クイック スタート:SQL 機械学習を使用して R で予測モデルを作成してスコア付けする
適用対象: ![]() SQL Server 2016 (13.x) 以降
SQL Server 2016 (13.x) 以降 ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
このクイックスタートでは、T を使用して予測モデルを作成してトレーニングします。そのモデルを SQL Server インスタンスのテーブルに保存してから、そのモデルを使用して、SQL Server Machine Learning Services またはビッグ データ クラスターを使って新しいデータから値を予測します。
このクイックスタートでは、T を使用して予測モデルを作成してトレーニングし、SQL Server インスタンスのテーブルにモデルを保存します。次に、そのモデルを使用して、SQL Server Machine Learning Services を使って新しいデータから値を予測します。
このクイックスタートでは、T を使用して予測モデルを作成してトレーニングします。そのモデルを SQL Server インスタンスのテーブルに保存してから、そのモデルを使用して、SQL Server R Services を使って新しいデータから値を予測します。
このクイックスタートでは、T を使用して予測モデルを作成してトレーニングし、SQL Server インスタンスのテーブルにモデルを保存します。次に、そのモデルを使用して、Azure SQL Managed Instance Machine Learning Services を使って新しいデータから値を予測します。
SQL で実行されている 2 つのストアド プロシージャを作成して実行します。 最初のプロシージャでは、R に含まれる mtcars データセットを使用して、車両にマニュアル トランスミッションが搭載されている確率を予測する単純な汎用線形モデル (GLM) を生成します。 2 番目のプロシージャはスコアリング用で、最初のプロシージャで生成されたモデルを呼び出して、新しいデータに基づいて一連の予測を出力します。 SQL ストアド プロシージャに R コードを配置することで、操作は SQL に格納され、再利用可能になり、他のストアド プロシージャやクライアント アプリケーションから呼び出すことができます。
ヒント
線形モデルの最新の情報に更新する必要がある場合は、rxLinMod を使用したモデルの調整プロセスについて説明しているこのチュートリアルをご覧ください。「Fitting Linear Models (線形モデルの当てはめ)」
このクイックスタートを完了すると、次のことを学習できます。
- ストアド プロシージャに R コードを埋め込む方法
- ストアド プロシージャの入力を介してコードに入力を渡す方法
- ストアド プロシージャを使用してモデルを運用化する方法
前提条件
このクイック スタートを実行するには、次の前提条件を用意しておく必要があります。
- SQL Server Machine Learning Services。 Machine Learning Services をインストールするには、Windows インストール ガイドまたは Linux インストール ガイドに関するページを参照してください。 SQL Server ビッグ データ クラスターで Machine Learning Services を有効にすることもできます。
- SQL Server Machine Learning Services。 Machine Learning Services をインストールするには、Windows インストール ガイドに関するページを参照してください。
- SQL Server 2016 R Services。 R Services をインストールするには、Windows インストール ガイドに関するページを参照してください。
- Azure SQL Managed Instance の Machine Learning Services。 詳細については、Azure SQL Managed Instance の Machine Learning Services の概要に関するページを参照してください。
- R スクリプトを含む SQL クエリを実行するためのツール。 このクイックスタートでは Azure Data Studio を使用します。
モデルを作成する
モデルを作成するには、トレーニング用のソース データを作成し、そのデータを使用してモデルの作成およびトレーニングを行います。次に、モデルをデータベースに格納します。ここで、それを使用して、新しいデータで予測を生成できます。
ソース データを作成する
Azure Data Studio を開き、インスタンスに接続し、新しいクエリ ウィンドウを開きます。
トレーニング データを保存するテーブルを作成します。
CREATE TABLE dbo.MTCars( mpg decimal(10, 1) NOT NULL, cyl int NOT NULL, disp decimal(10, 1) NOT NULL, hp int NOT NULL, drat decimal(10, 2) NOT NULL, wt decimal(10, 3) NOT NULL, qsec decimal(10, 2) NOT NULL, vs int NOT NULL, am int NOT NULL, gear int NOT NULL, carb int NOT NULL );組み込みデータセット
mtcarsからデータを挿入します。INSERT INTO dbo.MTCars EXEC sp_execute_external_script @language = N'R' , @script = N'MTCars <- mtcars;' , @input_data_1 = N'' , @output_data_1_name = N'MTCars';ヒント
R ランタイムには、大小多くのデータセットが付属しています。 R と共にインストールされるデータセットの一覧を取得するには、R コマンド プロンプトから「
library(help="datasets")」と入力します。
モデルの作成とトレーニング
自動車の速度データには、馬力 (hp) と重量 (wt) という、2 つの列 (どちらも数値) が含まれます。 このデータから、車両にマニュアル トランスミッションが搭載されている確率を予測する汎用線形モデル (GLM) を作成します。
モデルを構築するには、R コード内で式を定義し、データを入力パラメーターとして渡します。
DROP PROCEDURE IF EXISTS generate_GLM;
GO
CREATE PROCEDURE generate_GLM
AS
BEGIN
EXEC sp_execute_external_script
@language = N'R'
, @script = N'carsModel <- glm(formula = am ~ hp + wt, data = MTCarsData, family = binomial);
trained_model <- data.frame(payload = as.raw(serialize(carsModel, connection=NULL)));'
, @input_data_1 = N'SELECT hp, wt, am FROM MTCars'
, @input_data_1_name = N'MTCarsData'
, @output_data_1_name = N'trained_model'
WITH RESULT SETS ((model VARBINARY(max)));
END;
GO
glmへの最初の引数は formula パラメーターで、これは、amをhp + wtに依存するものとして定義します。- 入力データは
MTCarsData変数に格納されます。この変数は、SQL クエリによって入力されます。 入力データに具体的な名前を割り当てなかった場合、既定の変数名は InputDataSet になります。
データベースにモデルを格納する
次に、モデルをデータベースに格納して、それを使用して予測や再トレーニングを行えるようにします。
モデルを格納するテーブルを作成する。
モデルを作成する R パッケージの出力は、通常はバイナリ オブジェクトです。 したがって、モデルを格納するテーブルには、varbinary(max) 型の列を提供している必要があります。
CREATE TABLE GLM_models ( model_name varchar(30) not null default('default model') primary key, model varbinary(max) not null );次の Transact-SQL ステートメントを実行してストアド プロシージャを呼び出し、モデルを生成し、作成したテーブルにそれを保存します。
INSERT INTO GLM_models(model) EXEC generate_GLM;ヒント
このコードを 2 回目に実行する場合、次のエラーが発生します。"Violation of PRIMARY KEY constraint...Cannot insert duplicate key in object dbo.stopping_distance_models" (PRIMARY KEY 制約違反...オブジェクト dbo.stopping_distance_models に重複するキーを挿入することはできません)。 このエラーを回避する方法の 1 つに、新しいモデルごとに名前を更新する方法があります。 たとえば、よりわかりやすい名前に変更したり、モデルの種類や作成日などを含めたりすることができます。
UPDATE GLM_models SET model_name = 'GLM_' + format(getdate(), 'yyyy.MM.HH.mm', 'en-gb') WHERE model_name = 'default model'
トレーニング済みのモデルを使用して新しいデータをスコアリングする
スコアリングは、データ サイエンスで使用される用語で、トレーニング済みのモデルに取り込まれた新しいデータに基づいて、予測、確率、またはその他の値を生成することを意味します。 前のセクションで作成したモデルを使用して、新しいデータに対して予測のスコアリングを行います。
新しいデータのテーブルを作成する
まず、新しいデータを使用してテーブルを作成します。
CREATE TABLE dbo.NewMTCars(
hp INT NOT NULL
, wt DECIMAL(10,3) NOT NULL
, am INT NULL
)
GO
INSERT INTO dbo.NewMTCars(hp, wt)
VALUES (110, 2.634)
INSERT INTO dbo.NewMTCars(hp, wt)
VALUES (72, 3.435)
INSERT INTO dbo.NewMTCars(hp, wt)
VALUES (220, 5.220)
INSERT INTO dbo.NewMTCars(hp, wt)
VALUES (120, 2.800)
GO
マニュアル トランスミッションを予測する
モデルに基づく予測を取得するには、次の処理を行う SQL スクリプトを作成する必要があります。
- 必要なモデルを取得します。
- 新しい入力データを取得します。
- そのモデルと互換性がある R 予測関数を呼び出します。
時間の経過とともに、テーブルには複数の R モデルが含まれるようになります。それぞれ異なるパラメーターまたはアルゴリズムを使用して構築されるか、異なるデータのサブセットに対してトレーニングされています。 この例では、default model という名前のモデルを使用します。
DECLARE @glmmodel varbinary(max) =
(SELECT model FROM dbo.GLM_models WHERE model_name = 'default model');
EXEC sp_execute_external_script
@language = N'R'
, @script = N'
current_model <- unserialize(as.raw(glmmodel));
new <- data.frame(NewMTCars);
predicted.am <- predict(current_model, new, type = "response");
str(predicted.am);
OutputDataSet <- cbind(new, predicted.am);
'
, @input_data_1 = N'SELECT hp, wt FROM dbo.NewMTCars'
, @input_data_1_name = N'NewMTCars'
, @params = N'@glmmodel varbinary(max)'
, @glmmodel = @glmmodel
WITH RESULT SETS ((new_hp INT, new_wt DECIMAL(10,3), predicted_am DECIMAL(10,3)));
上記のスクリプトは、次の手順を実行します。
SELECT ステートメントを使用してテーブルから単一のモデルを取得し、それを入力パラメーターとして渡します。
テーブルからモデルを取得した後、そのモデルに対して
unserialize関数を呼び出します。predict関数と適切な引数をモデルに適用し、新しい入力データを提供します。
Note
この例では、テスト フェーズ中に str 関数を追加して、R から返されるデータのスキーマを確認します。このステートメントは後で削除できます。
R スクリプトで使用される列名は、ストアド プロシージャの出力に必ずしも渡されるとは限りません。 ここでは、WITH RESULTS 句を使用して、新しい列名をいくつか定義します。
結果
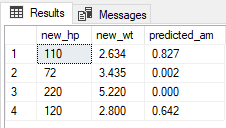
また、PREDICT (Transact-SQL) ステートメントを使用して、格納されているモデルに基づいて予測値またはスコアを生成することも可能です。
次のステップ
SQL 機械学習を使用した R のチュートリアルの詳細については、以下を参照してください。