例: Azure Machine Learning を使用してカスタム スキルを構築してデプロイする (アーカイブ済み)
この例はアーカイブされ、サポート対象外です。 Azure Machine Learning を使用してカスタム スキルを作成し、レビューからアスペクトベースのセンチメントを抽出する方法について説明しました。 これにより、同じレビュー内で肯定的な感情と否定的な感情を割り当て、スタッフ、部屋、ロビー、プールなどの識別されたエンティティに正しく割り当てることができます。
Azure Machine Learning でアスペクトベースのセンチメント モデルをトレーニングするには、nlp レシピ リポジトリを使用します。 その後、そのモデルは Azure Kubernetes クラスター上にエンドポイントとしてデプロイされます。 デプロイされたエンドポイントは、Cognitive Search サービスで使用するための AML スキルとしてエンリッチメント パイプラインに追加されます。
提供されるデータセットは 2 つあります。 モデルを自分でトレーニングする場合は、hotel_reviews_1000.csv ファイルが必要です。 トレーニング手順をスキップする場合は、 hotel_reviews_100.csv をダウンロードします。
- Azure Cognitive Search インスタンスを作成する
- Azure Machine Learning ワークスペースを作成する (検索サービスとワークスペースが同じサブスクリプションに存在する必要があります)
- モデルをトレーニングして Azure Kubernetes クラスターにデプロイする
- デプロイされたモデルに AI エンリッチメント パイプラインをリンクする
- デプロイされたモデルからの出力をカスタム スキルとして取り込む
重要
このスキルはパブリック プレビュー段階にあり、追加使用条件の下で提供されます。 プレビューの REST API では、このスキルがサポートされています。
前提条件
- Azure サブスクリプション - 無料のサブスクリプションを入手できます。
- Cognitive Search サービス
- Cognitive Services リソース
- Azure Storage アカウント)
- Azure Machine Learning ワークスペース
セットアップ
- サンプル リポジトリのコンテンツをクローンまたはダウンロードします。
- ZIP ファイルをダウンロードしたら、コンテンツを展開します。 ファイルが読み取り/書き込み可能であることを確認します。
- Azure のアカウントとサービスを設定する際、簡単にアクセスできるテキスト ファイルにそれらの名前とキーをコピーします。 名前とキーは、ノートブックの最初のセルに追加されます。ここでは、Azure サービスにアクセスするための変数が定義されています。
- Azure Machine Learning とその要件に詳しくない場合は、作業を開始する前に次のドキュメントを確認してください。
- Azure Machine Learning のための開発環境を構成する
- Azure portal 内で Azure Machine Learning ワークスペースを作成および管理する
- Azure Machine Learning の開発環境を構成する場合は、クラウドベースのコンピューティング インスタンスを使用して開始時の速度と使いやすさを向上させることを検討してください。
- ストレージ アカウント内のコンテナーにデータセット ファイルをアップロードします。 ノートブックでトレーニング手順を実行するには、大きなファイルが必要です。 トレーニング手順をスキップする場合は、ファイルのサイズを小さくすることをお勧めします。
ノートブックを開いて Azure サービスに接続する
- Azure サービスへのアクセスを許可する変数に関する必要な情報を最初のセル内に入力し、そのセルを実行します。
- 2 番目のセルを実行すると、お使いのサブスクリプションの検索サービスに接続済みであることが確認されます。
- セクション 1.1 から 1.5 では、検索サービスのデータストア、スキルセット、インデックス、インデクサーが作成されます。
この時点では、Azure Machine Learning でトレーニング データ セットと実験を作成する手順をスキップし、GitHub リポジトリのモデル用フォルダーに用意されている 2 つのモデルの登録に直接進むことができます。 これらの手順をスキップする場合は、ノートブックのセクション 3.5 のスコアリング スクリプトの記述に進みます。 その結果、時間が節約されます。データのダウンロードとアップロードの手順の完了には、最大 30 分かかる場合があります。
モデルを作成してトレーニングする
セクション 2 には、nlp レシピ リポジトリから glove 埋め込みファイルをダウンロードする 6 つのセルがあります。 ダウンロード後、このファイルは Azure Machine Learning データストアにアップロードされます。 この .zip ファイルのサイズは約 2G あるため、これらのタスクを実行するには時間がかかります。 アップロードが完了すると、トレーニング データが抽出され、セクション 3 に進むことができます。
アスペクトベースのセンチメント モデルをトレーニングしてエンドポイントをデプロイする
ノートブックのセクション 3 では、セクション 2 で作成したモデルをトレーニングして登録し、Azure Kubernetes クラスターにエンドポイントとしてデプロイします。 Azure Kubernetes に詳しくない場合は、推論クラスターを作成する前に次の記事を確認することを強くお勧めします。
- Azure Kubernetes サービスの概要
- Azure Kubernetes Services (AKS) における Kubernetes の中心概念
- Azure Kubernetes Service (AKS) のクォータ、仮想マシンのサイズの制限、およびリージョンの可用性
推論クラスターの作成とデプロイには、最大 30 分かかる場合があります。 最後の手順に進む前に Web サービスをテストし、スキルセットを更新して、インデクサーを実行することをお勧めします。
スキルセットを更新する
ノートブックのセクション 4 には、スキルセットとインデクサーを更新する 4 つのセルがあります。 また、ポータルを使用して、新しいスキルを選択してスキルセットに適用してから、インデクサーを実行して検索サービスを更新することもできます。
ポータルで [スキルセット] に移動し、[スキルセットの定義 (JSON)] リンクを選択します。 ポータルには、ノートブックの最初のセルで作成されたスキルセットの JSON が表示されます。 画面の右側には、スキル定義テンプレートを選択できるドロップダウン メニューがあります。 Azure Machine Learning (AML) テンプレートを選択します。 Azure ML ワークスペースの名前と、推論クラスターにデプロイされたモデルのエンドポイントを指定します。 このテンプレートはエンドポイントの URI とキーで更新されます。
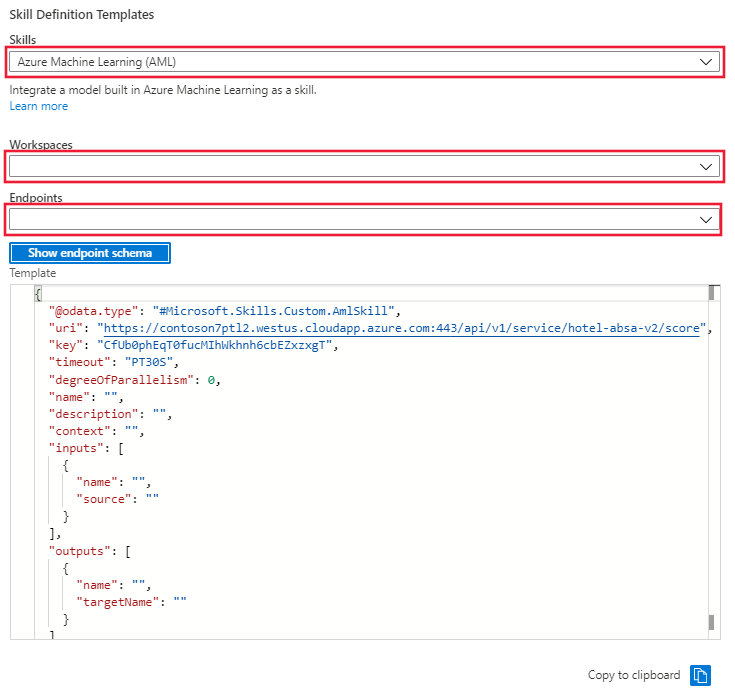
このウィンドウからスキルセット テンプレートをコピーし、左側のスキルセット定義に貼り付けます。 テンプレートを編集して、不足している次の値を指定します。
- 名前
- 説明
- Context
- "inputs" の名前とソース
- "outputs" の名前とターゲット名
スキルセットを保存します。
スキルセットを保存したら、インデクサーに移動し、[インデクサー定義 (JSON)] リンクを選択します。 ポータルには、ノートブックの最初のセルで作成されたインデクサーの JSON が表示されます。 出力フィールドのマッピングは、インデクサーが適切に処理して渡すことができるように、追加のフィールド マッピングを使用して更新する必要があります。 変更を保存し、[実行] を選択します。
リソースをクリーンアップする
独自のサブスクリプションを使用している場合は、プロジェクトの最後に、作成したリソースがまだ必要かどうかを確認してください。 リソースを実行したままにすると、お金がかかる場合があります。 リソースは個別に削除することも、リソース グループを削除してリソースのセット全体を削除することもできます。
ポータルの左側のナビゲーション ウィンドウにある [All resources](すべてのリソース) または [Resource groups](リソース グループ) リンクを使って、リソースを検索および管理できます。
無料サービスを使っている場合は、3 つのインデックス、インデクサー、およびデータソースに制限されることに注意してください。 ポータルで個別の項目を削除して、制限を超えないようにすることができます。