SQL Server ビッグ データ クラスター上の Visual Studio Code で Spark ジョブを送信する
重要
Microsoft SQL Server 2019 ビッグ データ クラスターのアドオンは廃止されます。 SQL Server 2019 ビッグ データ クラスターのサポートは、2025 年 2 月 28 日に終了します。 ソフトウェア アシュアランス付きの SQL Server 2019 を使用する既存の全ユーザーはプラットフォームで完全にサポートされ、ソフトウェアはその時点まで SQL Server の累積更新プログラムによって引き続きメンテナンスされます。 詳細については、お知らせのブログ記事と「Microsoft SQL Server プラットフォームのビッグ データ オプション」を参照してください。
Spark & Hive Tools for Visual Studio Code を使用して Apache Spark 用の PySpark スクリプトを作成して送信する方法について説明します。まず、Spark & Hive Tools を Visual Studio Code にインストールする方法について説明し、次に Spark にジョブを送信する方法について説明します。
Spark & Hive Tools は、Windows、Linux、macOS など、Visual Studio Code でサポートされているプラットフォームにインストールできます。 以下では、さまざまなプラットフォームの前提条件について説明します。
前提条件
この記事の手順を完了するには、次の項目が必要です。
- SQL Server ビッグ データ クラスター。 SQL Server ビッグ データ クラスターに関するページを参照してください。
- Visual Studio Code。
- Visual Studio Code での Python および Python 拡張機能。
- Mono。 Mono は、Linux と macOS の場合にのみ必要です。
- Visual Studio Code 用に PySpark の対話型の環境を設定します。
- SQLBDCexample という名前のローカル ディレクトリ。 この記事では、C:\SQLBDC\SQLBDCexample を使用しています。
Spark & Hive Tools をインストールする
前提条件を満たしたら、Spark & Hive Tools for Visual Studio Code をインストールできます。 Spark & Hive Tools をインストールするには、次の手順を実行します。
Visual Studio Code を開きます。
メニュー バーから [View]\(表示\)>[Extensions]\(拡張機能\) に移動します。
検索ボックスに、「Spark & Hive」と入力します。
検索結果から、(Microsoft によって公開された) Spark & Hive Tools を選び、[インストール] を選択します。
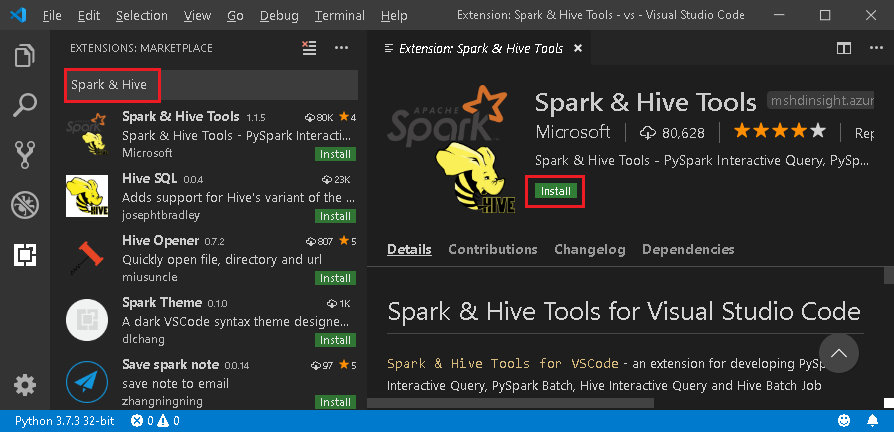
必要に応じてリロードします。
作業フォルダーを開く
次の手順を実行して作業フォルダーを開き、Visual Studio Code でファイルを作成します。
メニュー バーから [ファイル]>[フォルダーを開く]>C:\SQLBDC\SQLBDCexample に移動し、 [フォルダーの選択] ボタンを選択します。 左側の [Explorer](エクスプローラー) ビューにフォルダーが表示されます。
[エクスプローラー] ビューで、SQLBDCexample というフォルダーを選択し、作業フォルダーの横にある [新しいファイル] アイコンを選択します。
新しいファイルに
.py(Spark スクリプト) ファイル拡張子を付けます。 この例では、HelloWorld.py を使用します。次のコードをコピーしてスクリプト ファイルに貼り付けます。
import sys from operator import add from pyspark.sql import SparkSession, Row spark = SparkSession\ .builder\ .appName("PythonWordCount")\ .getOrCreate() data = [Row(col1='pyspark and spark', col2=1), Row(col1='pyspark', col2=2), Row(col1='spark vs hadoop', col2=2), Row(col1='spark', col2=2), Row(col1='hadoop', col2=2)] df = spark.createDataFrame(data) lines = df.rdd.map(lambda r: r[0]) counters = lines.flatMap(lambda x: x.split(' ')) \ .map(lambda x: (x, 1)) \ .reduceByKey(add) output = counters.collect() sortedCollection = sorted(output, key = lambda r: r[1], reverse = True) for (word, count) in sortedCollection: print("%s: %i" % (word, count))
SQL Server ビッグ データ クラスターをリンクする
Visual Studio Code からクラスターにスクリプトを送信するには、SQL Server ビッグ データ クラスターをリンクする必要があります。
メニュー バーから、 [表示]>[コマンド パレット] に移動し、「Spark / Hive: Link a Cluster」と入力します。

リンクされるクラスターの種類として [SQL Server Big Data](SQL Server ビッグ データ) を選択します。
SQL Server ビッグ データ エンドポイントを入力します。
SQL Server ビッグ データ クラスターのユーザー名を入力します。
ユーザー管理者のパスワードを入力します。
ビッグ データ クラスターの表示名を設定します (省略可能)。
クラスターを一覧表示し、[OUTPUT](出力) ビューを確認します。
クラスターを一覧表示する
メニュー バーから、 [表示]>[コマンド パレット] に移動し、「Spark / Hive:List Cluster」と入力します。
[OUTPUT](出力) ビューを確認します。 このビューには、リンクされたクラスターが表示されます。

既定のクラスターを設定する
前の手順で作成したフォルダー SQLBDCexample を閉じている場合は再び開きます。
以前の手順で作成した HelloWorld.py ファイルを選択し、スクリプト エディターで開きます。
クラスターをまだリンクしていない場合は、リンクします。
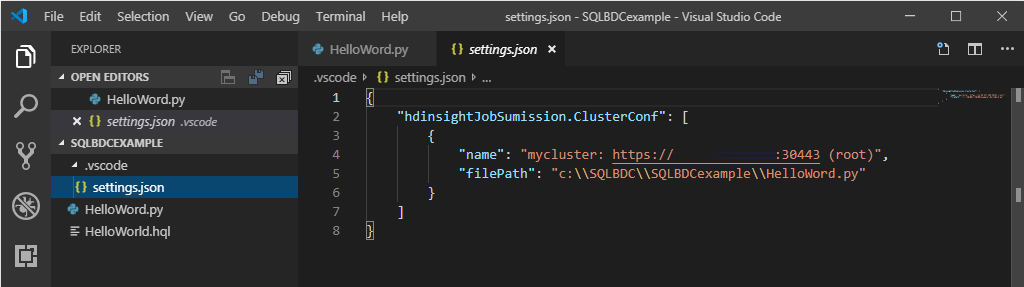
スクリプト エディターを右クリックし、 [Spark / Hive: Set Default Cluster] を選択します。
現在のスクリプト ファイルの既定のクラスターとしてクラスターを選択します。 ツールによって構成ファイル .VSCode\settings.json が自動的に更新されます。
対話型の PySpark クエリを送信する
次の手順に従って、対話型の PySpark クエリを送信できます。
前の手順で作成したフォルダー SQLBDCexample を閉じている場合は再び開きます。
以前の手順で作成した HelloWorld.py ファイルを選択し、スクリプト エディターで開きます。
クラスターをまだリンクしていない場合は、リンクします。
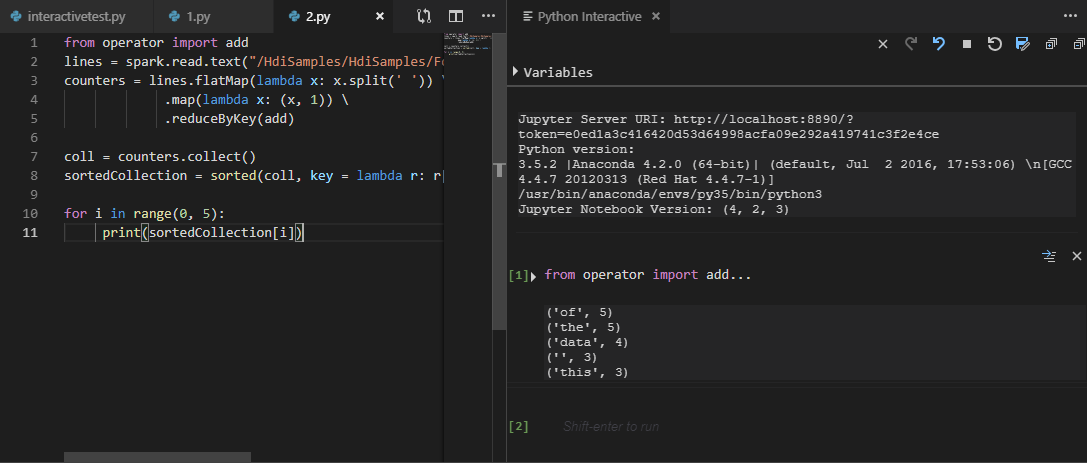
すべてのコードを選択してスクリプト エディターを右クリックし、 、[Spark: PySpark Interactive] を選択してクエリを送信するか、ショートカット Ctrl + Alt + I を使用します。
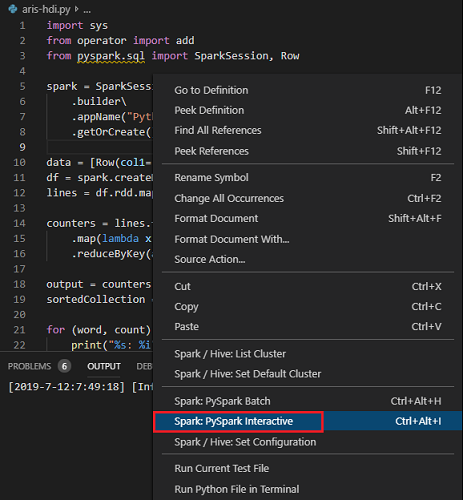
既定のクラスターを指定していない場合は、クラスターを選択します。 しばらくすると、Python Interactive の結果が新しいタブに表示されます。このツールでコンテキスト メニューを使用すると、スクリプト ファイル全体ではなくコード ブロックを送信することもできます。
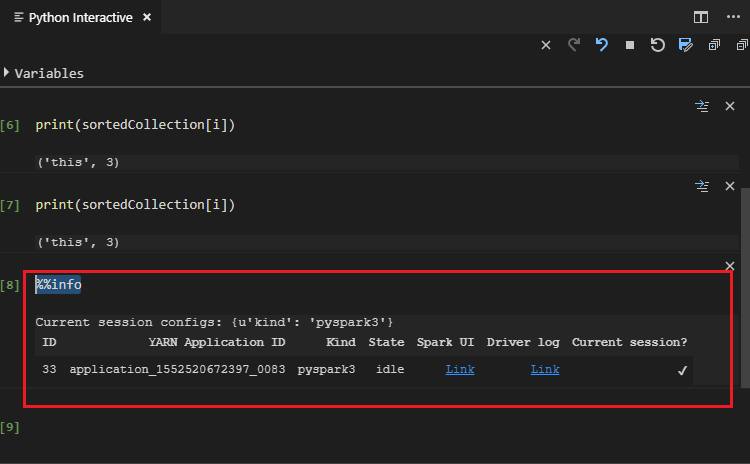
「%%Info」と入力し、Shift + Enter キーを押してジョブ情報を表示します。 (省略可能)
Note
設定で [Python Extension Enabled](Python 拡張機能が有効) がオフの場合 (既定の設定はオン)、送信される PySpark の対話結果には古いウィンドウが使用されます。
PySpark バッチ ジョブを送信する
前の手順で作成したフォルダー SQLBDCexample を閉じている場合は再び開きます。
以前の手順で作成した HelloWorld.py ファイルを選択し、スクリプト エディターで開きます。
クラスターをまだリンクしていない場合は、リンクします。
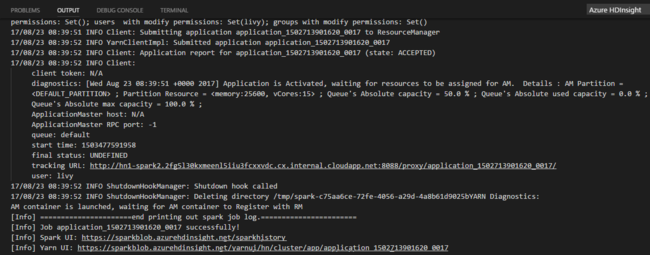
スクリプト エディターを右クリックして [Spark: PySpark Batch] を選択するか、ショートカット Ctrl + Alt + H を使用します。
既定のクラスターを指定していない場合は、クラスターを選択します。 Python ジョブを送信すると、Visual Studio Code の [OUTPUT](出力) ウィンドウに送信ログが表示されます。 Spark UI URL と Yarn UI URL も表示されます。 Web ブラウザーで URL を開いて、ジョブの状態を追跡することができます。
Apache Livy の構成
Apache Livy の構成はサポートされており、ワーク スペース フォルダーの .VSCode\settings.json で設定できます。 現在、Livy の構成では Python スクリプトのみがサポートされています。 詳細については、Livy の README を参照してください。
Livy の構成をトリガーする方法
方法 1
- メニュー バーから [File](ファイル)>[Preferences](基本設定)>[Settings](設定) に移動します。
- [Search settings](検索設定) テキスト ボックスに「HDInsight Job Submission: Livy Conf」と入力します。
- 関連する検索結果に対して [Edit in settings.json](settings.json で編集) を選択します。
方法 2
ファイルを送信すると、.vscode フォルダーが自動的に作業フォルダーに追加されることがわかります。 Livy の構成を確認するには、.vscode の下の settings.json を選択します。
プロジェクトの設定:
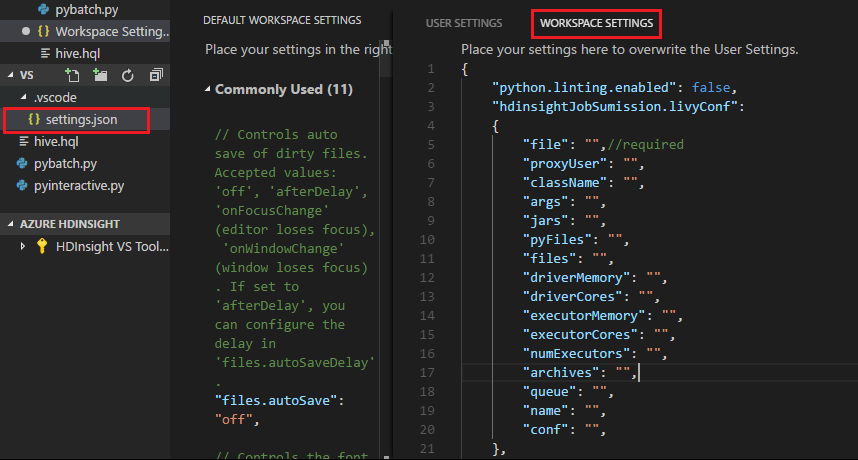
Note
設定の driverMemory と executorMemory について、値を単位付きで設定します (たとえば、1gb、1024mb など)。
サポートされている Livy の構成
POST /batches
要求本文
| name | description | type |
|---|---|---|
| file | 実行するアプリケーションを含むファイル | パス (必須) |
| proxyUser | ジョブの実行時に権限を借用するユーザー | string |
| className | アプリケーション Java/Spark のメイン クラス | string |
| args | アプリケーションのコマンド ライン引数 | 文字列のリスト |
| jars | このセッションで使用される Jar | 文字列の一覧 |
| pyFiles | このセッションで使用される Python ファイル | 文字列の一覧 |
| files | このセッションで使用されるファイル | 文字列の一覧 |
| driverMemory | ドライバー プロセスに使用するメモリの量 | string |
| driverCores | ドライバー プロセスに使用するコアの数 | INT |
| executorMemory | 実行プログラム プロセスごとに使用するメモリの量 | string |
| executorCores | 実行プログラムごとに使用するコアの数 | INT |
| numExecutors | このセッションで起動する実行プログラムの数 | INT |
| archives | このセッションで使用するアーカイブ | 文字列の一覧 |
| queue | 送信先の YARN キューの名前 | string |
| name | このセッションの名前 | string |
| conf | Spark の構成プロパティ | キーのマップ = val |
| $ | $ | $ |
応答本文
作成されるバッチ オブジェクト。
| name | description | type |
|---|---|---|
| id | セッション ID | INT |
| appId | このセッションのアプリケーション ID | String |
| appInfo | アプリケーションの詳細情報 | キーのマップ = val |
| log | ログの行 | 文字列のリスト |
| state | バッチの状態 | string |
| $ | $ | $ |
Note
割り当てられた Livy の構成は、スクリプトの送信時に出力ウィンドウに表示されます。
その他の機能
Spark & Hive for Visual Studio Code は次の機能をサポートしています。
IntelliSense のオートコンプリート。 キーワード、メソッド、変数などの候補がポップアップ表示されます。 さまざまな種類のオブジェクトを表すさまざまなアイコン。
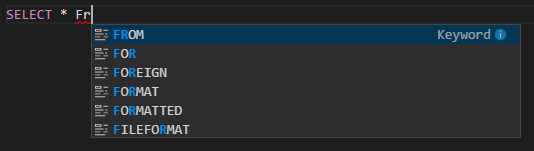
IntelliSense エラー マーカー。 言語サービスによって、Hive スクリプトの編集エラーに下線が引かれます。
構文の強調表示。 言語サービスでは、変数、キーワード、データ型、関数などを区別するためにさまざまな色が使用されます。
クラスターのリンク解除
メニュー バーから、 [表示]>[コマンド パレット] の順に移動し、「Spark / Hive: Unlink a Cluster」と入力します。
リンクを解除するクラスターを選択します。
[OUTPUT](出力) ビューを確認します。
次の手順
SQL Server ビッグ データ クラスターと関連するシナリオの詳細については、「SQL Server ビッグ データ クラスター」を参照してください。