高可用性を使用して SQL Server ビッグ データ クラスターを展開する
適用対象: ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
重要
Microsoft SQL Server 2019 ビッグ データ クラスターのアドオンは廃止されます。 SQL Server 2019 ビッグ データ クラスターのサポートは、2025 年 2 月 28 日に終了します。 ソフトウェア アシュアランス付きの SQL Server 2019 を使用する既存の全ユーザーはプラットフォームで完全にサポートされ、ソフトウェアはその時点まで SQL Server の累積更新プログラムによって引き続きメンテナンスされます。 詳細については、お知らせのブログ記事と「Microsoft SQL Server プラットフォームのビッグ データ オプション」を参照してください。
SQL Server ビッグ データ クラスターは、コンテナー化アプリケーションとして Kubernetes 上にあり、ステートフル セットや永続ストレージなどの機能を使用するため、このインフラストラクチャには、サービスの正常性を維持するためにクラスター コンポーネントで利用される、正常性監視、障害検出、およびフェールオーバー メカニズムが組み込まれています。 信頼性を向上させるために、高可用性構成で追加のレプリカを使用して展開するように、SQL Server マスター インスタンス、HDFS 名前ノードと Spark 共有サービス、またはその両方を構成することもできます。 監視、障害検出、および自動フェールオーバーは、ビッグ データ クラスター管理サービス、つまり、制御サービスによって管理されます。 このサービスでは、可用性グループのセットアップ、データベース ミラーリング エンドポイントの構成から、可用性グループへのデータベースの追加またはフェールオーバーとアップグレードの調整まですべて、ユーザーの介入なしで提供されます。
次の図は、SQL Server ビッグ データ クラスターに可用性グループが展開される方法を示しています。
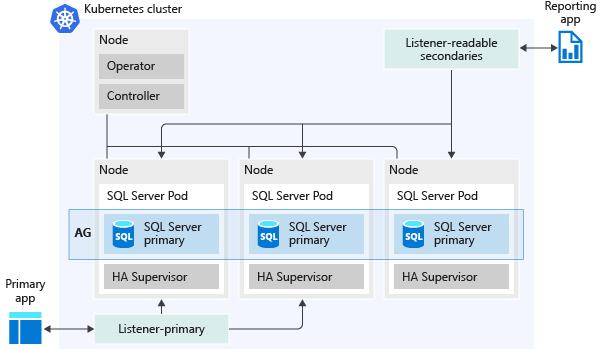
可用性グループで有効になる機能の一部を以下に示します。
高可用性の設定が展開構成ファイルで指定されている場合は、
containedagという名前の 1 つの可用性グループが作成されます。 既定では、containedagに、プライマリを含む、3 つのレプリカがあります。 可用性グループの CRUD 操作はすべて内部的に管理されます。これには、可用性グループの作成や作成された可用性グループへのレプリカの参加が含まれます。 ビッグ データ クラスターの SQL Server マスター インスタンスで、追加の可用性グループを作成することはできません。データベースはすべて可用性グループに自動的に追加されます。これには、すべてのユーザーおよびシステム データベース (
masterやmsdbなど) が含まれます。 この機能により、可用性グループ レプリカ全体で単一システム ビューが提供されます。 追加のモデル データベース (model_replicatedmasterとmodel_msdb) は、システム データベースのレプリケートされた部分をシード処理するために使用されます。 これらのデータベースに加えて、インスタンスに直接接続している場合は、containedag_masterおよびcontainedag_msdbデータベースが表示されます。containedagデータベースは、可用性グループ内のmasterとmsdbを表します。重要
アタッチ データベースなどのワークフローの結果としてインスタンスに作成されたデータベースは、可用性グループに自動的に追加されることはありません。 SQL Server ビッグ データ クラスター管理者はこれを手動で行う必要があります。 SQL Server インスタンス マスター データベースに対して一時エンドポイントを有効にする方法を説明するには、「SQL Server インスタンスに接続する」を参照してください。 SQL Server 2019 CU2 より前のリリースでは、復元ステートメントの結果として作成されたデータベースも同じ動作を示し、データベースを包含可用性グループに手動で追加する必要がありました。
PolyBase 構成データベースは可用性グループには含まれません。これは、各レプリカに固有のインスタンス レベルのメタデータが含まれているためです。
外部エンドポイントは、可用性グループ内のデータベースへの接続用に自動的にプロビジョニングされます。 このエンドポイント
master-svc-externalは、可用性グループ リスナーの役割を果たします。2 つ目の外部エンドポイントは、読み取りワークロードをスケールアウトするために、セカンダリ レプリカへの読み取り専用接続用にプロビジョニングされます。
配置
可用性グループに SQL Server マスターを展開するには、次のようにします。
hadr機能を有効にします- AG のレプリカの数を指定します (最小値は 3)
- 読み取り専用セカンダリ レプリカへの接続用に作成された 2 番目の外部エンドポイントの詳細を構成します
aks-dev-test-ha または kubeadm-prod の組み込み構成プロファイルを使用して、ビッグ データ クラスターのカスタマイズを開始できます。 これらのプロファイルには、追加の高可用性を構成できるリソースに必要な設定が含まれます。 たとえば、以下は、SQL Server マスター インスタンスの可用性グループの有効化に関連する、bdc.json 構成ファイルのセクションです。
{
...
"spec": {
"type": "Master",
"replicas": 3,
"endpoints": [
{
"name": "Master",
"serviceType": "LoadBalancer",
"port": 31433
},
{
"name": "MasterSecondary",
"serviceType": "LoadBalancer",
"port": 31436
}
],
"settings": {
"sql": {
"hadr.enabled": "true"
}
}
}
...
}
次の手順では、aks-dev-test-ha プロファイルから開始し、ビッグ データ クラスターの展開構成をカスタマイズする方法の例について説明します。 kubeadm クラスターでの展開でも、同様の手順が適用されますが、endpoints セクションの serviceType には必ず NodePort を使用するようにしてください。
ターゲットとなるプロファイルを複製します
azdata bdc config init --source aks-dev-test-ha --target custom-aks-ha必要に応じて、カスタム プロファイルを任意で編集することもできます。
上記で作成されたクラスター構成プロファイルを使用して、クラスターの展開を開始します
azdata bdc create --config-profile custom-aks-ha --accept-eula yes
可用性グループ内の SQL Server データベースに接続する
SQL Server マスターに対して実行するワークロードの種類に応じて、読み取り/書き込みワークロードの場合はプライマリに、読み取り専用の種類のワークロードの場合はセカンダリ レプリカ内のデータベースに接続できます。 接続の種類ごとの概要を以下に示します。
プライマリ レプリカのデータベースに接続する
プライマリ レプリカへの接続では、sql-server-master エンドポイントを使用します。 このエンドポイントは、AG のリスナーでもあります。 このエンドポイントを使用する場合、すべての接続は可用性グループ内のデータベースのコンテキストにあります。 たとえば、このエンドポイントを使用する既定の接続では、SQL Server インスタンスの master データベースではなく、可用性グループ内の master データベースに接続することになります。 次のコマンドを実行して、エンドポイントを検索します。
azdata bdc endpoint list -e sql-server-master -o table
Description Endpoint Name Protocol
------------------------------------ ------------------- ----------------- ----------
SQL Server Master Instance Front-End 11.11.111.111,11111 sql-server-master tds
Note
フェールオーバー イベントは、HDFS やデータ プールなどのリモート データ ソースからデータにアクセスする分散クエリの実行中に発生する可能性があります。 ベスト プラクティスとして、フェールオーバーによる切断が発生した場合に接続再試行ロジックを使用するように、アプリケーションを設計する必要があります。
セカンダリ レプリカのデータベースに接続する
セカンダリ レプリカのデータベースへの読み取り専用接続では、sql-server-master-readonly エンドポイントを使用します。 このエンドポイントは、すべてのセカンダリ レプリカにわたるロード バランサーのように機能します。 このエンドポイントを使用する場合、すべての接続は可用性グループ内のデータベースのコンテキストにあります。 たとえば、このエンドポイントを使用する既定の接続では、SQL Server インスタンスの master データベースではなく、可用性グループ内の master データベースに接続することになります。
azdata bdc endpoint list -e sql-server-master-readonly -o table
Description Endpoint Name Protocol
--------------------------------------------- ------------------ -------------------------- ----------
SQL Server Master Readable Secondary Replicas 11.11.111.11,11111 sql-server-master-readonly tds
SQL Server インスタンスに接続する
サーバー レベルの構成を設定する、または可用性グループにデータベースを手動で追加するなどの特定の操作では、SQL Server インスタンスに接続する必要があります。 SQL Server 2019 CU2 よりも前のバージョンでは、sp_configure、RESTORE DATABASE、または任意の可用性グループの DDL などの操作には、この種類の接続が必要になります。 既定では、ビッグ データ クラスターにインスタンス接続を有効にするエンドポイントが含まれていないため、このエンドポイントを手動で公開する必要があります。
重要
SQL Server インスタンス接続用に公開されたエンドポイントでは、Active Directory が有効になっているクラスターであっても、サポートされるのは SQL 認証のみとなります。 既定では、ビッグ データ クラスターの展開中に、sa ログインが無効になり、AZDATA_USERNAME および AZDATA_PASSWORD 環境変数の展開時に指定された値に基づいて、新しい sysadmin ログインがプロビジョニングされます。
重要
含まれる可用性グループ DDL は BDC で排他的に自己管理されます。 (外部ユーザーが) 含まれる可用性またはデータベース ミラーリング エンドポイントを削除することはできません。削除できても、BDC の状態が回復不可能になることがあります。
このエンドポイントを公開してから、復元ワークフローで作成されたデータベースを可用性グループに追加する方法の例を以下に示します。 sp_configure でサーバー構成を変更する場合は、SQL Server マスター インスタンスへの接続を設定するための同様の手順が適用されます。
Note
SQL Server 2019 CU2 以降では、復元ワークフローの結果として作成されたデータベースは自動的に包含可用性グループに追加されます。
sql-server-masterエンドポイントに接続してプライマリ レプリカをホストするポッドを特定して、以下を実行します。SELECT @@SERVERNAME新しい Kubernetes サービスを作成して外部エンドポイントを公開します
kubeadmクラスターの場合は、以下のコマンドを実行します。podNameを前の手順で返されたサーバーの名前に、serviceNameを作成された Kubernetes サービスの優先名に、namespaceName* をビッグ データ クラスターの名前に置き換えます。kubectl -n <namespaceName> expose pod <podName> --port=1533 --name=<serviceName> --type=NodePortaks クラスターを実行する場合も同じコマンドを実行しますが、作成されるサービスの種類は
LoadBalancerとなります。 次に例を示します。kubectl -n <namespaceName> expose pod <podName> --port=1533 --name=<serviceName> --type=LoadBalanceraks に対して実行されるこのコマンドの例を以下に示します。この場合、プライマリをホストしているポッドは
master-0となります。kubectl -n mssql-cluster expose pod master-0 --port=1533 --name=master-sql-0 --type=LoadBalancer作成された Kubernetes サービスの IP を取得します。
kubectl get services -n <namespaceName>
重要
ベスト プラクティスとして、このコマンドを実行し、上記で作成された Kubernetes サービスを削除してクリーンアップする必要があります。
kubectl delete svc master-sql-0 -n mssql-cluster
可用性グループにデータベースを追加します。
データベースを AG に追加するには、データベースを完全復旧モードで実行する必要があり、ログ バックアップを作成する必要があります。 上記で作成された Kubernetes サービスの IP を使用して、SQL Server インスタンスに接続し、以下に示すように TSQL ステートメントを実行します。
ALTER DATABASE <databaseName> SET RECOVERY FULL; BACKUP DATABASE <databaseName> TO DISK='<filePath>' ALTER AVAILABILITY GROUP containedag ADD DATABASE <databaseName>以下の例では、インスタンスで復元された
salesという名前のデータベースを追加します。ALTER DATABASE sales SET RECOVERY FULL; BACKUP DATABASE sales TO DISK='/var/opt/mssql/data/sales.bak' ALTER AVAILABILITY GROUP containedag ADD DATABASE sales
既知の制限事項
ビッグ データ クラスターの SQL Server マスターについて、含まれる可用性グループには次の既知の問題と制限事項があります。
- ビッグ データ クラスターが展開されるときに、高可用性構成が作成される必要があります。 展開後に可用性グループで高可用性構成を有効にすることはできません。 現時点では、同期コミット レプリカの構成のみが有効になります。
警告
クォーラム コミット内のいずれかのレプリカの同期モードを非同期コミットに更新すると、高可用性について無効な構成が生成されます。 この構成での実行にはデータ損失のリスクが伴います。プライマリ レプリカに影響を与える障害イベントが発生した場合にトリガーされる自動フェールオーバーが存在せず、ユーザーは手動フェールオーバーを発行する際にデータ損失のリスクを受け入れる必要があるためです。
- 別のサーバー上に作成されたバックアップから TDE 対応のデータベースを正常に復元するには、必須の証明書が、SQL Server インスタンス マスターと包含 AG マスターの両方に確実に復元されるようにする必要があります。 証明書のバックアップと復元の方法の例については、こちらを参照してください。
sp_configureでのサーバー構成設定の実行などの特定の操作では、可用性グループmasterではなく、SQL Server インスタンスmasterデータベースへの接続が必要になります。 対応するプライマリ エンドポイントを使用することはできません。 指示に従ってエンドポイントを公開し、SQL Server インスタンスに接続してsp_configureを実行します。 SQL 認証を使用できるのは、エンドポイントを手動で公開して SQL Server インスタンスmasterデータベースに接続する場合のみです。- 包含 msdb データベースは可用性グループに含まれており、SQL Agent ジョブはレプリケートされますが、プライマリ レプリカではジョブはスケジュールに従って実行されるのみです。
- 含まれている可用性グループに対するレプリケーション機能はサポートされていません。 含まれている AG の一部である SQL Server インスタンスは、インスタンス レベルでも含まれている AG レベルでも、ディストリビューターまたはパブリッシャーとして機能することはできません。
- データベースの作成中にファイル グループを追加することはサポートされていません。 回避策として、まずデータベースを作成し、次に ALTER DATABASE ステートメントを実行してファイル グループを追加します。
- SQL Server 2019 CU2 よりも前のバージョンでは、
CREATE DATABASEおよびRESTORE DATABASE以外のワークフロー (CREATE DATABASE FROM SNAPSHOTなど) の結果として作成されたデータベースは、自動的に可用性グループに追加されません。 インスタンスに接続し、データベースを可用性グループに手動で追加します。 - Service Broker とデータベース メールは、高可用性を使用してデプロイされたビッグ データ クラスターでは、現在サポートされていません。
次のステップ
- ビッグ データ クラスターの展開での構成ファイルの使用について詳しくは、「Kubernetes に SQL Server ビッグ データ クラスターを展開する方法」を参照してください。
- SQL Server の可用性グループの機能について詳しくは、「Overview of Always On Availability Groups (SQL Server)」 (Always On 可用性グループの概要 (SQL Server)) を参照してください。