計算テーブルのシナリオとユース ケース
データフローで計算テーブルを使用することにはメリットがあります。 この記事では、計算テーブルのユース ケースを紹介し、舞台裏でどのように機能するかを説明します。
計算テーブルとは
テーブルは、データフローに作成されるクエリによる、データフロー更新後の出力データを表します。 ソースからのデータと、必要に応じて、ソースに適用された変換を表します。 場合によっては、新しいテーブルを作成し、前回取り込まれたテーブルとして使用する場合があります。
クエリを繰り返し実行してテーブルを作成し、新しく変換を適用することも可能ですが、その方法ではデータを 2 回取り込む必要があるため、読み込みの負荷が 2 倍になるという欠点があります。
それを解決するのが計算テーブルです。 計算テーブルは、ソースからデータを取得し、追加の変換を適用して作成できるという点では他のテーブルと同じです。 しかし、それらのデータは、元のデータ ソースではなく、使用されているストレージ データフローによって生成されたものです。 つまり、データフローによって以前に作成されたデータを再利用します。
計算テーブルは、同じデータフロー内のテーブルを参照するか、別のデータフローで作成されたテーブルを参照することによって作成されます。

計算テーブルを使用するメリット
すべての変換手順を 1 つのテーブルで実行すると、処理が遅くなります。 この速度の低下には、たとえば、データ ソースの速度が低下したため、または実行している変換を 2 つ以上のクエリでレプリケートする必要があるためなど、多くの理由が考えられます。 最初にソースからデータを取り込み、それを 1 つ以上のテーブルで再利用することで、処理時間を短縮できます。 このような場合、2 つのテーブルを作成することを選択できます。1 つはデータ ソースからデータを取得するテーブルで、もう 1 つは、データフローによって使用されるデータ レイクに既に書き込まれたデータに追加の変換を適用するテーブル—計算テーブル—です。 この方法でパフォーマンスが向上し、再利用を行って時間とリソースを節約できます。
たとえば、2 つのテーブルが変換ロジックを半分ずつ共有している場合、計算テーブルを使用しなければ、変換を 2 度実行する必要があります。
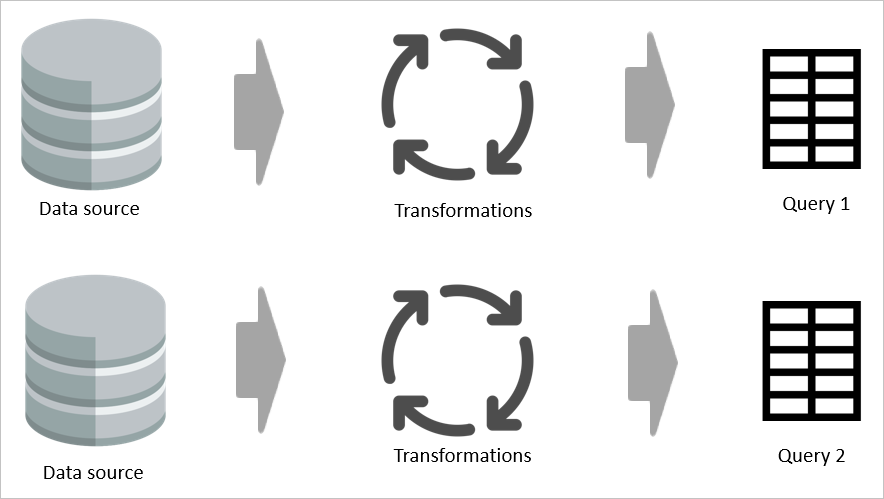
しかし、計算テーブルを使用すれば、変換の共通部分 (共有部分) を一度処理するだけで、Azure Data Lake Storage に格納できます。 残りの変換処理は共通の変換の出力から実行されるため、 全体として、この処理の方がはるかに高速です。
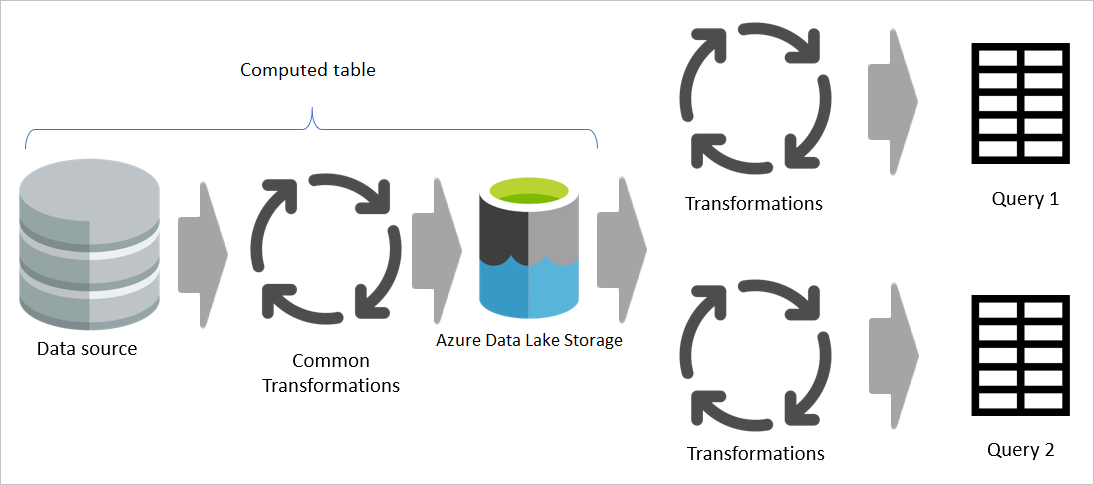
計算テーブルは、変換のソース コードとして1つの場所を提供し、複数回ではなく1回実行するだけで済むため、変換を高速化します。 また、データ ソースの負荷も軽減されます。
計算テーブル使用のシナリオ例
Power BI で集計テーブルを作成してデータ モデルを高速化する際に、元のテーブルを参照し、その他の変換を適用して集計テーブルを作成することができます。 この方法を使用すると、ソース (元のテーブルからの部分) から変換をレプリケートする必要がありません。
たとえば、Orders テーブルを示す次の画像をご覧ください。

このテーブルの参照を使用して、計算テーブルを作成します。
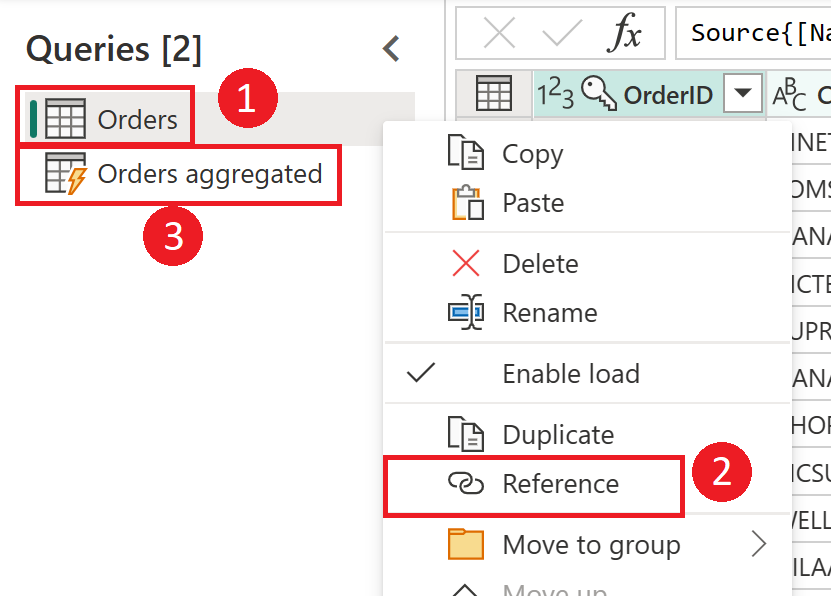
Orders テーブルから計算テーブルを作成する方法を示すスクリーンショット。 最初に [クエリ] ペインで Orders テーブルを右クリックし、ドロップダウン メニューから [参照] オプションを選択します。 計算テーブルが作成されます (テーブルの名前が Orders Aggregated に変更されています)。
計算テーブルに追加の変換を適用します。 たとえば、[グループ別] を使用して、顧客レベルでデータを集計できます。
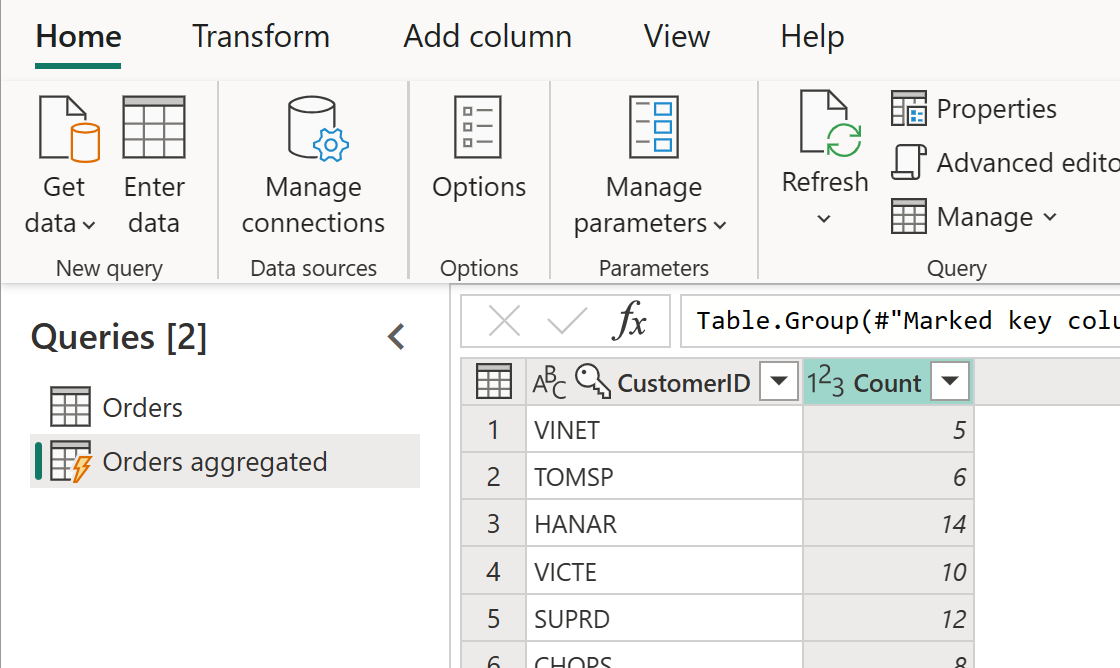
つまり、Orders Aggregated テーブルは Orders テーブルからデータを取得し、データ ソースから再度取得することはありません。 必要とされる変換の一部は Orders テーブルで既に実行されているため、パフォーマンスが向上し、データ変換処理にかかる時間が短くなります。
他のデータフローの計算テーブル
他のデータフローに計算テーブルを作成することもできます。 これは、Microsoft Power Platform データフロー コネクタを使用してデータフローからデータを取得することによって作成できます。
Power Query - データ ソースの選択ウィンドウの Power Platform データフロー コネクタを強調表示する画像。 また、「1 つのデータフロー テーブルを、ストレージで既に永続化されている別のデータフロー テーブルのデータの上位に作成できる」という説明も表示されています。
計算テーブルの概念は、テーブルをストレージに永続化し、そこから他のテーブルにデータを取り込むことで、データ ソースからの読み取り時間を短縮し、共通の変換の一部を共有することです。 これは、データフロー コネクタを介して他のデータフローからデータを取得するか、同じデータフロー内の別のクエリを参照することで実現できます。
計算テーブル: 変換を適用するケースとしないケース
ここまで、計算テーブルを使用してデータ変換のパフォーマンスを向上できることを説明しました。では、変換は常に計算テーブルまで遅延させて適用すべきなのでしょうか。それともソース テーブルに適用すべきケースが存在するのでしょうか。 つまり、データは常に 1 つのテーブルに取り込んで、計算テーブルで変換を行うべきでしょうか? その長所と短所は何でしょうか?
テキストまたは CSV ファイルの変換なしのデータを読み込む
データ ソースでクエリ フォールディングがサポートされない場合 (テキストまたは CSV ファイルなど)、特にデータ ボリュームが大きい場合は、ソースからデータを取得するときに変換を適用してもメリットはほとんどありません。 ソース テーブルのデータを、変換を適用せずにテキスト/CSV ファイルから読み込んでください。 そして、ソース テーブルから計算テーブルにデータを取得し、取り込まれたデータに対して変換を実行してください。
データを取り込むためだけに、なぜソース テーブルを作成するのだろうと思うかもしれません。 このテーブルを作成するのは、ソースから取り込むデータを複数のテーブルで使用する場合に、データ読み込みの負荷を減らせるからです。 さらに、他のユーザーおよびデータフローによってデータを再利用することもできるようになります。 計算テーブルは、データのボリュームが大きい場合に特に便利です。また、オンプレミス データ ゲートウェイ経由でデータ ソースにアクセスする場合も、ゲートウェイからのトラフィックを減らし、そのデータ ソースの負荷も軽減されるため非常に便利です。
SQL テーブルに対する共通の変換の一部を実行する
データ ソースがクエリ フォールディングをサポートしている場合は、変換の一部をソース テーブルで実行することをお勧めします。その理由は、クエリがデータ ソースにフォールディングされ、そこから変換されたデータのみをフェッチできるからです。 そのため、パフォーマンスが全体的に向上します。 下流の計算テーブルで共通して実行される一連の変換は、ソース テーブルで適用し、ソースにフォールドされるようにしてください。 それ以外の、下流のテーブルにのみ適用する変換は、計算テーブルで実行してください。