In Microsoft Team Foundation Server (TFS) 2018 and previous versions,
build and release pipelines are called definitions,
runs are called builds,
service connections are called service endpoints,
stages are called environments,
and jobs are called phases.
The concept of stages varies depending on whether you use YAML pipelines or classic release pipelines.
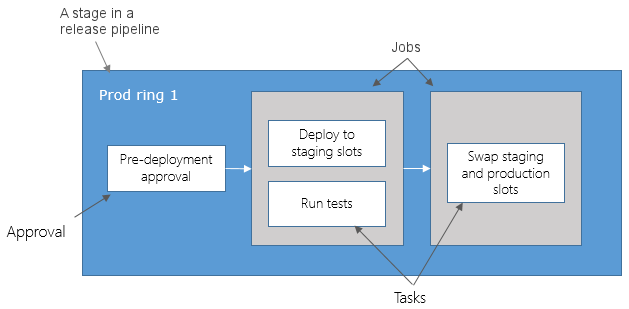
You can organize the deployment jobs in your release pipeline into stages.
Stages are the major divisions in your release pipeline: "run functional tests", "deploy to pre-production",
and "deploy to production" are good examples of release stages.
A stage in a release pipeline consists of jobs and tasks.
To add a stage to your release pipeline, select the release pipeline in Releases page, select the action to Edit it, and then select the Pipeline tab.
While the most important part of defining a stage is the
automation tasks, you can also configure several properties and options
for a stage in a release pipeline. You can:
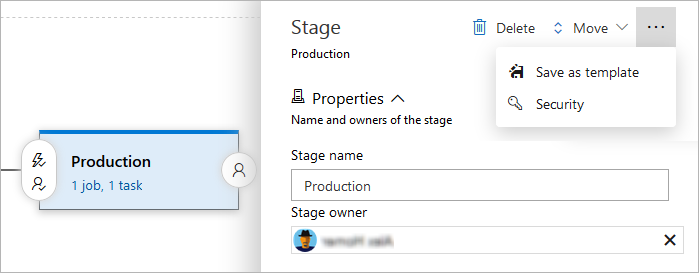
Edit the name of the stage here if necessary.
Designate one user or a
group to be the stage owner. Stage owners get
notified whenever a deployment to that
stage fails. Being a stage owner does not automatically come with any permissions.
You control the dependencies by setting the triggers on each stage of the release pipeline:
Stages run with a trigger or by being manually started.
With an After release trigger, a stage will start as soon as the release starts, in parallel with other stages that have After release trigger.
With an After stage trigger, a stage will start after all the dependent stages complete. Using this, you can model fan-out and fan-in behavior for stages.
Conditions
You can specify the conditions under which each stage runs. By default, a stage runs if it does not depend on any other stage, or if all of the stages that it depends on have completed and succeeded. You can customize this behavior by forcing a stage to run even if a previous stage fails or by specifying a custom condition.
If you customize the default condition of the preceding steps for a stage, you remove the conditions for completion and success. So, if you use a custom condition, it's common to use and(succeeded(),custom_condition) to check whether the preceding stage ran successfully. Otherwise, the stage runs regardless of the outcome of the preceding stage.
Note
Conditions for failed ('JOBNAME/STAGENAME') and succeeded ('JOBNAME/STAGENAME') as shown in the following example work only for YAML pipelines.
When you specify After release or After stage triggers, you can also specify the branch filters for the artifacts consumed in the release. Releases will only deploy to a stage when the branch filters are satisfied.
In some cases, you may be generate builds faster than
they can be deployed. Alternatively, you may configure multiple
agents and, for example, be creating releases from the same release pipeline
for deployment of different artifacts. In such cases, it's useful to
be able to control how multiple releases are queued into a
stage. Queuing policies give you that control.
The options you can choose for a queuing policy are:
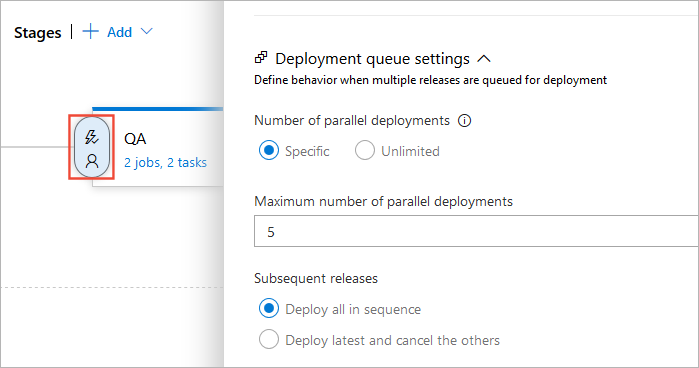
Number of parallel deployments:
Use this option if you dynamically provision new resources
in your stage and it is physically capable of handling
the deployment of multiple releases in parallel, but you want
to limit the number of parallel deployments.
If you specify a maximum number of deployments, two more options appear:
Deploy all in sequence:
Use this option if you want to deploy all the releases
sequentially into the same shared physical resources.
By deploying them in turn, one after the other, you
ensure that two deployment jobs do not target the same
physical resources concurrently, even if there are
multiple build and release agents available. You
also ensure that pre-deployment approval requests for the
stage are sent out in sequence.
Deploy latest and cancel the others:
Use this option if you are producing releases faster
than builds, and you only want to deploy the latest build.
To understand how these options work, consider a scenario
where releases R1, R2, ..., R5 of a
single release pipeline get created in quick succession.
Assume that
the first stage in this pipeline is named QA
and has both pre-deployment and post-deployment approvers
defined.
If you do not specify a limit for the number of parallel deployments,
all five approval requests will be sent out as soon as
the releases are created. If the approvers grant approval for all of the
releases, they will all be deployed to the QA stage in parallel.
(if the QA stage did not have any pre-deployment
approvers defined, all the five releases will automatically
be deployed in parallel to this stage).
If you specify a limit and Deploy all in sequence,
and the limit has already been reached, the pre-deployment approval for
release R1 will be sent out first. After this
approval is completed, the deployment of release R1 to the
QA stage begins. Next, a request for
post-deployment approval is sent out for release R1. It is
only after this post-deployment approval is completed that
execution of release R2 begins and its pre-deployment
approval is sent out. The process continues like this for
all of the releases in turn.
If you specify a limit and Deploy latest and cancel the others,
and the limit has already been reached, releases R2, R3, and R4 will be
skipped, and the pre-deployment approval for R5 in
the QA stage will be sent out immediately
after the post-deployment approval for release R1 is completed.