Azure での SharePoint イントラネット ファームのフェーズ 5:可用性グループを作成して SharePoint データベースに追加する
適用対象:
 2016 2019 Subscription Edition SharePoint in Microsoft 365
2016 2019 Subscription Edition SharePoint in Microsoft 365
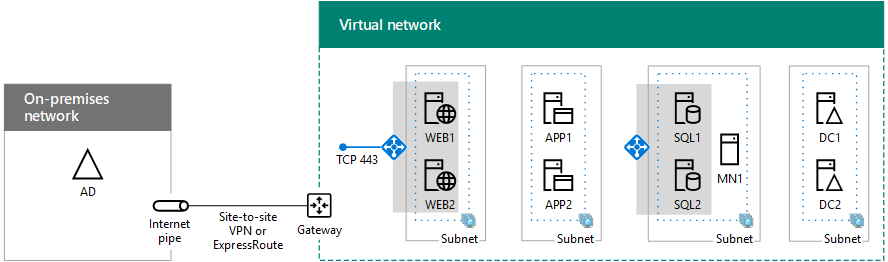
Azure インフラストラクチャ サービスにイントラネット専用の SharePoint Server 2016 ファームをデプロイするこの最終フェーズでは、SharePoint ファームのデータベースを使用して新しい SQL Server Always On 可用性グループを作成し、可用性グループ リスナーを作成し、SharePoint ファームの構成を完了します。
すべてのフェーズについては、「 Azure での SQL Server Always On 可用性グループを使用した SharePoint Server のデプロイ 」を参照してください。
可用性グループを構成する
SharePoint では、初期構成の一環として 2 つのデータベースが作成されます。 これらのデータベースは、次に示す手順で準備する必要があります。
データベースの復旧モデルは「完全」に設定する必要があります。
プライマリ マシンでデータベースの完全バックアップとトランザクション ログ バックアップを作成します。 バックアップ マシンで完全バックアップとログ バックアップを復元します。
データベースのバックアップと復元が完了したら、それらを可用性グループに追加します。 SQL Server は、バックアップを 1 回以上作成して、別のマシンに復元したデータベースのみをグループに追加することを許可します。
次に示す手順で、セカンダリの SQL Server 仮想マシンからバックアップ ファイル (.bak) にアクセスできるようにします。
<ドメイン>\sp_farm_db アカウント資格情報を使用してプライマリ SQL Server 仮想マシンに接続します。
[エクスプローラー] を開いて、 [H:] ディスクに移動します。
[バックアップ] フォルダーを右クリックして、 [共有相手]、 [特定のユーザー] の順にクリックします。
[ ファイル共有 ] ダイアログで、「 <ドメイン名>\sqlservice」と入力し、[ 追加] をクリックします。
sqlservice アカウントの [アクセス許可レベル] 列をクリックして、 [読み取り/書き込み] をクリックします。
[共有] をクリックして、 [完了] をクリックします。
セカンダリの SQL Server ホストにも、前述の手順を実行します。ただし、手順 5 では、 sqlservice アカウントに [H:\バックアップ] フォルダーの [読み取り] アクセス許可を付与します。
可用性グループに追加したデータベースごとに、次に示す手順を実行します。
プライマリの SQL Server 仮想マシンで、 [スタート] をクリックして、「 SQL Studio」と入力し、 [SQL Server Management Studio] をクリックします。
[ 接続] をクリックします。
左側のウィンドウで、 [データベース] ノードを展開します。
データベースを右クリックして、プロパティを選択します。
左側のナビゲーションから、 [オプション] 項目を選択します。
[復旧モデル] が [完全] に設定されていることを確認します。 そうでない場合は、Always On 機能をサポートするように変更します。
次に示す手順は、可用性グループに追加する必要のあるデータベースごとに繰り返す必要があります。 一部の SharePoint Server 2016 データベースでは、SQL Server Always On 可用性グループがサポートされていません。 詳細については、「サポートされている SharePoint データベース用の高可用性と障害復旧のオプション」を参照してください。
データベースをバックアップするには
最初の SQL Server 仮想マシンに接続します。
[スタート] をクリックして、「 SQL Studio」と入力し、 [SQL Server Management Studio] をクリックします。
[ 接続] をクリックします。
左側のウィンドウで、 [データベース] ノードを展開します。
バックアップするデータベースを右クリックし、 [タスク] をポイントして、 [バックアップ] をクリックします。
[バックアップ先] セクションで、 [削除] をクリックしてバックアップ ファイルの既定のファイル パスを削除します。
[ 追加 ] をクリックします。 [ファイル名] に「 \<machineName>\backup<databaseName>.bak」と入力します。ここで、machineName はプライマリ SQL Server コンピューターの名前、databaseName はデータベースの名前です。 [ OK] をクリックし、正常なバックアップに関するメッセージの後でもう一度 [OK] をクリックします 。
左側のウィンドウで、 <databaseName>を右クリックし、[ タスク] をポイントし、[ バックアップ] をクリックします。
[バックアップの種類]で、 [トランザクション ログ] を選択して、 [OK] を 2 回クリックします。
最初の SQL Server 仮想マシンへのリモート デスクトップ セッションは、開いたままにしておきます。
データベースを復元するには
<ドメイン>\sp_farm_db アカウント資格情報を使用してセカンダリ SQL Server 仮想マシンに接続します。
セカンダリの SQL Server 仮想マシンで、 [スタート] をクリックして、「 SQL Studio」と入力し、 [SQL Server Management Studio] をクリックします。
[ 接続] をクリックします。
左側のウィンドウで、 [データベース] を右クリックして、 [データベースの復元] をクリックします。
[ ソース ] セクションで [ デバイス] を選択し、省略記号 ( ...) ボタンをクリックします。
[バックアップ デバイスの選択] で、 [追加] をクリックします。
[ バックアップ ファイルの場所 ] に「 \<machine name>\backup」と入力し、Enter キーを押し、[ <databaseName>.bak を選択し、[OK] を 2 回クリック します 。 この時点で、 [復元するバックアップ セット] セクションに完全バックアップとログ バックアップが表示されるようになります。
[ページの選択] の下側で、 [オプション] をクリックします。 [復元オプション] セクションの [復旧状態] で、 [RESTORE WITH NORECOVERY] を選択して、 [OK] をクリックします。
確認を求められたら、 [OK] をクリックします。
少なくとも 1 つのデータベースの準備 (バックアップと復元の方法を使用) が完了したら、次に示す手順を実行して、可用性グループを作成します。
最初の SQL Server 仮想マシンへのリモート デスクトップ セッションに戻ります。
SQL Server Management Studio の左側のウィンドウで、[Always On 高可用性] を右クリックし、[新しい可用性グループ ウィザード] をクリックします。
[説明] ページで、 [次へ] をクリックします。
[可用性グループ名の指定] ページの [可用性グループ名] に、可用性グループの名前 (例: AG1) を入力して、 [次へ] をクリックします。
[データベースの選択] ページで、バックアップを作成した SharePoint ファーム用のデータベースを選択して、 [次へ] をクリックします。 これに該当するデータベースは、対象とするプライマリ レプリカで少なくとも 1 つの完全バックアップを作成しているため、可用性グループの前提条件を満たしています。
[レプリカの指定] ページで、 [レプリカの追加] をクリックします。
[サーバーに接続] に、セカンダリの SQL Server 仮想マシンの名前を入力して、 [接続] をクリックします。
[レプリカの指定] ページの [可用性レプリカ] の一覧にセカンダリの SQL Server 仮想マシンが表示されます。 両方のインスタンスに、次に示すオプション値を設定します。
| 初期ロール | オプション | 値 |
|---|---|---|
| 主/プライマリ |
自動フェールオーバー (上限 2) |
選択 |
| セカンダリ |
自動フェールオーバー (上限 2) |
選択 |
| 主/プライマリ |
同期コミット (上限 3) |
選択 |
| セカンダリ |
同期コミット (上限 3) |
選択 |
| 主/プライマリ |
読み取り可能なセカンダリ |
はい |
| セカンダリ |
読み取り可能なセカンダリ |
はい |
[ 次へ] をクリックします。
[最初のデータの同期を選択] ページで、 [結合のみ] をクリックして、 [次へ] をクリックします。 データの同期は、プライマリ サーバーで完全バックアップとトランザクション バックアップを作成して、それらをバックアップで復元することで手動で実行します。 [完全] を選択して、新しい可用性グループ ウィザードにデータの同期を任せることもできます。 ただし、一部の企業に存在する巨大なデータベースには、 完全な自動同期はお勧めできません。
[検証] ページで、 [次へ] をクリックします。 可用性グループ リスナーを構成していないため、リスナー構成が見つからないという警告が表示されます。 これについては、この記事の後で説明する手順で手動で実行します。
[概要] ページで、 [完了] をクリックします。 ウィザードを完了したら、 [結果] ページを調べて、可用性グループが正常に作成されたことを確認します。 [閉じる] をクリックして、ウィザードを閉じます。
[スタート] をクリックし、「 Failover」と入力して、 [フェールオーバー クラスター マネージャー] をクリックします。 左側のウィンドウで、クラスタの名前を開いて、 [役割] をクリックします。 可用性グループの名前が付いた新しい役割が表示されます。
可用性グループ リスナーを構成する
可用性グループ リスナーとは、SQL Server 可用性グループがリッスンする IP アドレスと DNS 名のことです。 次に示す手順を使用して、SQL Server クラスターの可用性グループ リスナーを作成します。
- 次に示す手順で、クラスター ネットワーク リソース名を調べます。
[スタート] をクリックし、「 Failover」と入力して、 [フェールオーバー クラスター マネージャー] をクリックします。
[ネットワーク] ノードをクリックして、クラスター ネットワーク名をメモしておきます。 この名前は、PowerShell コマンド ブロックの $ClusterNetworkName 変数の名前として必要になります (この手順の手順 6 を参照)。
- クライアント アクセス ポイントは、アプリケーションが可用性グループ内のデータベースに接続するために使用するネットワーク名です。 次に示す手順で、クライアント アクセス ポイントを追加します。
[フェールオーバー クラスター マネージャー] で、クラスター名を展開して、 [役割] をクリックします。
[役割] ウィンドウで、可用性グループの名前を右クリックして、 [リソースの追加] > [クライアント アクセス ポイント] を選択します。
[名前] に、この新しいリスナーの名前を指定します。
新しいリスナーの名前は、アプリケーションが SQL Server 可用性グループのデータベースに接続するために使用するネットワーク名になります。
[次へ] を 2 回クリックして、 [完了] をクリックします。 この時点では、リスナーやリソースをオンラインにしないでください。
- 次に示す手順で、 可用性グループの IP リソースを構成します。
[リソース] タブをクリックして、前の手順で作成したクライアント アクセス ポイントを展開します。 このクライアント アクセス ポイントはオフラインになっています。
IP リソースを右クリックして、 [プロパティ] をクリックします。 IP アドレスの名前をメモしておきます。 この名前は、PowerShell コマンド ブロックの $IPResourceName 変数の名前として必要になります (この手順の手順 6 を参照)。
[IP アドレス] の下側で、 [静的 IP アドレス] をクリックします。 IP アドレスの値を「表 I」-「項目 4」の値に設定します。
- 次に示す手順を実行して、SQL Server 可用性グループ リソースがクライアント アクセス ポイントに依存するようにします。
[フェールオーバー クラスター マネージャー] で、 [役割] をクリックして、可用性グループをクリックします。
[リソース] タブの [サーバー名] の下側で、可用性リソース グループを右クリックして、 [プロパティ] をクリックします。
[依存関係] タブで、名前リソースを追加します。 このリソースは、クライアント アクセス ポイントになります。
[OK] をクリックします。
- 次に示す手順で、クライアント アクセス ポイント リソースが IP アドレスに依存するようにします。
[フェールオーバー クラスター マネージャー] で、 [役割] をクリックして、可用性グループをクリックします。
[リソース] タブの [サーバー名] の下側で、クライアント アクセス ポイントを右クリックして、 [プロパティ] をクリックします。
[ 依存関係 ] タブをクリックします。リスナー リソース名に依存関係を設定します。 一覧に複数のリソースが表示されている場合は、IP アドレスに [AND] ではなく [OR] の依存関係が設定されていることを確認します。 [OK] をクリックします。
リスナー名を右クリックして、 [オンラインにする] をクリックします。
- 次に示す手順で、クラスターのパラメーターを設定します。
<ドメイン名>\sp_farm_db アカウント資格情報を使用して、いずれかの SQL Server 仮想マシンに接続します。
管理者レベルの PowerShell コマンド プロンプトを起動して、変数の値を指定し、次に示すコマンドを実行します。
$ClusterNetworkName = "<MyClusterNetworkName>"
$IPResourceName = "<IPResourceName>"
$ILBIP = "<Table I - Item 4 - Value column>"
[int]$ProbePort = <nnnnn>
Import-Module FailoverClusters
Get-ClusterResource $IPResourceName | Set-ClusterParameter -Multiple @{"Address"="$ILBIP";"ProbePort"=$ProbePort;"SubnetMask"="255.255.255.255";"Network"="$ClusterNetworkName";"EnableDhcp"=0}
次の手順を使用して、リスナー ポートを構成します。
最初の SQL Server 仮想マシンに接続して、SQL Server Management Studio を起動し、ローカル コンピューターに接続します。
[ Always On 高可用性 > 可用性グループ > 可用性グループ リスナー] に移動します。
[フェールオーバー クラスター マネージャー] で作成したリスナーの名前が表示されるようになります。
リスナー名を右クリックして、 [プロパティ] をクリックします。
[ポート] ボックスで、以前に使用した $ProbePort (既定は 1433) を使用して、可用性グループ リスナーのポート番号を指定し、 [OK] をクリックします。
次に示す手順を使用して、リスナーへの接続をテストします。
セカンダリの SQL Server 仮想マシンに接続して、管理者レベルのコマンド プロンプトを起動します。
sqlcmd ツールを使用して、接続をテストします。 たとえば、次に示すコマンドでは、Windows 認証によるプライマリ レプリカへの sqlcmd 接続がリスナー経由で確立されます。
sqlmd -S <listenerName> -E
リスナーが使用しているポートが既定のポート (1433) 以外の場合は、接続文字列でポートを指定します。 たとえば、次に示す sqlcmd コマンドは、ポート 1435 でリスナーに接続します。
sqlcmd -S <listenerName>,1435 -E
sqlcmd 接続により、プライマリ レプリカをホストしているほうの SQL Server インスタンスに自動的に接続されます。
正常性ダッシュボードを使用して、Always On 可用性グループが正常に動作することを確認するには、次の手順を実行します。
最初の SQL Server 仮想マシンの SQL Server Management Studio の左側のウィンドウで、[ Always On 高可用性] > [可用性グループ] を展開します。
可用性グループを右クリックして、 [ダッシュボードの表示] をクリックします。
ダッシュボードのステータスには、すべての [同期の状態] に対して緑色が示されます。
SharePoint ファームの構成を完了する
SharePoint 構成と管理コンテンツ データベースが可用性グループに追加され、正しく同期されたので、次の手順は、SQL Server ノードの障害が発生した場合にアクセスできることを確認することです。 これを行うには、SharePoint ファームの SQL Server データベース接続文字列を、SQL クラスターの内部ロード バランサーの DNS 名と一致するように更新する必要があります。
注:
オンプレミスの SQL Server Always On 展開では、可用性グループはリスナーを使用して SharePoint サーバーへの接続ポイントを提示します。 Azure IaaS には、これを妨げるネットワークの制限があるため、代わりに、内部ロード バランサーの DNS 名を使用する必要があります。 この状況では、可用性グループのメンバーシップを管理するための SharePoint PowerShell コマンドレットが使用できません。 その代わりに、データベース オブジェクトのメソッド呼び出しを使用する必要があります。
次に示す手順を実行して、SharePoint のデータベース接続文字列を更新します。
ファーム内のいずれかの SharePoint サーバーに接続して、管理者レベルの PowerShell コマンド プロンプトを起動します。
次のコマンドを実行して、ファーム内のデータベースごとに、現在の接続文字列の設定を確認します。
Add-psnappin Microsoft.SharePoint.PowerShell -EA 0
Get-Spdatabase | select name, server
Get-Spdatabase コマンドの出力には、接続文字列に基づいたデーベース名とサーバー プロパティ値が表示されます。
- クラスターで SQL ノードと一致するサーバー プロパティを持つ可用性グループのデータベースごとに、PowerShell を使用して、このプロパティ値がロード バランサーの DNS 名と一致するように更新する必要があります。 この例は、SharePoint_Config データベースに対応するものです。
Get-SPDatabase #Lists all available SharePoint Databases
$agName = "<Availability Group Listener DNS name>"
$db = Get-SPDatabase -Name "Sharepoint_Config"
$db.ChangeDatabaseInstance("$agName")
$db.update()
可用性グループに含まれるデータベースごとに、このタスクを完了すると、フェールオーバー テストを実施できるようになります。
次の手順を実行して、SQL Server 可用性グループのフェールオーバーを実施し、サーバーの全体管理 Web サイトが動作状態を維持していることを確認します。
ファーム内のいずれかの SharePoint サーバーに接続します。
SharePoint サーバーの全体管理を起動し、Web サイトを巡回して、エラーがないことを確認します。
最初の SQL Server 仮想マシンに接続して、SQL Server Management Studio を起動します。
[可用性グループ] ノードを展開し、可用性グループの名前を右クリックして、 [フェールオーバー] をクリックします。
可用性グループ フェールオーバー ウィザードが起動します。 [次へ] をクリックします。
この可用性グループの [新しいプライマリ レプリカの選択] ページで、セカンダリの SQL Server 仮想マシンを選択して、 [次へ] をクリックします。
セカンダリノードに対する認証のために [接続] をクリックして、 [次へ] をクリックします。
[完了] をクリックして操作を確認し、手動のフェールオーバーを開始します。
エラーや警告について、フェールオーバー ウィザードの概要情報を確認します。
サーバーの全体管理 Web サイトを閲覧していた SharePoint サーバーに戻って、エラーなしで Web サイトを閲覧できることを確認します。
これで、Azure の高可用性 SharePoint Server 2016 ファームは完成です。
関連項目
その他のリソース
Azure で SharePoint Server と SQL Server の Always On 可用性グループを展開する
Microsoft Azure での SharePoint Server