AI/ML システムと依存関係の脅威のモデル化
著者: Andrew Marshall、Jugal Parikh、Emre Kiciman、Ram Shankar Siva Kumar
Raul Rojas と AETHER セキュリティ エンジニアリング ワークストリームに感謝します
2019年 11月
このドキュメントでは、AI と機械学習の領域に固有の脅威の一覧と軽減策に関する新しいガイダンスを提供することにより、AI 作業グループ向け AETHER エンジニアリング プラクティスを紹介し、既存の SDL 脅威モデル化手法を補完します。 これは、次のようなもののセキュリティ設計レビュー時に、リファレンスとして使用することを目的としています。
AI/ML ベースのサービスとやり取りする、または依存関係を持つ製品やサービス
AI/MLを中心に構築されている製品やサービス
従来のセキュリティ脅威の軽減策は、かつてないほど重要になっています。 セキュリティ開発ライフサイクルによって確立された要件は、本ガイダンスの基になる製品セキュリティ基盤を確立するうえで不可欠です。 従来のセキュリティ脅威に対処できない場合、ソフトウェアおよび物理ドメインの両方で、本ドキュメントに記載している AI/ML 固有の攻撃が可能になるだけでなく、単純な侵害がソフトウェア スタックの下位にまで及んでしまいます。 この領域の最も新しいセキュリティ上の脅威の概要については、Microsoft における AI および MLの未来の保護に関するページを参照してください。
通常、セキュリティ エンジニアとデータ サイエンティストのスキルセットは重複しません。 このガイダンスでは、セキュリティ エンジニアとデータ サイエンティストがそれぞれが持つ知識の範囲内で、これらの最新の脅威や軽減策について、構造化された対話を共有できるようにする方法を提供します。
このドキュメントは、次の2つのセクションに分かれています。
- 「脅威のモデル化における重要な新しい考慮事項」では、AI/ML システムの脅威をモデル化する際の新しい考え方と問うべき質問に焦点を当てています。 このセクションは脅威のモデル化について議論し、軽減策に優先順位を付ける際のプレイブックとなるため、データ サイエンティストとセキュリティ エンジニアはどちらも確認しておく必要があります。
- 「AI/ML 固有の脅威とその軽減策」では、特定の攻撃についての詳細と、これらの脅威から Microsoftの製品やサービスを保護するために現在使用されている具体的な軽減のステップについて説明します。 このセクションの主な対象は、脅威のモデル化やセキュリティ レビュー プロセスの成果としての具体的な脅威軽減策を実装する必要があるデータ サイエンティストです。
このガイダンスは、「機械学習の障害モード」において、Ram Shankar Siva Kumar、David O’Brien、Kendra Albert、Salome Viljoen、および Jeffrey Snover が作成した「敵対的な機械学習の脅威の分類法」を中心に構成されています。 このドキュメントで詳しく説明されているセキュリティ脅威の優先順位付けに関するインシデント管理のガイダンスについては、AI/ML 脅威の SDL Bug Barを参照してください。これらはすべて、脅威の状況に応じて時間の経過とともに進化する生きたドキュメントです。
脅威モデリングにおける主な新しい考慮事項: 信頼境界の表示方法の変更
トレーニングに使用するデータだけでなく、データ プロバイダーにおけるセキュリティ侵害やポイズニングを想定します。 異常かつ悪意のあるデータ エントリを検出し、それらを識別して回復できるようにする方法について説明します
まとめ
トレーニング データ ストアとそれらをホストするシステムは、脅威のモデル化のスコープに含まれます。 現時点での機械学習の最大のセキュリティ脅威はデータ ポイズニングです。トレーニング データのソースを、信頼または選別されていないパブリック データセットに依存していることと併せて、この分野では標準的な検出策と軽減策が欠如しているためです。 データの信頼性を確保し、"ゴミを入れるとゴミが出てくる" トレーニング サイクルを回避するには、データの来歴と系列を追跡することが不可欠です。
セキュリティ レビューで問うべき質問
データが侵害または改ざんされている場合は、どうすればわかりますか?
- トレーニング データの品質の歪みを検出するには、どのようなテレメトリを使用しますか?
ユーザー提供の入力でトレーニングを行っていますか?
- そのコンテンツに対して、どのような種類の入力検証やサニタイズを実行していますか?
- このデータの構造は、「データセット用のデータシート」のようにドキュメント化されていますか?
オンライン データ ストアを基にトレーニングを行う場合、モデルとデータ間の接続のセキュリティを確保するためにどのようなステップを実行していますか?
- フィードのコンシューマーに対する侵害を報告する手段は用意されていますか?
- その手段を実行できますか?
トレーニング データの機密性はどの程度ですか?
- カタログを作成したり、データ エントリの追加、更新、削除を制御したりしていますか?
モデルが機密データを出力することはありますか?
- このデータは、アクセス許可を使用してソースから取得されていますか?
モデルは、目標を達成するために必要な結果だけを出力しますか?
モデルからは、記録と複製が可能な生の信頼度スコアや、その他の直接的な出力が返されますか?
モデルの攻撃または反転によってトレーニング データが復旧されることで、どのような影響が出ますか?
モデル出力の信頼度レベルが突然低下した場合、その方法と理由、およびその原因となったデータを検出できますか?
モデルの整形式の入力を定義していますか? 入力がこの形式を満たしていることを確認するために何をしていますか? また、満たしていない場合はどうしていますか?
出力が不適切でもエラーが報告されない場合、どうすればそれがわかりますか?
トレーニング アルゴリズムが敵対的入力に対する回復性を数学的レベルで備えているかどうかを知っていますか?
トレーニング データの敵対的汚染からどのように回復しますか?
- 敵対的コンテンツを分離または検疫したり、影響を受けたモデルを再トレーニングしたりできますか?
- 再トレーニングのために以前のバージョンのモデルにロールバックしたり、以前のバージョンのモデルを復旧したりできますか?
選別されていない公開コンテンツに対して強化学習を使用していますか?
データの系列について考えてください - 問題が見つかった場合、そのデータがデータセットに取り込まれた時点まで追跡できますか? できない場合、それは問題となりますか?
異常がどのようなものであるかを理解できるように、トレーニング データの取得元を確認し、統計的標準値を特定できますか?
- トレーニング データのどの要素が外部からの影響に対して脆弱ですか?
- トレーニングに使用するデータ セットにデータを提供しているのはだれですか?
- 競合他社に損害を与えるために、あなたならトレーニング データのソースをどのように攻撃しますか?
このドキュメントの関連する脅威と軽減策
敵対的摂動 (すべてのバリエーション)
データのポイズニング (すべてのバリエーション)
攻撃の例
害のないメールを強制的にスパムとして分類したり、敵対的なサンプルが検出されないようにしたりする
特に重要度の高いシナリオで、攻撃者が入力を巧妙に操作して、適切な分類の信頼度レベルを下げる
攻撃者が分類済みソース データにランダムにノイズを挿入することで、今後適切な分類が使用される可能性を低減し、モデルの機能を事実上低下させる
トレーニング データを汚染することで優良なデータ ポイントの分類を誤らせ、システムが具体的な措置を取らざるを得なくさせたり、特定のアクションを見送らざるを得なくさせる
使用しているモデルまたは製品やサービスによって実行され、オンラインまたは物理ドメインの顧客に害が及ぶ可能性がある行為を識別する
まとめ
軽減せずに放置した場合、AI/ML システムに対する攻撃によって、物理的な領域にまで被害が及ぶ可能性があります。 ユーザーに心理的または物理的な被害を与えるために歪められる可能性のあるシナリオはどれも、製品やサービスにとって重大なリスクとなります。 これは、トレーニングに使用される顧客の機密データやこれらのプライベート データ ポイントを漏えいする可能性のある設計上の選択にまで及びます。
セキュリティ レビューで問うべき質問
敵対的なサンプルを使用してトレーニングを行いますか? それは物理ドメインでのモデル出力にどのように影響しますか?
製品やサービスに対する荒しの外観はどのようなものですか? どのようにすればそれを検出して対応できますか?
提供しているサービスを騙して正当なユーザーへのアクセスを拒否させるような結果をモデルが返すようにするには何が必要ですか?
モデルがコピーまたは盗用されると、どのような影響がありますか?
モデルを使用して、特定のグループ内または単にトレーニング データ内の個々の人物のメンバーシップを推論することができますか?
攻撃者は、製品に特定のアクションを強制的に実行させることによって、評判に傷をつけたり、PR への反感を引き起こすことができますか?
適切に書式設定されているが、明らかに偏りのある (荒しなどの) データをどのように処理しますか?
モデルと対話する方法、つまりモデルにクエリを実行する方法が露呈した場合、その方法を問い合わせを行ってトレーニング データやモデルの機能を漏えいさせることは可能ですか?
このドキュメントの関連する脅威と軽減策
メンバーシップ推論
モデル移転
モデルの盗用
攻撃の例
モデルに対して繰り返しクエリを実行し、最大限に信頼度の高い結果を取得することで、トレーニング データの再構築と抽出を行う
クエリと応答を徹底的に照合することにより、モデル自体を複製する
モデルにクエリを実行するとプライベート データの特定の要素が遺漏するような操作をトレーニング セットに含める
停止の標識や交通信号を無視するように自己運転車を騙す
温和なユーザーに対して荒し行為をするように会話ボットを操作する
AI/MLのすべてのソースの依存関係と、データまたはモデルのサプライ チェーンのフロントエンド プレゼンテーション層を特定する
まとめ
AI と機械学習における多くの攻撃は、モデルへのクエリ アクセスを提供するために公開されている API への正当なアクセスから始まります。 豊富なデータ ソースと豊富なユーザー エクスペリエンスはこの点と関連するため、認証されてはいるが "不適切な" (ここにグレー ゾーンが存在します) サード パーティによるモデルへのアクセスはリスクとなります。これは、彼らが Microsoftの提供するサービスより上のプレゼンテーション層として活動することができるからです。
セキュリティ レビューで問うべき質問
モデルまたはサービスの API にアクセスするために認証されているのは、どの顧客やパートナーですか?
- 彼らはサービス上でプレゼンテーション層として活動することができますか?
- 侵害が発生した場合に直ちにアクセスを取り消すことができますか?
- サービスまたは依存関係が悪用された場合の復旧戦略はどのようなものですか?
サード パーティが、モデルのファサードを構築して悪用し、Microsoft またはその顧客に害を及ぼすことができますか?
顧客はあなたに直接トレーニング データを提供しますか?
- どのようにそのデータをセキュリティで保護しますか?
- そのデータに悪意があり、サービスがターゲットである場合はどうなりますか?
この場合の偽陽性とはどのようなものですか? 偽陰性の影響はどのようなものですか?
複数のモデル間の真陽性と偽陽性の比率の偏差を追跡して測定できますか?
モデル出力の信頼性を顧客に証明するために、どのような種類のテレメトリが必要ですか?
ML またはトレーニング データ サプライ チェーン (オープン ソース ソフトウェアだけでなく、データ プロバイダーも含む) におけるサード パーティの依存関係をすべて特定します
- サード パーティを使用する理由は何ですか? また、その信頼性はどのように確認しますか?
サード パーティの事前構築済みモデルを使用していますか? また、サード パーティの MLaaS プロバイダーにトレーニング データを提出していますか?
類似の製品やサービスに対する攻撃に関するニュース記事の一覧表を作成します。 多くの AI/MLの脅威はモデルの種類間で転移することを理解したうえで、これらの攻撃がご自身の製品に与える影響はどのようなものですか?
このドキュメントの関連する脅威と軽減策
ニューラル ネットワークの再プログラミング
物理ドメインにおける敵対的な例
悪意ある ML プロバイダーによるトレーニング データの復旧
ML サプライ チェーンへの攻撃
モデルに対するバックドア攻撃
ML 固有の依存関係の侵害
攻撃の例
悪意のある MLaaS プロバイダーが特定のバイパスを使用してモデルにトロイの木馬を仕掛ける
敵対者な顧客が、使用中の一般的な OSS 依存関係の脆弱性を見つけ、作成したトレーニング データ ペイロードをアップロードしてサービスを侵害する
悪質なパートナーが顔認識 APIを使用し、サービス上でプレゼンテーション層を作成してディープ フェイクを生成する。
AI/ML 固有の脅威とその軽減策
#1: 敵対的摂動
説明
摂動スタイルの攻撃では、攻撃者は、密かにクエリを変更して、運用環境に配置されているモデルから目的の応答を引き出します [1]。 これはモデルの入力の整合性を侵害するため、ファジー スタイルの攻撃につながります。最終的な結果は必ずしもアクセス違反または EOP というわけではありませんが、代わりにモデルの分類のパフォーマンスを低下させます。 また、これは、AI が禁止するような方法で特定のターゲット単語を使用した荒し行為として現れることもあります。これにより、"禁止されている" 単語に一致する名前を持つ正当なユーザーが事実上サービスから拒否されてしまいます。
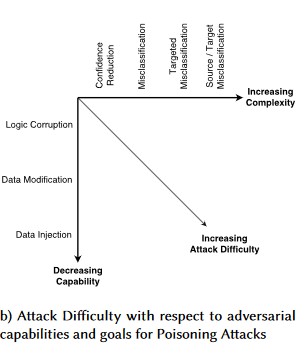 [24]
[24]
バリアント #1a: 対象の誤分類
この場合、攻撃者は、対象となる分類子の入力クラスに含まれないが、その特定の入力クラスとしてモデルによって分類されているサンプルを生成します。 敵対的サンプルは人間の目にはランダムなノイズのように見えますが、攻撃者は、標的となる機械学習システムについての知識を持っているため、ランダムではなく、対象モデルの特定の側面を悪用するホワイト ノイズを生成することができます。 敵対者が正当ではない入力サンプルを提供しても、ターゲット システムはこれを正当なクラスとして分類します。
例
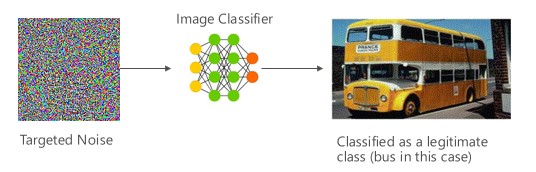 [6]
[6]
軽減策
敵対的トレーニングによって誘発されたモデル信頼性を使用した敵対的堅牢性の強化 [19]: 著者らは、基本モデルの敵対的堅牢性を強化するために、信頼度情報と最近傍検索を組み合わせたフレームワークである高信頼近傍 (HCNN)を提案しています。 これは、基になるトレーニング分布からサンプリングされたポイントの近隣部分で、適切なモデル予測と間違ったモデル予測を識別するのに役立ちます。
アトリビューション主導の因果分析 [20]: 著者らは、敵対的な摂動に対する回復力と、機械学習モデルによって生成された個々の決定のアトリビューションに基づく説明との関係を研究しています。 彼らは、敵対的入力が属性空間では堅牢ではないことを報告しています。つまり、いくつかの特徴を高い属性でマスキングすると、敵対的サンプルに対する機械学習モデルの優柔不断さが変化します。 対照的に、自然な入力は属性空間において堅牢です。
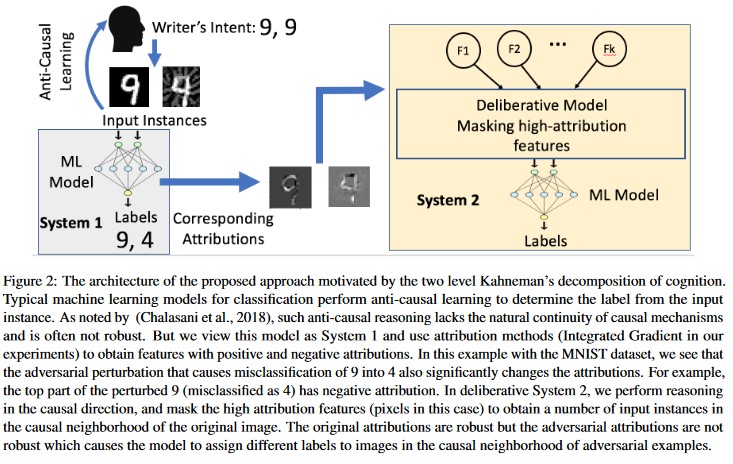 [20]
[20]
これらのアプローチでは、悪意のある攻撃に対する機械学習モデルの回復力を強化できます。これは、この2層の認識システムを欺くには、元のモデルを攻撃するだけでなく、敵対的なサンプルに対して生成される属性と元のサンプルの類似性を確保する必要もあるからです。 悪意のある攻撃を成功させるには、両方のシステムを同時に侵害する必要があります。
同時に行われることが多い攻撃
攻撃者がモデルを制御できるようになった後の、リモートからの特権の昇格
重要度
重大
バリエーション #1b: ソース/ターゲットの誤分類
これは、特定の入力に対して目的のラベルを返すようにモデルを操作しようとする攻撃者の試みとして特徴付けられます。 通常、これによってモデルからは擬陽性または偽陰性が返されます。 最終的にモデルの分類精度がわずかに乗っ取られるため、攻撃者は自由に特定のバイパスを誘導することができます。
この攻撃は分類の精度に大きな悪影響を与えますが、攻撃者は正しくラベル付けされないようにソース データを操作するだけではなく、目的とする不正なラベルで明確にラベル付けする必要もあるため、実行には非常に時間がかかります。 多くの場合、これらの攻撃では複数のステップや試行を使用して、誤分類を強制します [3]。 モデルが標的型誤分類を強制する転移学習攻撃を受けやすい場合、攻撃の調査はオフラインでしか実行できないため、攻撃者の識別可能なトラフィックの痕跡が見つからない可能性があります。
例
害のないメールを強制的にスパムとして分類したり、敵対的なサンプルが検出されないようにしたりします。 これらは、モデル回避攻撃やモデル擬態攻撃とも呼ばれます。
軽減策
事後対応型または防御型検出アクション
- 分類の結果を提供する API への呼び出し間に最小時間しきい値を実装します。 これにより、成功摂動を見つけるために必要な全体的な時間を増やすことで、複数のステップから成る攻撃テストの速度を鈍化させます。
事前対応型または保護アクション
敵対的堅牢性を向上させるための機能ノイズ除去 [22]: 著者らは、機能ノイズ除去を実行することで敵対的堅牢性を向上させる新しいネットワーク アーキテクチャを開発しています。 具体的には、このネットワークには、非ローカルの手段またはその他のフィルターを使用して特徴からノイズを除去するブロックが含まれています。これにより、ネットワーク全体がエンド ツー エンドでトレーニングされます。 特徴からノイズを除去したネットワークを対敵トレーニングと組み合わせることで、ホワイトボックスとブラックボックスの両方の攻撃設定において、最新の対敵堅牢性が大幅に向上します。
敵対的なトレーニングと正則化: 既知の敵対的なサンプルを使用してトレーニングし、悪意のある入力に対する回復力と堅牢性を構築します。 これは正則化の一形式と考えることもできます。正則化では、入力勾配のノルムの大きさにペナルティーを科し、分類子の予測機能をより滑らかにします (入力限界を増やします)。 これには、低信頼度を使用した正しい分類が含まれます。
単調な特徴を選択することによる、単調な分類の開発に投資します。 これにより、敵対者は、負のクラスから特徴を埋め込むだけでは分類子を回避できなくなります [13]。
特徴の絞り出し [18]を使用すると、敵対的なサンプルを検出することで DNN モデルを強化できます。 これにより、元の空間のさまざまな特徴ベクトルに対応するサンプルを単一のサンプルに融合することで、敵対者が使用できる検索領域を減らします。 元の入力に対する DNN モデルの予測と、絞り出された入力に対する予測を比較することによって、特徴の絞り出しが敵対的なサンプルの検出に役立ちます。 元のサンプルと絞り出されたサンプルでモデルから生成される出力が大幅に異なる場合は、入力が敵対的である可能性があります。 システムは予測間の不一致を測定し、しきい値を選択することによって、正当なサンプルに対する正しい予測を出力し、敵対的入力を拒否することができます。

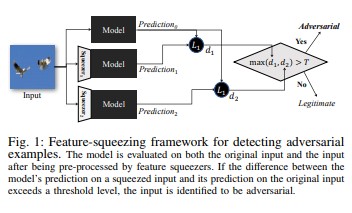 [18]
[18]敵対的な例に対する認証済みの防御 [22]: 著者らは、特定のネットワークとテスト入力に対して、いかなる攻撃もエラーを特定の値を超えることを強制できないという証明書を出力する、半明確な緩和に基づく方法を提案しています。 次に、この証明書は弁別可能であるため、筆者たちは合同でネットワーク パラメーターを使用して最適化を行い、すべての攻撃に対する堅牢性を促進するアダプティブな正則化を提供しています。
対応アクション
- 分類子の間の不一致が大きい (特に1人のユーザーまたは少数ユーザーのグループについて不一致が大きい) 分類結果に対してアラートを発行します。
同時に行われることが多い攻撃
リモートからの特権の昇格
重要度
重大
バリアント #1c: ランダムな誤分類
これは、攻撃者が正当なソース分類以外のあらゆる分類をターゲットにできる特殊なバリエーションです。 一般的に、攻撃者は分類済みソース データにランダムにノイズを挿入することで、今後適切な分類が使用される可能性を低下させます [3]。
例
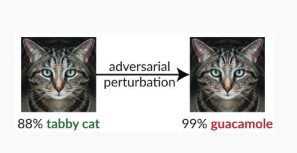
軽減策
バリアント 1a と同じです。
同時に行われることが多い攻撃
非永続的なサービス拒否
重要度
重要
バリアント #1d: 信頼度の低下
特に重要度の高いシナリオで、攻撃者が入力を巧妙に操作して、適切な分類の信頼度レベルを下げます。 また、これは、正当なアラートと区別できない不正なアラートによって管理者や監視システムを圧倒することを意図した、膨大な数の偽陽性という形を取ることもあります [3]。
例

軽減策
- バリアント #1a で説明されているアクションに加え、イベント調整を使用して1つのソースからのアラートの量を減らすことができます。
同時に行われることが多い攻撃
非永続的なサービス拒否
重要度
重要
#2a 標的型データ ポイズニング
説明
攻撃者の目標は、トレーニング フェーズで生成されたマシン モデルを汚染し、テスト フェーズにおいて新しいデータに基づく予測を改変することです [1]。 標的型ポイズニング攻撃では、攻撃者の目的は特定のサンプルの分類を誤らせ、特定のアクションを誘発したり、特定のアクションを怠らせたりします。
例
AV ソフトウェアをマルウェアとして送信して、誤分類を悪意のあるものとして強制し、クライアント システムで対象の AV ソフトウェアを使用できないようにします。
軽減策
異常センサーを定義して、データ分布を毎日確認し、バリエーションが見つかったらアラートを表示します
- トレーニング データのバリエーションを毎日測定し、非対称や誤差のテレメトリを確認します
入力の検証 (サニタイズと整合性チェックの両方)
ポイズニングによって、範囲外のトレーニング サンプルが挿入されます。 この脅威に反撃するには、主に次の2つの戦略があります。
- データのサニタイズおよび検証: トレーニング データからのポイズニング サンプルの削除 - バギングを使用したポイズニング攻撃への反撃 [14]
- 否定的影響に対する拒否 (RONI) による防御 [15]
-堅牢な学習: 汚染サンプルの存在下でも堅牢な学習アルゴリズムを選択します。
- そのようなアプローチの1つが [21] で説明されており、著者らは2つのステップでデータ ポイズニングの問題に取り組んでいます: 1) 真の部分空間を回復するための新しいロバストな行列因数分解手法の導入、2) ベースで敵対的なインスタンスを除去するための新しいロバストな主成分回帰 ステップ (1) で回復されたベースに基づいて。 彼らは、真のサブ空間を正常に復旧するために必要十分な条件を特徴付け、グラウンド トゥルースと比較した場合に予期される予測損失の境界を示しています。
同時に行われることが多い攻撃
トロイの木馬を忍ばせることで、攻撃者が長期間ネットワーク上に存在します。 トレーニング データまたは構成データが侵害され、モデルを作成する際に取り込まれたり、信頼されたりします。
重要度
重大
#2b 無差別のデータ ポイズニング
説明
目標は、攻撃対象のデータ セットの品質または整合性を損なうことです。 多くのデータセットは公開されており、信頼されておらず、選別もされていないため、この攻撃によって、まずこのようなデータ整合性違反を特定する能力に関する懸念が増大します。 気付かないうちに侵害されたデータを使用してトレーニングを行うことは、"ゴミを入れるとゴミが出てくる" 状況となります。 検出された場合、トリアージによって、侵害されてるデータの範囲を確定し、検疫および再トレーニングする必要があります。
例
ある企業はモデルをトレーニングするために、信頼できる有名 Web サイトで原油の先物データを収集しています。 そのデータ プロバイダーの Web サイトが、その後 SQL インジェクション攻撃によって侵害されます。 攻撃者はデータセットを自由に汚染することができ、トレーニングされるモデルにはデータが汚染されている兆候は見えません。
軽減策
バリアント 2a と同じです。
同時に行われることが多い攻撃
高価値資産に対する認証済みのサービス拒否攻撃
重要度
重要
#3 モデル反転攻撃
説明
機械学習モデルで使用されるプライベートな特徴を復元することができます [1]。 これには、攻撃者がアクセスできないプライベートなトレーニング データの再構築が含まれます。 生体認証コミュニティでは、ヒル クライム攻撃とも呼ばれています [16、17]。これは、返される信頼度レベルを最大化する入力を見つけることで達成されますが、ターゲットに一致する分類によって左右されます [4]。
例
 [4]
[4]
軽減策
機密データでトレーニングされたモデルへのインターフェイスには、強力なアクセス制御が必要です。
モデルで許可されるクエリ数を制限します
提示されたすべてのクエリに対して入力の検証を実行し、ユーザーまたは呼び出し元と実際のモデルとの間にゲートを実装します。これにより、モデルの入力の正しさの定義に合致しないクエリをすべて拒否し、有用であるために必要な最小限の情報のみを返すようにします。
同時に行われることが多い攻撃
標的型攻撃、隠れた情報漏えい
重要度
標準の SDL バグ バーに従えば既定で "重要" ですが、機密データや個人を特定できるデータが抽出される場合は、"クリティカル" になります。
#4 メンバーシップ推論攻撃
説明
攻撃者は、特定のデータ レコードがそのモデルのトレーニング データセットに含まれていたかどうかを判別できます [1]。 研究者は、属性 (年齢、性別、病院など) に基づいて、患者のメイン手順 (例: 患者が通過した手術)を予測することができました [1]。
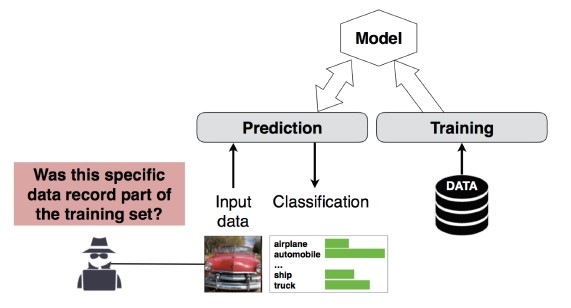 [12]
[12]
軽減策
この攻撃の実行可能性を論証する研究論文では、差分プライバシー [4、9] が効果的な軽減策であることが示されています。 これは Microsoft にとって新たな分野であるため、AETHER セキュリティ エンジニアリングではこの領域の研究に投資を行い専門知識を高めることを推奨しています。 この研究では、差分プライバシーの機能を列挙し、その軽減策としての実際的な有効性を評価した後、(Visual Studio でコードをコンパイルすると、開発者とユーザーには透過的にセキュリティが既定で有効になるのと同じように)、これらの防御がオンライン サービス プラットフォームで透過的に継承されるように設計する必要があります。
ニューロン ドロップアウトとモデル スタッキングを使用することで、ある程度は効果的に軽減することができます。 ニューロン ドロップアウトを使用すると、この攻撃に対するニューラル ネットワークの回復力が向上するだけでなく、モデルのパフォーマンスを向上させることもできます [4]。
同時に行われることが多い攻撃
データのプライバシー。 トレーニング セットにデータ ポイントが含まれるかどうかについての推論は行われますが、トレーニング データ自体が漏えいすることはありません
重要度
これはプライバシーの問題であり、セキュリティ上の問題ではありません。 この問題については脅威のモデル化のガイダンスで取り上げられています。領域は重なっていますが、ガイダンスではセキュリティではなくプライバシーの観点から回答が行われています。
#5 モデルの盗用
説明
攻撃者は、モデルに対して正当なクエリを実行することで、基になるモデルを再作成します。 新しいモデルの機能は、基になるモデルの機能と同じになります [1]。 モデルを再作成すると、逆に特徴情報を復旧したり、トレーニング データに対して推論を行ったりすることができるようになります。
式を解く - API 出力を使用してクラスの確率を返すモデルの場合、攻撃者はモデル内の不明な変数を特定するクエリを作成できます。
パスを見つける - APIの特殊性を悪用して、入力を分類する際にツリーによって取得された "決定"を抽出する攻撃 [7]。
転移可能性攻撃 - 敵対者は、標的のモデルに予測クエリを発行することで、ローカル モデルをトレーニングし、そのモデルを使用して標的のモデルに転送する敵対的サンプルを作成することができます [8]。 モデルが抽出され、敵対的入力のタイプの攻撃に対して脆弱であることが判明した場合、モデルのコピーを抽出した攻撃者は、実稼働環境に配置されているモデルに対する新しい攻撃を完全にオフラインの状態で開発できます。
例
スパムの識別、マルウェアの分類、ネットワークの異常検出など、敵対的動作を検出するために ML モデルを役立たせる設定では、モデルを抽出することによってこれらを回避する攻撃が容易になります [7]。
軽減策
事前対応型または保護アクション
予測 API で返される詳細情報を最小限に抑えたり難読化したりしながらも、その有用性を"誠実な" アプリケーションと言えるレベルに維持します [7]。
モデル入力に対して整形式のクエリを定義し、その形式に一致する完全に整形式の入力にのみ応答する結果を返します。
丸められた信頼度値を返します。 大部分の正当な呼び出し元には、小数第2位以上の精度は不要です。
同時に行われることが多い攻撃
価値の高い情報の漏えいを目的とした、システム データに対する認証されていない読み取り専用の改ざん。
重要度
セキュリティが重視されるモデルでは "重要"、それ以外の場合は "中程度"
#6 ニューラル ネットワークの再プログラミング
説明
敵対者によって特別に作成されたクエリを使用することで、機械学習システムを作成者の本来の目的から逸脱したタスクに再プログラミングできます [1]。
例
顔認識 APIのアクセス制御が脆弱な場合、サード パーティが Microsoftの顧客に害を与えるように設計されたアプリ (ディープ フェイク ジェネレーターなど) に組み込むことができます。
軽減策
強力なクライアント</>サーバー相互認証とモデル インターフェイスへのアクセス制御
問題のあるアカウントを停止します。
APIのサービス レベル アグリーメントを特定して適用します。 報告された問題の修正に許容できる時間を決定し、SLAの有効期限が切れた時点で問題が再現されないことを確認します。
同時に行われることが多い攻撃
これは不正使用のシナリオです。 違反者のアカウントを無効にするだけで、セキュリティ インシデントが発生する可能性は低くなります。
重要度
"重要" から "クリティカル"
#7 物理ドメインにおける敵対的サンプル (ビット - >アトム)
説明
敵対的サンプルとは、機械学習システムをミスリードするという唯一の目的で、悪意のあるエンティティから送信された入力やクエリのことです [1]
例
これらのサンプルは、物理ドメインで発生する可能性があります。たとえば、特定の色の信号灯 (敵対的入力) が一時停止の標識で点灯しており、画像認識システムが停止標識を停止標識として認識できなくなっているため、自己運転車が騙されて停止の標識を無視して走行する場合が考えられます。
同時に行われることが多い攻撃
特権の昇格、リモートでのコード実行
軽減策
これらの攻撃は、機械学習レイヤー (AI 駆動型の意思決定の下にあるデータ & アルゴリズム レイヤー) の問題が軽減されなかったために発生します。 他のソフトウェア *または* 物理システムと同様に、標的の下にあるレイヤーは、常に従来のベクトルを通じて攻撃を受ける可能性があります。 このため、従来のセキュリティ プラクティスはかつてないほど重要になっています。特に、脆弱性が軽減されていないレイヤー (データまたはアルゴリズム レイヤー) が、AI と従来のソフトウェアの間で使用されている場合は重要です。
重要度
重大
#8 トレーニング データを復旧できる悪意のある ML プロバイダー
説明
悪意のあるプロバイダーがバックドア アルゴリズムを提供し、そこから非公開のトレーニング データが再生されます。 モデルの指定のみで顔とテキストを再構築できました。
同時に行われることが多い攻撃
標的型情報漏えい
軽減策
この攻撃の実行可能性を論証する研究論文では、準同型暗号化が効果的な軽減策であることが示されています。 これは現在 Microsoft ではほとんど投資が行われていない分野であるため、AETHER セキュリティ エンジニアリングではこの領域の研究に投資を行い専門知識を高めることを推奨しています。 この研究では、準同型暗号化の原則を列挙し、悪意のある "サービスとしての ML" プロバイダーに対する軽減策として、それらが実際にどの程度有効であるかを評価する必要があります。
重要度
データが PIIの場合は "重要"、それ以外の場合は "中程度"
#9 ML サプライ チェーンへの攻撃
説明
アルゴリズムのトレーニングには大規模なリソース (データ + 計算) が必要となるため、現在の慣行では、大企業によってトレーニングされたモデルを再利用し、当面のタスクに合わせてわずかに変更します (例: ResNet は Microsoftの人気のある画像認識モデルです)。 これらのモデルは、Model Zoo によって厳選されたものです (Caffe は人気の画像認識モデルをホストしています)。 この攻撃では、敵対者は Caffe でホストされているモデルを攻撃することで、だれもが利用する "井戸"を毒しています。 [1]
同時に行われることが多い攻撃
サード パーティが提供する、セキュリティ関連以外の依存関係が侵害される
知らないうちにアプリ ストアがマルウェアをホストしている
軽減策
モデルとデータについては、サード パーティとの依存関係を可能な限り最小限に抑えます。
これらの依存関係を脅威のモデル化のプロセスに組み込みます。
ファースト パーティ システムとサード パーティシ ステムの間で、強力な認証、アクセス制御、暗号化を活用します。
重要度
重大
#10 バックドア機械学習
説明
トレーニング データを改ざんし、トロイの木馬モデルを供給する悪意のあるサード パーティにトレーニング プロセスが外注されます。このモデルは、特定のウイルスを悪意のないものとして分類するなど、対象に誤分類を強制します [1]。 これは、"サービスとしての ML" によるモデル生成シナリオにおけるリスクです。
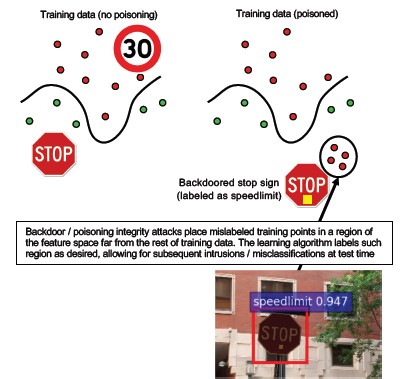 [12]
[12]
同時に行われることが多い攻撃
サード パーティが提供する、セキュリティ関連の依存関係が侵害される
ソフトウェア更新メカニズムの侵害
証明機関の侵害
軽減策
事後対応型または防御型検出アクション
- この脅威が発見された時点で、既に被害が及んでいます。そのため、悪意のあるプロバイダーによって提供されるモデルとトレーニング データを信頼することはできません。
事前対応型または保護アクション
機密性の高いモデルはすべて社内でトレーニングする
トレーニング データをカタログにする、またはトレーニング データが強力なセキュリティ プラクティスを備えた信頼できるサード パーティから提供されていることを確認する
MLaaS プロバイダーと自身のシステムの間のやり取りにおける脅威をモデル化する
対応アクション
- 外部依存関係の侵害の場合と同じ
重要度
重大
#11 ML システムのソフトウェアの依存関係の悪用
説明
この攻撃では、攻撃者はアルゴリズムの操作は行いません。 代わりに、バッファー オーバーフローやクロスサイト スクリプティングなどのソフトウェアの脆弱性を悪用します [1]。 AI/MLの下にあるソフトウェア レイヤーを侵害するのは、学習レイヤーを直接攻撃するよりも容易です。したがって、セキュリティ開発ライフサイクルで詳細に説明されている従来のセキュリティ脅威軽減策がきわめて重要です。
同時に行われることが多い攻撃
オープンソース ソフトウェアの依存関係の侵害
Web サーバーの脆弱性 (XSS、CSRF、APIの入力検証エラー)
軽減策
セキュリティ チームと協力して、セキュリティ開発ライフサイクルや運用セキュリティ アシュアランスで適用可能なベスト プラクティスに従います。
重要度
従来のソフトウェアの脆弱性の種類によってさまざまに異なります。
Bibliography
[1] 機械学習の障害モード、Ram Shankar Siva Kumar、David O'Brien、Kendra Albert、Salome Viljoen、Jeffrey Snover、https://video2.skills-academy.com/security/failure-modes-in-machine-learning
[2] AETHER セキュリティ エンジニアリング ワークストリーム、「Data Provenance/Lineage (データの来歴と系列)」、v チーム
[3] 深部ラーニングにおける敵対的な例:特性評価と相違、Weiら、https://arxiv.org/pdf/1807.00051.pdf
[4] ML-Leaks: 機械学習モデルに対するモデルとデータに依存しないメンバーシップ推論の攻撃と防御、Salem ら、https://arxiv.org/pdf/1806.01246v2.pdf
[5] M. Fredrikson、S. Jha、T. Ristenpart、「Model Inversion Attacks that Exploit Confidence Information and Basic Countermeasures (信用情報を悪用したモデル反転攻撃と基本的対抗手段)」。コンピューターと通信のセキュリティ (CCS) に関する 2015年の ACM SIGSAC カンファレンスの議事録より。
[6] Nicolas Pagenot、Patrick McDaniel、「Adversarial Examples in Machine Learning (機械学習における敵対的サンプル)」、AIWTB 2017
[7] 「Stealing Machine Learning Models via Prediction APIs (予測 APIを介した機械学習モデルの盗用)」、Florian Tramèr (スイス連邦工科大学ローザンヌ校 (EPFL))、Fan Zhang (コーネル大学)、Ari Juels (コーネル テック)、Michael K. Reiter (ノースカロライナ大学チャペルヒル校)、Thomas Ristenpart (コーネル テック)
[8] 「The Space of Transferable Adversarial Examples (転送可能な敵対的サンプルの領域)」、Florian Tramèr、Nicolas Papernot、Ian Goodfellow、Dan Boneh、Patrick McDaniel
[9] 「Understanding Membership Inferences on Well-Generalized Learning Models (適切に生成された学習モデルでのメンバーシップの推論について)」、Yunhui Long 1、Vincent Bindschaedler 1、Lei Wang 2、Diyue Bu 2、Xiaofeng Wang 2、Haixu Tang 2、Carl A. Gunter 1、Kai Chen 3、4
[10] Simon-Gabriel 他、「Adversarial vulnerability of neural networks increases with input dimension (ニューラルネット ワークの敵対的脆弱性は入力ディメンションが増えると共に増える)」、ArXiv 2018
[11] Lyu 他、「A unified gradient regularization family for adversarial examples (敵対的サンプルの統一された勾配正則化ファミリ)」、ICDM 2015
[12] ワイルド パターン: 敵対的機械学習の台頭から 10年 - NeCS 2019 Battista Biggioa、Fabio Roli
[13] 「Adversarially Robust Malware Detection Using Monotonic Classification (単調な分類を使用した、対敵堅牢性を備えたマルウェア検出機能)」、Inigo Incer 他。
[14] Battista Biggio、Igino Corona、Giorgio Fumera、Giorgio Giacinto、Fabio Roli。 「Bagging Classifiers for Fighting Poisoning Attacks in Adversarial Classification Tasks (分類子のバギングによる、敵対的分類タスクでのポイズニング攻撃への反撃)」
[15] ネガティブインパクト防御に対する改善された拒絶 Hongjiang Li and Patrick P.K. Chan
[16] Adler、 「Vulnerabilities in biometric encryption systems (生体暗号化システムの脆弱性)」。 第5回国際会議。 AVBPA、2005
[17] Galbally、McCool、Fierrez、Marcel、Ortega-Garcia、 「On the vulnerability of face verification systems to hill-climbing attacks (ヒルクライム攻撃に対する顔検証システムの脆弱性)」。 Patt. Rec、2010
[18] Weilin Xu、David Evans、Yanjun Qi。 特徴圧縮: ディープ ニューラル ネットワークにおける敵対的な例の検出。 2018年開催のネットワークおよび分散システムのセキュリティに関するシンポジウム。 2月18日から 21日。
[19] 「Reinforcing Adversarial Robustness using Model Confidence Induced by Adversarial Training (対敵トレーニングによって誘導されるモデルの信頼度を使用した対敵堅牢性の補強)」、Xi Wu、Uyeong Jang、Jiefeng Chen、Lingjiao Chen、Somesh Jha
[20] 「Attribution-driven Causal Analysis for Detection of Adversarial Examples (敵対的サンプルを検出するための属性駆動型の原因分析)」、Susmit Jha、Sunny Raj、Steven Fernandes、Sumit Kumar Jha、Somesh Jha、Gunjan Verma、Brian Jalaian、Ananthram Swami
[21] 「Robust Linear Regression Against Training Data Poisoning (トレーニング データのポイズニングに対する堅牢な線形回帰)」、Chang Liu 他。
[22] 「Feature Denoising for Improving Adversarial Robustness (特徴のノイズ除去による対敵堅牢性の向上)」、Cihang Xie、Yuxin Wu、Laurens van der Maaten、Alan Yuille、Kaiming He
[23] 「Certified Defenses against Adversarial Examples (敵対的サンプルに対する認定された防御)」、Aditi Raghunathan、Jacob Steinhardt、Percy Liang