SQL Server ビッグ データ クラスターでのアプリ展開の概要
適用対象: ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
重要
Microsoft SQL Server 2019 ビッグ データ クラスターのアドオンは廃止されます。 SQL Server 2019 ビッグ データ クラスターのサポートは、2025 年 2 月 28 日に終了します。 ソフトウェア アシュアランス付きの SQL Server 2019 を使用する既存の全ユーザーはプラットフォームで完全にサポートされ、ソフトウェアはその時点まで SQL Server の累積更新プログラムによって引き続きメンテナンスされます。 詳細については、お知らせのブログ記事と「Microsoft SQL Server プラットフォームのビッグ データ オプション」を参照してください。
アプリケーション展開は、アプリケーションを作成、管理、および実行するためのインターフェイスを提供することにより、SQL Server ビッグ データ クラスターでアプリケーションの展開を可能にします。 ビッグ データ クラスターに展開されたアプリケーションは、クラスターの計算機能を活用し、クラスターで使用可能なデータにアクセスできます。 これにより、データが存在するアプリケーションを管理しながら、アプリケーションのスケーラビリティとパフォーマンスが向上します。 SQL Server ビッグ データ クラスターでサポートされるアプリケーション ランタイムは、R、Python、dtexec、MLeap です。
以降のセクションでは、アプリケーション展開のアーキテクチャと機能について説明します。
アプリケーション展開アーキテクチャ
アプリケーション展開は、コントローラーとアプリのランタイム ハンドラーで構成されます。 アプリケーションを作成するときに、仕様ファイル (spec.yaml) が提供されます。 この spec.yaml ファイルには、アプリケーションを正常に展開するためにコントローラーが認識する必要があるすべてのものが含まれています。 spec.yaml の内容例を次に示します。
#spec.yaml
name: add-app #name of your python script
version: v1 #version of the app
runtime: Python #the language this app uses (R or Python)
src: ./add.py #full path to the location of the app
entrypoint: add #the function that will be called upon execution
replicas: 1 #number of replicas needed
poolsize: 1 #the pool size that you need your app to scale
inputs: #input parameters that the app expects and the type
x: int
y: int
output: #output parameter the app expects and the type
result: int
コントローラーは、spec.yaml ファイル内で指定された runtime を検査し、対応するランタイム ハンドラーを呼び出します。 ランタイム ハンドラーによってアプリケーションが作成されます。 まず、Kubernetes ReplicaSet が作成されます。これには、それぞれに展開するアプリケーションが含まれた 1 つ以上のポッドが含まれます。 ポッドの数は、アプリケーションの spec.yaml ファイルで設定された replicas パラメーターによって定義されます。 各ポッドには、1 つ以上のプールを含めることができます。 プールの数は、spec.yaml ファイルの poolsize パラメーター セットによって定義されます。
これらの設定によって、展開が並列で処理できる要求の量が決定します。 指定された時間内の要求の最大数は、replicas に poolsize を掛けた数と等しくなります。 5 つのレプリカがあり、レプリカあたり 2 つのプールがある場合、展開では 10 個の要求を並行して処理できます。 次の図は、replicas と poolsize をグラフィカルに表現したものです。
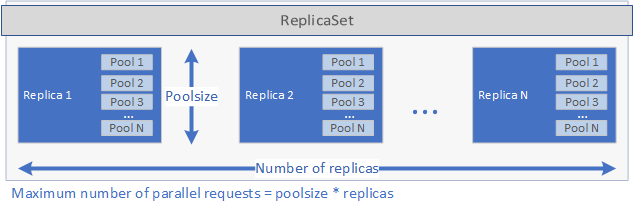
ReplicaSet が作成され、ポッドが開始されると、spec.yaml ファイルで schedule が設定されている場合は、cron ジョブが作成されます。 最後に、アプリケーションの管理と実行に使用できる Kubernetes サービスが作成されます (以下を参照)。
アプリケーションが実行されると、アプリケーションの Kubernetes サービスによって、レプリカに対する要求がプロキシされ、結果が返されます。
OpenShift でのアプリケーション展開のセキュリティに関する考慮事項
SQL Server 2019 CU5 により、Red Hat OpenShift での BDC の展開、および BDC の更新されたセキュリティ モデルがサポートされるため、特権コンテナーは不要になります。 SQL Server 2019 CU5 を使用するすべての新しい展開では、非特権だけでなく、コンテナーも既定では非ルート ユーザーとして実行されます。
CU5 リリースの時点では、アプリ展開インターフェイスを使用して展開されたアプリケーションのセットアップ手順は、引き続き ルート ユーザーとして実行されます。 これは、セットアップ中に、アプリケーションで使用する追加のパッケージがインストールされるために必要です。 アプリケーションの一部として展開された他のユーザー コードは、特権の低いユーザーとして実行されます。
また、CAP_AUDIT_WRITE 機能は、cron ジョブを使用して SQL Server Integration Services (SSIS) アプリケーションをスケジュールするために必要なオプションの機能です。 アプリケーションの yaml 仕様ファイルでスケジュールが指定されている場合、アプリケーションは cron ジョブによってトリガーされるため、追加の機能が必要になります。 または、Web サービスの呼び出しを使用して azdata app run で必要に応じてアプリケーションをトリガーすることもできます。この場合、CAP_AUDIT_WRITE 機能は必要ありません。 SQL Server 2019 CU8 リリース以降では cronjob で CAP_AUDIT_WRITE 機能が不要になりました。
Note
この機能は、BDC の既定の展開では必須ではないため、OpenShift の展開の記事 のカスタム SCC には含まれていません。 この機能を有効にするには、まず、カスタム SCC yaml ファイルを更新して、CAP_AUDIT_WRITE を含める必要があります。
...
allowedCapabilities:
- SETUID
- SETGID
- CHOWN
- SYS_PTRACE
- AUDIT_WRITE
...
ビッグ データ クラスター内でアプリの展開を操作する方法
アプリケーション展開には、次の 2 つの主要なインターフェイスがあります。
RESTful Web サービスを使用してアプリケーションを実行することもできます。 詳細については、ビッグ データ クラスターでのアプリケーションの使用に関するページを参照してください。
アプリケーション展開のシナリオ
アプリケーション展開は、アプリケーションを作成、管理、および実行するためのインターフェイスを提供することにより、SQL Server BDC でアプリケーションの展開を可能にします。
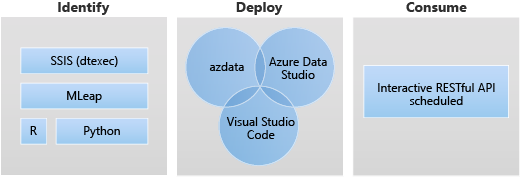
アプリケーション展開の対象シナリオを次に示します。
- 機械学習の推論、API サービスなどのさまざまなユース ケースに対応するために、ビッグ データ クラスター内に Python または R Web サービスを展開する。
- MLeap エンジンを使用して機械学習の推論のエンドポイントを作成する。
- データの変換と移動に dtexec ユーティリティを使用して、DTSX ファイルからパッケージのスケジュール設定と実行を行う。
アプリケーション展開の Python ランタイムを使用する
アプリケーション展開では、BDC Python ランタイムによって、ビッグ データ クラスター内の Python アプリケーションが機械学習の推論、API サービスなどの、さまざまなユースケースに対応できるようになります。
アプリケーション展開の Python ランタイムによって Python 3.8 が SQL Server ビッグ データ クラスター CU10+ で使用されます。
アプリケーション展開において、spec.yaml は、アプリケーション展開のコントローラーが認識する必要がある情報を指定するものです。 指定できるフィールドは次のとおりです。
name: アプリケーション名version: アプリケーションのバージョン。たとえば、v1runtime: アプリケーション展開のランタイム。Pythonのように指定する必要がありますsrc: Python アプリケーションのパスentry point: この Python アプリケーションに対して実行する src スクリプトのエントリ ポイント関数。
上記以外に、Python アプリケーションの入力と出力を指定する必要があります。 次のような spec.yaml ファイルが生成されます。
#spec.yaml
name: add-app
version: v1
runtime: Python
src: ./add.py
entrypoint: add
replicas: 1
poolsize: 1
inputs:
x: int
y: int
output:
result: int
ビッグ データ クラスターで実行されている Python アプリケーションを展開するために必要な基本的なフォルダーとファイル構造を作成できます。
azdata app init --template python --name hello-py --version v1
次の手順については、「SQL Server ビッグ データ クラスターにアプリを展開する方法」を参照してください。
アプリ展開の Python ランタイムの制限事項
アプリ展開の Python ランタイムは、スケジューリング シナリオをサポートしていません。 Python アプリを展開し、BDC で実行すると、受信要求をリッスンするように RESTful エンドポイントが構成されます。
アプリケーション展開の R ランタイムを使用する
アプリケーション展開では、BDC Python ランタイムによって、ビッグ データ クラスター内の R アプリケーションが機械学習の推論、API サービスなどの、さまざまなユースケースに対応できるようになります。
アプリケーション展開の R ランタイムによって Microsoft R Open (MRO) バージョン 3.5.2 が SQL Server ビッグ データ クラスター CU10+ で使用されます。
使用方法
アプリケーション展開において、spec.yaml は、アプリケーション展開のコントローラーが認識する必要がある情報を指定するものです。 指定できるフィールドは次のとおりです。
name: アプリケーション名version: アプリケーションのバージョン。たとえば、v1runtime: アプリケーション展開のランタイム。Rのように指定する必要がありますsrc: R アプリケーションのパスentry point: この R アプリケーションを実行するためのエントリ ポイント
上記以外に、R アプリケーションの入力と出力を指定する必要があります。 次のような spec.yaml ファイルが生成されます。
#spec.yaml
name: roll-dice
version: v1
runtime: R
src: ./roll-dice.R
entrypoint: rollEm
replicas: 1
poolsize: 1
inputs:
x: integer
output:
result: data.fram
次のコマンドを使用して、新しい R アプリケーションを展開するために必要な基本的なフォルダーとファイル構造を作成できます。
azdata app init --template r --name hello-r --version v1
次の手順については、「SQL Server ビッグ データ クラスターにアプリを展開する方法」を参照してください。
R ランタイムの制限事項
これらの制限事項は、2023 年 7 月 1 日に廃止された Microsoft R Application Network と合わせたものです。 詳細と回避策については、「Microsoft R Application Network の廃止」を参照してください。
アプリケーション展開の dtexec ランタイムの使用
アプリ展開では、ビッグ データ クラスター ランタイム統合 dtexec ユーティリティは、SSIS on Linux からのものです (mssql-server-is)。 アプリ展開では、*.dtsx ファイルからのパッケージの読み込みに、dtexec ユーティリティが使用されます。 cron 形式のスケジュールでの SSIS パッケージの実行、または Web サービス要求によるオンデマンドがサポートされます。
この機能は、SQL Server 2019 Integration Service on Linux の /opt/ssis/bin/dtexec /FILE を使用し、 SQL Server 2019 Integration Service on Linux (mssql-server-is 15.0.2) 用に dtsx 形式をサポートしています。 dtexec ユーティリティの詳細については、「dtexec ユーティリティ」を参照してください。
アプリケーション展開において、spec.yaml は、アプリケーション展開のコントローラーが認識する必要がある情報を指定するものです。 指定できるフィールドは次のとおりです。
name: アプリケーションのnameversion: アプリケーションのバージョン。たとえば、v1runtime: アプリケーション展開のランタイム。dtexec ユーティリティを実行するには、SSISのように指定する必要がありますentrypoint: エントリ ポイントを指定します。今回の場合、通常は自分の .dtsx ファイルです。options:/opt/ssis/bin/dtexec /FILEの追加オプションを指定します。接続文字列を使用してデータベースに接続する場合は、次のパターンに従います。/REP V /CONN "sqldatabasename"\;"\"Data Source=xx;User ID=xx;Password=xx\""構文の詳細については、「dtexec ユーティリティ」を参照してください。
schedule: ジョブに必要な実行頻度を指定します。たとえば、cron 式を使用してこの値を指定する場合、"*/1 * * * *" と指定します。これは、ジョブが分単位で実行されることを意味します。
次のコマンドを使用して、新しい SSIS アプリケーションを展開するために必要な基本的なフォルダーとファイル構造を作成できます。
azdata app init --name hello-is –version v1 --template ssis
次のような spec.yaml ファイルが生成されます。
#spec.yaml
entrypoint: ./hello.dtsx
name: hello-is
options: /REP V
poolsize: 2
replicas: 2
runtime: SSIS
schedule: '*/2 * * * *'
version: v1
この例では、サンプルの hello.dtsx パッケージも作成されます。
すべてのアプリケーション ファイルが spec.yaml と同じディレクトリにあります。 spec.yaml は、dtsx ファイルを含めたアプリケーションのソース コード ディレクトリのルート レベルにある必要があります。
次の手順については、「SQL Server ビッグ データ クラスターにアプリを展開する方法」を参照してください。
dtexec ユーティリティ ランタイムの制限事項
SQL Server Integration Services (SSIS) on Linux のすべての制限事項と既知の問題が、SQL Server ビッグ データ クラスターで適用されます。 詳細については、「Linux での SSIS に関する制限事項と既知の問題」を参照してください。
アプリケーション展開の MLeap ランタイムの使用
アプリケーション展開の MLeap ランタイムは、v0.13.0 にサービスを提供する MLeap をサポートしています。
アプリケーション展開において、spec.yaml は、アプリケーション展開のコントローラーが認識する必要がある情報を指定するものです。 指定できるフィールドは次のとおりです。
name: アプリケーション名version: アプリケーションのバージョン。たとえば、v1runtime: アプリケーション展開のランタイム。Mleapのように指定する必要があります
上記以外に、MLeap アプリケーションの bundleFileName を指定する必要があります。 次のような spec.yaml ファイルが生成されます。
#spec.yaml
name: mleap-census
version: v1
runtime: Mleap
bundleFileName: census-bundle.zip
replicas: 1
次のコマンドを使用して、新しい MLeap アプリケーションを展開するために必要な基本的なフォルダーとファイル構造を作成できます。
azdata app init --template mleap --name hello-mleap --version v1
次の手順については、「SQL Server ビッグ データ クラスターにアプリを展開する方法」を参照してください。
MLeap ランタイムの制限事項
この制限事項は、MLeap オープンソース プロジェクト GitHub の Combust のビジョンに合わせたものです。
次のステップ
SQL Server ビッグ データ クラスターでアプリケーションを作成して実行する方法の詳細については、次を参照してください。
SQL Server ビッグ データ クラスターの詳細については、次の概要を参照してください。