SQL Server Machine Learning Services で Python 開発用のデータ サイエンス クライアントを設定する
適用対象: ![]() SQL Server 2016 (13.x)、
SQL Server 2016 (13.x)、![]() SQL Server 2017 (14.x)、
SQL Server 2017 (14.x)、![]() SQL Server 2019 (15.x)、
SQL Server 2019 (15.x)、![]() SQL Server 2019 (15.x) - Linux
SQL Server 2019 (15.x) - Linux
Machine Learning Services (データベース内) インストールに Python オプションを含めると、SQL Server 2017 以降で Python 統合を使用できます。
注意
現在、この記事は、SQL Server 2016 (13.x)、SQL Server 2017 (14.x)、SQL Server 2019 (15.x)、SQL Server 2019 (15.x) (Linux のみ) に適用されます。
SQL Server 用の Python ソリューションを開発して展開するには、Microsoft の revoscalepy およびその他の Python ライブラリを開発ワークステーションにインストールします。 リモート SQL Server インスタンス上にもある、revoscalepy ライブラリでは、両方のシステム間の計算要求を調整します。
この記事では、機械学習と Python 統合で有効になっているリモート SQL Server を操作できるように、Python 開発ワークステーションを構成する方法を学習します。 この記事の手順を完了すると、Python ライブラリは SQL Server のものと同じになります。 また、ローカル Python セッションから SQL Server のリモート Python セッションに計算をプッシュする方法がわかります。

インストールを確認するために、この記事で説明されている組み込みの Jupyter Notebook を使用するか、PyCharm または通常使用する他の IDE にライブラリをリンクすることができます。
ヒント
これらの演習のビデオ デモについては、Jupyter Notebook からの SQL Server での R および Python のリモート実行に関するビデオをご覧ください。
一般的に使用されるツール
SQL を初めて使用する Python 開発者であるか、Python とデータベース内分析を初めて利用する SQL 開発者であるかに関係なく、データベース内分析の機能をすべて実行するには、Python 開発ツールと T-SQL クエリ エディター (SQL Server Management Studio (SSMS) など) の両方が必要になります。
Python の開発では、Jupyter Notebook を使用できます。これは SQL Server によってインストールされる Anaconda ディストリビューションにバンドルされています。 この記事では、Jupyter Notebook を起動して、SQL Server で Python コードをローカルおよびリモートで実行できるようにする方法について説明します。
SSMS は個別にダウンロードします。これは、Python コードが含まれているものを含め、SQL Server でストアド プロシージャを作成および実行する場合に便利です。 Jupyter Notebook で記述するほとんどすべての Python コードは、ストアド プロシージャに埋め込むことができます。 他のクイックスタートをステップ実行し、SSMS と埋め込み Python について学習することができます。
1 - Python パッケージをインストールする
ローカル ワークステーションには、Python 3.5.2 ディストリビューションを使用する基本の Anaconda 4.2.0 を含む、SQL Server のものと同じバージョンの Python パッケージと、Microsoft 固有のパッケージが必要です。
インストール スクリプトによって、3 つの Microsoft 固有のライブラリが Python クライアントに追加されます。 スクリプトによって次がインストールされます。
- revoscalepy は、データ ソース オブジェクトとコンピューティング コンテキストを定義するために使用されます。
- 機械学習アルゴリズムを提供する microsoftml。
- azureml は、スタンドアロン サーバー コンテキストに関連付けられている操作化タスクに適用され、データベース内分析での使用が制限される場合があります。
インストール スクリプトをダウンロードします。 適切な次の GitHub ページで、[RAW ファイルのダウンロード] を選択します。
https://aka.ms/mls-py では、バージョン 9.2.1 の Microsoft Python パッケージがインストールされます。 このバージョンは、既定の SQL Server インスタンスに対応します。
https://aka.ms/mls93-py では、バージョン 9.3 の Microsoft Python パッケージがインストールされます。
特権を持つ管理者権限で PowerShell ウィンドウを開きます ([管理者として実行] を右クリックする)。
インストーラーをダウンロードしたフォルダーに移動し、スクリプトを実行します。
-InstallFolderコマンドライン引数を追加して、ライブラリのフォルダーの場所を指定します。 次に例を示します。cd {{download-directory}} .\Install-PyForMLS.ps1 -InstallFolder "C:\path-to-python-for-mls"
インストール フォルダーを省略した場合、既定値は %ProgramFiles%\Microsoft\PyForMLS です。
インストールの完了には時間がかかります。 進行状況は PowerShell ウィンドウで監視できます。 セットアップが完了すると、パッケージの完全なセットが作成されます。
ヒント
Windows 用の Python の FAQ が示されたページで、Windows での Python プログラムの実行に関する汎用情報を確認することをお勧めします。
2 - 実行可能ファイルの検索
引き続き PowerShell で、インストール フォルダーの内容をリストし、Python.exe、スクリプト、およびその他のパッケージがインストールされていることを確認します。
「
cd \」と入力してルート ドライブに移動してから、前の手順で-InstallFolderに指定したパスを入力します。 インストール中にこのパラメーターを省略した場合、既定値はcd %ProgramFiles%\Microsoft\PyForMLSとなります。「
dir *.exe」と入力して、実行可能ファイルをリストします。 python.exe、pythonw.exe、および uninstall-anaconda.exe が表示されるはずです。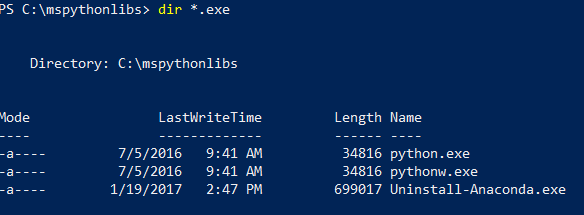
複数のバージョンの Python があるシステムで、revoscalepy やその他の Microsoft パッケージを読み込む場合は、必ず、この特定の Python.exe を使用してください。
Note
インストール スクリプトでは、コンピューター上の PATH 環境変数は変更されません。つまり、インストールしたばかりの新しい python インタープリターとモジュールは、他のツール (お持ちの場合) で自動的に使用可能になりません。 Python インタープリターとライブラリのツールへのリンクに関するヘルプについては、IDE のインストールに関する記述を参照してください。
3 - Jupyter Notebook を開く
Anaconda には Jupyter Notebook が含まれています。 次の手順として、ノートブックを作成し、先ほどインストールしたライブラリを含む Python コードをいくつか実行します。
PowerShell プロンプトで、引き続き
%ProgramFiles%\Microsoft\PyForMLSディレクトリにある Scripts フォルダーの Jupyter Notebook を開きます。.\Scripts\jupyter-notebookノートブックは、既定のブラウザーの
https://localhost:8889/treeで開くはずです。起動するもう 1 つの方法は、jupyter-notebook.exe をダブルクリックすることです。
[新規] を選択し、[Python 3] を選択します。
![[新規] [Python 3] が選択された状態の Jupyter Notebook のスクリーンショット。](media/setup-python-client-tools-sql/jupyter-notebook-new-p3.png?view=sql-server-2017)
「
import revoscalepy」と入力し、コマンドを実行して、Microsoft 固有のライブラリのいずれかを読み込みます。「
print(revoscalepy.__version__)」と入力して実行すると、バージョン情報が返されます。 9.2.1 または 9.3.0 が表示されるはずです。 これらのバージョンのいずれかを、サーバーの revoscalepy で使用できます。より複雑な一連のステートメントを入力します。 この例では、ローカル データ セットで rx_summary を使用して、概要の統計情報を生成します。 その他の関数では、サンプル データの場所を取得し、ローカルの .xdf ファイルのデータ ソース オブジェクトを作成します。
import os from revoscalepy import rx_summary from revoscalepy import RxXdfData from revoscalepy import RxOptions sample_data_path = RxOptions.get_option("sampleDataDir") print(sample_data_path) ds = RxXdfData(os.path.join(sample_data_path, "AirlineDemoSmall.xdf")) summary = rx_summary("ArrDelay+DayOfWeek", ds) print(summary)
次のスクリーンショットでは入力と、出力の一部が示されており、簡潔にするためにトリミングされています。

4 - SQL のアクセス許可を取得する
スクリプトを実行してデータをアップロードするために SQL Server のインスタンスに接続するには、データベース サーバーでの有効なログインが必要です。 SQL ログインまたは統合 Windows 認証を使用できます。 一般的には Windows 統合認証を使用することをお勧めしますが、一部のシナリオでは、特にスクリプトに外部データへの接続文字列が含まれている場合は、SQL ログインを使用する方が簡単です。
少なくとも、コードの実行に使用するアカウントには、操作するデータベースから読み取るためのアクセス許可に加え、特別なアクセス許可である EXECUTE ANY EXTERNAL SCRIPT が必要です。 ほとんどの開発者には、ストアド プロシージャを作成し、トレーニング データまたはスコア付きデータを含むテーブルにデータを書き込むためのアクセス許可も必要です。
Python を使用するデータベースで、アカウントの次のアクセス許可を構成するようにデータベース管理者に依頼してください。
- EXECUTE ANY EXTERNAL SCRIPT - サーバー上で Python を実行します。
- db_datareader 特権 - モデルのトレーニングに使用するクエリを実行します。
- db_datawriter - トレーニング データまたはスコア付きデータを書き込みます。
- db_owner - ストアド プロシージャ、テーブル、関数などのオブジェクトを作成します。 サンプルを作成し、データベースをテストする場合は、db_owner も必要です。
SQL Server と共に既定でインストールされないパッケージをコードが必要とする場合は、データベース管理者に連絡して、インスタンスと共にパッケージがインストールされるようにしてください。 SQL Server はセキュリティで保護された環境であり、パッケージをインストールできる場所に制限があります。 権限がある場合でも、コードの一部としてのパッケージのアドホック インストールはお勧めできません。 また、サーバー ライブラリに新しいパッケージをインストールする前に、常に、セキュリティへの影響を慎重に検討してください。
5 - テスト データを作成する
リモート サーバーにデータベースを作成するためのアクセス許可がある場合は、次のコードを実行して、この記事の残りの手順で使用する Iris デモ データベースを作成できます。
5-1 - irissql データベースをリモートで作成する
import pyodbc
# creating a new db to load Iris sample in
new_db_name = "irissql"
connection_string = "Driver=SQL Server;Server=localhost;Database={0};Trusted_Connection=Yes;"
# you can also swap Trusted_Connection for UID={your username};PWD={your password}
cnxn = pyodbc.connect(connection_string.format("master"), autocommit=True)
cnxn.cursor().execute("IF EXISTS(SELECT * FROM sys.databases WHERE [name] = '{0}') DROP DATABASE {0}".format(new_db_name))
cnxn.cursor().execute("CREATE DATABASE " + new_db_name)
cnxn.close()
print("Database created")
5-2 - SkLearn から Iris サンプルをインポートする
from sklearn import datasets
import pandas as pd
# SkLearn has the Iris sample dataset built in to the package
iris = datasets.load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
5-3 - Revoscalepy API を使用してテーブルを作成し、Iris データを読み込む
from revoscalepy import RxSqlServerData, rx_data_step
# Example of using RX APIs to load data into SQL table. You can also do this with pyodbc
table_ref = RxSqlServerData(connection_string=connection_string.format(new_db_name), table="iris_data")
rx_data_step(input_data = df, output_file = table_ref, overwrite = True)
print("New Table Created: Iris")
print("Sklearn Iris sample loaded into Iris table")
6 - リモート接続をテストする
この次の手順を試す前に、SQL Server インスタンスに対するアクセス許可と、Iris サンプル データベースへの接続文字列があることを確認してください。 データベースが存在せず、十分なアクセス許可がある場合は、これらのインライン命令を使用してデータベースを作成することができます。
接続文字列は有効な値に置き換えます。 このサンプル コードでは "Driver=SQL Server;Server=localhost;Database=irissql;Trusted_Connection=Yes;" を使用しますが、ご自分のコードではリモート サーバーを指定する必要があります。その際に、インスタンス名と、データベース ログインにマップする資格情報オプションを指定する場合があります。
6-1 関数を定義する
次のコードでは、後の手順で SQL Server に送信する関数を定義します。 実行すると、リモート サーバー上のデータとライブラリ (revoscalepy、panda、matplotlib) を使用して、Iris データ セットの散布図が作成されます。 ブラウザーに表示するために、.png のバイトストリームが Jupyter Notebook に戻されます。
def send_this_func_to_sql():
from revoscalepy import RxSqlServerData, rx_import
from pandas.tools.plotting import scatter_matrix
import matplotlib.pyplot as plt
import io
# remember the scope of the variables in this func are within our SQL Server Python Runtime
connection_string = "Driver=SQL Server;Server=localhost;Database=irissql;Trusted_Connection=Yes;"
# specify a query and load into pandas dataframe df
sql_query = RxSqlServerData(connection_string=connection_string, sql_query = "select * from iris_data")
df = rx_import(sql_query)
scatter_matrix(df)
# return bytestream of image created by scatter_matrix
buf = io.BytesIO()
plt.savefig(buf, format="png")
buf.seek(0)
return buf.getvalue()
6-2 関数を SQL Server に送信する
この例では、リモート計算コンテキストを作成してから、rx_exec を使用して SQL Server に関数の実行を送信します。 rx_exec 関数は、計算コンテキストが引数として受け入れられるため、便利です。 リモートで実行するすべての関数には、計算コンテキスト引数が必要です。 rx_lin_mod などの一部の関数では、この引数が直接サポートされます。 そうでない演算では、rx_exec を使用して、リモート計算コンテキストでコードを提供できます。
この例では、SQL Server から Jupyter Notebook に生データを転送する必要はありませんでした。 すべての計算は Iris データベース内で行われ、イメージ ファイルのみがクライアントに返されます。
from IPython import display
import matplotlib.pyplot as plt
from revoscalepy import RxInSqlServer, rx_exec
# create a remote compute context with connection to SQL Server
sql_compute_context = RxInSqlServer(connection_string=connection_string.format(new_db_name))
# use rx_exec to send the function execution to SQL Server
image = rx_exec(send_this_func_to_sql, compute_context=sql_compute_context)[0]
# only an image was returned to my jupyter client. All data remained secure and was manipulated in my db.
display.Image(data=image)
次のスクリーンショットでは、入力と散布図の出力が示されています。

7 - ツールから Python を起動する
開発者は頻繁に複数のバージョンの Python を操作するため、セットアップでは Python がパスに追加されません。 セットアップでインストールされた Python の実行可能ファイルとライブラリを使用するには、revoscalepy と microsoftml も提供するパスの Python.exe に IDE をリンクします。
コマンド ライン
%ProgramFiles%\Microsoft\PyForMLS (または Python クライアント ライブラリのインストール用に指定した任意の場所) から Python.exe を実行すると、完全な Anaconda ディストリビューションに加え、Microsoft Python モジュールの revoscalepy および microsoftml にアクセスできます。
%ProgramFiles%\Microsoft\PyForMLSに移動し、Python.exe を実行します。- 対話型ヘルプを開きます:
help()。 - ヘルプ プロンプトでモジュールの名前を入力します:
help> revoscalepy。 ヘルプでは、名前、パッケージの内容、バージョン、およびファイルの場所が返されます。 - help> プロンプトでバージョンとパッケージの情報を返します:
revoscalepy。 Enter キーを数回押してヘルプを終了します。 - モジュールをインポートします:
import revoscalepy。
Jupyter Notebooks
この記事では組み込みの Jupyter Notebook を使用して、revoscalepy に対する関数呼び出しを示します。 このツールを初めてご利用になる場合は、次のスクリーンショットを参照してください。これには、各部分がどのように組み合わされているかと、すべて "とにかく使える" 理由が示されています。
親フォルダーの %ProgramFiles%\Microsoft\PyForMLS には、Anaconda に加え、Microsoft パッケージが含まれています。 Jupyter Notebook は Anaconda の Scripts フォルダーの下に含まれており、Python 実行可能ファイルは Jupyter Notebook に自動的に登録されます。 site-packages の下にあるパッケージは、データ サイエンスと機械学習に使用される 3 つの Microsoft パッケージを含め、ノートブックにインポートできます。
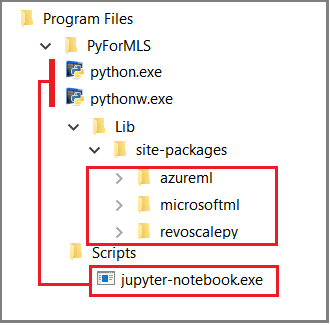
別の IDE を使用している場合は、Python 実行可能ファイルと関数ライブラリをツールにリンクする必要があります。 以下のセクションでは、一般的に使用されるツールについて説明します。
Visual Studio
Visual Studio で Python を利用する場合は、次の構成オプションを使用して、Microsoft Python パッケージを含む Python 環境を作成します。
| 構成設定 | value |
|---|---|
| Prefix path (プレフィックスのパス) | %ProgramFiles%\Microsoft\PyForMLS |
| Interpreter Path (インタープリターのパス) | %ProgramFiles%\Microsoft\PyForMLS\python.exe |
| Windowed interpreter (ウィンドウ形式のインタープリター) | %ProgramFiles%\Microsoft\PyForMLS\pythonw.exe |
Python 環境の構成のヘルプについては、Visual Studio での Python 環境の管理に関するページを参照してください。
PyCharm
PyCharm で、インタープリターをインストールされる Python 実行可能ファイルに設定します。
新しいプロジェクトの [設定] で、[ローカルの追加] を選択します。
「
%ProgramFiles%\Microsoft\PyForMLS\」と入力します。
これで、revoscalepy、microsoftml、または azureml モジュールをインポートできるようになりました。 また、 [ツール]>[Python Console](Python コンソール) の順に選択して、対話型ウィンドウを開くこともできます。