JSON データへのインデックスの追加
適用対象: ![]() SQL Server 2016 (13.x) 以降
SQL Server 2016 (13.x) 以降 ![]() Azure SQL データベース
Azure SQL データベース ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
標準的なインデックスを使用して、JSON ドキュメント用にクエリを最適化できます。 SQL Server にはカスタム JSON インデックスがありません。
- 現在、SQL Server json はビルトインデータ型ではありません。
- 現在、JSON データ型は、Azure SQL データベース で使用できます。
インデックスは、varchar/nvarchar またはネイティブ json データ型の JSON データでも同じように機能します。
データベース インデックスでは、フィルターおよび並べ替え操作のパフォーマンスを向上させることができます。 インデックスがない場合、SQL Server は、データのクエリを実行するたびに、テーブルを完全にスキャンしなければなりません。
計算列を使用した JSON のプロパティへのインデックスの追加
SQL Server に JSON データを格納するときは通常、JSON ドキュメントの 1 つまたは複数の "プロパティ" でクエリ結果をフィルターしたり並べ替えたりします。
例
この例では、AdventureWorks.SalesOrderHeader テーブルに、注文に関するさまざまな情報を JSON 形式で格納している Info 列があるものとします。 たとえば、顧客、営業担当者、出荷および請求先住所などの非構造化データが含まれます。 顧客の販売注文をフィルター処理するには、Info 列の値を使用します。
既定では、使用されている Info 列は存在しません。次のコードを使用して、AdventureWorks データベースに作成できます。 次の例は、AdventureWorksLT の一連のサンプル データベースには適用されません。
IF NOT EXISTS(SELECT * FROM sys.columns WHERE object_id = OBJECT_ID('[Sales].[SalesOrderHeader]') AND name = 'Info')
ALTER TABLE [Sales].[SalesOrderHeader] ADD [Info] NVARCHAR(MAX) NULL
GO
UPDATE h
SET [Info] =
(
SELECT [Customer.Name] = concat(p.FirstName, N' ', p.LastName),
[Customer.ID] = p.BusinessEntityID,
[Customer.Type] = p.[PersonType],
[Order.ID] = soh.SalesOrderID,
[Order.Number] = soh.SalesOrderNumber,
[Order.CreationData] = soh.OrderDate,
[Order.TotalDue] = soh.TotalDue
FROM [Sales].SalesOrderHeader AS soh
INNER JOIN [Sales].[Customer] AS c ON c.CustomerID = soh.CustomerID
INNER JOIN [Person].[Person] AS p ON p.BusinessEntityID = c.CustomerID
WHERE soh.SalesOrderID = h.SalesOrderID FOR JSON PATH, WITHOUT_ARRAY_WRAPPER
)
FROM [Sales].SalesOrderHeader AS h;
最適化するためのクエリ
インデックスを使用して最適化するクエリの種類の例を次に示します。
SELECT SalesOrderNumber,
OrderDate,
JSON_VALUE(Info, '$.Customer.Name') AS CustomerName
FROM Sales.SalesOrderHeader
WHERE JSON_VALUE(Info, '$.Customer.Name') = N'Aaron Campbell'
インデックスの例
JSON ドキュメントのプロパティでフィルターまたは ORDER BY 句を高速化する場合は、他の列で既に使用しているのと同じインデックスを使用します。 ただし、JSON ドキュメントのプロパティを "直接" 参照することはできません。
- 最初に、フィルター処理に使用する値を返す "仮想列" を作成します。
- それからその仮想列にインデックスを作成します。
次の例では、インデックスに使用できる計算列を作成します。 その後で、新しい計算列にインデックスを作成します。 この例では、JSON データの $.Customer.Name パスに格納されている顧客名を公開する列を作成します。
ALTER TABLE Sales.SalesOrderHeader
ADD vCustomerName AS JSON_VALUE(Info,'$.Customer.Name')
CREATE INDEX idx_soh_json_CustomerName
ON Sales.SalesOrderHeader(vCustomerName)
このステートメントは、次の警告を返します。
Warning! The maximum key length for a nonclustered index is 1700 bytes.
The index 'vCustomerName' has maximum length of 8000 bytes.
For some combination of large values, the insert/update operation will fail.
JSON_VALUE 関数は、8000 バイトまでのテキスト値を返すことができます (たとえば、nvarchar(4000) 型として)。 ただし、1700 バイトより長い値にインデックスを付けることはできません。 1700 バイトより長いインデックス付き計算列に値を入力しようとすると、データ操作言語 (DML) 操作は失敗します。
パフォーマンスを向上させるには、計算列を使用して公開した値を、適用可能な最小のデータ型にキャストしてみてください。 文字列型ではなく、int および datetime2 型を使用してください。
計算列に関するその他の情報
計算列は保存されません。 計算列はインデックスを再構築する必要がある場合にのみ計算されます。 これでは、テーブルのその他の領域を占有しません。
計算列は、クエリで使用するのと同じ式を使用して作成することが重要です。この例では、式は JSON_VALUE(Info, '$.Customer.Name') です。
クエリは書き直す必要はありません。 JSON_VALUE 関数を含む式を使用する場合、前述の例のクエリのように、SQL Server は同じ式を使用する同等な計算列が存在することを確認し、可能であればインデックスを適用します。
この例の実行プラン
この例のクエリの実行プランを次に示します。
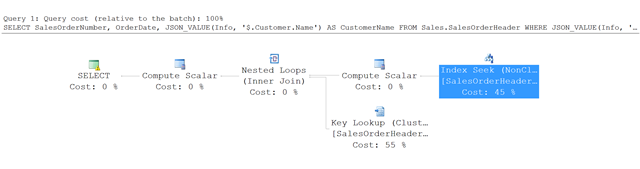
SQL Server では、テーブルを完全にスキャンするのではなく、非クラスター化インデックスに index seek を使用し、指定した条件に一致する行を探します。 次に、SalesOrderHeader テーブルでキー参照を使って、クエリで参照される他の列 (この例では SalesOrderNumber と OrderDate) をフェッチします。
付加列でインデックスをさらに最適化する
インデックスに必要な列を追加すれば、テーブルでこの追加の参照を回避できます。 これらの列は、次の例のとおり標準の付加列として追加できます。これは、前述の CREATE INDEX の例を拡張します。
CREATE INDEX idx_soh_json_CustomerName
ON Sales.SalesOrderHeader(vCustomerName)
INCLUDE(SalesOrderNumber,OrderDate)
この場合、必要なものがすべて JSON の非クラスター化インデックスに含まれているため、SQL Server は SalesOrderHeader テーブルから追加のデータを読み取る必要はありません。 このインデックスの種類は、JSON と列データをクエリに結合し、ワークロードに最適なインデックスを作成するよい方法です。
照合順序対応のインデックスである JSON インデックス
JSON データに対するインデックスの重要な機能は、インデックスが照合順序に対応することです。 計算列の作成に使う JSON_VALUE 関数の結果は、入力式からその照合順序を継承するテキスト値です。 そのため、インデックス内の値は、ソース列で定義されている照合順序規則を使用して並べ替えられています。
インデックスが照合順序対応であることを示すために、次の例では、主キーと JSON コンテンツを使用して単純なコレクション テーブルを作成します。
CREATE TABLE JsonCollection
(
id INT IDENTITY CONSTRAINT PK_JSON_ID PRIMARY KEY,
[json] NVARCHAR(MAX) COLLATE SERBIAN_CYRILLIC_100_CI_AI
CONSTRAINT [Content should be formatted as JSON]
CHECK(ISJSON(json)>0)
)
上記のコマンドでは、json 列でのセルビア語 (キリル) の照合順序を指定しています。 次の例では、テーブルに入力し、name プロパティにインデックスを作成します。
INSERT INTO JsonCollection
VALUES
(N'{"name":"Иво","surname":"Андрић"}'),
(N'{"name":"Андрија","surname":"Герић"}'),
(N'{"name":"Владе","surname":"Дивац"}'),
(N'{"name":"Новак","surname":"Ђоковић"}'),
(N'{"name":"Предраг","surname":"Стојаковић"}'),
(N'{"name":"Михајло","surname":"Пупин"}'),
(N'{"name":"Борислав","surname":"Станковић"}'),
(N'{"name":"Владимир","surname":"Грбић"}'),
(N'{"name":"Жарко","surname":"Паспаљ"}'),
(N'{"name":"Дејан","surname":"Бодирога"}'),
(N'{"name":"Ђорђе","surname":"Вајферт"}'),
(N'{"name":"Горан","surname":"Бреговић"}'),
(N'{"name":"Милутин","surname":"Миланковић"}'),
(N'{"name":"Никола","surname":"Тесла"}')
GO
ALTER TABLE JsonCollection
ADD vName AS JSON_VALUE(json,'$.name')
CREATE INDEX idx_name
ON JsonCollection(vName)
上記のコマンドは計算列 vName に標準的なインデックスを作成します。これはJSON の $.name プロパティからの値を表します。 セルビア語 (キリル) のコードページでは、文字の順序は、А、Б、В、Г、Д、Ђ、Е などです。JSON_VALUE 関数の結果は、ソース列からの照合順序を継承するため、インデックスの項目の順序はセルビア語 (キリル) の規則に準拠しています。 次の例では、このコレクションにクエリを実行し、結果を名前で並べ替えます。
SELECT JSON_VALUE(json,'$.name'),*
FROM JsonCollection
ORDER BY JSON_VALUE(json,'$.name')
実際の実行計画を見ると、非クラスター化インデックスからの並べ替えられた値を使用していることがわかります。

クエリには ORDER BY 句がありますが、実行プランでは、Sort 演算子は使用しません。 JSON インデックスは既にセルビア語 (キリル) の規則に従って並んでいます。 したがって、結果が既に並べ替えられている場合、SQL Server は非クラスター化インデックスを使用できます。
ただし、JSON_VALUE 関数の後に COLLATE French_100_CI_AS_SC を追加するなど、ORDER BY 式の照合順序を変更した場合、得られるクエリ実行プランは異なります。

インデックス内の値の順序はフランス語の照合順序の規則を準拠していないために、SQL Server では、結果の順序付けにそのインデックスを使用できません。 したがって、フランス語の照合順序の規則を使用して結果を並べ替える Sort 演算子が追加されます。
Microsoft ビデオ
Note
このセクションのビデオ リンクの一部は、現時点では機能しない場合があります。 Microsoft では、以前 Channel 9 上にあったコンテンツの新しいプラットフォームへの移行作業を進めています。 ビデオが新しいプラットフォームに移行されるに従ってリンクを更新します。
SQL Server と Azure SQL Database に組み込まれている JSON のサポートの視覚的な紹介は、次のビデオをご覧ください。