K-Means クラスタリング
重要
Machine Learning Studio (クラシック) のサポートは、2024 年 8 月 31 日に終了します。 その日までに、Azure Machine Learning に切り替えすることをお勧めします。
2021 年 12 月 1 日以降、新しい Machine Learning Studio (クラシック) リソースは作成できません。 2024 年 8 月 31 日まで、既存の Machine Learning Studio (クラシック) リソースを引き続き使用できます。
- ML Studio (クラシック) から Azure Machine Learning への機械学習プロジェクトの移動に関する情報を参照してください。
- Azure Machine Learning についての詳細を参照してください。
ML Studio (クラシック) のドキュメントは廃止予定であり、今後更新されない可能性があります。
K-Means クラスタリング モデルを構成して初期化します
カテゴリ: 機械学習 / モデルの初期化 / クラスタリング
注意
適用対象: Machine Learning Studio (クラシック) のみ
類似のドラッグ アンド ドロップ モジュールは Azure Machine Learning デザイナーで使用できます。
モジュールの概要
この記事では、Machine Learning Studio (クラシック) の K-Means クラスタリング モジュールを使用して、トレーニングされていない K-Means クラスタリング モデルを作成する方法について説明します。
K 平均は、最も単純で最もよく知られている教師 なし 学習アルゴリズムの 1 つであり、異常なデータの検出、テキスト ドキュメントのクラスタリング、他の分類または回帰方法 を使用する前のデータセットの分析など、さまざまな機械学習タスクに使用できます。 クラスタリング モデルを作成するには、このモジュールを実験に追加し、データセットに接続して、予想されるクラスターの数、クラスターの作成に使用するために距離メトリックなど、パラメーターを設定します。
モジュールハイパーパラメーターを構成したら、トレーニングされていないモデルを クラスタリング モデルのトレーニング または スイープ クラスタリング モジュールに接続して、指定した入力データでモデルをトレーニングします。 K-Means アルゴリズムは教師なし学習方法なので、ラベル列は省略可能です。
- データにラベルが含まれる場合は、ラベルの値を使用して、クラスターの選択を示し、モデルを最適化することができます。
- データにラベルがない場合、アルゴリズムによって、データのみに基づいて可能なカテゴリを表すクラスターが作成されます。
ヒント
トレーニング データにラベルがある場合は、Machine Learning で提供されている監視対象 の分類 方法の 1 つを使用することを検討してください。 たとえば、マルチクラス デシジョン ツリー アルゴリズムのいずれかを使用する場合、クラスタリングの結果と結果を比較できます。
K-Means クラスタリングを理解する
一般に、クラスタリングでは、反復的な技術を使用して、データセットのケースを同様の特性を含むクラスターにグループ化します。 これらのグループ化は、データを探索して、データ内の異常を識別し、最終的に予測を行うために便利です。 クラスタリング モデルは、参照またはシンプルな監視によって論理的に派生する可能性がないデータセットで、リレーションシップを識別するのにも役立ちます。 これらの理由から、クラスタリングは、データの詳細を確認し、予期しない相関を検出するために、機械学習タスクの初期フェーズで使用されることが多いです。
K-Means メソッドを使用してクラスタリング モデルを構成する場合、モデルで必要な重心の数を示す、ターゲット数 k を指定する必要があります。 重心は、各クラスターの代表的なポイントです。 K-Means アルゴリズムでは、クラスター内の平方和を最小限にすることで、クラスターのいずれかに各受信データ ポイントを割り当てます。
トレーニング データを処理していると、K-Means アルゴリズムがクラスターごとの開始点として機能するランダムに選択された重心の初期セットで開始され、Lloyd のアルゴリズムを適用して重心の場所を繰り返し絞り込みます。 次の条件の 1 つまたは複数に合致するときに、K-Means アルゴリズムによってクラスターのビルドと絞り込みが停止されます。
重心が固定されている。つまり、個別のポイントへのクラスターの割り当てはこれ以上変更されることはなく、アルゴリズムはソリューションに集中しているということです。
アルゴリズムによって、指定されたイテレーションの数の実行が完了している。
トレーニング フェーズが完了したら、K-Means アルゴリズムによって見付けられたクラスターの 1 つに新しいケースを割り当てるために、Assign Data to Clusters (クラスターにデータを割り当て) モジュールを使用します。 クラスターの割り当ては、新しいケースと各クラスターの重心の距離を計算することで実行されます。 新しいケースはそれぞれ、最も近い重心を持つクラスターに割り当てられます。
K-Means Clustering (K-Means クラスタリング) を構成する方法
K-Means Clustering (K-Means クラスタリング) モジュールを自分の実験に追加します。
[Create trainer mode](トレーナー モードの作成) オプションを設定して、モデルのトレーニング方法を指定します。
Single Parameter (単一パラメーター) : クラスタリング モデルで使用する正確なパラメーターを把握している場合は、特定の値のセットを引数として指定できます。
パラメーター範囲: 最適なパラメーターがわからない場合は、複数の値を指定し、 スイープ クラスタリング モジュールを使用して最適な構成を見つけることで、最適なパラメーターを見つけることができます。
トレーナーは、指定した設定の複数の組み合わせを反復処理し、最適なクラスタリング結果を生成する値の組み合わせを決定します。
[ 重心の数] に、アルゴリズムを開始するクラスターの数を入力します。
モデルでは、正確にこのクラスターの数が生成されることが保証されるわけではありません。 algorithn は、この数のデータ ポイントから始まり、「 テクニカル ノート 」セクションで説明されているように、反復処理して最適な構成を見つけます。
パラメーター スイープを実行している場合、プロパティの名前は [ 重心の数] の [範囲] に変わります。 範囲ビルダーを使用して範囲を指定することも、各モデルを初期化するときに作成するクラスターの数を表す一連の数値を入力することもできます。
プロパティ の初期化 または スイープの初期化 は、初期クラスター構成の定義に使用されるアルゴリズムを指定するために使用されます。
最初の N: データ セットからいくつかの初期数のデータ ポイントが選択され、最初の手段として使用されます。
Forgy メソッドとも呼ばれます。
ランダム: アルゴリズムによって、クラスターにデータ ポイントがランダムに配置され、クラスターのランダムに割り当てられたポイントの重心になる初期平均値が計算されます。
ランダム パーティション メソッドとも呼ばれます。
K-Means++ : これは、クラスターの初期化に対する既定のメソッドです。
K-Means ++ アルゴリズムは、標準の K-Means アルゴリズムによって適切でないクラスタリングを避けるために、2007 年に David Arthur と Sergei Vassilvitskii によって提案されました。 K-Means ++ では、初期クラスターの中心を選ぶために別のメソッドを使用することで、標準の K-Means が改善されます。
K-Means++Fast: クラスタリングを高速化するために最適化された K-means ++ アルゴリズムのバリアント。
均等: 重心は、n 個のデータ ポイントの d 次元空間内で互いに等間隔に配置されます。
ラベル列を使用する: ラベル列の値は、重心の選択をガイドするために使用されます。
[Random number seed]\(乱数シード\) には、クラスターの初期化にシードとして使用する値を必要に応じて入力します。 この値は、クラスターの選択に大きな影響を及ぼすことがあります。
パラメーター スイープを使用する場合は、最適な初期シード値を探すために、複数の初期シードを作成するように指定できます。 [ スイープするシードの数] に、開始点として使用するランダム シード値の合計数を入力します。
[Metric]\(メトリック\) で、クラスター ベクター間、または新しいデータ ポイントとランダムに選択された重心の間の距離を測定するために使用する関数を選びます。 Machine Learning では、次のクラスター距離メトリックがサポートされています。
ユークリッド: ユークリッド距離は、一般的に K-Means クラスタリング用のクラスター散布図のメジャーとして使用されます。 ポイントと重心の間の平均距離が最小になるため、このメトリックが推奨されます。
コサイン: コサイン関数は、クラスターの類似性を測定するために使用されます。 コサイン類似性は、ベクトルの長さを気にせず、その角度だけを気にする場合に便利です。
[Iterations]\(イテレーション\) には、重心の選択を確定する前に、アルゴリズムがトレーニング データを反復させる必要がある回数を入力します。
このパラメーターを調整して、精度とトレーニングの時間の差を調整します。
[Assign label mode]\(ラベル モードの割り当て\) で、ラベル列 (データセットに存在する場合) が処理される方法を指定するオプションを選びます。
K-Means クラスタリングは教師なしの機械学習メソッドのため、ラベルは省略可能です。 しかし、データセットに既にラベル列がある場合は、それらの値を使用してクラスターの選択を示したり、値を無視するように指定したりすることができます。
Ignore label column (ラベル列を無視する) : ラベル列の値は無視され、モデルのビルドには使用されません。
Fill missing values (欠落値を入力する) : ラベル列の値は、クラスターのビルドに役立つフィーチャーとして使用されます。 任意の行にラベルが不足している場合は、その値はその他のフィーチャーを使用することで補完されます。
Overwrite from closest to center (中心に最も近い値から上書きする) : ラベル列の値は、現在の重心に最も近いポイントのラベルを使用して、予測ラベル値に置き換えられます。
モデルをトレーニングする。
[Create trainer mode]\(トレーナー モードの作成\)を [Single Parameter]\(単一パラメーター\) に設定した場合、Train Clustering Model (クラスタリング モデルのトレーニング) モジュールを使用することで、タグ付けしたデータセットを追加してモデルをトレーニングします。
[ トレーナー モードの作成 ] を [パラメーター範囲] に設定した場合は、タグ付けされたデータセットを追加し、 スイープ クラスタリングを使用してモデルをトレーニングします。 これらのパラメーターを使用してトレーニングされたモデルを使用するか、学習器を構成するときに使用するパラメーターの設定を書き留めてください。
結果
モデルの構成とトレーニングが完了したら、スコアの生成に使用できるモデルができます。 しかし、モデルのトレーニングには複数の方法があり、結果を表示して使用するには複数の方法があります。
ワークスペースでモデルのスナップショットをキャプチャする
クラスタリング モデルのトレーニング モジュールを使用した場合
- Train Clustering Model (クラスタリング モデルのトレーニング) モジュールを右クリックします。
- [Trained model]\(トレーニングされたモデル\) を選択して、[Save as Trained Model]\(トレーニングされたモデルとして保存\) をクリックします。
スイープ クラスタリング モジュールを使用してモデルをトレーニングした場合
- スイープ クラスタリング モジュールを右クリックします。
- [ 最適なトレーニング済みモデル ] を選択し、[ トレーニング済みモデルとして保存] をクリックします。
保存されたモデルは、モデルを保存したときのトレーニング データを表します。 実験で使用したトレーニング データを後で更新する場合、保存されたモデルは更新されません。
モデル内のクラスターの視覚的表現を確認する
クラスタリング モデルのトレーニング モジュールを使用した場合
- モジュールを右クリックし、[ 結果データセット] を選択します。
- [可視化] を選択します。
スイープ クラスタリング モジュールを使用した場合
[Assign Data to Clusters]\(クラスターへのデータの割り当て\) モジュールのインスタンスを追加し、最適なトレーニング済みモデルを使用してスコアを生成します。
[ クラスターへのデータの割り当て ] モジュールを右クリックし、[ 結果データセット] を選択して、[視覚化] を選択 します。
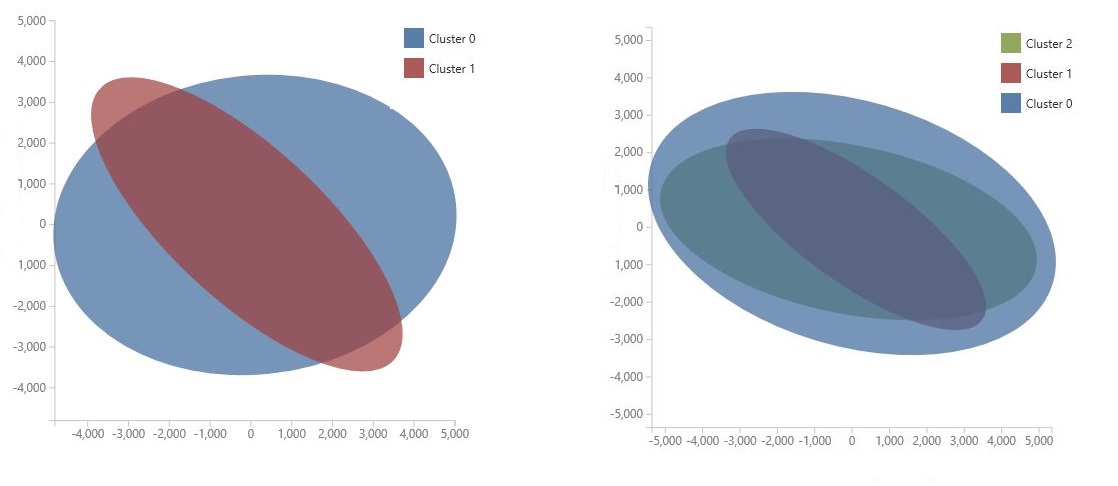
グラフは、モデルの特徴空間を圧縮するためのデータ サイエンスの手法である 主成分分析を使用して生成されます。 グラフには、クラスター間の違いを最も適切に特徴付けするために、2 つのディメンションに圧縮された一連の特徴が表示されます。 各クラスターの機能空間の一般的なサイズとクラスターの重なりを視覚的に確認することで、モデルのパフォーマンスを把握できます。
たとえば、次の PCA グラフは、同じデータを使用してトレーニングされた 2 つのモデルの結果を表しています。1 つ目は 2 つのクラスターを出力するように構成され、2 つ目は 3 つのクラスターを出力するように構成されています。 これらのグラフから、クラスターの数を増やすと、クラスの分離が必ずしも向上しなかったことがわかります。
ヒント
スイープ クラスタリング モジュールを使用して、ランダム シードや開始重心の数など、ハイパーパラメーターの最適なセットを選択します。
データ ポイントとそのデータ ポイントが属するクラスターの一覧を表示する
モデルのトレーニング方法に応じて、結果を含むデータセットを表示するには、次の 2 つのオプションがあります。
スイープ クラスタリング モジュールを使用してモデルをトレーニングした場合
- [スイープ クラスタリング] モジュールのチェックボックスを使用して、入力データを結果と共に表示するか、結果だけを表示するかを指定します。
- トレーニングが完了したら、モジュールを右クリックし、 結果データセット (出力番号 2) を選択します
- [ 視覚化] をクリックします。
クラスタリング モデルのトレーニング モジュールを使用した場合
- [Assign Data to Clusters]\(クラスターへのデータの割り当て\) モジュールを追加し、トレーニング済みのモデルを左側の入力に接続します。 データセットを右側の入力に接続します。
- データセットへの変換モジュールを実験に追加し、クラスターへのデータの割り当ての出力に接続します。
- [ クラスターへのデータの割り当て ] モジュールのチェックボックスを使用して、入力データを結果と共に表示するか、結果だけを表示するかを指定します。
- 実験を実行するか、 データセットへの変換 モジュールのみを実行します。
- [ データセットに変換] を右クリックし、[ 結果データセット] を選択して、[ 視覚化] をクリックします。
出力には、入力データ列を含める場合は最初に入力データ列が含まれ、入力データの各行に対して次の列が含まれます。
割り当て: 割り当ては 1 から n までの値で、 n はモデル内のクラスターの合計数です。 データの各行は、1 つのクラスターにのみ割り当てることができます。
DistancesToClusterCenter no.n: この値は、現在のデータ ポイントからクラスターの重心までの距離を測定します。 トレーニング済みモデル内のクラスターごとに出力内の個別の列。
クラスター距離の値は、[クラスターの 結果を測定するためのメトリック] オプションで選択した距離メトリックに基づいています。 クラスタリング モデルに対してパラメーター スイープを実行した場合でも、スイープ中に適用できるメトリックは 1 つだけです。 メトリックを変更すると、異なる距離値が得られる場合があります。
クラスター内の距離を視覚化する
前のセクションの結果のデータセットで、各クラスターの距離の列をクリックします。 Studio (クラシック) では、クラスター内のポイントの距離の分布を視覚化するヒストグラムが表示されます。
たとえば、次のヒストグラムは、4 つの異なるメトリックを使用して、同じ実験からのクラスター距離の分布を示しています。 パラメーター スイープのその他の設定はすべて同じでした。 メトリックを変更すると、1 つのモデルで異なる数のクラスターが生成されました。
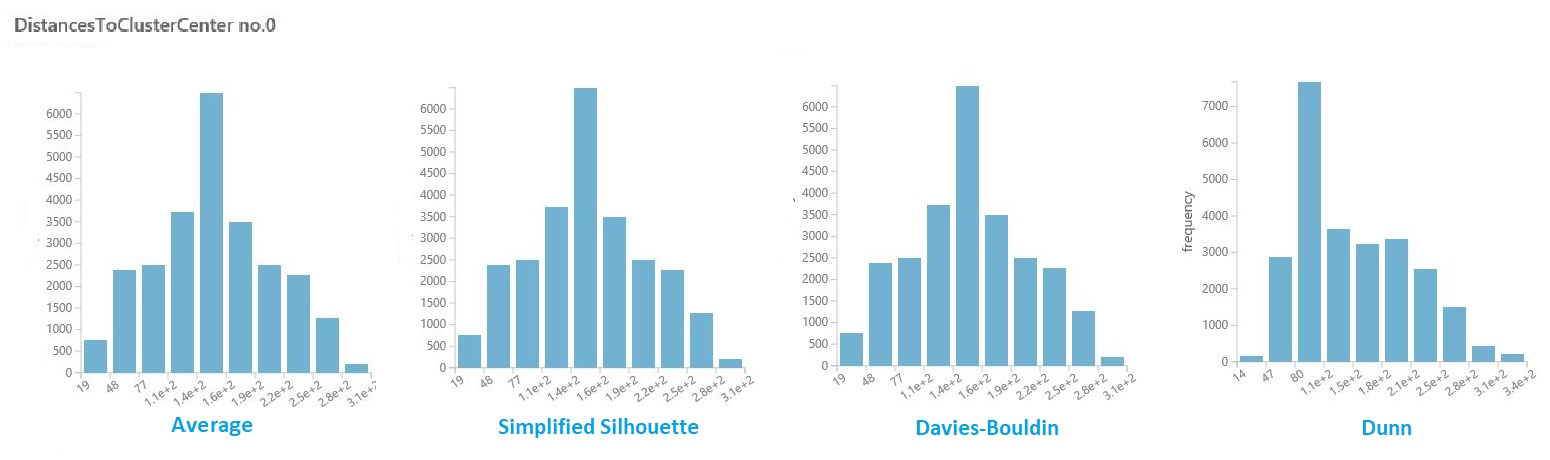
一般に、異なるクラス内のデータ ポイント間の距離を最大化し、クラス内の距離を最小限に抑えるメトリックを選択する必要があります。 [ 統計 ] ウィンドウで事前計算済みの平均とその他の値を使用して、この決定について説明できます。
ヒント
機械学習用の PowerShell モジュールを使用して、視覚化で使用される平均やその他の値を抽出できます。
または、 R スクリプトの実行 モジュールを使用して、カスタム距離マトリックスを計算します。
最適なクラスタリング モデルを生成するためのヒント
クラスタリング中に使用されるシード処理プロセスが、モデルに大きく影響することが知られています。 シード処理は、可能性がある重心へのポイントの初期配置を意味します。
たとえば、データセットに多くの外れ値が含まれ、外れ値がクラスターをシードするために選択された場合、その他のデータ ポイントがそのクラスターにうまく適合することはなく、クラスターはシングルトンになる可能性があります。つまり、1 つのポイントのみのクラスターになります。
この問題を回避するには、さまざまな方法があります。
パラメーター スイープを使用して重心の数を変更し、複数のシード値を試します。
メトリックを変えるか、さらに反復処理して、複数のモデルを作成します。
PCA などのメソッドを使用して、クラスタリングに悪影響を及ぼす変数を見つけます。 この手法のデモについては、「 類似企業を検索 する」サンプルを参照してください。
一般に、クラスタリング モデルを使用すると、任意の指定された構成は、ローカルで最適化されたクラスターのセットになる可能性があります。 つまり、モデルで返されたクラスターのセットは、現在のデータ ポイントのみに適し、その他のデータに対して汎化可能ではありません。 別の初期構成を使用する場合、K-Means メソッドは別の (上位である可能性がある) 構成であることに気付くことがあります。
重要
常にパラメーターを試し、複数のモデルを作成し、結果のモデルを比較することをお勧めします。
例
Machine Learning での K-Means クラスタリングの使用方法の例については、 Azure AI ギャラリーで次の実験を参照してください。
グループ虹彩データ: 分類タスクの K 平均クラスタリング と 多クラスロジスティック回帰 の結果を比較します。
カラー量子化サンプル:最適な画像圧縮を見つけるために、異なるパラメータを持つ複数のK平均モデルを構築します。
クラスタリング: 類似企業: S&P500 で類似企業のグループを見つけるために、重心の数が異なります。
テクニカル ノート
K-Means アルゴリズムでは、特定の数のクラスター (K) で D 次元データ ポイントと N データ ポイントのセットを見つける際に、次のようなクラスターを構築します。
モジュールは、見つかった K クラスターを定義する最終的な重心を使用して K-by-D 配列を初期化します。
既定では、モジュールは K クラスターに最初の K データ ポイントを割り当てます。
K 重心の初期セット以降、このメソッドでは Lloyd のアルゴリズムを使用して、重心の位置を繰り返し絞り込みます。
このアルゴリズムは、重心が安定したとき、または指定された数のイテレーションが完了したときに終了します。
類似性メトリック (既定では、ユークリッド距離) を使用して、重心の最も近いクラスターに各データ ポイントが割り当てられます。
警告
- パラメーター範囲を クラスタリング モデルのトレーニングに渡すと、パラメーター範囲リストの最初の値のみが使用されます。
- 1 つのパラメーター値のセットを スイープ クラスタリング モジュールに渡すと、各パラメーターの設定範囲が予期される場合、値は無視され、学習者の既定値が使用されます。
- [Parameter Range](パラメーター範囲) オプションを選択し、任意のパラメーターに単一の値を入力した場合、指定した単一の値はスイープ全体で使用されます。これは、他のパラメーターが値の範囲の中で変化する場合でも同様です。
モジュールのパラメーター
| 名前 | Range | Type | Default | 説明 |
|---|---|---|---|---|
| 重心の数 | >=2 | Integer | 2 | 重心の数 |
| メトリック | リスト (サブセット) | メトリック | ユークリッド | 選択したメトリック |
| 初期化 | List | 重心初期化メソッド | K-Means++ | 初期化アルゴリズム |
| イテレーション | >=1 | Integer | 100 | イテレーション数 |
出力
| 名前 | 型 | 説明 |
|---|---|---|
| 未トレーニング モデル | ICluster インターフェイス | 未トレーニングの K-Means クラスタリング モデル |
例外
すべての例外の一覧については、「 Machine Learning モジュールのエラー コード」を参照してください。
| 例外 | 説明 |
|---|---|
| エラー 0003 | 1 つまたは複数の入力が null または空の場合、例外が発生します。 |