Machine Learning Studio (クラシック) でモデルのパフォーマンスを評価する
適用対象:  Machine Learning Studio (クラシック)
Machine Learning Studio (クラシック)  Azure Machine Learning
Azure Machine Learning
重要
Machine Learning Studio (クラシック) のサポートは、2024 年 8 月 31 日に終了します。 その日までに、Azure Machine Learning に切り替えすることをお勧めします。
2021 年 12 月 1 日以降、新しい Machine Learning Studio (クラシック) リソースは作成できません。 2024 年 8 月 31 日まで、既存の Machine Learning Studio (クラシック) リソースを引き続き使用できます。
- ML Studio (クラシック) から Azure Machine Learning への機械学習プロジェクトの移動に関する情報を参照してください。
- Azure Machine Learning についての詳細を参照してください
ML Studio (クラシック) のドキュメントは廃止予定であり、今後更新されない可能性があります。
この記事では、Machine Learning Studio (クラシック) でモデルのパフォーマンスを監視するために使用できるメトリックについて説明します。 モデルのパフォーマンスの評価は、データ サイエンス プロセスの重要な段階の 1 つです。 その評価は、トレーニングしたモデルによるデータセットのスコア付け (予測) がどれほど成功したかを示す指標になります。 Machine Learning Studio (クラシック) では、機械学習の 2 つのメイン モジュールを使用したモデルの評価がサポートされています。
これらのモジュールを使用すれば、機械学習と統計情報でよく使用されるさまざまなメトリックの観点からモデルのパフォーマンスを確認できます。
モデルの評価は、以下と一緒に検討する必要があります。
以下の 3 種類の学習のシナリオを取り上げます。
- 回帰
- 二項分類
- 多クラス分類
評価とクロス検証
評価とクロス検証は、モデルのパフォーマンスを測定する標準的な方法です。 どちらの場合も評価メトリックが生成されるので、そのメトリックを確認したり、他のモデルと比較したりできます。
[モデルの評価] では、スコア付けされたデータセットが入力として 1 つ必要になります (2 つのモデルのパフォーマンスを比較する場合は 2 つ必要です)。 そのため、結果を評価する前に、[モデルのトレーニング] モジュールでモデルのトレーニングを実行し、[モデルのスコア付け] モジュールでデータセットの予測を作成しておく必要があります。 この評価は、スコア付けされたラベル/確率と実際のラベルに基づいて行われます。これらはすべて、[モデルのスコア付け] モジュールから出力されます。
あるいは、クロス検証を使用して、入力データの各サブセットに対して 10 分割のトレーニング/スコア付け/評価の操作を自動的に実行することもできます。 その場合、入力データは 10 分割され、1 つはテスト用、残りの 9 つはトレーニング用になります。 このプロセスが 10 回繰り返され、評価メトリックは平均化されます。 そのようにして、モデルが新しいデータセットにどの程度汎用化されるかを確認できます。 [モデルのクロス検証] モジュールでは、トレーニングをしていないモデルとラベルの付いたデータセットを取り込んで、10 回の処理のそれぞれの評価結果と平均値を出力します。
以下の各セクションでは、シンプルな回帰モデルと分類モデルを作成し、[モデルの評価] モジュールと [モデルのクロス検証] モジュールを使用してそれぞれのパフォーマンスを評価します。
回帰モデルの評価
自動車の大きさ、馬力、エンジンの仕様などの特徴を利用して、価格を予測するとします。 これは、ターゲット変数 (価格) が連続数値になる典型的な回帰問題です。 自動車のさまざまな特徴の値に基づいて価格を予測する線形回帰モデルを作成できます。 この回帰モデルを使用して、トレーニングで使用したのと同じデータセットのスコア付けを行うことができます。 自動車の価格を予測したら、その予測と実際の価格の差異の平均値に基づいてモデルのパフォーマンスを評価できます。 その一例として、Machine Learning Studio (クラシック) の [保存されたデータセット] セクションにある 自動車価格データ (生データ) データセット を使用します。
実験の作成
Machine Learning Studio (クラシック) で次のモジュールをワークスペースに追加します。
- 自動車価格データ (生データ)
- 線形回帰
- モデルのトレーニング
- モデルのスコア付け
- モデルの評価
図 1 のようにポートを接続し、[モデルのトレーニング] モジュールのラベル列を price に設定します。
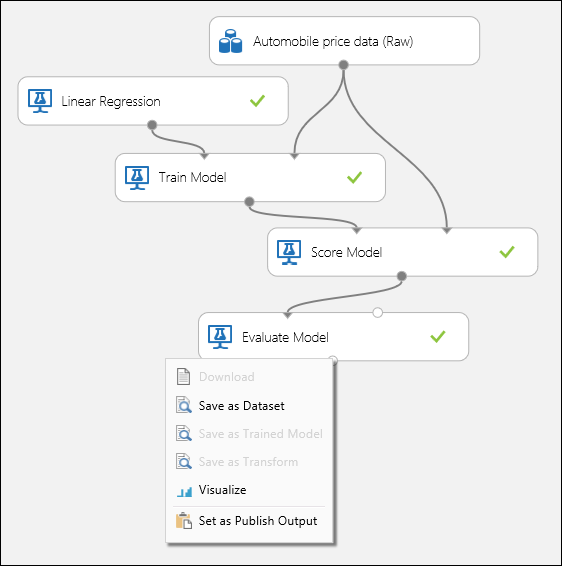
図 1. 回帰モデルの評価。
評価結果の確認
実験を実行したら、[モデルの評価] モジュールの出力ポートをクリックし、"視覚化" を選択して評価結果を確認できます。 回帰モデルで使用できる評価メトリックは、"平均絶対誤差"、"二乗平均絶対誤差"、"相対絶対誤差"、"相対二乗誤差"、"決定係数" です。
ここでは、予測の値と実際の値の差異のことを「誤差」といいます。 予測の値と実際の値の差が負の値になることもあるので、通常は、この差の絶対値または 2 乗が計算され、すべての事例の誤差が全体でどれほどの大きさになっているかを確認します。 誤差のメトリックでは、実際の値に対する予測の値の平均偏差に基づいて回帰モデルの予測パフォーマンスを測定します。 誤差の値が小さければ小さいほど、モデルの予測が正確だということになります。 全体の誤差のメトリックがゼロであれば、そのモデルはデータに完璧に適合しています。
決定係数 (R 2 乗) も、モデルとデータがどれほど適合しているかを測定するための標準的な方法です。 これは、モデルで説明される変動の比率として解釈できます。 この場合は、比率が高いほど良く、1 は完璧に適合している状態です。
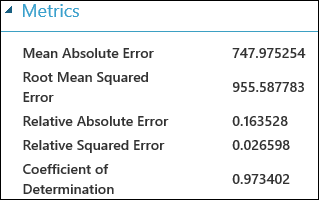
図 2. 線形回帰の評価メトリック。
クロス検証の使用
前述のとおり、[モデルのクロス検証] モジュールを使用すれば、トレーニング/スコア付け/評価の反復処理を自動的に実行できます。 この場合に必要なのは、データセット、トレーニングしていないモデル、および [モデルのクロス検証] モジュールのみです (下の図をご覧ください)。 [モデルのクロス検証] モジュールのプロパティで、ラベル列を price に設定する必要があります。
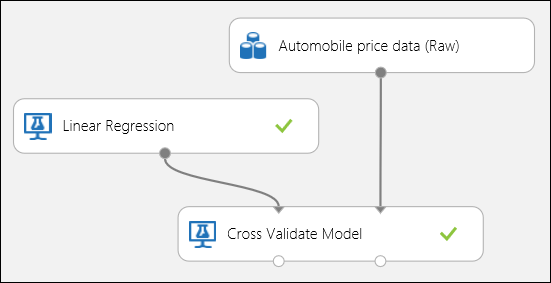
図 3。 回帰モデルのクロス検証。
実験を実行したら、[モデルのクロス検証] モジュールの該当する出力ポートをクリックして、評価結果を確認できます。 それぞれの反復処理 (分割処理) の詳細と、各メトリックの結果の平均値が表示されます (図 4)。
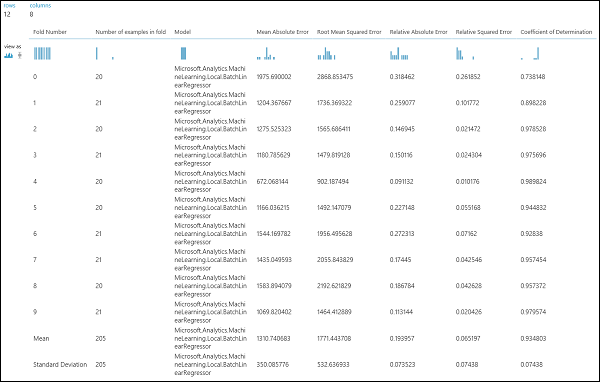
図 4 回帰モデルのクロス検証の結果。
二項分類モデルの評価
二項分類のシナリオでは、ターゲット変数には 2 つの選択肢しかありません。たとえば、{0, 1}、{偽, 真}、{負, 正} などです。 いくつかの人口統計や雇用の変数が含まれた成人従業員のデータセットが提供され、値 {"<=50 K", ">50 K"} を使った二項変数の収入レベルを予測するように依頼されたとします。 つまり、年収が 5 万ドル以下の従業員を表す負のクラスと、その他の従業員を表す正のクラスです。 回帰のシナリオの場合と同じく、モデルのトレーニング、データのスコア付け、結果の評価を行います。 ここでの主な違いは、Machine Learning Studio (クラシック) で計算され出力されるメトリックの選択です。 この収入レベルの予測シナリオでは、Adult データセットを使用して Studio (クラシック) の実験を作成し、よく使われている二項分類モデルである 2 クラスのロジスティック回帰モデルのパフォーマンスを評価します。
実験の作成
Machine Learning Studio (クラシック) で次のモジュールをワークスペースに追加します。
- 米国国勢調査局提供の、成人収入に関する二項分類データセット
- 2 クラス ロジスティック回帰
- モデルのトレーニング
- モデルのスコア付け
- モデルの評価
図 5 のようにポートを接続し、[モデルのトレーニング] モジュールのラベル列を income に設定します。
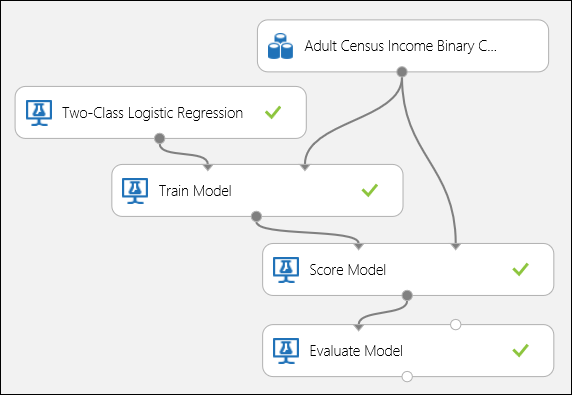
図 5。 二項分類モデルの評価。
評価結果の確認
実験を実行したら、[モデルの評価] モジュールの出力ポートをクリックし、"視覚化" を選択して評価結果を確認できます (図 7)。 二項分類モデルで使用できる評価メトリックは、"精度"、"正確度"、"再現率"、"F1 スコア"、"AUC" です。 さらに、このモジュールは、真陽性、偽陰性、偽陽性、真陰性の数を示す混同行列と "ROC"、"正確度/再現性"、"リフト" の曲線を出力します。
精度とは、簡単に言えば正しく分類された事例の比率です。 分類モデルを評価するときは通常、精度のメトリックに最初に注目します。 しかし、テスト データのバランスが悪い (ほとんどの事例が一方のクラスに属している )場合や、一方のクラスのパフォーマンスに主な関心がある場合には、実際には精度によって分類モデルの有効性が捕捉されるわけではありません。 たとえば、収入レベルの分類シナリオで、99% が年収 5 万ドル以下の層に属するデータをテストしているとしましょう。 どの事例についても "<=50K" の層を予測することで、0.99 の精度を達成することが可能です。 この分類モデルのパフォーマンスは非常に高いように思えるかもしれませんが、実際のところ、高収入の人たち (1%) を正確に分類することはできません。
そのため、多角的に評価するには、さらに別のメトリックを計算する必要があります。 そのようなメトリックを詳しく取り上げる前に、二項分類の評価の混同行列について理解しておくことは重要です。 トレーニング セットのクラス ラベルには 2 つの値しかありません。通常は、正の値と負の値です。 分類モデルが正しく予測した正の事例と負の事例のことを、それぞれ真陽性 (TP) と真陰性 (TN) といいます。 また、間違って分類した事例のことを、それぞれ偽陽性 (FP) と偽陰性 (FN) といいます。 混同行列とは、簡単に言えば、この 4 つの分類に該当する事例の数をまとめた表です。 Machine Learning Studio (クラシック) によって、データセット内の 2 つのクラスのうちどちらが正のクラスかが自動的に決定されます。 クラス ラベルがブール値または整数値であれば、「真」または「1」のラベルの事例が正のクラスに割り当てられます。 収入のデータセットの場合のようにラベルが文字列であれば、ラベルがアルファベット順に並べ替えられ、最初に選択されるレベルが負のクラス、2 番目のレベルが正のクラスになります。
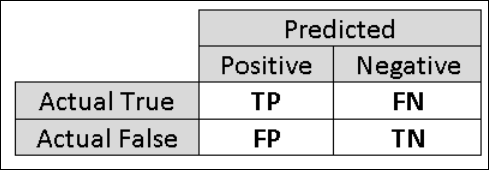
図 6。 二項分類の混同行列。
収入の分類問題に戻りましょう。分類モデルのパフォーマンスを評価するために、いくつかのことを確認したいと思います。 まず思い浮かぶのは次のような点です。モデルによって年収が 5 万ドル超と予測された人 (TP+FP) のうち、その予測が正しかった人 (TP) の割合はどれほどでしょうか。 これを確かめるには、モデルの精度 (正しく分類された陽性の比率: TP/(TP+FP)) を確認します。 また、次のような疑問も思い浮かびます。年収が 5 万ドルを超える高収入の従業員 (TP+FN) のうち、その分類モデルによって正しく分類された人 (TP) の割合はどれほどでしょうか。 これは実際には再現率または真陽性率になります。つまり、分類子の TP/(TP+FN) になります お気づきかもしれませんが、精度と再現率はトレードオフの関係になっています。 たとえば、比較的バランスの取れたデータセットの場合、ほとんどを正の事例として予測する分類モデルは、再現率が高くなります。一方、負の事例の多くが間違って分類され、偽陽性の数が多くなるので、精度は低めになります。 評価結果の出力ページ (図 7 の左上の部分) にある精度/再現率曲線をクリックすれば、この 2 つのメトリックがどう変化するかを示すプロットを表示できます。
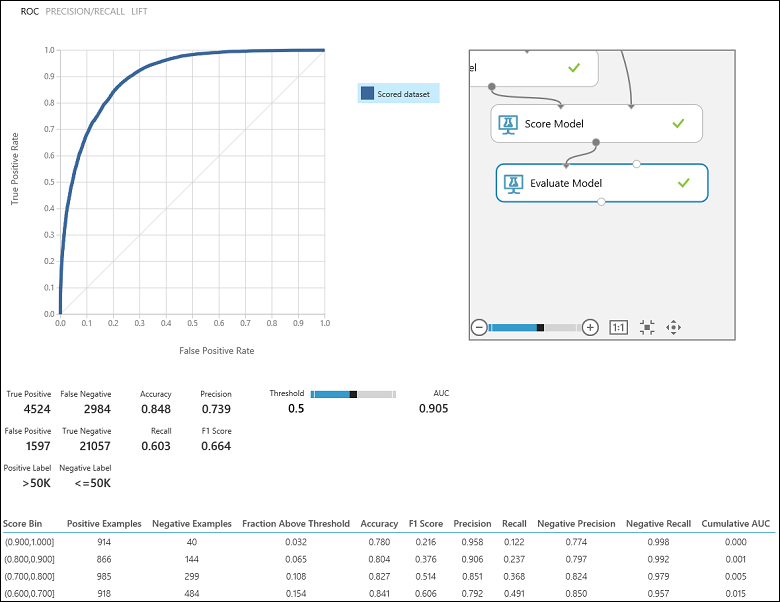
図 7. 二項分類の評価結果。
F1 スコアもよく使うメトリックです。この場合は、精度と再現率の両方を考慮に入れます。 これは、これら 2 つのメトリックの調和平均であり、F1 = 2 (精度 x 再現率) / (精度 + 再現率) のように計算されます。 F1 スコアは、1 つの数字で評価を要約するための便利な方法ですが、分類モデルの動作の仕組みをより詳しく把握するには、精度と再現率の両方を併せて確認することをお勧めします。
さらに、受信者操作特性 (ROC) 曲線とそれに対応する曲線下面積 (AUC) 値で真陽性率と偽陽性率の対比を確認できます。 この曲線が左上隅に近いほど、分類モデルのパフォーマンスは良好です (つまり、真陽性率が高く、偽陽性率が低くなります)。 ほぼ当てずっぽうのような予測をする傾向の強い分類モデルでは、プロットの対角線に近い曲線になります。
クロス検証の使用
回帰の例と同じく、クロス検証を使用して、データの各サブセットのトレーニング、スコア付け、評価を自動的に反復実行できます。 また、[モデルのクロス検証] モジュールでは、トレーニングしていないロジスティック回帰モデルとデータセットを使用できます。 [モデルのクロス検証] モジュールのプロパティで、ラベル列を income に設定する必要があります。 実験を実行して、[モデルのクロス検証] モジュールの該当する出力ポートをクリックすれば、各分割処理の二項分類メトリック値とそれぞれの平均偏差と標準偏差を確認できます。
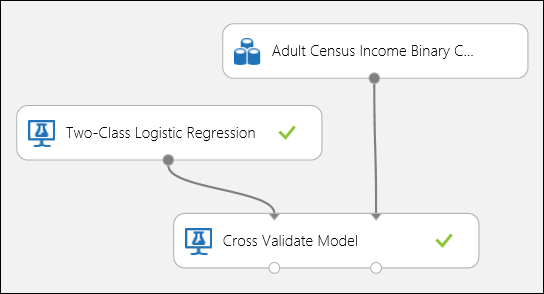
図 8. 二項分類モデルのクロス検証。
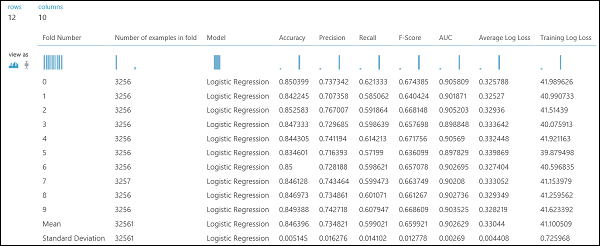
図 9. 二項分類モデルのクロス検証の結果。
多クラス分類モデルの評価
この実験では、3 種類 (クラス) のあやめの事例が含まれている有名な Iris データセットを使います。 事例ごとに 4 つの特徴値 (がくの長さ、がくの幅、花弁の長さ、花弁の幅) があります。 前の実験では、同じデータセットを使ってモデルのトレーニングとテストを行いました。 今回は、[データの分割] モジュールを使ってデータのサブセットを 2 つ作成し、1 つ目でトレーニングを行い、2 つ目でスコア付けと評価を行います。 Iris データセットは UCI Machine Learning Repository で公開されており、[データのインポート] モジュールを使ってダウンロードできます。
実験の作成
Machine Learning Studio (クラシック) で次のモジュールをワークスペースに追加します。
図 10 のようにポートを接続します。
[モデルのトレーニング] モジュールのラベル列のインデックスを 5 に設定します。 このデータセットにはヘッダー行がありませんが、クラス ラベルが第 5 列にあります。
[データのインポート] モジュールをクリックし、"データ ソース" プロパティを "HTTP を使用する Web URL" に設定し、"URL" を http://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data に設定します。
[データの分割] モジュールでトレーニングに使用する事例の割合を設定します (0.7 など)。
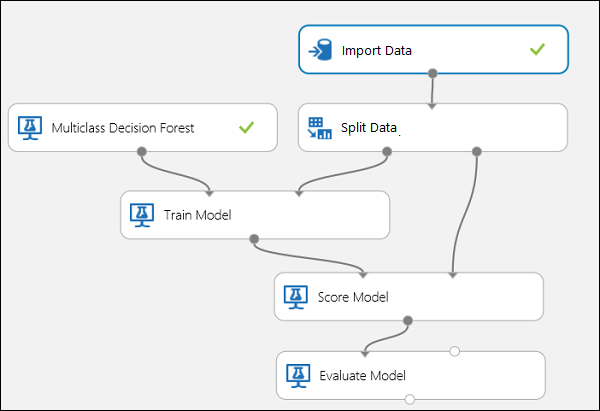
図 10. 多クラス分類モデルの評価
評価結果の確認
実験を実行し、モデルの評価の出力ポートをクリックします。 この場合は、評価結果が混同行列の形式で表示されます。 この行列で、3 つのクラスすべての実際の事例と予測の事例を確認できます。
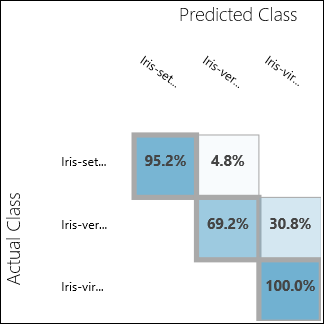
図 11. 多クラス分類の評価結果。
クロス検証の使用
前述のとおり、[モデルのクロス検証] モジュールを使用すれば、トレーニング/スコア付け/評価の反復処理を自動的に実行できます。 データセット、トレーニングしていないモデル、[モデルのクロス検証] モジュールが必要です (下の図を参照)。 この場合も、[モデルのクロス検証] モジュールのラベル列を設定しなければなりません (この場合は列のインデックスを 5 にします)。 実験を実行して、[モデルのクロス検証] の該当する出力ポートをクリックすれば、各分割処理のメトリック値に加え、平均偏差と標準偏差も確認できます。 この場合に表示されるメトリックは、二項分類の例で取り上げたメトリックと同じです。 ただし、多クラス分類では、真陽性と陰性、偽陽性と陰性の計算がクラスごとに行われ、正または負のクラスの全体の値はありません。 たとえば、'Iris-setosa' クラスの精度や再現率を計算する場合は、これが正のクラスで他はすべて負であると仮定されます。
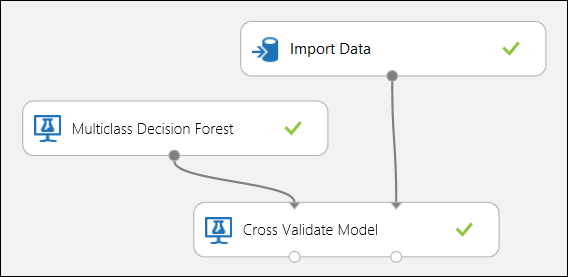
図 12. 多クラス分類モデルのクロス検証。
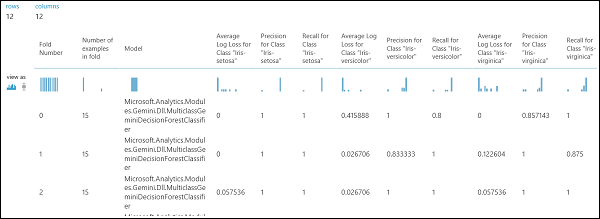
図 13. 多クラス分類モデルのクロス検証の結果。