Agg テーブルは、DirectQuery モードの中間の集計テーブルです。 Azure Synapse Analytics (旧称 SQL Data Warehouse) の 10 億を超える行が含まれ、列ストア インデックスを使用してソースで最適化されます。
- Driver Activity Agg2 インポート テーブルは、group-by 属性が少なく、カーディナリティが低いため、粒度が高くなっています。 行数は、メモリ内キャッシュに余裕で収まるように、数千程度に抑えることができます。 これらの属性は、幹部のダッシュボードで使用されることがあるため、それらを参照するクエリはできるだけ高速にする必要があります。
注意
詳細テーブルと異なるデータ ソースを使用する DirectQuery 集計テーブルは、集計テーブルが SQL Server、Azure SQL、または Azure Synapse Analytics (旧称 SQL Data Warehouse) ソースからのものである場合にのみサポートされます。
このモデルのメモリ占有領域は比較的小さいものの、大きなモデルのロックを解除します。 これは分散アーキテクチャを表します。これは、その長所に基づいてアーキテクチャのコンポーネントを利用し、それらの間でクエリの負荷が分散されるためです。
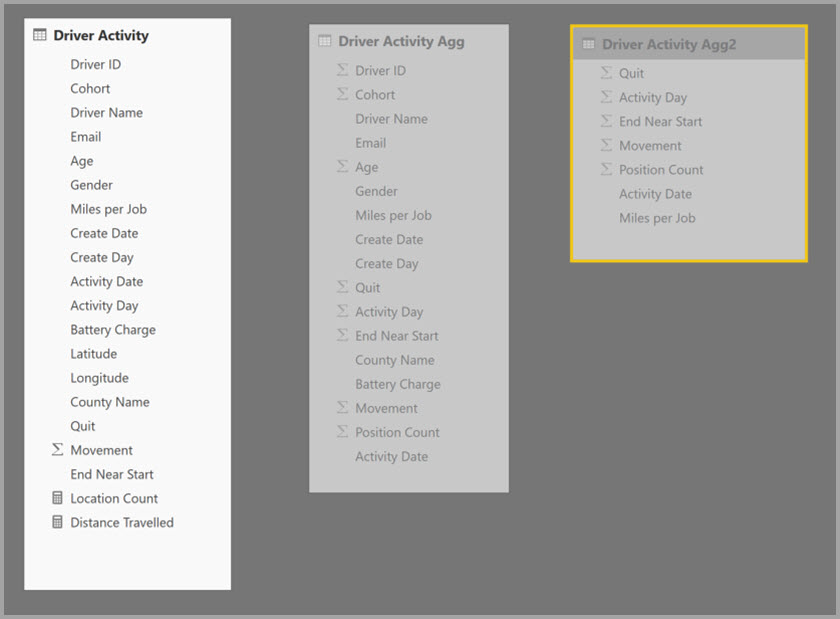
Driver Activity Agg2 の [管理された集計] ダイアログでは、[優先順位] フィールドが 10 に設定されます。これは Driver Activity Agg よりも高くなります。 優先順位を高く設定すると、集計を使用するクエリでは最初に Driver Activity Agg2 が考慮されます。 Driver Activity Agg2 で対応できる粒度ではないサブクエリでは、代わりに Driver Activity Agg が考慮されます。 どちらの集計テーブルでも応答できない詳細クエリは、Driver Activity に送ることができます。
チェーン集計が許可されていないため、[詳細テーブル] 列には、Driver Activity Agg ではなく、Driver Activity テーブルが指定されています。
![[優先順位] が選択された [集計の管理] ダイアログ ボックスが表示されているスクリーンショット。](media/aggregations-advanced/aggregations_14.png)
次のテーブルは、Driver Activity Agg2 テーブルの集計を示しています。
クエリで集計にヒットするかしないかを検出する
SQL Profiler では、メモリ内キャッシュ ストレージ エンジンからクエリが返されるか、DirectQuery によってデータ ソースにプッシュされるかを検出できます。 同じプロセスを使用して、集計にヒットするかどうかを検出することができます。 詳細については、「キャッシュにヒットするクエリまたはヒットしないクエリ」を参照してください。
SQL Profiler では、Query Processing\Aggregate Table Rewrite Query 拡張イベントも提供されます。
次の JSON スニペットでは、集計が使用されている場合のイベントの出力例を示しています。
- matchingResult は、サブクエリで集計が使用されたことを示します。
- dataRequest は、サブクエリで使用された GroupBy 列と集計列を示します。
- mapping は、マップ先の集計テーブル内の列を示します。

キャッシュの同期を保持する
DirectQuery と、インポートおよびデュアルのいずれかまたは両方のストレージ モードを組み合わせる集計では、メモリ内キャッシュとソース データとの同期が保持されている場合を除き、異なるデータが返される可能性があります。 たとえば、クエリを実行しても、キャッシュされた値と一致するように DirectQuery の結果をフィルター処理して、データに関する問題のマスキングは試行されません。 必要に応じて、ソースでそのような問題を処理する手法が確立されています。 パフォーマンスの最適化は、ビジネス要件を満たす能力を損なわない方法でのみ使用する必要があります。 お客様がご自身のデータ フローを把握し、それに応じて設計してください。
考慮事項と制限事項
集計で、動的 M クエリ パラメーターはサポートされていません。
2022 年 8 月から、機能の変更により、Power BI では シングル サインオン (SSO) が有効なデータ ソースを含むインポート モードの集計テーブルが無視されます。セキュリティ リスクの可能性があるためです。 集計を実行して最適なクエリ パフォーマンスを確保するには、これらのデータ ソースに対して SSO を無効にすることをお勧めします。
コミュニティ
Power BI には、MVP、BI プロフェッショナル、および同僚がディスカッション グループ、ビデオ、ブログなどの専門知識を共有する、活気のあるコミュニティがあります。 集計について学習する場合は、次の追加リソースを確認してください。