Always On 可用性グループとは
適用対象: ![]() SQL Server
SQL Server
この記事では、Always On 可用性グループの概念について説明します。これは、SQL Server の Enterprise Edition での 1 つ以上の可用性グループの構成と管理において重要です。 Standard Edition については、「単一データベース用基本的な Always On 可用性グループ」を参照してください。
Always On 可用性グループ 機能は、データベース ミラーリングに代わる、高可用性と災害復旧のためのエンタープライズ レベルのソリューションです。 Always On 可用性グループを使用すると、エンタープライズのユーザー データベース セットの可用性が最大限に高まります。 可用性グループ は、 可用性データベースとして知られる、ひとまとまりでフェールオーバーされる個別のユーザー データベースのセットのためのフェールオーバー環境をサポートします。 可用性グループは、読み取り/書き込みプライマリ データベースのセットをサポートし、1 ~ 8 セットの対応するセカンダリ データベースをサポートします。 必要に応じて、セカンダリ データベースで読み取り専用アクセスまたはいくつかのバックアップ操作を利用できます。
Azure Arc によって有効化された SQL Serverを使用すると、Azure portal で可用性グループを表示できます。
概要
可用性グループは、可用性データベースとして知られる、個別のユーザー データベース セットのための複製環境をサポートします。 高可用性 (HA) または読み取りスケールの可用性グループを作成できます。 HA グループは、共にフェールオーバーするデータベースのグループです。 読み取りスケール可用性グループは、読み取り専用ワークロードのために、SQL Server の他のインスタンスにコピーされるデータベースのグループです。 可用性グループは、プライマリ データベースの 1 セットをサポートし、1 ~ 8 セットの対応するセカンダリ データベースをサポートします。 セカンダリ データベースはバックアップではありません。 継続してデータベースおよびそのトランザクション ログを定期的にバックアップします。
ヒント
プライマリ データベースのバックアップの種類を作成できます。 または、セカンダリ データベースのログ バックアップとコピーのみの完全バックアップを作成できます。 詳細については、「可用性グループのセカンダリ レプリカにサポートされているバックアップをオフロードする」を参照してください。
可用性データベースの各セットは、可用性レプリカによりホストされます。 可用性レプリカには2 種類あります。プライマリ データベースをホストしている単一のプライマリ レプリカと、それぞれがセカンダリ データベースのセットをホストし、可用性グループの潜在的なフェールオーバー ターゲットとして機能する 1~8 つの セカンダリ レプリカです。 可用性グループは、可用性レプリカのレベルでフェールオーバーします。 可用性レプリカでは、1 つの可用性グループ内のデータベースのセットに対してデータセット レベルでのみ冗長性が提供されます。 データベースの問題点 (たとえば、データ ファイルの損失やトランザクション ログの破損による障害が疑われる場合など) が発生してもフェールオーバーは行われません。
プライマリ レプリカは、クライアントからプライマリ データベースへの読み取り/書き込み接続を可能にします。 プライマリ レプリカは、各プライマリ データベースのトランザクション ログ レコードをすべてのセカンダリ データベースに送信します。 データの同期と呼ばれているこのプロセスはデータベース レベルで行われます。 すべてのセカンダリ レプリカは、トランザクション ログ レコードをキャッシュし (ログの書き込み )、それを対応するセカンダリ データベースに適用します。 データの同期は、プライマリ データベースと接続されているそれぞれのセカンダリ データベースとの間で、他のデータベースとは無関係に発生します。 したがって、セカンダリ データベースの中断や障害が発生した場合でも他のセカンダリ データベースはその影響を受けません。また、プライマリ データベースの中断や障害が発生した場合でも他のプライマリ データベースはその影響を受けません。
必要に応じて、1 つ以上のセカンダリ レプリカでセカンダリ データベースへの読み取り専用アクセスをサポートするように構成できます。また、任意のセカンダリ レプリカでセカンダリ データベースのバックアップを許容するように構成できます。
SQL Server 2017 では、可用性グループのために 2 つの異なるアーキテクチャが導入されました。 Always On 可用性グループは、高可用性、ディザスター リカバリー、読み取りスケール分散を提供します。 これらの可用性グループでは、クラスター マネージャーが必要です。 Windows では、フェールオーバー クラスタリング機能によってクラスター マネージャーが提供されます。 Linux では、Pacemaker を使用できます。 その他のアーキテクチャは読み取りスケール可用性グループです。 読み取りスケール可用性グループは、読み取り専用ワークロードのためのレプリカを提供しますが、高可用性は提供しません。 読み取りスケール可用性グループには、フェールオーバーを自動にできないので、クラスター マネージャーがありません。
Windows の HA のために Always On 可用性グループを配置するには、Windows Server フェールオーバー クラスター (WSFC) が必要です。 指定された可用性グループの各可用性レプリカは、同一の WSFC の異なるノード上に存在する必要があります。 唯一の例外は、別の WSFC クラスターに移行するときに、可用性グループは一時的に 2 つのクラスターにまたがることができるという点です。
Note
Linux の可用性グループについては、「SQL Server on Linux の可用性グループ」を参照してください。
HA 構成では、作成されたすべての可用性グループに対してクラスター ロールが作成されます。 WSFC クラスターは、このロールを監視し、プライマリ レプリカの正常性を評価します。 Always On 可用性グループ のクォーラムは、クラスター ノードが可用性レプリカをホストしているかどうかに関係なく、WSFC クラスター内のすべてのノードに基づきます。 データベース ミラーリングとは異なり、Always On 可用性グループには監視ロールはありません。
Note
SQL Server Always On コンポーネントと WSFC クラスターとの関係については、「Windows Server フェールオーバー クラスタリングと SQL Server」をご覧ください。
次の図は、1 つのプライマリ レプリカと 4 つのセカンダリ レプリカを含む可用性グループを示しています。 最大 8 つのセカンダリ レプリカ (1 つのプライマリ レプリカと 4 つの同期コミット セカンダリ レプリカを含む) がサポートされています。
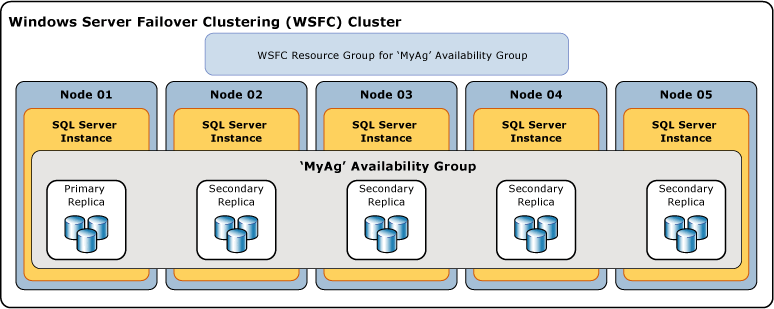
用語と定義
| Term | 説明 |
|---|---|
| 可用性グループ | ひとまとまりでフェールオーバーされるデータベースのセット ( 可用性データベース) のコンテナー。 |
| 可用性データベース | 可用性グループに属しているデータベース。 可用性データベースごとに、可用性グループは 1 個の読み取り/書き込み可能なコピー ( プライマリ データベース) と 1 ~ 8 個の読み取り専用コピー (セカンダリ データベース) を管理します。 |
| プライマリ データベース | 可用性データベースの読み取り/書き込み可能なコピー。 |
| セカンダリ データベース | 可用性データベースの読み取り専用コピー。 |
| 可用性レプリカ | 可用性グループのインスタンス化。 SQL Server の特定のインスタンスによってホストされ、可用性グループに属する各可用性データベースのローカル コピーを保持します。 可用性グループには、2 種類の可用性レプリカ ( プライマリ レプリカ と 1 ~ 8 個の セカンダリ レプリカ) があります。 |
| プライマリ レプリカ | クライアントからプライマリ データベースへの読み取り/書き込み接続を可能にし、各プライマリ データベースのトランザクション ログ レコードをすべてのセカンダリ レプリカに送信する可用性レプリカ。 |
| セカンダリ レプリカ | 各可用性データベースのセカンダリ コピーを保持し、可用性グループの潜在的なフェールオーバー ターゲットとして機能する可用性レプリカ。 必要に応じて、セカンダリ レプリカは、セカンダリ データベースへの読み取り専用アクセスと、セカンダリ データベース上でのバックアップの作成をサポートできます。 |
| 可用性グループ リスナー | 可用性グループのプライマリ レプリカまたはセカンダリ レプリカ内のデータベースにアクセスするためにクライアントが接続できるサーバー名。 可用性グループ リスナーは、プライマリ レプリカまたは読み取り専用セカンダリ レプリカに着信接続をダイレクトします。 |
可用性データベース
可用性グループに追加するデータベースは、オンラインの読み取り/書き込みデータベースであることが必要であり、プライマリ レプリカをホストするサーバー インスタンスに置かれている必要があります。 追加されたデータベースは、プライマリ データベースとして可用性グループに参加しますが、引き続きクライアントから使用できます。 新しいプライマリ データベースのバックアップが、セカンダリ レプリカをホストするサーバー インスタンスに復元されない限り (RESTORE WITH NORECOVERY を使用します)、対応するセカンダリ データベースは存在しません。 新しいセカンダリ データベースは、可用性グループに参加するまでは RESTORING 状態です。 詳細については、「AlwaysOn セカンダリ データベース上のデータ移動の開始 (SQL Server)」を参照してください。
可用性グループに参加すると、セカンダリ データベースは ONLINE 状態になり、対応するプライマリ データベースとのデータ同期が開始されます。 データ同期 は、プライマリ データベースへの変更をセカンダリ データベースに再現するプロセスです。 データ同期では、プライマリ データベースがトランザクション ログ レコードをセカンダリ データベースに送信します。
重要
可用性データベースは、Transact-SQL、PowerShell、および SQL Server 管理オブジェクト (SMO) の名前では、"データベース レプリカ" と呼ばれることがあります。 たとえば、可用性データベースに関する情報を返す Always On 動的管理ビューの名前では、sys.dm_hadr_database_replica_states"データベース レプリカ (database replica)" という語が使用されています。sys.dm_hadr_database_replica_cluster_states と 。 ただし、SQL Server オンライン ブックでは、"レプリカ" という用語は一般に可用性レプリカを指します。 たとえば、"プライマリ レプリカ" と "セカンダリ レプリカ" は、常に可用性レプリカを指します。
可用性レプリカ
各可用性グループは、可用性レプリカと呼ばれる 2 つ以上のフェールオーバー パートナーを定義します。 可用性レプリカ は、可用性グループのコンポーネントです。 各可用性レプリカは、可用性グループ内の可用性データベースのコピーをホストします。 各可用性グループで、個々の可用性レプリカは、1 つの WSFC クラスターの別々のノード上に存在する SQL Server の個々のインスタンスによってホストされる必要があります。 これらのサーバー インスタンスそれぞれで、AlwaysOn を有効にする必要があります。
SQL Server 2019 (15.x) では 3 つであった同期レプリカの最大数が、SQL Server 2017 (14.x) では 5 つに増加します。 この 5 つのレプリカのグループを、グループ内で自動フェールオーバーするように構成できます。 1 つのプライマリ レプリカと、4 つの同期セカンダリ レプリカがあります。
指定したインスタンスで、1 つの可用性グループにつき 1 つだけ可用性レプリカをホストすることができます。 ただし、各インスタンスを多数の可用性グループに使用することはできます。 指定したインスタンスは、スタンドアロン インスタンスまたは SQL Server フェールオーバー クラスター インスタンス (FCI) として使用できます。 サーバー レベルの冗長性が必要な場合は、フェールオーバー クラスター インスタンスを使用します。
すべての可用性レプリカには、初期ロールとして、プライマリ ロールまたはセカンダリ ロールが割り当てられています。これが、レプリカの可用性データベースによって継承されます。 指定されたレプリカのロールにより、読み取り/書き込みデータベースと読み取り専用のデータベースのどちらがホストされるかが決定されます。 プライマリ レプリカと呼ばれる 1 つのレプリカには、プライマリ ロールが割り当てられ、 プライマリ データベースと呼ばれる読み取り/書き込みデータベースをホストします。 それ以外の 1 つ以上のレプリカは セカンダリ レプリカと呼ばれ、セカンダリ ロールが割り当てられます。 セカンダリ レプリカは、セカンダリ データベースと呼ばれる読み取り専用のデータベースをホストします。
Note
フェールオーバー中など、可用性レプリカのロールが不確定である場合、そのデータベースは一時的に NOT SYNCHRONIZING 状態になります。 可用性レプリカのロールが解決されるまで、それらのロールは RESOLVING に設定されます。 可用性レプリカがプライマリ ロールに解決された場合、そのデータベースはプライマリ データベースになります。 可用性レプリカがセカンダリ ロールに解決された場合、そのデータベースはセカンダリ データベースになります。
可用性モード
可用性モードは、各可用性レプリカのプロパティです。 可用性モードによって、特定のセカンダリ レプリカがディスクにトランザクション ログ レコードを書き込む (ログ書き込み) まで、プライマリ レプリカによるデータベースへのトランザクションのコミットを待機するかどうかが決定されます。 Always On 可用性グループでは、非同期コミット モードと同期コミット モードの 2 種類の可用性モードがサポートされます。
Asynchronous-commit mode
この可用性モードを使用する可用性レプリカは、非同期コミット レプリカと呼ばれます。 非同期コミット モードでは、非同期コミット セカンダリ レプリカからのトランザクション ログの書き込みの確認応答を待機せずに、プライマリ レプリカがトランザクションをコミットします。 非同期コミット モードでは、セカンダリ データベースでのトランザクションの遅延が最小になりますが、セカンダリ データベースがプライマリ データベースよりも遅延する場合があるため、一部のデータが失われる可能性があります。
Synchronous-commit mode
この可用性モードを使用する可用性レプリカは、 同期コミット レプリカと呼ばれます。 同期コミット モードの場合、同期コミット プライマリ レプリカは、同期コミット セカンダリ レプリカによるログ書き込みが確認されるまで待機した後で、トランザクションをコミットします。 同期コミット モードでは、特定のセカンダリ データベースがプライマリ データベースに 1 回同期されれば、コミットされたトランザクションが完全に保護されることが保証されます。 この保護の欠点は、トランザクションの遅延が増加することです。 必要に応じて、SQL Server 2017 では 必須の同期されたセカンダリ 機能が導入されており、待ち時間を犠牲にして安全性をさらに高めることができます。 REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT 機能を有効にすると、プライマリ レプリカによるコミットが許可される前に、指定した数の同期レプリカがトランザクションをコミットするように要求できます。
詳細については、「Always On 可用性グループの可用性モードの違い」を参照してください。
フェールオーバーの種類
プライマリ レプリカとセカンダリ レプリカとのセッションのコンテキスト内で、プライマリ ロールとセカンダリ ロールが フェールオーバーと呼ばれるプロセスで交換されることがあります。 フェールオーバー中に、対象のセカンダリ レプリカがプライマリ ロールに移行し、新しいプライマリ レプリカになります。 新しいプライマリ レプリカのデータベースがプライマリ データベースとしてオンラインになります。クライアント アプリケーションから、これらのデータベースに接続できるようになります。 元のプライマリ レプリカは使用可能になるとセカンダリ ロールに移行し、セカンダリ レプリカになります 元のプライマリ データベースはセカンダリ データベースになり、データ同期が再開されます。
可用性グループは、可用性レプリカのレベルでフェールオーバーします。 データベースの問題点 (たとえば、データ ファイルの損失、データベースの削除、トランザクション ログの破損による障害が疑われる場合など) が発生してもフェールオーバーは行われません。
フェールオーバーには、自動、手動、および強制 (データ損失の可能性あり) という 3 つの形式があります。 特定のセカンダリ レプリカでサポートされるフェールオーバーの形式は、可用性モードによって決まります。同期コミット モードでは、プライマリ レプリカのフェールオーバー モードおよび対象のセカンダリ レプリカによって決まります。次に例を示します。
同期コミット モードでは、対象のセカンダリ レプリカが現在、プライマリ レプリカと同期されている場合、計画的な手動フェールオーバー と自動フェールオーバー という 2 つの形式のフェールオーバーがサポートされます。 これらのフェールオーバーの形式のサポートは、フェールオーバー パートナーの フェールオーバー モード プロパティ の設定によって決まります。 プライマリ レプリカとセカンダリ レプリカのどちらかのフェールオーバー モードが "手動" に設定されている場合、そのセカンダリ レプリカに対しては手動フェールオーバーのみがサポートされます。 プライマリ レプリカとセカンダリ レプリカのどちらのフェールオーバー モードも "自動" に設定されている場合、そのセカンダリ レプリカでは自動フェールオーバーと手動フェールオーバーの両方がサポートされます。
計画的な手動フェールオーバー (データ損失なし)
データベース管理者がフェールオーバー コマンドを発行した後に手動フェールオーバーが開始され、同期されたセカンダリ レプリカがプライマリ ロールに移行し (データ保護の保証あり)、プライマリ レプリカはセカンダリ ロールに移行します。 手動フェールオーバーには、プライマリ レプリカと対象のセカンダリ レプリカの両方が同期コミット モードで実行されていることが必要です。また、セカンダリ レプリカが既に同期されている必要があります。
自動フェールオーバー (データ損失なし)
エラーが発生すると、自動フェールオーバーが開始されて、同期されたセカンダリ レプリカがプライマリ ロールに移行します (データ保護が保証されます)。 元のプライマリ レプリカは、使用可能になるとセカンダリ ロールに移行します。 自動フェールオーバーでは、プライマリ レプリカと対象のセカンダリ レプリカの両方が同期コミット モードで実行されている必要があります。また、フェールオーバー モードが自動に設定されている必要があります。 さらに、セカンダリ レプリカが既に同期されており、WSFC クォーラムを持っていることに加え、可用性グループの柔軟なフェールオーバー ポリシーで指定された条件を満たしている必要があります。
非同期コミット モードで使用されるフェールオーバーは、 強制フェールオーバーと通常呼ばれる強制手動フェールオーバーのみです (データ損失の可能性あり)。 強制フェールオーバーは手動のみで開始できるため、手動フェールオーバーの一種と見なされます。 強制フェールオーバーは、障害復旧オプションです。 ターゲットのセカンダリ レプリカがプライマリ レプリカに同期されない場合に使用できる唯一のフェールオーバーフォームです。
詳しくは、「フェールオーバーとフェールオーバー モード (Always On 可用性グループ)」をご覧ください。
重要
- SQL Server フェールオーバー クラスター インスタンス (FCI) は可用性グループによる自動フェールオーバーをサポートしないため、FCI によってホストされる可用性レプリカは手動フェールオーバー用にのみ構成できます。
- 同期されたセカンダリ レプリカ上で強制フェールオーバー コマンドを発行した場合、セカンダリ レプリカは計画的な手動フェールオーバーの場合と同様に動作します。
メリット
Always On 可用性グループには、データベースの可用性を向上し、リソースの使用を改善する、豊富なオプションのセットが用意されています。 主なコンポーネントは次のとおりです。
最大 9 つの可用性レプリカをサポートします。 可用性グループ は、SQL Server の特定のインスタンスによってホストされ、可用性グループに属する各可用性データベースのローカル コピーを保持します。 各可用性グループは、1 個のプライマリ レプリカと最大 8 個のセカンダリ レプリカをサポートします。 詳細については、「Always On 可用性グループとは」を参照してください。
重要
各可用性レプリカは、単一の Windows Server フェールオーバー クラスタリング (WSFC) クラスターの異なるノード上に存在する必要があります。 可用性グループの前提条件、制限事項、推奨事項の詳細については、「Always On 可用性グループの前提条件、制限事項、推奨事項」を参照してください。
次の選択可能な可用性モードをサポートします。
非同期コミット モード。 この可用性モードは、距離を隔てて可用性レプリカが分散されている場合に効果的な災害復旧ソリューションです。
同期コミット モード。 この可用性モードは、パフォーマンスよりも高可用性とデータ保護が重視され、トランザクションの遅延が増加するのが欠点です。 1 つの可用性グループで、現在のプライマリ レプリカを含む、最大 5 つの同期コミット可用性レプリカをサポートできます。
詳細については、「Always On 可用性グループの可用性モードの違い」を参照してください。
自動フェールオーバー、計画的な手動フェールオーバー (通常は単に "手動フェールオーバー" と呼ばれます)、および強制手動フェールオーバー (通常は単に "強制フェールオーバー" と呼ばれます) の複数の形式の可用性グループ フェールオーバーをサポートします。 詳しくは、「フェールオーバーとフェールオーバー モード (Always On 可用性グループ)」をご覧ください。
次のアクティブ セカンダリ機能の一方または両方をサポートするように指定された可用性レプリカを構成できます。
セカンダリ レプリカとして実行中に、レプリカへの読み取り専用接続でそのデータベースにアクセスして読み取りができる読み取り専用接続アクセス。 詳細については、「Always On 可用性グループのセカンダリ レプリカに読み取り専用の負荷を移す」を参照してください。
セカンダリ レプリカとして動作中に、そのデータベース上でバックアップ操作を実行します。 詳細については、「可用性グループのセカンダリ レプリカにサポートされているバックアップをオフロードする」を参照してください。
アクティブ セカンダリ機能を使用して、セカンダリ ハードウェアのリソース使用効率を高めることで、IT の効率性を改善し、コストを低減できます。 また、読み取りを目的としたアプリケーションやバックアップ ジョブをセカンダリ レプリカへとオフロードすることで、プライマリ レプリカのパフォーマンスを改善できます。
可用性グループごとに 1 つの可用性グループ リスナーをサポートします。 可用性グループ リスナー は、Always On 可用性グループのプライマリ レプリカまたはセカンダリ レプリカ内のデータベースにアクセスするためにクライアントが接続できるサーバー名です。 可用性グループ リスナーは、プライマリ レプリカまたは読み取り専用セカンダリ レプリカに着信接続をダイレクトします。 リスナーは、可用性グループがフェールオーバーした後のアプリケーション フェールオーバーを高速化します。 詳しくは、「Always On 可用性グループ リスナーに接続する」を参照してください。
可用性グループのフェールオーバーを細かく制御する柔軟なフェールオーバー ポリシーをサポートします。 詳しくは、「フェールオーバーとフェールオーバー モード (Always On 可用性グループ)」をご覧ください。
ページ破損に対する保護機能を提供する自動ページ修復をサポートします。 詳細については、このトピックの「ページの自動修復 (可用性グループ: データベース ミラーリング)」を参照してください。
安全性とパフォーマンスに優れたトランスポートを実現する、暗号化機能と圧縮機能をサポートします。
可用性グループの展開と管理を簡単にするツールの統合セットが用意されています。これには次のツールが含まれます。
可用性グループの作成と管理のための Transact-SQL DDL ステートメント。 詳しくは、「Always On 可用性グループの Transact-SQL ステートメント」を参照してください。
SQL Server Management Studio ツール。
新しい可用性グループ ウィザード では、可用性グループの作成と構成を行います。 一部の環境では、このウィザードで、セカンダリ データベースを自動的に準備し、それらの各データベースに対するデータ同期を開始することもできます。 詳細については、「新しい可用性グループ ダイアログ ボックスの使用 (SQL Server Management Studio)」を参照してください。
可用性グループへのデータベース追加ウィザードでは、既存の可用性グループに 1 つ以上のプライマリ データベースを追加できます。 一部の環境では、このウィザードで、セカンダリ データベースを自動的に準備し、それらの各データベースに対するデータ同期を開始することもできます。 詳しくは、「可用性グループ ウィザードを使用して Always On 可用性グループにデータベースを追加するv」を参照してください。
可用性グループへのレプリカ追加ウィザード では、既存の可用性グループに 1 つ以上のセカンダリ レプリカを追加できます。 一部の環境では、このウィザードで、セカンダリ データベースを自動的に準備し、それらの各データベースに対するデータ同期を開始することもできます。 詳しくは、「SQL Server Management で可用性グループ ウィザードを使用し、Always On 可用性グループにレプリカを追加する」を参照してください。
可用性グループのフェールオーバー ウィザードでは、可用性グループに対して手動のフェールオーバーを開始できます。 フェールオーバーのターゲットとして指定するセカンダリ レプリカの構成と状態によっては、このウィザードで計画的または強制的な手動フェールオーバーを実行することもできます。 詳細については、「可用性グループのフェールオーバー ウィザードの使用 (SQL Server Management Studio)」を参照してください。
Always On 可用性グループ、可用性レプリカ、および可用性データベースを監視し、Always On ポリシーの結果を評価する Always On ダッシュボード。 詳しくは、「Always On 可用性グループ ダッシュボードの使用 (SQL Server Management Studio)」を参照してください。
既存の可用性グループに関する基本情報を表示する、[オブジェクト エクスプローラーの詳細] ペイン。 詳しくは、「[オブジェクト エクスプローラーの詳細] を使用した可用性グループの監視」を参照してください。
PowerShell コマンドレット。 詳しくは、「Always On 可用性グループの PowerShell コマンドレットの概要 (SQL Server)」を参照してください。
クライアント接続
可用性グループ リスナーを作成することによって、特定の可用性グループのプライマリ レプリカへのクライアント接続を提供できます。 可用性グループ リスナー には、クライアント接続を適切な可用性レプリカに送るために特定の可用性グループにアタッチされる一連のリソースが用意されています。
可用性グループ リスナーは、仮想ネットワーク名 (VNN) として機能する一意の DNS 名、1 つ以上の仮想 IP アドレス (VIP)、および TCP ポート番号に関連付けられています。 詳しくは、「Always On 可用性グループ リスナーに接続する」を参照してください。
ヒント
可用性グループに 2 つしか可用性レプリカが存在せず、なおかつ、その可用性グループが、セカンダリ レプリカへの読み取りアクセスを許可する設定になっていない場合、クライアントは、データベース ミラーリングの接続文字列を使用してプライマリ レプリカに接続できます。 この方法は、データベースをデータベース ミラーリングから Always On 可用性グループに移行した後で、一時的に役に立つ場合があります。 他のセカンダリ レプリカを追加する前に、可用性グループの可用性グループ リスナーを作成し、そのリスナーのネットワーク名を使用するようにアプリケーションを更新する必要があります。
アクティブなセカンダリ レプリカ
Always On 可用性グループでは、アクティブなセカンダリ レプリカがサポートされます。 アクティブなセカンダリ機能では以下をサポートしています。
セカンダリ レプリカでのバックアップ操作の実行
セカンダリ レプリカでは、ログ バックアップと、データベース全体、ファイル、またはファイル グループの コピーのみの バックアップを実行できます。 可用性グループを構成して、バックアップを実行する優先順位を指定できます。 優先順位は SQL Server によって適用されるものではないので、アドホック バックアップには影響がないことを理解しておくことが重要です。 この優先順位の解釈は、特定の可用性グループの各データベースに対するバックアップ ジョブのスクリプトでのロジックに依存します (ある場合)。 同じ可用性グループ内の個々の可用性レプリカで実行されるバックアップの優先順位を指定できます。 詳細については、「可用性グループのセカンダリ レプリカにサポートされているバックアップをオフロードする」を参照してください。
1 つ以上のセカンダリ レプリカへの読み取り専用アクセス (読み取り可能なセカンダリ レプリカ)
ローカル データベースへの読み取り専用アクセスのみを許可するようにセカンダリ可用性レプリカを構成できます (ただし、一部の操作は完全にはサポートされていません)。 これにより、セカンダリ レプリカへの読み取り/書き込み接続を試行できなくなります。 読み取り/書き込みアクセスのみを許可することで、プライマリ レプリカに対する読み取り専用ワークロードを防止することもできます。 これにより、プライマリ レプリカに対して読み取り専用接続が行われません。 詳細については、「Always On 可用性グループのセカンダリ レプリカに読み取り専用の負荷を移す」を参照してください。
可用性グループに、現在、可用性グループ リスナーと 1 つ以上の読み取り可能なセカンダリ レプリカが存在する場合、SQL Server では読み取りを目的とした接続要求をそれらのいずれかにルーティングできます (読み取り専用ルーティング)。 詳しくは、「Always On 可用性グループ リスナーに接続する」を参照してください。
セッション タイムアウト期間
セッション タイムアウト期間は、可用性レプリカのプロパティで、他の可用性レプリカとの接続を閉じるまでに非アクティブに保持できる時間を決定します。 プライマリ レプリカとセカンダリ レプリカは、アクティブであることを通知するために互いに ping を実行します。 他のレプリカからタイムアウト期間内に ping を受信した場合は、その接続がまだ開いており、サーバー インスタンスが通信していることを示します。 可用性レプリカは、ping を受信すると、接続のセッション タイムアウト カウンターをリセットします。
セッション タイムアウト期間を設定することにより、相手レプリカからの ping を受信するまで無期限に待機することがなくなります。 セッション タイムアウト期間中に相手のレプリカから ping を受信しなかった場合、レプリカはタイムアウトします。レプリカの接続は閉じられ、タイムアウトしたレプリカは DISCONNECTED 状態になります。 切断されたレプリカが同期コミット モード用に構成されている場合でも、トランザクションはそのレプリカが再接続および再同期するまでは待機しません。
各可用性レプリカの既定のセッション タイムアウト期間は 10 秒です。 この値はユーザーが構成でき、最小値は 5 秒です。 通常は、タイムアウト期間を 10 秒以上にしておくことをお勧めします。 値を 10 秒未満に設定すると、負荷の高いシステムで誤認エラーが示される可能性があります。
Note
解決中のロールでは、ping が発生しないため、セッション タイムアウト期間は適用されません。
ページの自動修復
各可用性レプリカでは、ローカル データベースに破損ページがあると、データ ページの読み取りを妨げるエラーを解決して自動的に復旧しようとします。 セカンダリ レプリカがページを読み取ることができない場合、プライマリ レプリカに対してページの新しいコピーを要求します。 プライマリ レプリカがページを読み取ることができない場合、すべてのセカンダリ レプリカに新しいコピーの要求をブロードキャストし、最初に応答したレプリカからページを取得します。 要求が受け入れられ、新しいコピーを取得できた場合は、読み取り不可能なページがそのコピーに置き換えられます。通常、これによりエラーは解決します。
詳細については、このトピックの「ページの自動修復 (可用性グループ: データベース ミラーリング)」を参照してください。
その他のデータベース エンジン機能との相互運用性と共存
Always On 可用性グループ は、SQL Serverの次の機能またはコンポーネントと共に使用できます。
- 変更データ キャプチャ (CDC) とは
- 変更の追跡について (SQL Server)
- 包含データベース
- 透過的なデータ暗号化 (TDE)
- AlwaysOn 可用性グループを含むデータベース スナップショット (SQL Server)
- FILESTREAM (SQL Server)
- FileTables (SQL Server)
- ログ配布情報 (SQL Server)
- リモート BLOB ストア (RBS) [SQL Server]
- SQL Server レプリケーション
- Service Broker
- SQL Server エージェント
- Reporting Services と Always On 可用性グループ (SQL Server)
関連タスク
- Always On 可用性グループの前提条件、制限事項、推奨事項
- Always On 可用性グループの作成と構成の参照
- 可用性グループの管理
- Always On 可用性グループを監視するツール
- Always On 可用性グループのセカンダリ レプリカに読み取り専用の負荷を移す
- 可用性グループのセカンダリ レプリカにサポートされているバックアップをオフロードする
- Always On 可用性グループ リスナーに接続する
- Always On 可用性グループの Transact-SQL ステートメント
- Always On 可用性グループの PowerShell コマンドレットの概要
- SQL Server サポート ブログ - 高可用性
- SQL Server ブログ - SQL Server Always On
- アーカイブ: SQL Server Always On チームのブログ: SQL Server Always On チームのオフィシャル ブログ
- アーカイブ: CSS SQL Server エンジニアのブログ
- 高可用性と災害復旧のための Microsoft SQL Server AlwaysOn ソリューション ガイド