SQL Server の RHEL フェールオーバー クラスター インスタンス (FCI) を運用する
適用対象: ![]() SQL Server - Linux
SQL Server - Linux
このドキュメントでは、Red Hat Enterprise Linux を使用した共有ディスク フェールオーバー クラスターで SQL Server に対する次のタスクを実行する方法について説明します。
- クラスターを手動でフェールオーバーする
- フェールオーバー クラスターの SQL Server サービスを監視する
- クラスター ノードを追加する
- クラスター ノードを削除する
- SQL Server のリソース監視頻度を変更する
アーキテクチャの説明
クラスタリング レイヤーは、Pacemaker の上に構築された Red Hat Enterprise Linux (RHEL) HA アドオンに基づいています。 Corosync と Pacemaker によって、クラスターの通信とリソース管理が調整されます。 SQL Server インスタンスは、一方のノードでのみアクティブになります。
次の図では、SQL Server が含まれる Linux クラスターのコンポーネントが示されています。
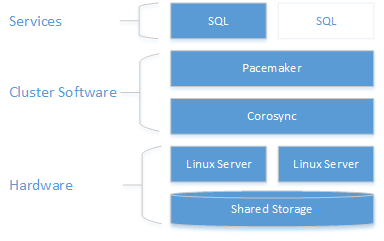
クラスター構成、リソース エージェント オプション、および管理の詳細については、RHEL リファレンス ドキュメントを参照してください。
クラスターを手動でフェールオーバーする
resource move コマンドでは、ターゲット ノードでリソースを強制的に開始する制約が作成されます。 move コマンドを実行した後、リソース clear を実行すると制約が削除されるため、リソースを再び移動したり、リソースを自動的にフェールオーバーさせたりできるようになります。
sudo pcs resource move <sqlResourceName> <targetNodeName>
sudo pcs resource clear <sqlResourceName>
次の例では、mssqlha リソースを sqlfcivm2 という名前のノードに移動した後、リソースが別のノードに移動できるように、制約を削除します。
sudo pcs resource move mssqlha sqlfcivm2
sudo pcs resource clear mssqlha
フェールオーバー クラスターの SQL Server サービスを監視する
クラスターの現在の状態を表示します。
sudo pcs status
クラスターとリソースのライブ状態を表示します。
sudo crm_mon
/var/log/cluster/corosync.log にあるリソース エージェント ログを表示します
クラスターにノードを追加する
各ノードの IP アドレスを確認します。 次のスクリプトを実行すると、現在のノードの IP アドレスが表示されます。
ip addr show新しいノードには、15 文字以下の一意の名前を指定する必要があります。 Red Hat Linux での既定のコンピューター名は
localhost.localdomainです。 この既定の名前は一意ではない可能性があり、長すぎます。 新しいノードにコンピューター名を設定します。 コンピューター名は/etc/hostsに追加することで設定します。 次のスクリプトを使うと、viで/etc/hostsを編集できます。sudo vi /etc/hosts次の例では、
sqlfcivm1、sqlfcivm2、sqlfcivm3という名前の 3 つのノードに対する追加が含まれる/etc/hostsを示します。127.0.0.1 localhost localhost4 localhost4.localdomain4 ::1 localhost localhost6 localhost6.localdomain6 10.128.18.128 fcivm1 10.128.16.77 fcivm2 10.128.14.26 fcivm3ファイルは、すべてのノードで同じである必要があります。
新しいノードで SQL Server サービスを停止します。
指示に従って、データベース ファイルのディレクトリを共有の場所にマウントします。
NFS サーバーから、
nfs-utilsをインストールしますsudo yum -y install nfs-utilsクライアントと NFS サーバーのファイアウォールを開きます
sudo firewall-cmd --permanent --add-service=nfs sudo firewall-cmd --permanent --add-service=mountd sudo firewall-cmd --permanent --add-service=rpc-bind sudo firewall-cmd --reload/etc/fstabファイルを編集して、mount コマンドを入れます。<IP OF NFS SERVER>:<shared_storage_path> <database_files_directory_path> nfs timeo=14,intrmount -aを実行して、変更を有効にします。新しいノードで、Pacemaker のログインのために SQL Server のユーザー名とパスワードを格納するファイルを作成します。 次のコマンドは、このファイルを作成および設定します。
sudo touch /var/opt/mssql/passwd sudo echo "<loginName>" >> /var/opt/mssql/secrets/passwd sudo echo "<loginPassword>" >> /var/opt/mssql/secrets/passwd sudo chown root:root /var/opt/mssql/passwd sudo chmod 600 /var/opt/mssql/passwd新しいノードで、Pacemaker のファイアウォール ポートを開きます。
firewalldを使用してこれらのポートを開くには、次のコマンドを実行します。sudo firewall-cmd --permanent --add-service=high-availability sudo firewall-cmd --reloadビルトインの高可用性構成が備わっていない別のファイアウォールを使用する場合は、Pacemaker がクラスター内の他のノードと通信できるように、次のポートを開く必要があります。
- TCP: ポート 2224、3121、21064
- UDP: ポート 5405
新しいノードに Pacemaker パッケージをインストールします。
sudo yum install pacemaker pcs fence-agents-all resource-agentsPacemaker と Corosync のパッケージをインストールしたときに作成された既定のユーザー用のパスワードを設定します。 既存のノードと同じパスワードを使います。
sudo passwd haclusterpcsdサービスと Pacemaker を有効にし、起動します。 これにより、再起動後に新しいノードはクラスターに再度参加できます。 新しいノードで次のコマンドを実行します。sudo systemctl enable pcsd sudo systemctl start pcsd sudo systemctl enable pacemakerSQL Server の FCI リソース エージェントをインストールします。 新しいノードで次のコマンドを実行します。
sudo yum install mssql-server-haクラスターの既存のノードで、新しいノードを認証し、クラスターに追加します。
sudo pcs cluster auth <nodeName3> -u hacluster sudo pcs cluster node add <nodeName3>次の例では、vm3 という名前のノードがクラスターに追加されます。
sudo pcs cluster auth sudo pcs cluster start
クラスターからノードを削除する
クラスターからノードを削除するには、次のコマンドを実行します。
sudo pcs cluster node remove <nodeName>
sqlservr リソースの監視間隔の頻度を変更する
sudo pcs resource op monitor interval=<interval>s <sqlResourceName>
次の例では、mssql リソースの監視間隔を 2 秒に設定しています。
sudo pcs resource op monitor interval=2s mssqlha
SQL Server 用の Red Hat Enterprise Linux 共有ディスク クラスターのトラブルシューティングを行う
クラスターのトラブルシューティングでは、3 つのデーモンの連携によってクラスター リソースが管理される方法を理解すると役に立ちます。
| デーモン | 説明 |
|---|---|
| Corosync | クラスター ノード間のクォーラム メンバーシップとメッセージングを提供します。 |
| Pacemaker | Corosync の上に存在し、リソースのステート マシンを提供します。 |
| PCSD | pcs ツールで Pacemaker と Corosync の両方を管理します。 |
pcs ツールを使うには、PCSD が実行されている必要があります。
クラスターの現在の状態
sudo pcs status では、各ノードのクラスター、クォーラム、ノード、リソース、デーモンの状態に関する基本情報が返されます。
Pacemaker での正常なクォーラムの出力の例を次に示します。
Cluster name: MyAppSQL
Last updated: Wed Oct 31 12:00:00 2016 Last change: Wed Oct 31 11:00:00 2016 by root via crm_resource on sqlvmnode1
Stack: corosync
Current DC: sqlvmnode1 (version 1.1.13-10.el7_2.4-44eb2dd) - partition with quorum
3 nodes and 1 resource configured
Online: [ sqlvmnode1 sqlvmnode2 sqlvmnode3 ]
Full list of resources:
mssqlha (ocf::sql:fci): Started sqlvmnode1
PCSD Status:
sqlvmnode1: Online
sqlvmnode2: Online
sqlvmnode3: Online
Daemon Status:
corosync: active/disabled
pacemaker: active/enabled
この例で、partition with quorum はノードの過半数のクォーラムがオンラインであることを意味します。 クラスターでノードの過半数のクォーラムが失われると、pcs status が partition WITHOUT quorum を返し、すべてのリソースが停止します。
online: [sqlvmnode1 sqlvmnode2 sqlvmnode3] では、クラスターに現在参加しているすべてのノードの名前が返されます。 参加していないノードがある場合は、pcs status は OFFLINE: [<nodename>] を返します。
PCSD Status では、各ノードのクラスターの状態が示されます。
ノードがオフラインになる理由
ノードがオフラインのときは、次の項目を確認してください。
ファイアウォール
Pacemaker が通信できるためには、すべてのノードで次のポートが開かれている必要があります。
- **TCP: 2224、3121、21064
Pacemaker または Corosync サービスが実行されていること
ノードの通信
ノード名のマッピング