Microsoft Purview ガバナンス ポータルでの分類のベスト プラクティス
Microsoft Purview ガバナンス ポータルでのデータ分類は、データ資産に一意の論理ラベルまたはクラスを割り当てることで、データ資産を分類する方法です。 分類は、データのビジネス コンテキストに基づいています。 たとえば、パスポート番号、運転免許証番号、クレジット カード番号、SWIFT コード、人物名などによって資産を分類できます。 分類自体の詳細については、 分類に関する記事を参照してください。
この記事では、データ資産を分類するときに採用するベスト プラクティスについて説明します。これにより、スキャンがより効果的になり、データ資産全体に関する最も完全な情報が得られます。
スキャン ルール セット
スキャン ルール セットを使用すると、データ ソースの特定のスキャンに適用する必要がある関連する分類を構成できます。 関連するシステム分類を選択するか、スキャンするデータ用の分類を作成した場合はカスタム分類を選択します。
たとえば、次の図では、スキャンするデータ ソース (財務データなど) に対して、選択した特定のシステム分類とカスタム分類のみが適用されます。

注釈管理
適用する分類を決定するときは、次のことをお勧めします。
[データ マップ>注釈管理>の分類] ウィンドウに移動します。
スキャンするデータ資産に適用する使用可能なシステム分類を確認します。 システム分類の正式な名前には、 MICROSOFT プレフィックスがあります。
![[分類] ウィンドウのシステム分類の一覧を示すスクリーンショット。](media/concept-best-practices/classification-classification-example-4.png)
必要に応じて、カスタム分類名を作成します。 このウィンドウから開始し、 データ マップ>注釈管理>分類ルールに移動します。 ここでは、前の手順で作成したカスタム分類名の分類規則を作成できます。
![[分類ルール] ウィンドウを示すスクリーンショット。](media/concept-best-practices/classification-classification-rules-example-2.png)
![[分類] ウィンドウのシステム分類の一覧を示すスクリーンショット。](media/concept-best-practices/classification-classification-example-4.png#lightbox)
![[分類ルール] ウィンドウを示すスクリーンショット。](media/concept-best-practices/classification-classification-rules-example-2.png#lightbox)
カスタム分類
使用可能なシステム分類がニーズを満たしていない場合にのみ、カスタム分類を作成します。
カスタム分類の 名前 については、名前空間規則 (会社名など <) を使用することをお勧めします>。<ビジネス ユニット>。<カスタム分類名>)。
たとえば、架空の会社 Contoso のカスタム EMPLOYEE_ID分類の場合、カスタム分類の名前は CONTOSO.HR されます。EMPLOYEE_IDし、フレンドリ名は HR としてシステムに格納されます。EMPLOYEE ID。

カスタム分類の分類規則を作成して構成する場合は、次の操作を行います。
分類ルールを作成する適切な分類名を選択します。
Microsoft Purview ガバナンス ポータルでは、カスタム分類規則を作成するための次の 2 つの方法がサポートされています。
正規表現パターンを使用してデータ要素を一貫して表現できる場合、またはデータ ファイルを使用してパターンを生成できる場合は、正規表現 (regex) メソッドを使用します。 サンプル データに母集団が反映されていることを確認します。
Dictionary メソッドは、ディクショナリ ファイル内の値の一覧が分類されるデータの使用可能なすべての値を表し、(将来の値も考慮して) 特定のデータ セットに準拠することが予想される場合にのみ使用します。
![カスタム分類ルールを作成するための [正規表現] オプションと [辞書] オプションを示すスクリーンショット。](media/concept-best-practices/classification-custom-classification-rule-example-6.png)
正規表現メソッドの使用:
分類するデータの正規表現パターンを構成します。 正規表現パターンが、分類されるデータに対応するのに十分なジェネリックであることを確認します。
Microsoft Purview には、推奨される正規表現パターンを生成する機能も用意されています。 サンプル データ ファイルをアップロードした後、推奨されるパターンのいずれかを選択し、[ パターンに追加 ] を選択して、推奨されるデータと列のパターンを使用します。 推奨されるパターンを変更することも、ファイルをアップロードすることなく独自のパターンを入力することもできます。
列を分類して誤検知を最小限に抑えるように列名パターンを構成することもできます。
分類を適用するために、データ パターンに一致するデータに許容される最小一致 しきい値 パラメーターを構成します。 しきい値は、1% から 100% までです。 誤検知を回避するために、しきい値として 60% 以上の値を指定することをお勧めします。 ただし、特定の分類シナリオに必要に応じて構成できます。 たとえば、パターンに一致する場合、データ内の任意の値の分類を検出して適用する場合、しきい値は 1% まで低くなる可能性があります。
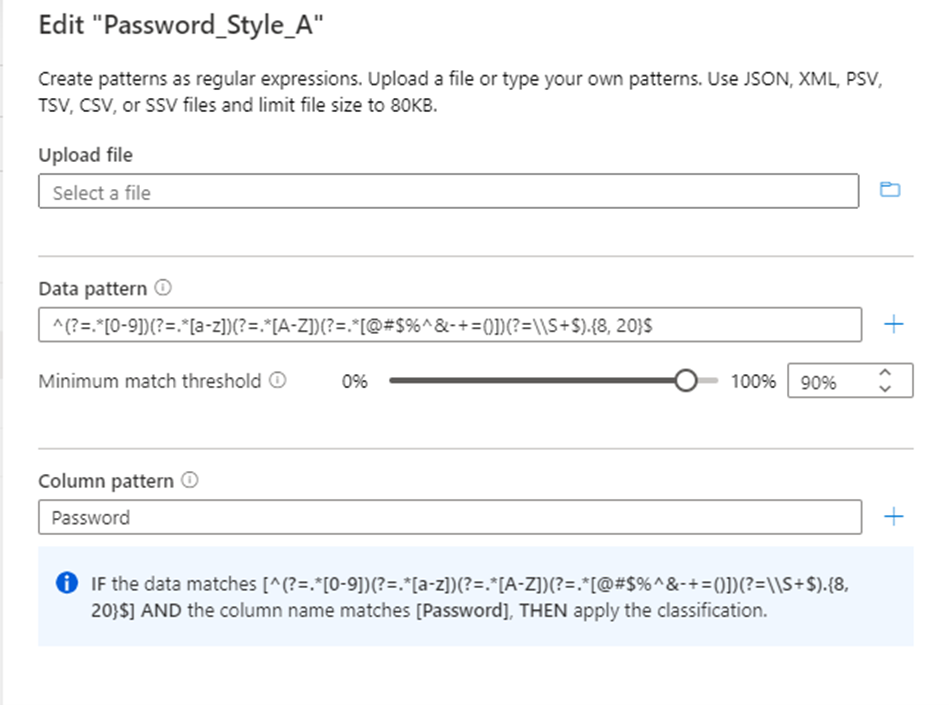
最小一致ルールを設定するオプションは、複数のデータ パターンが分類ルールに追加された場合に自動的に無効になります。
分類ルールのテストとサンプル データのテストを使用して、分類ルールが期待どおりに動作していることを確認します。 サンプル データ (たとえば、.csv ファイル内) に、分類を適用する列を含む少なくとも 3 つの列が存在することを確認します。 テストが成功した場合は、次の図に示すように、列に分類ラベルが表示されます。
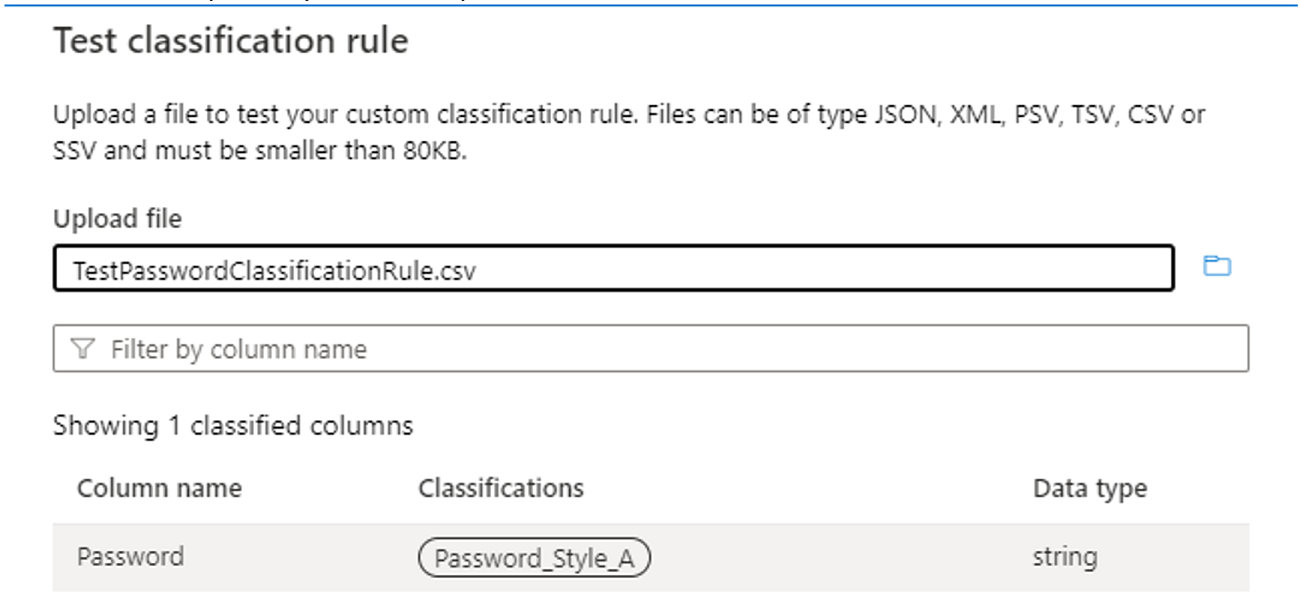
Dictionary メソッドの使用:
列挙データに合わせて Dictionary メソッドを使用するか、可能な値のディクショナリ リストを使用できる場合は、 Dictionary メソッドを使用できます。
このメソッドは、ファイル サイズ制限が 30 MB (MB) の .csv ファイルと .tsv ファイルをサポートします。
![カスタム分類ルールを作成するための [正規表現] オプションと [辞書] オプションを示すスクリーンショット。](media/concept-best-practices/classification-custom-classification-rule-example-6.png#lightbox)


カスタム分類のアーキタイプ
正規表現での "threshold" パラメーターのしくみ
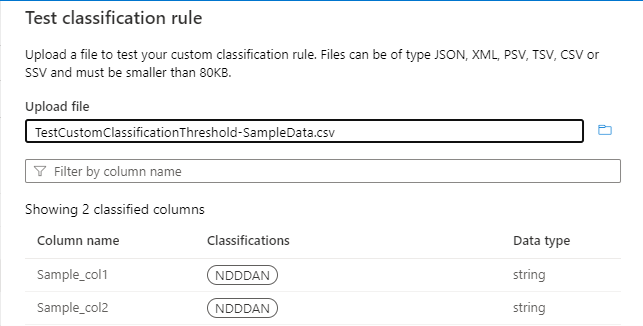
次の図のサンプル ソース データについて考えてみましょう。 列は 5 つあり、データ パターン N{Digit}{Digit}{Digit}AN の列Sample_col1、Sample_col2、Sample_col3にカスタム分類規則を適用する必要があります。
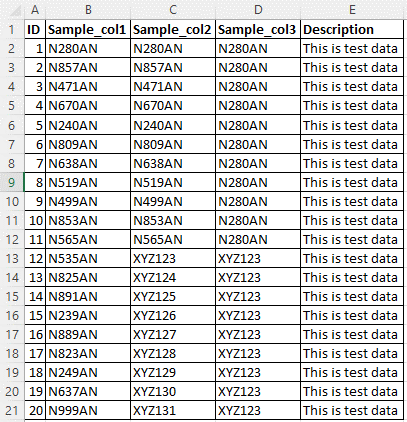
カスタム分類の名前は NDDDAN です。
分類規則 (データ パターンの正規表現) は ^N[0-9]{3}AN$ です。
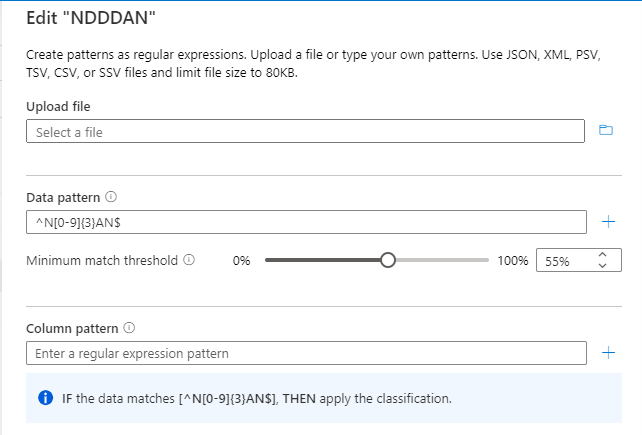
しきい値は、次の図に示すように、"^N[0-9]{3}AN$" パターンに対して計算されます。

しきい値が 55% の場合、 列Sample_col1 と Sample_col2 のみが分類されます。 Sample_col3 は、55% のしきい値基準を満たしていないため、分類されません。




データ パターンと列パターンの両方を使用する方法
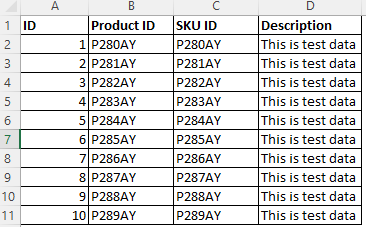
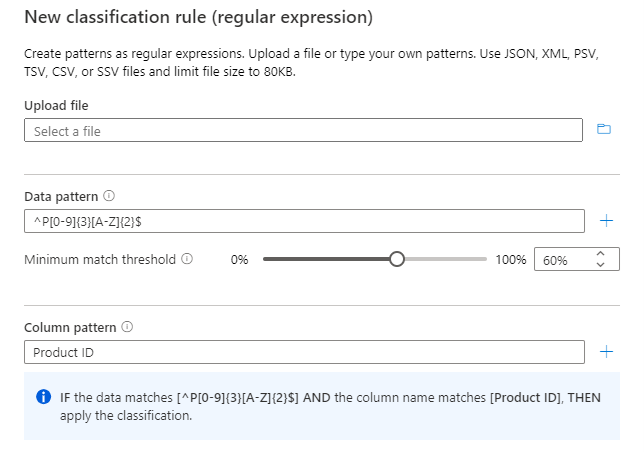
列 B と列 C の両方に類似のデータ パターンがある特定のサンプル データの場合、データ パターン "^P[0-9]{3}[A-Z]{2}$" に基づいて列 B に分類できます。
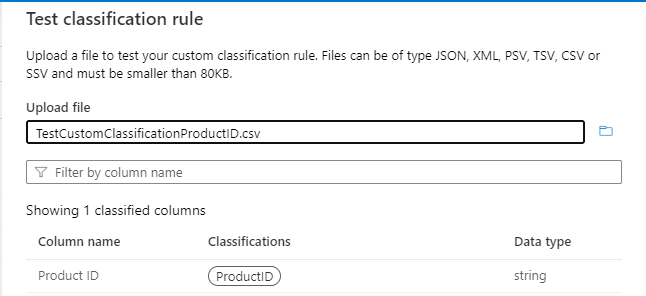
列パターンとデータ パターンを使用して、 Product ID 列のみが分類されるようにします。
注:
列パターンは、データ パターンを使用して AND 条件として検証されます。
分類ルールのテストとサンプル データのテストを使用して、分類ルールが期待どおりに動作していることを確認します。



複数の列パターンを使用する方法
同じ分類規則に分類する列パターンが複数ある場合は、パイプ (|) 文字区切りの列名を使用します。 たとえば、 列 Product ID、 Product_ID、 ProductID などについては、次の図に示すように列パターンを記述します。

詳細については、「 正規表現の alternation コンストラクト」を参照してください。
分類に関する考慮事項
分類を定義する際に留意すべき考慮事項を次に示します。
スキャンの前に資産に適用する必要がある分類を決定するには、分類の使用方法を検討してください。 不要な分類ラベルは、ノイズが多く、データコンシューマーにとって誤解を招く可能性があります。 分類を使用すると、次のことができます。
- スキャンされるデータ資産またはスキーマに存在するデータの性質について説明します。 言い換えると、分類は、顧客がカタログを検索する場合に、分類ラベルからデータ資産またはスキーマの内容を識別できるようにする必要があります。
- 優先順位を設定し、organizationのセキュリティとコンプライアンスのニーズを達成するための計画を策定します。
- データ準備プロセス (生ゾーン、ランディング ゾーンなど) のフェーズを説明し、特定の資産に分類を割り当てて、プロセスのフェーズをマークします。
スキャン ルールに関連する分類を含めることで、資産レベルまたは列レベルで分類を自動的に割り当てることも、メタデータをMicrosoft Purview データ マップに取り込んだ後に手動で割り当てることもできます。
自動割り当てについては、 Microsoft Purview ガバナンス ポータルでサポートされているデータ ストアに関するページを参照してください。
Microsoft Purview データ マップでデータ ソースをスキャンする前に、スキャン パフォーマンスに影響を与える可能性があるため、データを理解し、適切なスキャン ルール セット (たとえば、関連するシステム分類、カスタム分類、またはその両方の組み合わせを選択するなど) を構成することが重要です。 詳細については、 Microsoft Purview ガバナンス ポータルでサポートされている分類に関するページを参照してください。
Microsoft Purview スキャナーは、システム分類とカスタム分類の両方について、ディープ スキャン (分類の対象) にデータ サンプリング ルールを適用します。 サンプリング 規則は、データ ソースの種類に基づいています。 詳細については、「 Microsoft Purview でサポートされているデータ ソースとファイルの種類」の「ファイル内のサンプリング」セクションを参照してください。
注:
個別のデータしきい値: これは、スキャナーがデータ パターンを実行する前に列で検出する必要がある個別のデータ値の合計数です。 個別のデータしきい値はパターン マッチングとは関係ありませんが、パターン マッチングの前提条件です。 システム分類ルールでは、各列に少なくとも 8 つの個別の値が含まれる必要があります。 この値は、スキャナーが正確に分類するのに十分なデータが列に含まれていることを確認するために必要です。 たとえば、値 1 を含む複数の行を含む列は分類されません。 値を持つ行が 1 つ含まれており、残りの行に null 値がある列も分類されません。 複数のパターンを指定した場合、この値はそれぞれのパターンに適用されます。
サンプリング規則は、リソース セットにも適用されます。 詳細については、 Microsoft Purview ガバナンス ポータルでサポートされているデータ ソースとファイルの種類の「リソース セット ファイル サンプリング」セクションを参照してください。
カスタム分類ルールを使用して、ドキュメントタイプアセットにカスタム分類を適用することはできません。 このような型の分類は、手動でのみ適用できます。
カスタム分類は、既定のスキャン ルールには含まれません。 したがって、カスタム分類の自動割り当てが必要な場合は、カスタム分類を含むカスタム スキャン ルールをデプロイして使用してスキャンを実行する必要があります。
Microsoft Purview ガバナンス ポータルから分類を手動で適用した場合、このような分類は後続のスキャンで保持されます。
後続のスキャンでは、分類ルールが適用できない場合でも、以前に検出された場合、資産から分類は削除されません。
暗号化されたソース データ資産の場合、Microsoft Purview は、ファイル名、完全修飾名、構造化ファイルの種類のスキーマの詳細、およびデータベース テーブルのみを選択します。 分類を機能させるには、スキャンを実行する前に暗号化されたデータの暗号化を解除します。
次の手順
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示