データ プライバシー ファイアウォールの舞台裏
Note
現在、Power Platform のデータフローでは、プライバシー レベルは利用できませんが、製品チームはこの機能の有効化に向けて取り組んでいます。
Power Query を短時間でも使用したことがある方なら、おそらく経験したことがあるでしょう。 それは、クエリの実行時に突然エラーが発生して、オンライン検索をしても、クエリを調整しても、キーボードを叩いてみても、一切解決方法が見つからないという問題です。 具体的には、次のようなエラーです。
Formula.Firewall: Query 'Query1' (step 'Source') references other queries or steps, so it may not directly access a data source. Please rebuild this data combination.
または、次のような場合もあります。
Formula.Firewall: Query 'Query1' (step 'Source') is accessing data sources that have privacy levels which cannot be used together. Please rebuild this data combination.
これらの Formula.Firewallエラーは、Power Query のデータ プライバシー ファイアウォール (ファイアウォールとも呼ばれます) の結果であり、世界中のデータ アナリストをイライラさせるためだけに存在しているように見えることがあります。 しかし、実際のところ、ファイアウォールには重要な目的があります。 この記事では、その仕組みをより深く理解するために内部を詳しく掘り下げていきます。 機能について理解を深めれば、今後ファイアウォール エラーに遭遇した際に、問題より効果的に診断し、修正できる可能性があります。
Xbox Live ゲームのバインドとは ?
データ プライバシー ファイアウォールの目的はシンプルです。この機能は、Power Query によって、ソース間で意図しないデータ漏えいが発生するのを防ぐために存在します。
なぜこれが必要なのですか? 開発者が作成した M によって、OData フィードに SQL 値が渡される場合があるからです。 しかし、これは意図的なデータ漏えいです。 マッシュアップの作成者は、それが実行されることを知っていることになります (少なくとも、知っているべきです)。 それではなぜ、意図しないデータ漏えいに対する保護措置が必要なのでしょうか?
その理由は、 フォールディングです。
フォールディングとは?
フォールディングとは、M 内の式 (フィルター、名前変更、結合など) を、生のデータ ソース (SQL、OData など) に対する操作へと変換することを意味する用語です。 Power Query の機能の大部分は、ユーザーがその言語を知らなくても、PQ がユーザー インターフェイスを介してユーザーが実行する操作を複雑な SQL またはその他のバックエンド データ ソース言語に変換できるという事実から来ています。 ユーザーは、ネイティブなデータ ソース操作のパフォーマンス上の利点を、使いやすい UI を通じて享受することができます。すべてのデータ ソースを、一般的なコマンド セットを使って変換できるのです。
PQ では、フォールディングの際、あるソースからデータを取得して別のソースへと渡すことが、特定のマッシュアップを実行する最も効率的な方法だと判断される場合があります。 たとえば、小さな CSV ファイルを巨大な SQL テーブルに結合する場合、PQ が CSV ファイルを読み取り、SQL テーブル全体を読み取って、ローカル コンピュータ上でそれらを結合することは望まないでしょう。 CSV データを SQL ステートメント内にインライン化し、SQL データベースに結合を実行させるほうが効率的です。
これこそが、意図しないデータ漏えい原因となりうるのです。
たとえば、従業員の社会保障番号を含んだ SQL データを外部の OData フィードの結果と結合した後に、SQL の社会保障番号が OData サービスに送信されることにふと気づいたとしたらどうでしょう。 まずい状況ですよね?
そのような事態を回避することが、ファイアウォールの目的なのです。
それはどのように機能しますか?
ファイアウォールは、1 つのソースから、データが意図せずに別のソースへと送信されるのを防ぐために存在します。 実にシンプルです。
では、このミッションはどのようにして達成されるのでしょうか?
これは、M クエリをパーティションと呼ばれるものに分割し、次のルールを適用することで実現されます。
- パーティションは、互換性のあるデータ ソースにアクセスするか、他のパーティションを参照することができるが、それら両方を参照することはできない。
シンプルですが、これだけではまだわかりにくいでしょう。 パーティションとは何か? 何が2つのデータソースに「互換性」を持たせるのか? また、パーティションからデータ ソースにアクセスしたりパーティションを参照したりする必要がある場合に、なぜファイアウォールが必要になるのでしょうか?
これを分解して、上記のルールを一つずつ見てみましょう。
パーティションとは何か?
最も基本的なレベルで言うと、パーティションは 1 つ以上のクエリ ステップのコレクションです。 最も小規模なパーティションは (少なくとも現在の実装では) 1 つのステップによるものです。 きわめて大きなパーティションになると、複数のクエリにまたがることもあります (詳細については、後述します)。
ステップに慣れていない場合は、クエリを選択した後、Power Query エディター ウィンドウの右側の [適用されたステップ] ペインでステップを表示できます。 ステップは、データを最終形状に変換するために行ったすべての作業を追跡します。
他のパーティションを参照するパーティション
ファイアウォールをオンにした状態でクエリが評価された場合、ファイアウォールによって、クエリとそのすべての依存関係がパーティション (一連のステップ) に分割されます。 あるパーティションが別のパーティション内の何かを参照するたびに、ファイアウォールはその参照を Value.Firewall と呼ばれる特別な関数の呼び出しに置き換えます。 つまり、ファイアウォールはパーティションどうしが相互に直接アクセスすることを許可しません。 すべての参照は、ファイアウォールを通過するために変更を加えられます。 ファイアウォールはゲートキーパーだと考えてください。 別のパーティションを参照するパーティションは、ファイアウォールの許可を取得する必要があり、参照されたデータがそのパーティションに入るのを許可するかどうかはファイアウォールによって制御されます。
これはすべて非常に抽象的に感じられるかもしれないので、例を見てみましょう。
SQL データベースから一部のデータを取得する、Employees というクエリがあるとします。 また、Employees を参照する別のクエリ (EmployeesReference) もあるとします。
shared Employees = let
Source = Sql.Database(…),
EmployeesTable = …
in
EmployeesTable;
shared EmployeesReference = let
Source = Employees
in
Source;
これらのクエリは、2 つのパーティションに分割されます。1 つは Employees クエリ用、もう 1 つは EmployeesReference クエリ (Employees パーティションを参照するクエリ) 用です。 ファイアウォールをオンにして評価した場合、これらのクエリは次のように書き換えられます。
shared Employees = let
Source = Sql.Database(…),
EmployeesTable = …
in
EmployeesTable;
shared EmployeesReference = let
Source = Value.Firewall("Section1/Employees")
in
Source;
Employees クエリへのシンプルな参照が、Value.Firewall の呼び出しへと置き換えられている点に注目してください。これに、Employees クエリの完全な名前が指定されています。
EmployeesReference が評価されると、Value.Firewall("Section1/Employees") の呼び出しがファイアウォールによってインターセプトされます。要求されたデータが EmployeesReference パーティションに渡されるかどうか (およびその方法) は、ファイアウォールによって制御されます。 ファイアウォールでは、要求の拒否、要求されたデータのバッファー処理 (元のデータ ソースへのさらなるフォールディングが発生するのを防ぐ) など、任意の数の処理を実行できます。
このように、パーティション間を流れるデータはファイアウォールによって制御されます。
データ ソースに直接アクセスするパーティション
1 つのステップでクエリ Query1 を定義し (この単一ステップのクエリは 1 つのファイアウォール パーティションに対応することに注意してください)、この 1 つのステップが 2 つのデータ ソース (SQL データベース テーブルと CSV ファイル) にアクセスするとします。 パーティション参照がないので、ファイアウォールがインターセプトするためのValue.Firewallの呼び出しがない場合、ファイアウォールはこれにどのように対処したらいいでしょうか? 前に述べたルールを確認してみましょう。
- パーティションは、互換性のあるデータ ソースにアクセスするか、他のパーティションを参照することができるが、それら両方を参照することはできない。
パーティションが 1 つでデータ ソースが 2 つあるクエリを実行できるようにするには、その 2 つのデータ ソースに「互換性」が必要です。 つまり、両方のソース間でデータを双方向に共有できることが必要です。 これにより、両方のソースのプライバシー レベルがパブリックであるか、両方とも組織であることが必要となります。これは、両方向の共有ができる唯一の2 つの組み合わせであるためです。 両方のソースが「非公開」としてマークされている場合や、一方が「公開」でもう一方が「組織」の場合、またはその他のプライバシー レベルの組み合わせでマークされている場合には、双方向の共有が許可されず、両者を同じパーティションで評価するのは安全ではありません。 そのようにすると、(フォールディングによって) 安全でないデータ漏えいが発生する可能性があります。また、ファイアウォールによってそれを防ぐ方法はありません。
同じパーティション内で互換性のないデータ ソースにアクセスしようとすると、どうなるでしょうか?
Formula.Firewall: Query 'Query1' (step 'Source') is accessing data sources that have privacy levels which cannot be used together. Please rebuild this data combination.
この記事の冒頭で示したエラー メッセージの 1 つですが、先ほどよりは、この意味が理解できるのではないでしょうか。
この互換性の要件は、当該のパーティション内でのみ適用されるという点に注意してください。 パーティションが他のパーティションを参照している場合は、参照先パーティションのデータ ソースが相互に互換性を持っている必要はありません。 なぜなら、ファイアウォールによってデータをバッファー処理できるので、元のデータ ソースに対するそれ以上のフォールディングは回避されるからです。 データはメモリに読み込まれ、元からそこにあるもののように扱われます。
両方を参照できない理由
他の 2 つのクエリ (つまり、他の 2 つのパーティション) にアクセスする 1 つのステップ (これも 1 つのパーティションに対応します) を含むクエリを定義するとします。 その際、同じステップ内で、SQL データベースにも直接アクセスしたいとしたらどうでしょう? パーティションが他のパーティションを参照したり、互換性のあるデータ ソースに直接アクセスしたりできないのはなぜですか?
先にも説明したように、あるパーティションから別のパーティションを参照する場合、ファイアウォールは、そのパーティションに送られるすべてのデータのゲートキーパーとして機能します。 そのためには、どのようなデータが許可されるのかを、ファイアウォールが制御できる必要があります。 パーティション内にアクセスされているデータ ソースがあり、他のパーティションからデータが流入している場合、流入するデータが内部でアクセスされるデータ ソースの 1 つに知らないうちに漏洩する可能性があるため、ゲートキーパーとしての機能を失います。 そのため、ファイアウォールでは、他のパーティションにアクセスするパーティションがデータ ソースに直接アクセスすることは禁止されます。
それでは、あるパーティションが他のパーティションを参照する場合に、データ ソースにも直接アクセスしようとした場合にはどうなるのでしょうか?
Formula.Firewall: Query 'Query1' (step 'Source') references other queries or steps, so it may not directly access a data source. Please rebuild this data combination.
この記事の冒頭で示したもう 1 つのエラー メッセージですが、先ほどよりは、この意味が理解できるのではないでしょうか。
パーティションの詳細
これまでの内容からもおわかりかと思いますが、クエリがどのようにパーティション分割されるかは、きわめて重要な問題です。 他のクエリを参照するステップと、データ ソースにアクセスするステップがある場合、おわかりかもしれませんが、特定の場所にパーティション境界を引くとファイアウォール エラーが発生し、別の場所に引くとクエリを実行できるという状況が生まれます。
それでは、クエリは厳密にはどのようにしてパーティション分割されるのでしょうか?
このセクションは、ファイアウォール エラーが表示される理由を理解し、(可能な場合は) それらを解決する方法を理解するためにおそらく最も重要です。
ここでは、パーティショニング ロジックの高度な概要を示します。
- 初期パーティショニング
- 各クエリ内のステップごとにパーティションを作成します
- 静的フェーズ
- このフェーズは評価結果に依存しません。 代わりに、クエリがどのように構造化されているかに依存します。
- パラメータのトリミング
- パラメータに似たパーティション、つまり次のようなパーティションをトリムします。
- 他のパーティションを参照しない
- 関数呼び出しを含まない
- サイクリックでない (つまり、それ自体を参照しない)
- パーティションを「削除」すると、そのパーティションを参照する他のパーティションにも、そのパーティションが実質的に含まれてしまうことに注意してください。
- パラメーター パーティションをトリミングすると、「パーティションはデータ ソースと他のステップを参照できません」エラーがスローされるのではなく、データ ソース関数呼び出し (例:
Web.Contents(myUrl)) 内で使用されるパラメーター参照が機能するようになります。
- パラメータに似たパーティション、つまり次のようなパーティションをトリムします。
- グループ化 (静的)
- パーティションは、ボトムアップ依存関係の発注で統合されます。 結果として統合されたパーティションでは、次の内容が分離されます:
- 異なるクエリ内のパーティション
- 他のパーティションを参照していない (そのため、データ ソースへのアクセスが許されている) パーティション
- 他のパーティションを参照している (そのため、データ ソースへのアクセスが禁止されている) パーティション
- パーティションは、ボトムアップ依存関係の発注で統合されます。 結果として統合されたパーティションでは、次の内容が分離されます:
- パラメータのトリミング
- このフェーズは評価結果に依存しません。 代わりに、クエリがどのように構造化されているかに依存します。
- 動的フェーズ
- このフェーズは評価結果に依存します (さまざまなパーティションによってアクセスされるデータ ソースに関する情報など)。
- トリミング
- 次の要件をすべて満たすパーティションをトリムします。
- データソースにアクセスしない
- データソースにアクセスするパーティションを参照しない
- サイクリックでない
- 次の要件をすべて満たすパーティションをトリムします。
- グループ化 (動的)
- 不要なパーティションがトリミングされたら、可能な限り大きいソース パーティションを作成します。 これを行うには、上記の静的グループ化フェーズで説明したのと同じ規則を使用してパーティションをマージします。
上記の内容が意味すること
上記の複雑なロジックがどのように機能するかを示す例を見てみましょう。
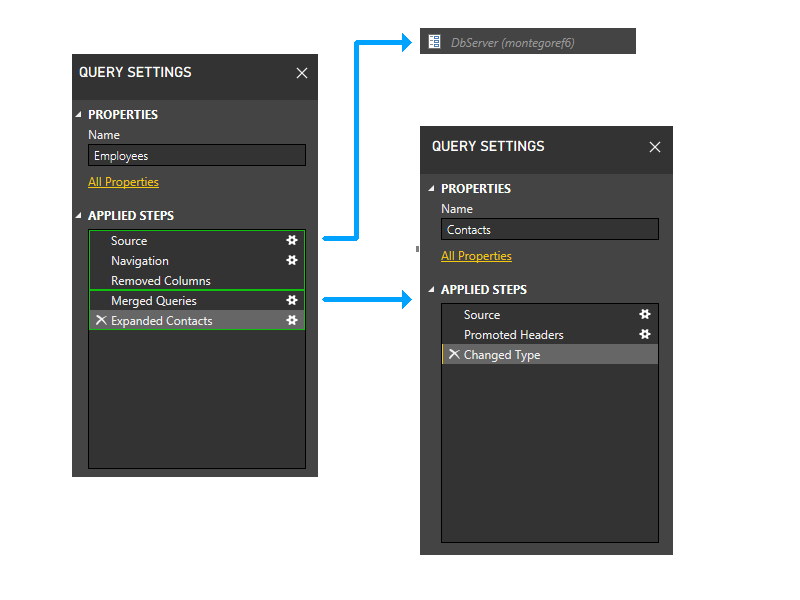
サンプルシナリオを次に示します。 これはテキスト ファイル (連絡先) と SQL データベース (従業員) の非常に単純なマージであり、SQL サーバーがパラメータ (DbServer) です。
3 つのクエリ
この例で使用される 3 つのクエリの M コードは次のとおりです。
shared DbServer = "montegoref6" meta [IsParameterQuery=true, Type="Text", IsParameterQueryRequired=true];
shared Contacts = let
Source = Csv.Document(File.Contents("C:\contacts.txt"),[Delimiter=" ", Columns=15, Encoding=1252, QuoteStyle=QuoteStyle.None]),
#"Promoted Headers" = Table.PromoteHeaders(Source, [PromoteAllScalars=true]),
#"Changed Type" = Table.TransformColumnTypes(#"Promoted Headers",{{"ContactID", Int64.Type}, {"NameStyle", type logical}, {"Title", type text}, {"FirstName", type text}, {"MiddleName", type text}, {"LastName", type text}, {"Suffix", type text}, {"EmailAddress", type text}, {"EmailPromotion", Int64.Type}, {"Phone", type text}, {"PasswordHash", type text}, {"PasswordSalt", type text}, {"AdditionalContactInfo", type text}, {"rowguid", type text}, {"ModifiedDate", type datetime}})
in
#"Changed Type";
shared Employees = let
Source = Sql.Databases(DbServer),
AdventureWorks = Source{[Name="AdventureWorks"]}[Data],
HumanResources_Employee = AdventureWorks{[Schema="HumanResources",Item="Employee"]}[Data],
#"Removed Columns" = Table.RemoveColumns(HumanResources_Employee,{"HumanResources.Employee(EmployeeID)", "HumanResources.Employee(ManagerID)", "HumanResources.EmployeeAddress", "HumanResources.EmployeeDepartmentHistory", "HumanResources.EmployeePayHistory", "HumanResources.JobCandidate", "Person.Contact", "Purchasing.PurchaseOrderHeader", "Sales.SalesPerson"}),
#"Merged Queries" = Table.NestedJoin(#"Removed Columns",{"ContactID"},Contacts,{"ContactID"},"Contacts",JoinKind.LeftOuter),
#"Expanded Contacts" = Table.ExpandTableColumn(#"Merged Queries", "Contacts", {"EmailAddress"}, {"EmailAddress"})
in
#"Expanded Contacts";
以下は、依存関係を示す上位レベルのビューです。
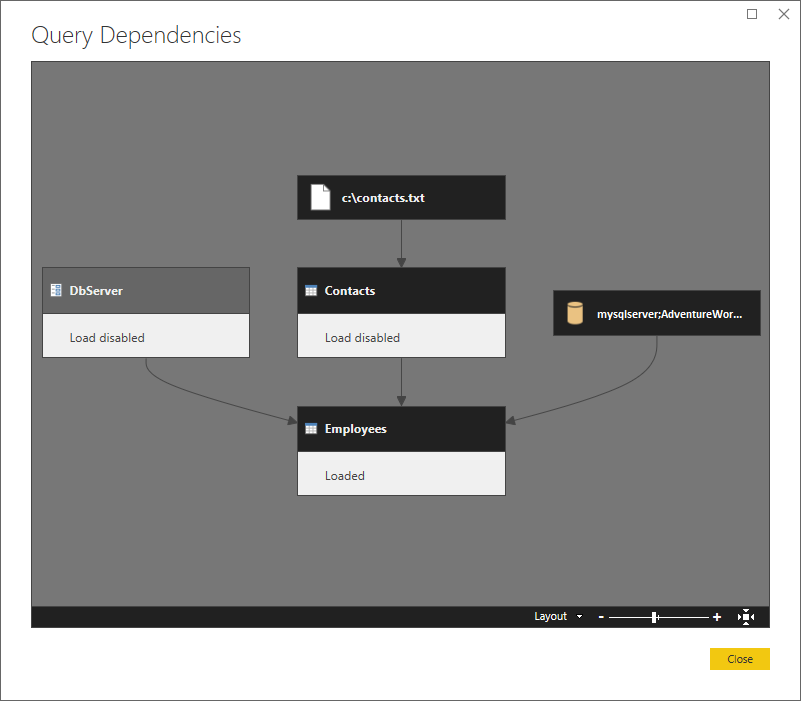
パーティショニングをしてみましょう
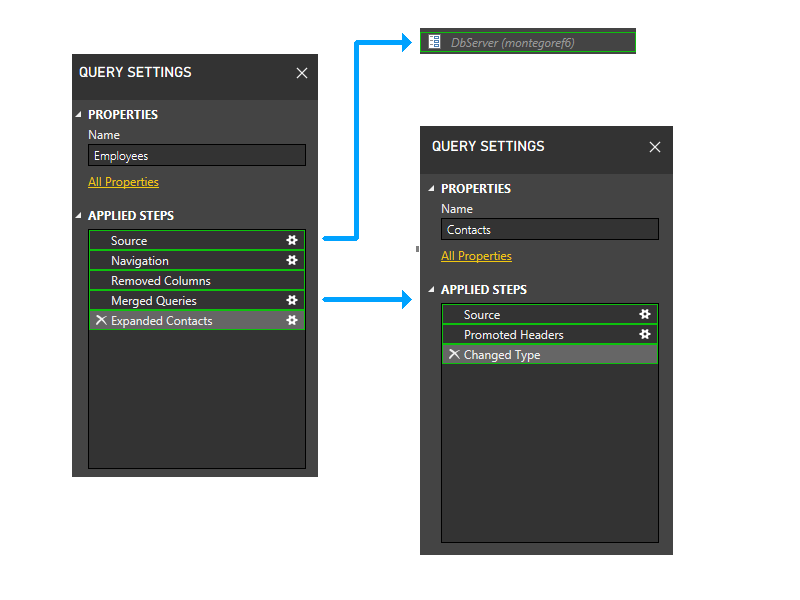
少し拡大して図に手順を含めて、パーティショニング ロジックを見てみましょう。 これは 3 つのクエリの図で、最初のファイアウォール パーティションが緑色で示されています。 各ステップが独自のパーティションで開始されるという点に注意してください。
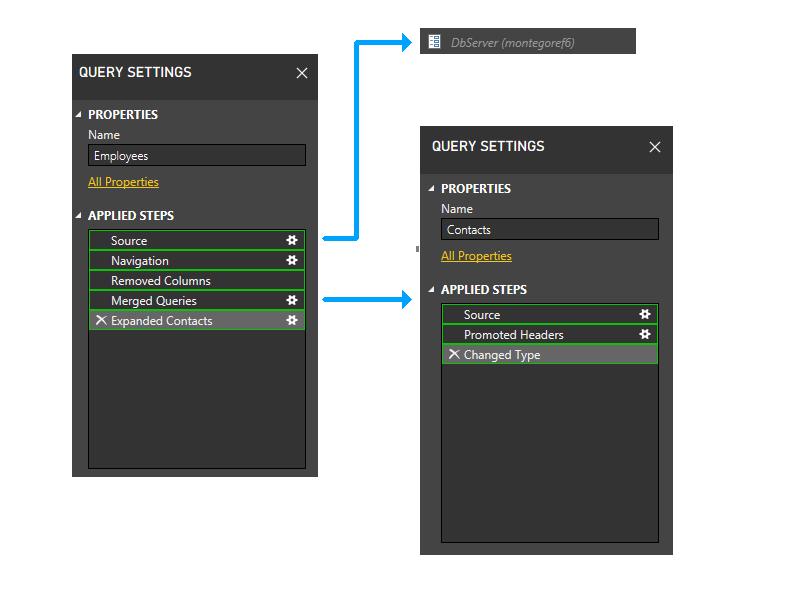
次に、パラメーター パーティションをトリミングします。 これにより、DbServer が Source パーティションに暗黙的に含められます。
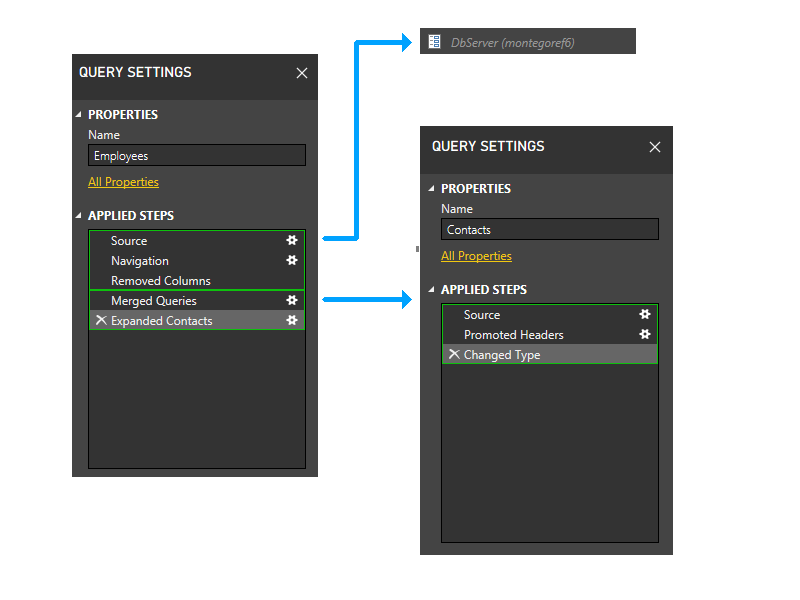
次に、静的グループ化を実行します。 これにより、別々のクエリのパーティション間の分離が維持され(例えば、Employeesの最後の2つのステップはContactsのステップとグループ化されないことに注意してください)、他のパーティションを参照するパーティション(Employeesの最後の2つのステップなど)と参照しないパーティション(Employeesの最初の3つのステップなど)間の分離が維持されます。
次に、動的フェーズに入ります。 このフェーズでは、上記の静的パーティションが評価されます。 データ ソースにアクセスしないパーティションはトリミングされます。 その後、パーティションはグループ化され、可能な限り大きいソース パーティションが作成されます。 ただし、このサンプル シナリオでは、残りのすべてのパーティションがデータ ソースにアクセスするため、これ以上グループ化を行うことはできません。 したがって、サンプル内のパーティションはこの段階では変更されません。
ごっこ遊びをしましょう
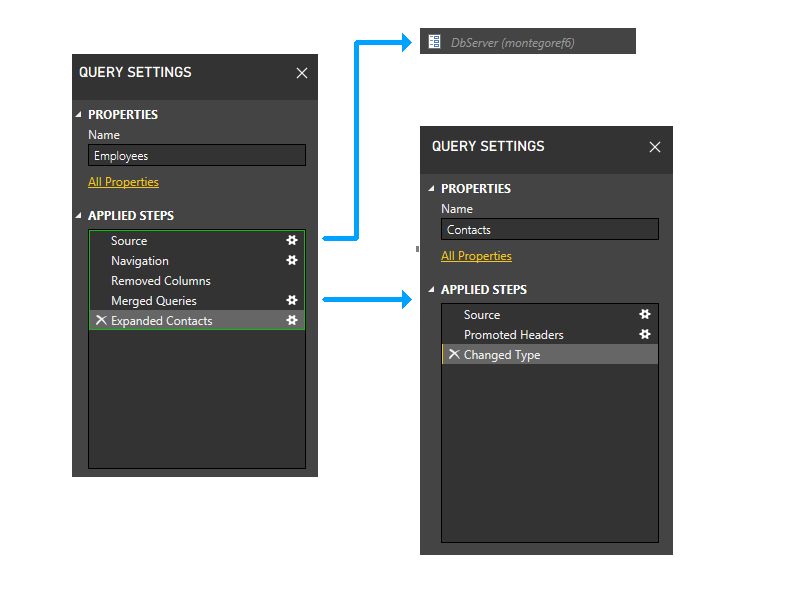
ただし、説明のために、連絡先クエリがテキスト ファイルからではなく、M でハードコーディングされた場合 (おそらくデータの入力ダイアログ経由) に何が起こるかを見てみましょう。
この場合、連絡先クエリはどのデータ ソースにもアクセスしません。 そのため、動的フェーズの最初の部分でトリミングされます。
Contacts パーティションが削除されると、Employees の最後の 2 つのステップは、Employees の最初の 3 つのステップを含んだパーティションを除き、パーティションを参照しなくなります。 したがって、これら 2 つのパーティションはグループ化されます。
結果のパーティションは次のようになります。
例: データ ソース間でデータを渡す
ここまでは、抽象的な説明をしてきました。 ここからは、ファイアウォール エラーが発生しやすい一般的なシナリオと、その解決手順を見ていきましょう。
たとえば、Northwind OData サービスからある会社名を検索し、その会社名を使って Bing 検索を実行したいとします。
まずは、会社名を取得する Company クエリを作成します。
let
Source = OData.Feed("https://services.odata.org/V4/Northwind/Northwind.svc/", null, [Implementation="2.0"]),
Customers_table = Source{[Name="Customers",Signature="table"]}[Data],
CHOPS = Customers_table{[CustomerID="CHOPS"]}[CompanyName]
in
CHOPS
次に、Company を参照する Search クエリを作成し、それを Bing に渡します。
let
Source = Text.FromBinary(Web.Contents("https://www.bing.com/search?q=" & Company))
in
Source
この時点で、問題が発生します。 Search を評価すると、ファイアウォール エラーが発生します。
Formula.Firewall: Query 'Search' (step 'Source') references other queries or steps, so it may not directly access a data source. Please rebuild this data combination.
これは、Search の Source ステップがデータ ソース (bing.com) を参照していて、同時に別のクエリ/パーティション (Company) も参照しているためです。 これは、上記のルール (「パーティションは互換性のあるデータ ソースにアクセスするか、他のパーティションを参照することができますが、両方を参照することはできません」) に違反しています。
どうすればよいでしょうか。 1 つの方法として、ファイアウォールを完全に無効にする方法があります ([プライバシー レベルを無視すると、パフォーマンスが向上する場合があります] というラベルが付いた [プライバシー] オプションを使用します)。 しかし、ファイアウォールを有効のままにしたい場合にはどうすればよいでしょうか?
ファイアウォールを無効にせずにエラーを解決するには、次のように、Company と Search を 1 つのクエリに結合します。
let
Source = OData.Feed("https://services.odata.org/V4/Northwind/Northwind.svc/", null, [Implementation="2.0"]),
Customers_table = Source{[Name="Customers",Signature="table"]}[Data],
CHOPS = Customers_table{[CustomerID="CHOPS"]}[CompanyName],
Search = Text.FromBinary(Web.Contents("https://www.bing.com/search?q=" & CHOPS))
in
Search
これで、すべてが 1 つのパーティション内で発生するようになりました。 2 つのデータ ソースのプライバシー レベルに互換性があれば、ファイアウォールでの問題は起こらず、エラーは発生しません。
ご苦労様でした
このトピックは、掘り下げようと思えばさらに説明することもできますが、今回は入門的な内容なので、説明は以上です。 ファイアウォールについての理解を深めることができ、将来ファイアウォール エラーが発生したときにそれを理解して修正するのに役立つことを願っています。
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示