SQL Server でのスピンロックの競合を診断および解決する
この記事では、同時実行性の高いシステム上で発生する SQL Server アプリケーションのスピンロックの競合に関連する問題を特定して解決する方法について詳しく説明します。
Note
ここに記載されている推奨事項とベスト プラクティスは、実際の OLTP システムの開発と展開における実際の経験に基づいています。 この記事は、当初、Microsoft の SQL Server Customer Advisory Team (SQLCAT) チームによって公開されたものです。
背景
これまで、Windows Server コモディティ コンピューターは 1 つまたは 2 つのマイクロプロセッサまたは CPU チップのみを使用し、CPU は単一のプロセッサまたは "コア" のみで設計されていました。 コンピューターの処理能力の向上は、主にトランジスタ密度の向上によって可能になった、より高速な CPU を使用することによって実現しています。 "ムーアの法則" に従い、1971 年に最初の汎用シングル チップ CPU が開発されて以来、トランジスタ密度、つまり集積回路に配置できるトランジスタ数は、一貫して 2 年ごとに倍増しています。 近年、より高速な CPU でコンピューターの処理能力を向上させるという従来のアプローチは、複数の CPU を搭載したコンピューターを構築することによって強化されています。 この記事の作成時点において、Intel Nehalem CPU アーキテクチャは、CPU あたり最大 8 コアに対応しており、8 ソケット システムで使用する場合、同時マルチスレッド (SMT) テクノロジを使用して 128 論理プロセッサに倍増できます。 Intel CPU では、SMT は Hyper-Threading と呼ばれます。 x86 互換コンピューター上の論理プロセッサの数が増えると、リソースを巡って論理プロセッサ間で競合が発生し、同時実行に関連する問題が増加します。 このガイドでは、一部のワークロードを使用する同時実行性の高いシステムで SQL Server アプリケーションを実行したときに見られる特定のリソース競合の問題を識別し、解決する方法について説明します。
このセクションでは、SQLCAT チームがスピンロックの競合問題の診断と解決から得た教訓を分析します。 スピンロックの競合は、高スケール システム上で顧客の実際のワークロードに見られる同時実行に関する問題の 1 つの種類です。
スピンロックの競合の現象と原因
このセクションでは、SQL Server 上の OLTP アプリケーションのパフォーマンスに悪影響を及ぼす "スピンロックの競合" に関する問題を診断する方法について説明します。 スピンロックの診断とトラブルシューティングは、デバッグツールと Windows 内部に関する知識を必要とする高度なテーマと見なす必要があります。
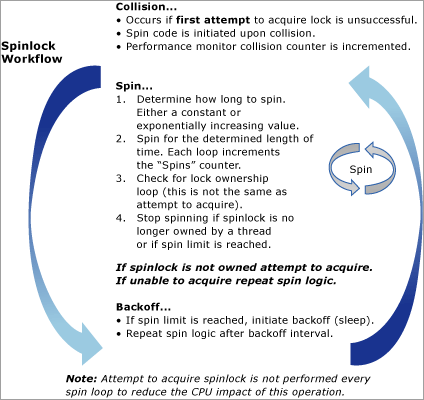
スピンロックは軽量の同期プリミティブであり、データ構造へのアクセスを保護するために使用されます。 スピンロックは、SQL Server 固有のものではありません。 オペレーティング システムにより、短時間のみ特定のデータ構造へのアクセスが必要な場合に、これが使用されます。 スピンロックを取得しようとするスレッドは、アクセスを取得できない場合、すぐに中断せずに、ループで実行され、リソースが使用できるかどうかを定期的にチェックします。 一定の時間が経過すると、スピンロックを待機しているスレッドは、リソースを取得しないうちに中断されます。 中断により、同じ CPU で実行されている他のスレッドは実行できるようになります。 この動作はバックオフと呼ばれています。これについては、この記事で後ほど詳細に説明します。
SQL Server により、スピンロックが利用され、内部データ構造の一部に対するアクセスが保護されます。 スピンロックは、ラッチと同様の方法で特定のデータ構造へのアクセスをシリアル化するためにエンジン内で使用されます。 ラッチとスピンロックの主な違いは、スピンロックでは一定時間スピン (ループを実行) され、データ構造の可用性がチェックされるのに対して、ラッチにより保護された構造へのアクセスを取得しようとするスレッドでは、リソースが使用できない場合すぐに中断されることです。 中断するには、別のスレッドを実行できるように、CPU でスレッドのコンテキスト切り替えを実行する必要があります。 これは比較的コストのかかる操作であり、短期間保持されるリソースの場合、スレッドをループで実行してリソースの可用性を定期的にチェックできるようにする方が全体的に効率的です。
SQL Server 2022 (16.x) で導入されたデータベース エンジンの内部調整により、スピンロックの効率が向上します。
現象
同時実行性の高いシステムがビジー状態の場合、スピンロックによって保護されている構造が頻繁にアクセスされ、アクティブな競合が発生するのは普通のことです。 この使用方法は、競合によって大きな CPU オーバーヘッドが生じる場合にのみ問題があると見なされます。 スピンロックの統計は、SQL Server 内の sys.dm_os_spinlock_stats 動的管理ビュー (DMV) によって公開されます。 たとえば、次のクエリにより、その後に示す出力が生成されます。
Note
この DMV によって返される情報の解釈の詳細については、この記事で後ほど説明します。
SELECT * FROM sys.dm_os_spinlock_stats
ORDER BY spins DESC;
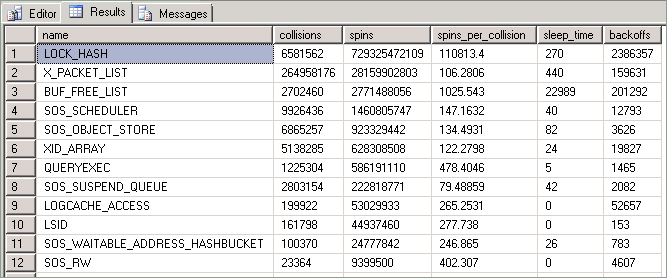
このクエリによって公開される統計の説明は、次のとおりです。
| 列 | 説明 |
|---|---|
| Collisions | この値は、スレッドが、スピンロックで保護されているリソースへのアクセスをブロックされるたびに増分されます。 |
| Spins | この値は、スピンロックが使用可能になるのを待機している間にスレッドでループが実行されるたびに増分されます。 これは、リソースを取得しようとしているときにスレッドで実行される作業量の測定値です。 |
| Spins_per_collision | 競合あたりのスピン数の比率。 |
| Sleep time | バックオフ イベント関連。ただし、この記事で説明する手法には関係ありません。 |
| Backoffs | 保持されているリソースにアクセスしようとしている "スピン中" のスレッドが、同じ CPU 上の他のスレッドを実行できるようにする必要があると判断した場合に発生します。 |
この説明の目的上、特に重要な統計は、システムの負荷が高いときに特定の期間内に発生する競合、スピン、バックオフ イベントの数です。 スレッドがスピンロックで保護されているリソースをアクセスしようとすると、競合が発生します。 競合が発生すると、競合回数が増分され、スレッドは、ループでのスピンを開始し、リソースが使用可能かどうかを定期的にチェックします。 スレッドがスピン (ループ) するたびに、スピン回数が増分されます。
競合あたりのスピン数は、スピンロックがスレッドによって保持されている間に発生するスピンの量の測定値であり、スレッドがスピンロックを保持している間に発生しているスピンの数を示します。 たとえば、競合あたりのスピン回数が少なく、競合回数が多い場合、スピンロック中に発生するスピンの量は少なく、それを巡って競合するスレッド数が多いことを意味します。 スピンの量が多いということは、スピンロック コードでスピンに費やされる時間が比較的長いことを意味します (つまり、コードによってハッシュ バケット内の多数のエントリが調べられています)。 競合が増加する (したがって競合回数が増加する) につれて、スピン数も増加します。
バックオフは、スピンと同様に考えることができます。 設計上、過度の CPU の浪費を回避するため、保持されているリソースにアクセスできるようになるまでスピンロックが無限にスピンし続けることはありません。 スピンロックによる CPU リソースの過度な使用を確実に防ぐために、スピンロックをバックオフしたり、スピンを停止して "スリープ"状態にします。 スピンロックは、ターゲット リソースの所有権を取得したかどうかに関係なく、バックオフされます。 これは、他のスレッドを CPU でスケジュールできるようにするために行われ、これにより、作業の生産性を向上する可能性があります。 エンジンの既定の動作は、バックオフを実行する前に、最初に一定の時間間隔でスピンすることです。 スピンロックを取得しようとすると、キャッシュの同時実行の状態が維持される必要があります。これは、スピンの CPU コストに比べて CPU を集中的に使用する操作です。 したがって、スピンロックを取得する試みは控えめに実行され、スレッドがスピンするたびに実行されるわけではありません。 SQL Server では、スピンロックの取得を試みる間隔を (一定の制限まで) 指数関数的に増加させることで、LOCK_HASH など特定の種類のスピンロックが改善されました。これにより、多くの場合、CPU パフォーマンスへの影響が軽減されます。
次の図は、スピンロック アルゴリズムの概念図を示しています。
一般的なシナリオ
スピンロックの競合は、さまざまな理由で発生する可能性があり、データベース設計の決定とは関係がない場合もあります。 スピンロックは内部データ構造へのアクセスの関門となるため、スピンロックの競合はスキーマ設計の選択とデータ アクセス パターンの影響を直接受けるバッファ ラッチの競合と同じようには現れません。
主にスピンロックの競合に関連する現象は、多数のスピンと、同じスピンロックを取得しようとする多数のスレッドの結果として、CPU 消費量が多くなることです。 通常、これは >= 24 のシステムで観察されたことがあり、最も一般的には > = 32 CPU コア システムで観察されています。 前に述べたように、同時実行性の高い OLTP システムで負荷が大きい場合、ある程度のスピンロックの競合は普通のことであり、多くの場合、長時間にわたり実行されているシステムに関する sys.dm_os_spinlock_stats DMV から多数 (数十億または数兆回) のスピンが報告されます。 この場合も、特定のスピンロックの種類について多数のスピンが確認されても、それだけではワークロードのパフォーマンスに悪影響があるか判断する十分な情報ではありません。
次の現象のいくつかが組み合わさると、スピンロックの競合を示している可能性があります。
特定のスピンロックの種類について多数のスピンとバックオフが観察される。
システムで、高い CPU 使用量または CPU 消費量のスパイクが発生している。 CPU の負荷が高いシナリオでは、(DMV
sys.dm_os_wait_statsによって報告される) SOS_SCHEDULER_YIELD で高いシグナル待機率が見られます。システムで、多くの同時実行が発生する。
スループットに対して CPU 使用率とスピン回数が多すぎる。
重要
前述の各条件が当てはまる場合でも、CPU 消費が高い根本原因は他にある可能性もあります。 実際、ほとんどの場合、CPU の増加は、スピンロックの競合以外の理由によるものです。 CPU 消費量の増加を引き起こすより一般的な原因としては、次のようなものがあります。
基になるデータの増加により時間の経過と共にコストが高くなり、メモリ常駐データの追加の論理読み取りを実行する必要が生じるクエリ。
最適ではない実行が生じるクエリ プランの変更。
これらの条件がすべて当てはまる場合は、スピンロックの競合の問題の可能性についてさらに調査を行います。
簡単に診断できる一般的な現象の 1 つは、スループットと CPU 使用率の大きな相違です。 多くの OLTP ワークロードには、(スループット / システム上のユーザー数) と CPU 消費量の間に関係があります。 CPU 消費量とスループットの大きな相違に関連して観察される高いスピン数は、CPU のオーバーヘッドを発生させるスピンロックの競合を示している可能性があります。 ここで注意すべき重要な点は、特定のクエリが時間の経過と共にコスト高になっていくと、一般的にシステムでこのような種類の相違も見られるようになるということです。 たとえば、実行する論理的な読み取りが時間の経過と共に増加するデータセットに対してクエリを発行すると、同様の現象を引き起こすおそれがあります。
このような種類の問題をトラブルシューティングする場合は、CPU が高くなる、より一般的な他の原因を除外することが重要です。
例
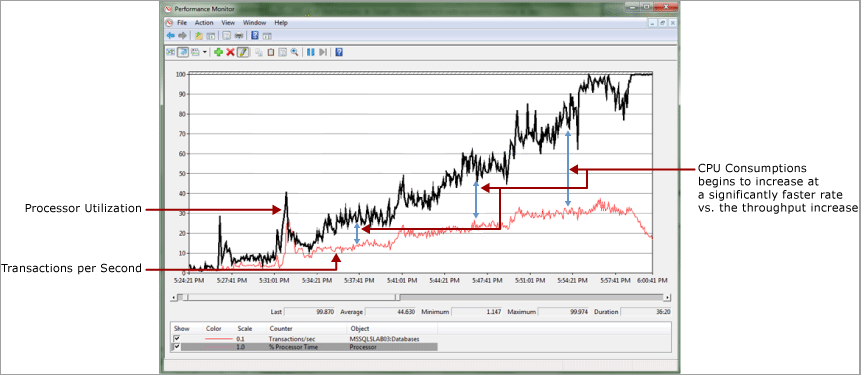
次の例では、1 秒あたりのトランザクション数で測定される CPU 消費量とスループットの間にほぼ線形の関係があります。 ワークロードが増加するとオーバーヘッドが発生するため、ここで多少の相違が見られるのは普通のことです。 次の図で示すように、この相違は大きくなります。 さらに、CPU 消費量が 100% に達すると、スループットが急激に減少します。
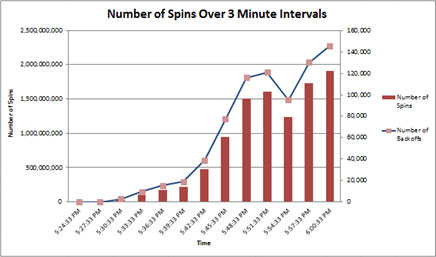
3 分間隔でスピン数を測定すると、スピンの線形増加よりも指数関数的であることがわかります。これは、スピンロックの競合が問題になるおそれがあることを示しています。
前述のとおり、同時実行性の高いシステムの負荷が高い場合、スピンロックは最も一般的です。
この問題が発生する可能性が高いシナリオとしては、次のようなものがあります。
オブジェクトの名前を完全に修飾できないことによって発生する名前解決の問題。 詳細については、コンパイル ロックによって発生する SQL Server のブロッキングに関する説明を参照してください。 この特定の問題については、この記事で詳細に説明します。
同じロック (頻繁に読み取られる行の共有ロックなど) に頻繁にアクセスするワークロードのロック マネージャーでのロック ハッシュ バケットの競合。 この種の競合は、LOCK_HASH という種類のスピンロックとして現れます。 ある特定のケースで、この問題が、テスト環境で誤ってモデル化されたアクセス パターンの結果として現れたことがわかりました。 この環境では、テスト パラメーターが正しく構成されていないため、予想を超える数のスレッドが常にまったく同じ行にアクセスしていました。
MSDTC トランザクション コーディネーター間に長い待機時間がある場合の高い DTC トランザクション率。 この特定の問題の詳細については、SQLCAT ブログ エントリ「DTC 関連の待機を解決し、DTC のスケーラビリティをチューニングする」を参照してください。
スピンロックの競合を診断する
このセクションでは、SQL Server のスピンロックの競合を診断するための情報を提供します。 スピンロックの競合の診断に使用される主なツールは次のとおりです。
| ツール | 用途 |
|---|---|
| パフォーマンス モニター | 高 CPU 状態、またはスループットと CPU 消費量の相違が検索されます。 |
sys.dm_os_spinlock stats DMV** |
一定の期間にわたって数多くのスピンおよびバックオフ イベントが検索されます。 |
| SQL Server 拡張イベント | 多数のスピンが発生しているスピンロックの呼び出し履歴を追跡するために使用されます。 |
| メモリ ダンプ | 場合によっては、SQL Server プロセスのメモリ ダンプと Windows デバッグ ツール。 通常、このレベルの分析は、Microsoft SQL Server サポートチームが関与しているときに実行されます。 |
SQL Server のスピンロックの競合を診断するための一般的な技術的プロセスは次のとおりです。
ステップ 1: スピンロックに関連している可能性のある競合が発生しているかどうかを確認します。
ステップ 2:
sys.dm_ os_spinlock_stats から統計をキャプチャして、最も競合が発生しているスピンロックの種類を特定します。ステップ 3: sqlservr.exe (sqlservr.pdb) のデバッグ シンボルを取得し、SQL Server のインスタンスの SQL Server サービスの .exe ファイル (sqlservr.exe) と同じディレクトリにシンボルを配置します。また、バックオフ イベントの呼び出し履歴を表示するには、実行している SQL Server の特定のバージョンのシンボルが必要です。 SQL Server のシンボルは、Microsoft シンボル サーバーで入手できます。 Microsoft シンボル サーバーからシンボルをダウンロードする方法の詳細については、「シンボルを使用したデバッグ」を参照してください。
ステップ 4: SQL Server 拡張イベントを使用して、対象とするスピンロックの種類のバックオフ イベントをトレースします。
拡張イベントを使用すると、バックオフ イベントを追跡し、スピンロックを取得しようとする最も一般的な操作の呼び出し履歴をキャプチャできます。 呼び出し履歴を分析することにより、特定のスピンロックの競合がどの種類の操作に起因しているかを特定できます。
診断チュートリアル
次のチュートリアルでは、ツールおよび手法を使用して、実際のシナリオでスピンロックの競合の問題を診断する方法について説明します。 このチュートリアルは、ベンチマーク テストを実行して、1 TB のメモリを備えた 8 ソケット、64 物理コア サーバーで約 6,500 人の同時ユーザーをシミュレートする顧客エンゲージメントに基づいています。
現象
定期的な CPU スパイクが観察され、CPU 使用率がほぼ 100% になりました。 スループットと CPU 消費量の間に相違が見られ、問題が発生しました。 大きな CPU スパイクが発生するまでに、特定の間隔で CPU 使用率が高いときに発生する多数のスピンのパターンが確立されました。
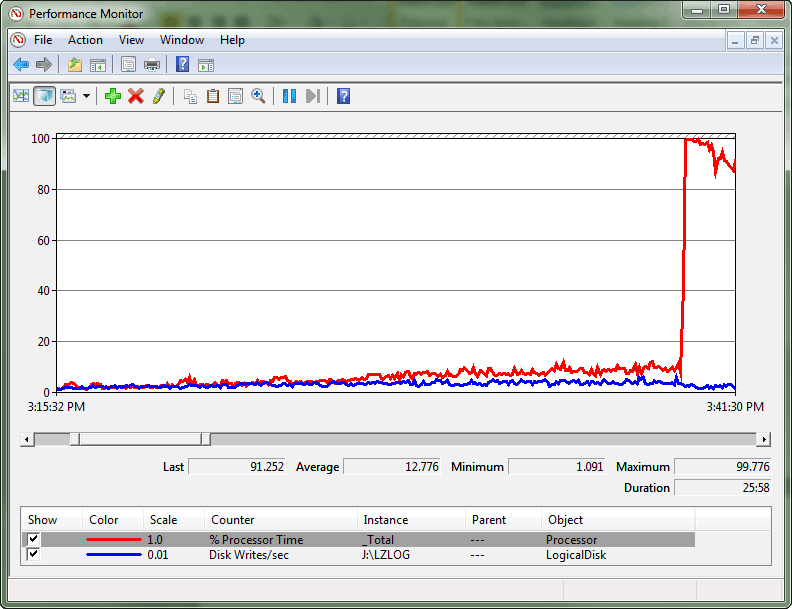
これは、競合によってスピンロック コンボイ状態が作成されるような極端なケースでした。 コンボイは、スレッドがワークロードの処理を進めることができなくなり、代わりにすべての処理リソースを使用してロックへのアクセスを試みるときに発生します。 パフォーマンス モニター ログには、トランザクション ログのスループットと CPU 消費量のこの相違が示され、最終的に、CPU 使用率の大きなスパイクが示されます。
sys.dm_os_spinlock_stats のクエリを実行して、SOS_CACHESTORE で重大な競合が発生していることを確認した後、対象とするスピンロックの種類についてバックオフ イベントの数を測定するため拡張イベント スクリプトが使用されました。
| 名前 | 競合数 | スピン数 | 競合あたりのスピン数 | バックオフ |
|---|---|---|---|---|
SOS_CACHESTORE |
14,752,117 | 942,869,471,526 | 63,914 | 67,900,620 |
SOS_SUSPEND_QUEUE |
69,267,367 | 473,760,338,765 | 6,840 | 2,167,281 |
LOCK_HASH |
5,765,761 | 260,885,816,584 | 45,247 | 3,739,208 |
MUTEX |
2,802,773 | 9,767,503,682 | 3,485 | 350,997 |
SOS_SCHEDULER |
1,207,007 | 3,692,845,572 | 3,060 | 109,746 |
スピンの影響を定量化する最も簡単な方法は、スピン数の最も多いスピンロックの種類について、同じ 1 分間隔で、sys.dm_os_spinlock_stats によって公開されたバックオフ イベントの数を調べることです。 この方法は、スピンロックの取得を待機しているときにスレッドがスピン制限を使い果たしていることを示すため、重大な競合を検出するのに最適です。 次のスクリプトは、拡張イベントを利用して関連するバックオフ イベントを測定し、競合が発生している特定のコード パスを識別する高度な手法を示しています。
SQL Server の拡張イベントの詳細については、「拡張イベントの概要」を参照してください。
スクリプト
/*
This script is provided "AS IS" with no warranties, and confers no rights.
This script will monitor for backoff events over a given period of time and
capture the code paths (callstacks) for those.
--Find the spinlock types
select map_value, map_key, name from sys.dm_xe_map_values
where name = 'spinlock_types'
order by map_value asc
--Example: Get the type value for any given spinlock type
select map_value, map_key, name from sys.dm_xe_map_values
where map_value IN ('SOS_CACHESTORE', 'LOCK_HASH', 'MUTEX')
Examples:
61LOCK_HASH
144 SOS_CACHESTORE
08MUTEX
*/
--create the even session that will capture the callstacks to a bucketizer
--more information is available in this reference: http://msdn.microsoft.com/en-us/library/bb630354.aspx
CREATE EVENT SESSION spin_lock_backoff ON SERVER
ADD EVENT sqlos.spinlock_backoff (
ACTION(package0.callstack) WHERE type = 61 --LOCK_HASH
OR TYPE = 144 --SOS_CACHESTORE
OR TYPE = 8 --MUTEX
) ADD TARGET package0.asynchronous_bucketizer (
SET filtering_event_name = 'sqlos.spinlock_backoff',
source_type = 1,
source = 'package0.callstack'
)
WITH (
MAX_MEMORY = 50 MB,
MEMORY_PARTITION_MODE = PER_NODE
);
--Ensure the session was created
SELECT * FROM sys.dm_xe_sessions
WHERE name = 'spin_lock_backoff';
--Run this section to measure the contention
ALTER EVENT SESSION spin_lock_backoff ON SERVER STATE = START;
--wait to measure the number of backoffs over a 1 minute period
WAITFOR DELAY '00:01:00';
--To view the data
--1. Ensure the sqlservr.pdb is in the same directory as the sqlservr.exe
--2. Enable this trace flag to turn on symbol resolution
DBCC TRACEON (3656, -1);
--Get the callstacks from the bucketize target
SELECT event_session_address,
target_name,
execution_count,
cast(target_data AS XML)
FROM sys.dm_xe_session_targets xst
INNER JOIN sys.dm_xe_sessions xs
ON (xst.event_session_address = xs.address)
WHERE xs.name = 'spin_lock_backoff';
--clean up the session
ALTER EVENT SESSION spin_lock_backoff ON SERVER STATE = STOP;
DROP EVENT SESSION spin_lock_backoff ON SERVER;
出力を分析することにより、SOS_CACHESTORE スピンの最も一般的なコード パスの呼び出し履歴を確認できます。 スクリプトは、返された呼び出し履歴の整合性をチェックするために、CPU 使用率が高いときに数回実行されました。 スロット バケット数が最も多い呼び出し履歴は、2 つの出力 (35,668 と 8,506) の間で共通です。 これらの呼び出し履歴には、次に高いエントリより 2 桁大きい "スロット カウント" があります。 この状態は、対象とするコード パスを示します。
Note
前のスクリプトによって返された呼び出し履歴が見られるのは、珍しいことではありません。 1 分間スクリプトの実行時、スロット数が > 1000 を超える呼び出し履歴は問題である一方、よりスロット数の多い > 10,000 未満のスロット数の方が問題になる可能性が高くなることを確認しました。
Note
次の出力の形式は、読みやすくするために不要なものは削除されています。
出力 1
<BucketizerTarget truncated="0" buckets="256">
<Slot count="35668" trunc="0">
<value>
XeSosPkg::spinlock_backoff::Publish
SpinlockBase::Sleep
SpinlockBase::Backoff
Spinlock<144,1,0>::SpinToAcquireOptimistic
SOS_CacheStore::GetUserData
OpenSystemTableRowset
CMEDScanBase::Rowset
CMEDScan::StartSearch
CMEDCatalogOwner::GetOwnerAliasIdFromSid
CMEDCatalogOwner::LookupPrimaryIdInCatalog CMEDCacheEntryFactory::GetProxiedCacheEntryByAltKey
CMEDCatalogOwner::GetProxyOwnerBySID
CMEDProxyDatabase::GetOwnerBySID
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
NTGroupInfo::`vector deleting destructor'
</value>
</Slot>
<Slot count="752" trunc="0">
<value>
XeSosPkg::spinlock_backoff::Publish
SpinlockBase::Sleep
SpinlockBase::Backoff
Spinlock<144,1,0>::SpinToAcquireOptimistic
SOS_CacheStore::GetUserData
OpenSystemTableRowset
CMEDScanBase::Rowset
CMEDScan::StartSearch
CMEDCatalogOwner::GetOwnerAliasIdFromSid CMEDCatalogOwner::LookupPrimaryIdInCatalog CMEDCacheEntryFactory::GetProxiedCacheEntryByAltKey CMEDCatalogOwner::GetProxyOwnerBySID
CMEDProxyDatabase::GetOwnerBySID
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
</value>
</Slot>
出力 2
<BucketizerTarget truncated="0" buckets="256">
<Slot count="8506" trunc="0">
<value>
XeSosPkg::spinlock_backoff::Publish
SpinlockBase::Sleep+c7 [ @ 0+0x0 SpinlockBase::Backoff Spinlock<144,1,0>::SpinToAcquireOptimistic
SOS_CacheStore::GetUserData
OpenSystemTableRowset
CMEDScanBase::Rowset
CMEDScan::StartSearch
CMEDCatalogOwner::GetOwnerAliasIdFromSid CMEDCatalogOwner::LookupPrimaryIdInCatalog CMEDCacheEntryFactory::GetProxiedCacheEntryByAltKey CMEDCatalogOwner::GetProxyOwnerBySID
CMEDProxyDatabase::GetOwnerBySID
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
NTGroupInfo::`vector deleting destructor'
</value>
</Slot>
<Slot count="190" trunc="0">
<value>
XeSosPkg::spinlock_backoff::Publish
SpinlockBase::Sleep
SpinlockBase::Backoff
Spinlock<144,1,0>::SpinToAcquireOptimistic
SOS_CacheStore::GetUserData
OpenSystemTableRowset
CMEDScanBase::Rowset
CMEDScan::StartSearch
CMEDCatalogOwner::GetOwnerAliasIdFromSid CMEDCatalogOwner::LookupPrimaryIdInCatalog CMEDCacheEntryFactory::GetProxiedCacheEntryByAltKey CMEDCatalogOwner::GetProxyOwnerBySID
CMEDProxyDatabase::GetOwnerBySID
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
</value>
</Slot>
前の例では、最も興味深いスタックのスロット数が最も多く (35,668 および 8,506)、実際、スロット数は > 1000 です。
ここで、"この情報をどう扱えばいいのか" という疑問が生じるかもしれません。 通常、呼び出し履歴情報を利用するには、SQL Server エンジンに関する深い知識が必要であるため、この時点でトラブルシューティング プロセスは不透明になります。 この特定のケースでは、呼び出し履歴を見ると、問題が発生するコード パスがセキュリティとメタデータの検索に関連していることがわかります (スタック フレーム CMEDCatalogOwner::GetProxyOwnerBySID & CMEDProxyDatabase::GetOwnerBySID) がエビデンスです)。
この情報だけを使用して問題を解決することは困難です。しかし、これにより問題をさらに切り離すため、追加のトラブルシューティングでどこに重点を置けばよいか、アイデアを得ることができます。
この問題は、セキュリティ関連のチェックを実行するコード パスに関連していると思われるため、データベースに接続しているアプリケーション ユーザーに sysadmin 権限が付与されたテストを実行することにしました。 この手法は、運用環境では推奨されませんが、テスト環境では、トラブルシューティング手順として役立つことがわかりました。 昇格された特権 (sysadmin) を使用してセッションを実行すると、競合に関連する CPU スパイクが消えました。
オプションと対処方法
明らかに、スピンロックの競合のトラブルシューティングは、簡単な作業ではありません。 "1 つの一般的な最善のアプローチ" はありません。 どんなパフォーマンス問題でも、トラブルシューティングして解決するための最初の手順は、根本原因を特定することです。 この記事で説明する手法とツールを使用することは、スピンロック関連の競合ポイントを理解するために必要な分析を実行するための最初のステップです。
SQL Server の新しいバージョンが開発されると、エンジンは、同時実行性の高いシステム用にさらに最適化されたコードを実装することにより、スケーラビリティを向上させ続けます。 SQL Server には、同時実行性の高いシステム用の多くの最適化が導入されています。そのうちの 1 つは、最も一般的な競合ポイント用の指数バックオフです。 SQL Server 2012 以降、エンジン内のすべてのスピンロックに対して指数バックオフ アルゴリズムを活用することにより、この特定の領域を特に改善する固有の拡張機能があります。
非常に高いパフォーマンスとスケーリングを必要とするハイ エンド アプリケーションを設計する場合、SQL Server 内で必要なコード パスをできるだけ短くする方法を検討してください。 コード パスが短いほど、データベース エンジンによって実行される作業が少なくなり、必然的に競合ポイントが回避されます。 多くのベスト プラクティスには、エンジンに必要な作業量が削減されるという副次的な効果があり、その結果、ワークロードのパフォーマンスが最適化されます。
この記事の前半で説明したいくつかのベスト プラクティスを例として取り上げます。
完全修飾名: すべてのオブジェクトの名前を完全修飾すると、名前の解決に必要なコード パスを SQL Server で実行する必要がなくなります。 ストアド プロシージャの呼び出しで完全修飾名を使用しない場合に発生するスピンロックの種類 SOS_CACHESTORE でも競合ポイントが確認されています。 これらの名前を完全に修飾しないと、SQL Server でユーザーの既定のスキーマを検索する必要が生じ、SQL の実行に必要なコード パスが長くなります。
パラメーター化したクエリ: もう 1 つの例は、パラメーター化されたクエリとストアド プロシージャの呼び出しを利用して、実行プランの生成に必要な作業を削減することです。 この場合も、実行に必要なコード パスが短くなります。
LOCK_HASH 競合: 特定のロック構造の競合またはハッシュ バケットの競合は、回避できない場合もあります。 SQL Server エンジンによってロック構造の大部分が分割されても、ロックを取得すると、同じハッシュ バケットにアクセスする場合があります。 たとえば、アプリケーションでは、同時に多くのスレッドによって同じ行 (つまり、参照データ) にアクセスされます。 この種類の問題は、データベース スキーマ内でこの参照データをスケール アウトするか、可能な場合は NOLOCK ヒントを使用することで対処できます。
SQL Server ワークロードのチューニングで最初の防御策は、常に標準のチューニング プラクティス (たとえば、インデックス作成、クエリの最適化、I/O の最適化など) です。 しかし、実行する標準のチューニングに加えて、操作の実行に必要なコードの量を減らすプラクティスに従うことも重要なアプローチです。 ベスト プラクティスに従っている場合でも、同時実行性の高いシステムがビジー状態のとき、スピンロックの競合が発生する場合があります。 この記事で説明したツールや手法を使用すると、このような問題を切り離し除外できます。また、適切な Microsoft リソースを利用し支援する必要がある状況について判断できます。
これらの手法によって、この種のトラブルシューティングに役立つ方法と、SQL Server で利用できるより高度なパフォーマンス プロファイリング手法のいくつかに関する分析情報の両方を提供できることを願っています。
付録: メモリ ダンプ キャプチャを自動化する
次の拡張イベント スクリプトは、スピンロックの競合が深刻化したときに、メモリ ダンプの収集を自動化するのに役立つことが実証されています。 場合によっては、問題を完全に診断するためにメモリ ダンプが必要になるか、Microsoft サポート チームから詳細な分析を実行するように要求されることがあります。 SQL Server 2008 では、バケタイザーによってキャプチャされる呼び出し履歴に 16 フレームの制限があります。このため、呼び出し履歴の入力元であるエンジン内の場所を正確に判断するのに十分ではない場合があります。 SQL Server 2012 では、バケタイザーによってキャプチャされる呼び出し履歴のフレーム数を 32 に増やすことによって改善されました。
次の SQL スクリプトを使用して、メモリ ダンプをキャプチャするプロセスを自動化し、スピンロックの競合の分析に役立てることができます。
/*
This script is provided "AS IS" with no warranties, and confers no rights.
Use: This procedure will monitor for spinlocks with a high number of backoff events
over a defined time period which would indicate that there is likely significant
spin lock contention.
Modify the variables noted below before running.
Requires:
xp_cmdshell to be enabled
sp_configure 'xp_cmd', 1
go
reconfigure
go
*********************************************************************************************************/
USE tempdb;
GO
IF object_id('sp_xevent_dump_on_backoffs') IS NOT NULL
DROP PROCEDURE sp_xevent_dump_on_backoffs
GO
CREATE PROCEDURE sp_xevent_dump_on_backoffs (
@sqldumper_path NVARCHAR(max) = '"c:\Program Files\Microsoft SQL Server\100\Shared\SqlDumper.exe"',
@dump_threshold INT = 500, --capture mini dump when the slot count for the top bucket exceeds this
@total_delay_time_seconds INT = 60, --poll for 60 seconds
@PID INT = 0,
@output_path NVARCHAR(MAX) = 'c:\',
@dump_captured_flag INT = 0 OUTPUT
)
AS
/*
--Find the spinlock types
select map_value, map_key, name from sys.dm_xe_map_values
where name = 'spinlock_types'
order by map_value asc
--Example: Get the type value for any given spinlock type
select map_value, map_key, name from sys.dm_xe_map_values
where map_value IN ('SOS_CACHESTORE', 'LOCK_HASH', 'MUTEX')
*/
IF EXISTS (
SELECT *
FROM sys.dm_xe_session_targets xst
INNER JOIN sys.dm_xe_sessions xs
ON (xst.event_session_address = xs.address)
WHERE xs.name = 'spinlock_backoff_with_dump'
)
DROP EVENT SESSION spinlock_backoff_with_dump
ON SERVER
CREATE EVENT SESSION spinlock_backoff_with_dump ON SERVER
ADD EVENT sqlos.spinlock_backoff (
ACTION(package0.callstack) WHERE type = 61 --LOCK_HASH
--or type = 144 --SOS_CACHESTORE
--or type = 8 --MUTEX
--or type = 53 --LOGCACHE_ACCESS
--or type = 41 --LOGFLUSHQ
--or type = 25 --SQL_MGR
--or type = 39 --XDESMGR
) ADD target package0.asynchronous_bucketizer (
SET filtering_event_name = 'sqlos.spinlock_backoff',
source_type = 1,
source = 'package0.callstack'
)
WITH (
MAX_MEMORY = 50 MB,
MEMORY_PARTITION_MODE = PER_NODE
)
ALTER EVENT SESSION spinlock_backoff_with_dump ON SERVER STATE = START;
DECLARE @instance_name NVARCHAR(MAX) = @@SERVICENAME;
DECLARE @loop_count INT = 1;
DECLARE @xml_result XML;
DECLARE @slot_count BIGINT;
DECLARE @xp_cmdshell NVARCHAR(MAX) = NULL;
--start polling for the backoffs
PRINT 'Polling for: ' + convert(VARCHAR(32), @total_delay_time_seconds) + ' seconds';
WHILE (@loop_count < CAST(@total_delay_time_seconds / 1 AS INT))
BEGIN
WAITFOR DELAY '00:00:01'
--get the xml from the bucketizer for the session
SELECT @xml_result = CAST(target_data AS XML)
FROM sys.dm_xe_session_targets xst
INNER JOIN sys.dm_xe_sessions xs
ON (xst.event_session_address = xs.address)
WHERE xs.name = 'spinlock_backoff_with_dump';
--get the highest slot count from the bucketizer
SELECT @slot_count = @xml_result.value(N'(//Slot/@count)[1]', 'int');
--if the slot count is higher than the threshold in the one minute period
--dump the process and clean up session
IF (@slot_count > @dump_threshold)
BEGIN
PRINT 'exec xp_cmdshell ''' + @sqldumper_path + ' ' + convert(NVARCHAR(max), @PID) + ' 0 0x800 0 c:\ '''
SELECT @xp_cmdshell = 'exec xp_cmdshell ''' + @sqldumper_path + ' ' + convert(NVARCHAR(max), @PID) + ' 0 0x800 0 ' + @output_path + ' '''
EXEC sp_executesql @xp_cmdshell
PRINT 'loop count: ' + convert(VARCHAR(128), @loop_count)
PRINT 'slot count: ' + convert(VARCHAR(128), @slot_count)
SET @dump_captured_flag = 1
BREAK
END
--otherwise loop
SET @loop_count = @loop_count + 1
END;
--see what was collected then clean up
DBCC TRACEON (3656, -1);
SELECT event_session_address,
target_name,
execution_count,
cast(target_data AS XML)
FROM sys.dm_xe_session_targets xst
INNER JOIN sys.dm_xe_sessions xs
ON (xst.event_session_address = xs.address)
WHERE xs.name = 'spinlock_backoff_with_dump';
ALTER EVENT SESSION spinlock_backoff_with_dump ON SERVER STATE = STOP;
DROP EVENT SESSION spinlock_backoff_with_dump ON SERVER;
GO
/* CAPTURE THE DUMPS
******************************************************************/
--Example: This will run continuously until a dump is created.
DECLARE @sqldumper_path NVARCHAR(MAX) = '"c:\Program Files\Microsoft SQL Server\100\Shared\SqlDumper.exe"';
DECLARE @dump_threshold INT = 300; --capture mini dump when the slot count for the top bucket exceeds this
DECLARE @total_delay_time_seconds INT = 60; --poll for 60 seconds
DECLARE @PID INT = 0;
DECLARE @flag TINYINT = 0;
DECLARE @dump_count TINYINT = 0;
DECLARE @max_dumps TINYINT = 3; --stop after collecting this many dumps
DECLARE @output_path NVARCHAR(max) = 'c:\'; --no spaces in the path please :)
--Get the process id for sql server
DECLARE @error_log TABLE (
LogDate DATETIME,
ProcessInfo VARCHAR(255),
TEXT VARCHAR(max)
);
INSERT INTO @error_log
EXEC ('xp_readerrorlog 0, 1, ''Server Process ID''');
SELECT @PID = convert(INT, (REPLACE(REPLACE(TEXT, 'Server Process ID is ', ''), '.', '')))
FROM @error_log
WHERE TEXT LIKE ('Server Process ID is%');
PRINT 'SQL Server PID: ' + convert(VARCHAR(6), @PID);
--Loop to monitor the spinlocks and capture dumps. while (@dump_count < @max_dumps)
BEGIN
EXEC sp_xevent_dump_on_backoffs @sqldumper_path = @sqldumper_path,
@dump_threshold = @dump_threshold,
@total_delay_time_seconds = @total_delay_time_seconds,
@PID = @PID,
@output_path = @output_path,
@dump_captured_flag = @flag OUTPUT
IF (@flag > 0)
SET @dump_count = @dump_count + 1
PRINT 'Dump Count: ' + convert(VARCHAR(2), @dump_count)
WAITFOR DELAY '00:00:02'
END;
付録: 時間の経過に伴うスピンロックの統計情報をキャプチャする
次のスクリプトを使用して、特定の期間のスピンロック統計を調べることができます。 これを実行するたびに、現在の値と以前に収集された値の差分が返されます。
/* Snapshot the current spinlock stats and store so that this can be compared over a time period
Return the statistics between this point in time and the last collection point in time.
**This data is maintained in tempdb so the connection must persist between each execution**
**alternatively this could be modified to use a persisted table in tempdb. if that
is changed code should be included to clean up the table at some point.**
*/
USE tempdb;
GO
DECLARE @current_snap_time DATETIME;
DECLARE @previous_snap_time DATETIME;
SET @current_snap_time = GETDATE();
IF NOT EXISTS (
SELECT name
FROM tempdb.sys.sysobjects
WHERE name LIKE '#_spin_waits%'
)
CREATE TABLE #_spin_waits (
lock_name VARCHAR(128),
collisions BIGINT,
spins BIGINT,
sleep_time BIGINT,
backoffs BIGINT,
snap_time DATETIME
);
--capture the current stats
INSERT INTO #_spin_waits (
lock_name,
collisions,
spins,
sleep_time,
backoffs,
snap_time
)
SELECT name,
collisions,
spins,
sleep_time,
backoffs,
@current_snap_time
FROM sys.dm_os_spinlock_stats;
SELECT TOP 1 @previous_snap_time = snap_time
FROM #_spin_waits
WHERE snap_time < (
SELECT max(snap_time)
FROM #_spin_waits
)
ORDER BY snap_time DESC;
--get delta in the spin locks stats
SELECT TOP 10 spins_current.lock_name,
(spins_current.collisions - spins_previous.collisions) AS collisions,
(spins_current.spins - spins_previous.spins) AS spins,
(spins_current.sleep_time - spins_previous.sleep_time) AS sleep_time,
(spins_current.backoffs - spins_previous.backoffs) AS backoffs,
spins_previous.snap_time AS [start_time],
spins_current.snap_time AS [end_time],
DATEDIFF(ss, @previous_snap_time, @current_snap_time) AS [seconds_in_sample]
FROM #_spin_waits spins_current
INNER JOIN (
SELECT *
FROM #_spin_waits
WHERE snap_time = @previous_snap_time
) spins_previous
ON (spins_previous.lock_name = spins_current.lock_name)
WHERE spins_current.snap_time = @current_snap_time
AND spins_previous.snap_time = @previous_snap_time
AND spins_current.spins > 0
ORDER BY (spins_current.spins - spins_previous.spins) DESC;
--clean up table
DELETE
FROM #_spin_waits
WHERE snap_time = @previous_snap_time;