SQL Server と Azure SQL のインデックスのアーキテクチャとデザイン ガイド
適用対象: ![]() SQL Server
SQL Server ![]() Azure SQL データベース
Azure SQL データベース ![]() Azure SQL Managed Instance
Azure SQL Managed Instance ![]() Azure Synapse Analytics
Azure Synapse Analytics ![]() Analytics Platform System (PDW)
Analytics Platform System (PDW)
不完全なデザインのインデックスやインデックスの不備は、データベース アプリケーションのボトルネックの主な原因となります。 効率的なインデックスのデザインは、データベースとアプリケーションの高パフォーマンスを実現するための最優先事項です。 このインデックス デザイン ガイドには、インデックスのアーキテクチャに関する情報と、効果的なインデックスをデザインしてアプリケーションのニーズを満たすために役立つベスト プラクティスが含まれています。
このガイドでは、使用できるインデックスの種類に関して一般的な知識があることを前提としています。 インデックスの種類に関する全般的な説明については、「インデックス」を参照してください。
このガイドでは、次のインデックスの種類について説明します。
| プライマリ ストレージの形式 | インデックスの種類 |
|---|---|
| ディスク ベースの行ストア | |
| クラスター化インデックス | |
| 非クラスター化インデックス | |
| [一意] | |
| フィルター済み | |
| Columnstore | |
| クラスター化列ストア | |
| 非クラスター化列ストア | |
| メモリ最適化 | |
| ハッシュ | |
| メモリ最適化された非クラスター化 |
XML インデックスについては、「XML インデックス (SQL Server)」および「選択的 XML インデックス (SXI)」をご覧ください。
空間インデックスについては、「空間インデックスの概要」をご覧ください。
フルテキスト インデックスの詳細については、「フルテキスト インデックスの作成」を参照してください。
インデックスのデザインの基礎
通常の書籍について考えてみましょう。書籍の最後には、その書籍内の情報をすばやく検索するのに役立つインデックスがあります。 インデックスは、並べ替えられたキーワードのリストであり、各キーワードの横には、各キーワードが記載されているページを指す一連のページ番号があります。
行ストア インデックスでも同様で、順序付けされた値のリストであり、値ごとに、これらの値が記載されているデータ ページへのポインターがあります。 インデックス自体は、インデックス ページと呼ばれるページに格納されます。 通常の書籍では、インデックスが複数のページにまたがっており、たとえば SQL という単語が含まれるすべてのページへのポインターを見つける必要がある場合は、キーワードである SQL を含むインデックス ページが見るかるまで、ページをめくる必要があります。 そこから、書籍のすべてのページへのポインターに従います。 インデックスの先頭で、各文字が見つかるアルファベット順のリストが記載されたページを 1 ページを作成すれば、さらに最適化されます。 "A から D - 121 ページ"、"E から G - 122 ページ" など。 この追加ページがあれば、インデックスのページをめくって始まりの場所を見つける手順を省くことができます。 このようなページは、通常の書籍にはありませんが、行ストア インデックスにはあります。 この 1 ページは、インデックスのルート ページと呼ばれます。 ルート ページとは、インデックスによって使用されるツリー構造の開始ページです。 ツリーの比喩で言えば、実際のデータへのポインターを含む最終ページは、ツリーの "リーフ ページ" と呼ばれます。
インデックスとは、テーブルまたはビューに関連付けられたディスク上またはメモリ内の構造で、テーブルやビューからの行の取得を高速化します。 行ストア インデックスには、テーブル内またはビュー内の 1 つ以上の列から構築されたキーが含まれています。 行ストア インデックスの場合、これらのキーは 1 つのツリー構造 (B+ ツリー) 内に格納されます。データベース エンジンはこの構造を使用して、キー値に関連付けられた 1 つ以上の行を効率よく迅速に検出できます。
行ストア インデックスでは、論理的には、行と列があるテーブルとして編成されたデータが格納されます。また物理的には、"行ストア" 1 と呼ばれる行単位のデータ形式、または "列ストア" と呼ばれる列単位のデータ形式で格納されます。
データベースとワークロードに適したインデックスの選択は、クエリの速度と更新コストのバランスを取る必要がある複雑な作業です。 インデックス キー内の列数が少ないディスク ベースの行ストア インデックスを使用すると、ディスク領域とメンテナンスのオーバーヘッドが少なくて済みます。 これに対して、列数の多いインデックスを使用すると、より多くのクエリに対応できます。 効率の高いインデックスを決定するには、さまざまなデザインをテストする必要があります。 インデックスは、データベース スキーマやアプリケーションのデザインに影響を与えずに追加、変更、および削除できます。 さまざまなデザインのインデックスを積極的にテストするようにしてください。
データベース エンジンのクエリ オプティマイザーでは、多くの場合、最も効率的なインデックスが選択されます。 インデックスのデザインの全体的な考え方としては、クエリ オプティマイザーでインデックスを選択するための選択肢として、さまざまなデザインのインデックスを用意し、オプティマイザーに決定を任せる必要があります。 このようにすると、分析時間を短縮でき、さまざまな状況でパフォーマンスを向上できます。 クエリ オプティマイザーで特定のクエリに使用されるインデックスを確認するには、SQL Server Management Studioで、 クエリ メニューの 実際の実行プランを含めるを選択します。
インデックスを使用しても、常にパフォーマンスが向上するわけではありません。また、パフォーマンスが優れていても、常にインデックスが効率的に使用されているわけでもありません。 インデックスを使用すれば常にパフォーマンスが向上するならば、クエリ オプティマイザーのジョブは単純です。 しかし実際には、不適切なインデックスを選択すると、最適なパフォーマンスを実現することはできません。 したがって、クエリ オプティマイザーでは、パフォーマンスが向上する場合にのみインデックスまたはインデックスの組み合わせが選択され、パフォーマンスが低下する場合、インデックス付き検索は実行されません。
1 列ストアは、リレーショナル テーブル データを格納する従来の方法です。 行ストア は、基になるデータ ストレージ形式が、ヒープ、B+ ツリー (クラスター化インデックス)、またはメモリ最適化テーブルであるテーブルを示します。 ディスクベースの行ストアでは、メモリ最適化テーブルは除外されます。
インデックスのデザインの作業
インデックスをデザインするには、次の作業を行うことをお勧めします。
データベース自体の特性を理解します。
- たとえば、頻繁なデータ変更を伴い、高スループットを維持する必要があるオンライン トランザクション処理 (OLTP) データベースですか? このようなシナリオには、ラッチフリー デザインが提供されているメモリ最適化テーブルとインデックスが特に適しています。 詳細については、「メモリ最適化テーブルのインデックス」、またはこのガイドの「メモリ最適化非クラスター化インデックスのデザイン ガイドライン」と「ハッシュ インデックスのデザイン ガイドライン」を参照してください。
- あるいは、大規模なデータセットをすばやく処理する必要がある意思決定支援システム (DSS) またはデータ ウェアハウス (OLAP) データベースの例ですか? 列ストア インデックスは、一般的なデータ ウェアハウスのデータ セットに特に適しています。 列ストア インデックスによって、フィルター処理クエリ、集計クエリ、グループ化クエリ、スター結合クエリなどの一般的なデータ ウェアハウス クエリのパフォーマンスを向上することで、ユーザーが快適にデータ ウェアハウスを利用できるようになります。 詳細については、「列ストア インデックス: 概要」、またはこのガイドの「列ストア インデックスのデザイン ガイドライン」を参照してください。
最もよく使用されるクエリの特性を理解します。 たとえば、よく使用されるクエリの中に、複数のテーブルを結合するクエリがあることを把握していると、使用する最適なインデックスの種類を決定するときに役立ちます。
クエリで使用される列の特性を理解します。 たとえば、整数データ型を格納する列で、一意の列または NULL 値を許容しない列であれば、インデックスに適しています。 適切に定義されたデータのサブセットが含まれている列に対し、SQL Server 2008 (10.0.x)以上のバージョンでは、フィルター選択されたインデックスを使用できます。 詳細については、このガイドの「フィルター選択されたインデックスのデザイン ガイドライン」を参照してください。
インデックスの作成時またはメンテナンス時のパフォーマンスを向上させることができるインデックス オプションを決定します。 たとえば、既存の大きなテーブルにクラスター化インデックスを作成する際には
ONLINEインデックス オプションが有益です。ONLINEオプションを使用すると、インデックスの作成中または再構築中に、基になるデータで同時処理を続行できます。 詳細については、「 インデックス オプションの設定」を参照してください。インデックスの最適な格納場所を決定します。
非クラスター化インデックスは、基になるテーブルと同じファイル グループまたは別のファイル グループに格納できます。 インデックスの格納場所により、ディスク I/O のパフォーマンスが向上し、その結果クエリのパフォーマンスを向上させることができます。 たとえば、非クラスター化インデックスを、テーブル ファイル グループとは別のディスク上にあるファイル グループに格納すると、複数のディスクを同時に読み取ることができるため、パフォーマンスが向上します。 また、クラスター化インデックスと非クラスター化インデックスでは、複数のファイル グループにまたがってパーティション構成を使用できます。 パーティション分割を検討するときは、インデックスを固定するかどうかを決定します。つまり、基本的にテーブルと同じ方法でパーティション分割するか、または別の方法でパーティション分割するかを決定するということです。 詳細については、この記事の「ファイル グループまたはパーティション構成に対するインデックス配置」セクションを参照してください。
sys.dm_db_missing_index_details や sys.dm_db_missing_index_columns などの動的管理ビュー (DMV) で欠落しているインデックスを特定すると、同じテーブルと列に対して同様のバリエーションのインデックスが提供される場合があります。 重複するインデックスが作成されるのを防ぐために、テーブル上の既存のインデックスと、不足しているインデックスの候補を調べてください。 詳細については、「インデックスの候補が見つからない、クラスター化されていないインデックスを調整する」を参照してください。
インデックスのデザインの全般的なガイドライン
経験豊富なデータベース管理者であれば適切なインデックス セットをデザインできますが、それほど複雑でないデータベースとワークロードであっても、この作業は複雑で、時間がかかり、間違いを犯しやすいものです。 使用するデータベース、クエリ、データ列の特性を理解することが、最適なインデックスをデザインする際に役に立ちます。
データベースの考慮事項
インデックスをデザインするときは、次のデータベースのガイドラインを考慮してください。
1 つのテーブルに多数のインデックスがあると、テーブル内のデータが変更された場合にインデックスをすべて調整する必要があるので、
INSERT、UPDATE、DELETE、およびMERGEの各ステートメントのパフォーマンスに影響します。 たとえば、列が複数のインデックスで使用されており、この列のデータを変更するUPDATEステートメントを実行する場合は、その列が含まれている各インデックスも、基になるベース テーブル (ヒープまたはクラスター化インデックス) と同様に更新する必要があります。頻繁に更新するテーブルにはインデックスをデザインしすぎないようにし、インデックスの幅を狭く、つまり列数を可能な限り少なくします。
更新の必要が少なく、容量の大きいテーブルの場合、クエリのパフォーマンスを向上させるにはインデックスを多数使用します。
SELECTステートメントなど、データを変更しないクエリの場合は、多数のインデックスを使用することで、クエリ オプティマイザーが最速のアクセス方法を決定する際に選択できるインデックスが多くなるため、クエリのパフォーマンスを向上できる可能性があります。
小さなテーブルではインデックスを作成しない方がよい場合もあります。これは、クエリ オプティマイザーが基本的なテーブル スキャンを実行するよりデータのインデックスを検索する方に時間がかかることがあるためです。 そのため、小さなテーブルのインデックスがまったく使用されない可能性があっても、テーブルのデータの変更に合わせてメンテナンスする必要があります。
ビューが集計、テーブル結合、または集計と結合の組み合わせを使用している場合、ビューにインデックスを設定すると、パフォーマンスが大幅に向上します。 クエリで明示的に参照しなくても、クエリ オプティマイザーはそのビューを使用します。
Azure SQL Database のプライマリ レプリカのデータベースでは、インデックスに対するデータベースアドバイザーのパフォーマンスに関する推奨事項が自動的に生成されます。 必要に応じて、インデックスの自動チューニングを有効にすることができます。
クエリ ストアは、パフォーマンスの低いクエリを識別し、オプティマイザーによって選択されたインデックスをドキュメント化するクエリ実行プランの履歴を提供します。
クエリの考慮事項
インデックスをデザインするときは、次のクエリのガイドラインを考慮してください。
クエリの述語や結合条件で頻繁に使用される列に対して非クラスター化インデックスを作成します。 これらは、SARGable1 列です。 ただし、不要な列を追加しないようにする必要があります。 インデックス列を追加しすぎると、必要なディスク領域が増え、インデックスのメンテナンスのパフォーマンスも低下する可能性があります。
クエリの対象にインデックスを含めると、クエリのパフォーマンスを向上できます。これは、クエリの要件を満たすために必要なデータがすべて、インデックス自体に保持されているためです。 つまり、要求されたデータの取得に必要なのはインデックス ページだけで、テーブルやクラスター化インデックスのデータ ページは必要ありません。このため、全体的にディスク I/O を削減できます。 たとえば、テーブルの列
AとBに対するクエリは、このテーブルに列A、B、Cに基づく複合インデックスが作成されていれば、インデックスのみから指定したデータを取得できます。カバリング インデックスは、ベース テーブルにアクセスせず、参照を行わずに、1 つまたは複数の似たクエリの結果を直接解決する非クラスター化インデックスに対する指定です。
そのようなインデックスは、すべての必要な非 SARGable 列をそれ自体のリーフ レベルに持っています。 つまり、
SELECT句およびすべてのWHERE引数とJOIN引数によって返される列はインデックスによってカバーされます。テーブル自体の行と列に比べてインデックスが十分に狭い場合 (つまり、列全体の実際のサブセットである)、クエリ実行の I/O がずっと少なくなる可能性があります。
大きいテーブルの小さい部分を選択し、その小さい部分が固定の述語によって定義されている場合 (たとえば、少数の非 NULL 値のみを含むスパース列など)、カバリング インデックスを検討してください。
複数のクエリを使用して同じ行を更新するよりも、1 つのステートメントでできるだけ多くの行を挿入または変更するクエリを作成します。 ステートメントを 1 つだけ使用することで、インデックスのメンテナンスを最適化できます。
クエリの種類とクエリ内での列の使用方法を評価します。 たとえば、完全一致検索クエリで使用される列は、非クラスター化インデックスまたはクラスター化インデックスにする適切な候補になります。
1 リレーショナル データベースにおける SARGable という用語は、インデックスを利用してクエリの実行速度を上げることができる、検索引数可能 (Search ARGument-able) な述語を意味します。
列に関する考慮事項
インデックスをデザインするときは、次の列のガイドラインを考慮してください。
クラスター化インデックスのインデックス キー長は長くならないようにします。 また、クラスター化インデックスは一意列や非 NULL 列に作成すると効率的です。
ntext、 text、 image、 varchar(max)、 nvarchar(max)、および varbinary(max) データ型の列を、インデックス キー列として指定することはできません。 ただし、 varchar(max)、 nvarchar(max)、 varbinary(max)、および xml データ型は、インデックスの非キー列として非クラスター化インデックスに含めることができます。 詳細については、このガイドの 「付加列インデックス」に関するセクションを参照してください。
xml データ型は、XML インデックスでのみキー列にできます。 詳細については、「XML インデックス (SQL Server)」を参照してください。 SQL Server 2012 SP1 では、選択的 XML インデックスと呼ばれる新しい種類の XML インデックスが導入されました。 この新しいインデックスを使用すると、XML 形式で格納されたデータに対するクエリのパフォーマンスが向上するため、XML データの大量のワークロードに対するインデックスの設定が高速になります。また、インデックス自体のストレージ コストを削減できるため、スケーラビリティも向上します。 詳細については、「選択的 XML インデックス (SXI)」を参照してください。
列の一意性を調べます。 同じ列の組み合わせに対して一意でないインデックスを作成するよりも一意インデックスを作成する方が、クエリ オプティマイザーに追加情報が提供され、インデックスの利用価値が高まります。 詳細については、このガイドの「一意なインデックスのデザイン ガイドライン」を参照してください。
列内のデータの分布を調べます。 インデックスを設定した列にほとんど一意の値がない場合や、このような列を結合する場合、クエリに時間がかかることがよくあります。 これは、データとクエリにかかわる根本的な問題で、通常はこのような状況を特定しなければ解決できません。 たとえば、姓がアルファベット順に並んだ電話帳では、対象地域のすべての人が Smith や Jones という姓である場合、特定の人を探すときに役に立ちません。 データ分布の詳細については、「 統計」を参照してください。
スパース列、ほとんどが
NULL値の列、さまざまなカテゴリの値を含む列、および異なる範囲の値を含む列のようなサブセットが明確に定義されている列では、フィルター選択されたインデックスの使用を検討してください。 フィルター選択されたインデックスを適切に設計すると、クエリのパフォーマンスが向上し、インデックスのメンテナンス コストとストレージ コストを削減できます。インデックスに複数の列が含まれる場合は、列の順序を考慮します。 等しい (
WHERE)、より大きい (=)、より小さい (>)、<などの検索条件のBETWEEN句で使用されるか、結合に含まれる列は、先頭に配置します。 その他の列は、差異の程度、つまり最も差異の大きいものから最も差異の小さいものの順に配置します。たとえば、インデックスが
LastName、FirstNameとして定義されている場合、このインデックスは、検索条件がWHERE LastName = 'Smith'またはWHERE LastName = Smith AND FirstName LIKE 'J%'である場合に効果があります。 ただし、クエリ オプティマイザーでは、FirstName (WHERE FirstName = 'Jane')のみで検索するクエリには、このインデックスが使用されません。計算列のインデックス設定を検討します。 詳細については、「計算列のインデックス」を参照してください。
インデックスの特性
クエリにインデックスを設定することが適切であると判断した場合は、状況に応じて最適な種類のインデックスを選択します。 インデックスの特性には、次のリストが含まれます。
- クラスター化と非クラスター化
- 一意と非一意
- 単一列と複数列
- 昇順と降順 (インデックス内の列の並び)
- テーブル全体の非クラスター化インデックスとフィルター選択された非クラスター化インデックス
- 列ストアと行ストア
- メモリ最適化テーブル用のハッシュ インデックスと非クラスター化インデックス
インデックスを最初に保存したときの特性をカスタマイズし、FILLFACTOR などのオプションを設定してパフォーマンスやメンテナンスを最適化できます。 また、パフォーマンスを最適化するために、ファイル グループやパーティション構成を使用してインデックスの保存場所を決定することもできます。
ファイル グループまたはパーティション構成に対するインデックス配置
インデックスの設計について考えるときは、データベースに関連付けられたファイル グループ上にインデックスを配置することを検討する必要があります。 ファイル グループまたはパーティション構成を慎重に選択することで、クエリのパフォーマンスを向上できる場合があります。
既定では、インデックスが作成されるベース テーブルと同じファイル グループにインデックスも格納されます。 パーティション分割されていないクラスター化インデックスおよびベース テーブルは、常に同じファイル グループに存在します。 しかし、次の手順を実行できます。
- ベース テーブルまたはクラスター化インデックスのファイル グループ以外のファイル グループに、非クラスター化インデックスを作成する。
- 複数のファイル グループにまたがるクラスター化インデックスおよび非クラスター化インデックスをパーティション分割する。
- あるファイル グループから別のファイル グループにテーブルを移動する。この操作を行うには、クラスター化インデックスを削除して
MOVE TOステートメントのDROP INDEX句に新しいファイル グループまたはパーティション構成を指定するか、CREATE INDEX句を指定したDROP_EXISTINGステートメントを使用します。
異なるファイル グループに非クラスター化インデックスを作成した場合、そのファイル グループが独自のコントローラーを持つ異なる物理ドライブを使用していると、パフォーマンスの向上を実現できます。 データおよびインデックス情報は、複数のディスク ヘッドにより並列で読み込めるようになります。 たとえば、ファイル グループ Table_A の f1 とファイル グループ Index_A の f2 が同じクエリで使用される場合、両ファイル グループが競合することなく完全に使用されるため、パフォーマンスが向上します。 ただし、クエリによって Table_A がスキャンされる場合でも、 Index_A が参照されていないと、ファイル グループ f1 のみが使用されます。 この場合、パフォーマンスは向上しません。
アクセスの種類や実行のタイミングは事前には予測できないため、テーブルとインデックスをすべてのファイル グループにわたって分散しておくことをお勧めします。 すべてのデータとインデックスが、すべてのディスクにわたって均等に分散されていれば、どのような方法でデータへのアクセスが行われても、確実にすべてのディスクがアクセスされます。 この方法は、システム管理者にとっても簡単な方法になります。
複数のファイル グループでのパーティション分割
複数のファイル グループにわたるディスク ベースのクラスター化および非クラスター化のインデックスをパーティション分割することもできます。 パーティション インデックスは、パーティション関数に基づいて、行方向または行ごとにパーティション分割されます。 パーティション関数では、パーティション分割列と呼ばれる特定の列の値に基づいて、一連のパーティションに各行をどのようにマップするのかを定義します。 パーティション構成では、一連のファイル グループにパーティションをマップするように指定します。
インデックスをパーティション分割すると、次のような利点があります。
大きなインデックスがより管理しやすくなるスケーラブルなシステムを提供できる。 たとえば OLTP システムで、大きなインデックスを扱うパーティション対応のアプリケーションを実装できます。
クエリをより高速かつ効率的に実行できる。 クエリからインデックスのいくつかのパーティションへアクセスしたときに、クエリ オプティマイザーでは個別のパーティションを同時に処理し、クエリによる影響を受けないパーティションを除外できます。
詳細については、「パーティション テーブルとインデックス」を参照してください。
インデックス並べ替え順のデザイン ガイドライン
インデックスを定義する場合は、インデックス キー列のデータを昇順と降順のどちらで格納する必要があるかを考慮してください。 昇順は既定の並べ替え順で、以前のバージョンのデータベース エンジンとの互換性が維持されます。 CREATE INDEX、CREATE TABLE、および ALTER TABLE の各ステートメントの構文では、インデックスと制約の個別の列にキーワード ASC (昇順) と DESC (降順) を使用できます。
インデックスにキー値が格納される順序を指定することは、テーブルを参照しているクエリに ORDER BY 句があり、そのインデックスの 1 つ以上のキー列が ORDER BY 句によって異なる方向に指定されている場合に役立ちます。 このような場合、インデックスにより、クエリ プランで SORT 演算子を実行する必要がなくなるので、クエリをより効率的に実行できるようになります。 たとえば、Adventure Works Cyclesの購買部のバイヤーが、業者から購入する製品の品質を評価する必要がある場合について考えてみます。 バイヤーにとって最も関心があるのは、これらの業者から配送された製品の中から、返品率の高い製品を見つけ出すことです。
AdventureWorks サンプル データベースに対する次のクエリに示すように、この基準を満たすデータを取得するには、RejectedQty テーブルの Purchasing.PurchaseOrderDetail 列を降順 (大から小) に並べ替え、ProductID 列を昇順 (小から大) に並べ替える必要があります。
SELECT RejectedQty, ((RejectedQty/OrderQty)*100) AS RejectionRate,
ProductID, DueDate
FROM Purchasing.PurchaseOrderDetail
ORDER BY RejectedQty DESC, ProductID ASC;
GO
次に示すこのクエリの実行プランは、クエリ オプティマイザーにより SORT 演算子が使用され、ORDER BY 句で指定された順序で結果セットが返されたことを示します。

作成したディスク ベースの行ストア インデックスのキー列がクエリの ORDER BY 句で使用するキー列と一致する場合、クエリ プランの SORT 演算子を削除できるので、クエリ プランがより効率的になります。
CREATE NONCLUSTERED INDEX IX_PurchaseOrderDetail_RejectedQty
ON Purchasing.PurchaseOrderDetail
(RejectedQty DESC, ProductID ASC, DueDate, OrderQty);
GO
もう一度クエリを実行した後、次の実行プランは、SORT 演算子が削除され、新しく作成された非クラスター化インデックスが使用されたことを示します。
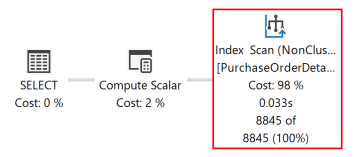
データベース エンジンは、どちらの方向でも同じように効率的に移動します。 (RejectedQty DESC, ProductID ASC) として定義されたインデックスは、ORDER BY 句の列の並べ替え方向が逆転されたクエリで引き続き使用できます。 たとえば、ORDER BY 句 ORDER BY RejectedQty ASC, ProductID DESC が含まれたクエリでは、このインデックスを使用できます。
並べ替え順序は、インデックスでキー列のみに指定できます。 sys.index_columns カタログ ビューと INDEXKEY_PROPERTY 関数により、インデックス列が昇順と降順のどちらで格納されているかが報告されます。
AdventureWorks サンプル データベースのコード例に従っている場合は、次の Transact-SQL を使用して IX_PurchaseOrderDetail_RejectedQty を削除できます。
DROP INDEX IX_PurchaseOrderDetail_RejectedQty
ON Purchasing.PurchaseOrderDetail;
GO
Metadata
これらのメタデータ ビューを使って、インデックスの属性を表示します。 多くのアーキテクチャ情報が、これらのビューの一部に埋め込まれます。
列ストア インデックスの場合、すべての列は付加列としてメタデータに格納されます。 列ストア インデックスはキー列を持ちません。
- sys.column_store_dictionaries
- sys.column_store_row_groups
- sys.column_store_segments
- sys.dm_column_store_object_pool
- sys.dm_db_column_store_row_group_operational_stats
- sys.dm_db_column_store_row_group_physical_stats
- sys.dm_db_index_operational_stats
- sys.dm_db_index_physical_stats
- sys.dm_db_xtp_hash_index_stats
- sys.dm_db_xtp_index_stats
- sys.dm_db_xtp_nonclustered_index_stats
- sys.dm_db_xtp_object_stats
- sys.dm_db_xtp_table_memory_stats
- sys.hash_indexes
- sys.index_columns
- sys.indexes
- sys.internal_partitions
- sys.memory_optimized_tables_internal_attributes
- sys.partitions
クラスター化インデックスの設計ガイドライン
クラスター化インデックスは、データ行をそのキー値に基づいて並べ替え、テーブル内に格納します。 データ行自体は 1 つの順序でしか並べ替えられないため、1 つのテーブルに設定できるクラスター化インデックスは 1 つだけです。 ほとんどの場合、各テーブルには、次の条件を満たす単一または複数の列に基づいて定義されたクラスター化インデックスを作成することをお勧めします。
頻繁に使用されるクエリに使用可能。
一意性が高い。
Note
PRIMARY KEY制約を作成すると、単一または複数の列に基づく一意のインデックスが自動的に作成されます。 既定では、クラスター化インデックスが作成されますが、制約を作成する際に非クラスター化インデックスを作成するように指定することもできます。範囲クエリで使用可能。
UNIQUEプロパティを指定せずにクラスター化インデックスが作成された場合、 データベース エンジンにより、4 バイトの uniqueifier 列が自動的にテーブルに追加されます。 必要があれば、各キーを一意にするため、データベース エンジンにより自動的に uniqueifier 値が行に追加されます。 この列とその値は、内部的に使用されるもので、ユーザーが参照したりアクセスすることはできません。
クラスター化インデックスのアーキテクチャ
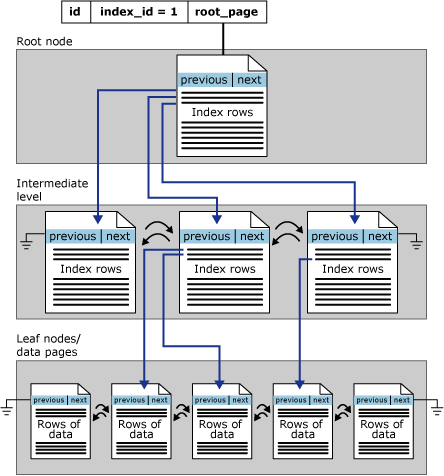
行ストア インデックスは、B+ ツリーとして構成されます。 インデックス B+ ツリー内の各ページをインデックス ノードと呼びます。 B+ ツリーの最上位ノードはルート ノードといいます。 インデックス内の最下位ノードをリーフ ノードと呼びます。 ルート ノードとリーフ ノードの間にあるインデックス レベルは、総称して中間レベルといいます。 クラスター化インデックスでは、リーフ ノードに基になるテーブルのデータ ページが含まれています。 ルート ノードと中間レベル ノードには、インデックス行を保持するインデックス ページが含まれています。 各インデックス行には、キー値と、B+ ツリー内の中間レベル ページかインデックスのリーフ レベルのデータ行のいずれかへのポインターが含まれています。 インデックスの各レベルのページは、二重にリンクされた一覧でリンクされています。
クラスター化インデックスの場合、sys.partitionsにはインデックスで使用されるパーティションごとに 1 つの行が含まれます。この場合、index_id = 1 となります。 既定では、クラスター化インデックスのパーティションは 1 つです。 クラスター化インデックスにパーティションが複数ある場合、各パーティションは、そのパーティションのデータを保持する B+ ツリー構造になります。 たとえば、クラスター化インデックスに 4 つのパーティションがある場合、4 つの B+ ツリー構造になります。この場合、パーティションごとに 1 つの B+ ツリーがあります。
クラスター化インデックスのデータ型によっては、各クラスター化インデックスの構造に 1 つ以上のアロケーション ユニットが含まれ、そこに特定のパーティションのデータが格納され、管理されます。 各クラスター化インデックスには、パーティションごとに、少なくとも 1 つの IN_ROW_DATA アロケーション ユニットがあります。 また、クラスター化インデックスにラージ オブジェクト (LOB) 列が含まれている場合は、パーティションごとに 1 つの LOB_DATA アロケーション ユニットもあります。 さらに、行サイズの上限である 8,060 バイトを超える可変長列が含まれている場合は、パーティションごとに 1 つの ROW_OVERFLOW_DATA アロケーション ユニットがあります。
データ チェーン内のページとページ内の行は、クラスター化インデックス キーの値に基づいて並べ替えられます。 挿入はすべて、挿入される行のキー値が、順序付けられた既存の行の並びの中に正しく収まる位置で行われます。
次の図は、1 つのパーティション内のクラスター化インデックスの構造を示します。
クエリの考慮事項
クラスター化インデックスを作成する前に、データがどのようにアクセスされるかを理解しておいてください。 次の処理を行うクエリには、クラスター化インデックスを使用することを検討してください。
BETWEEN、>、>=、<、<=などの演算子を使用して、ある範囲の値を返す。クラスター化インデックスを使用して最初の値を持つ行が検索されると、後続のインデックス値がある行は物理的に必ず隣接しています。 たとえば、クエリである範囲内の販売注文番号を持つ行を取得する場合、
SalesOrderNumber列のクラスター化インデックスを使用すると、最初の販売注文番号を含む行をすばやく検索して、最後の販売注文番号に達するまでテーブル内の後続の行をすべて取得できます。大きな結果セットを返す。
JOIN句を使用する。通常、これらは外部キー列になります。複数の
ORDER BY句またはGROUP BY句を使用する。ORDER BYまたはGROUP BY句に指定した列にインデックスが設定されている場合は、行が既に並べ替えられているため、データベース エンジンがデータを並べ替える必要がなくなることがあります。 このような場合は、クエリ パフォーマンスが向上します。
列に関する考慮事項
通常は、クラスター化インデックス キーの定義に使用する列はできるだけ少なくする必要があります。 次の 1 つ以上の条件を満たす列を使用するようにしてください。
一意な値または多数の異なる値を含む。
たとえば、従業員 ID は、従業員を一意に識別します。
EmployeeID列にクラスター化インデックスまたは PRIMARY KEY 制約を設定すると、従業員 ID 番号に基づいて従業員情報を検索するクエリのパフォーマンスが向上します。 また、LastName列、FirstName列、MiddleName列を基にクラスター化インデックスを作成することもできます。従業員レコードは、これらの列でグループ化されたりクエリが実行されることが多く、これらの列を組み合わせると高い多様性が生まれます。ヒント
別で指定をしない場合、PRIMARY KEY 制約を作成するときに、データベース エンジンによってその制約をサポートするクラスター化インデックスが作成されます。
PRIMARY KEYとして一意性を適用するために uniqueidentifier を使用できますが、これは効率的なクラスター化キーではありません。PRIMARY KEYとして uniqueidentifier を使用する場合は、非クラスター化インデックスとして作成し、IDENTITYなどの別の列を使用してクラスター化インデックスを作成することをお勧めします。順次アクセスされる。
たとえば、製品 ID は、
Production.ProductデータベースのAdventureWorks2022テーブルにある製品を一意に識別します。WHERE ProductID BETWEEN 980 and 999など、順次検索が指定されているクエリでは、ProductID列に基づくクラスター化インデックスによりパフォーマンスが向上する場合があります。 これは、行がこのキー列を基に並べ替えて格納されている場合があるためです。IDENTITYとして定義されている。テーブルから取得したデータの並べ替えに頻繁に使用される。
このような列を基にテーブルをクラスター化する (つまり、物理的に並べ替える) と、この列に対してクエリを実行するたびに並べ替えにかかるコストを節約できるため便利です。
次のような場合は、クラスター化インデックスの使用は適していません。
頻繁に変更される列
データベース エンジンでは各行のデータ値を物理的な順序で維持する必要があるので、データが変更されると行全体が移動します。 データが頻繁に変更される大規模トランザクション処理システムでは、特にこの点に留意してください。
広範なキー
広範なキーは、複数の列または複数のサイズの大きな列を組み合わせたものです。 クラスター化インデックスのキー値は、すべての非クラスター化インデックスにより、参照キーとして使用されます。 非クラスター化インデックスのエントリには、クラスター化キー以外に、非クラスター化インデックスのキー列も格納されるため、同じテーブルに非クラスター化インデックスが定義されている場合は、サイズがかなり大きくなります。
非クラスター化インデックスのデザイン ガイドライン
ディスク ベースの行ストア非クラスター化インデックスには、インデックス キー値、およびテーブル データの格納場所を指す行ロケーターが含まれています。 1 つのテーブルまたはインデックス付きビューに複数の非クラスター化インデックスを作成できます。 一般に、非クラスター化インデックスは、頻繁に使用するクエリで、クラスター化インデックスで対応されないクエリのパフォーマンスを向上するようにデザインします。
クエリ オプティマイザーでデータ値を検索するときは、本の索引を使用する場合と同じように、非クラスター化インデックスを検索してテーブル内でのデータ値の位置を探し、その位置から直接データを取得します。 非クラスター化インデックスには、クエリの検索対象であるデータ値のテーブル内での位置を正確に記述するエントリが格納されているので、完全一致比較クエリの場合は非クラスター化インデックスが最適です。 たとえば、 HumanResources.Employee テーブルに対してクエリを実行し、ある 1 人の上司に直属するすべての従業員を取得する場合、クエリ オプティマイザーは IX_Employee_ManagerIDをキー列として、非クラスター化インデックス ManagerID を使用することができます。 クエリ オプティマイザーはこのインデックスの中から、指定された ManagerIDと一致するすべてのエントリを迅速に検索できます。 インデックスの各エントリのポインターは、テーブル (またはクラスター化インデックス) の、対応するデータが見つかる正確なページおよび行を指しています。 クエリ オプティマイザーは、インデックスの中からすべてのエントリを検出した後、正確なページおよび行に直接移動してデータを取得できます。
非クラスター化インデックスのアーキテクチャ
ディスク ベースの行ストア非クラスター化インデックスもクラスター化インデックスと同じ B+ ツリー構造ですが、次に示す大きな相違点があります。
基になるテーブルのデータ行は、非クラスター化キーに基づいた順序で並べ替えられたり格納されたりしません。
非クラスター化インデックスのリーフ レベルは、データ ページではなくインデックス ページで構成されます。 非クラスター化インデックスのリーフ レベルのインデックス ページには、キー列と付加列が含まれます。
非クラスター化インデックス行内の行ロケーターは、次に示すような、行を指すポインターまたは行のクラスター化インデックス キーのいずれかです。
テーブルがヒープで、クラスター化インデックスが設定されていない場合、行ロケーターはその行へのポインターです。 このポインターは、ファイル識別子 (ID)、ページ番号、およびそのページ上での行の番号で構成されます。 ポインター全体は、RID (行 ID) と呼ばれます。
テーブルにクラスター化インデックスがある場合、またはインデックスがインデックス付きビューにある場合は、行ロケーターが行のクラスター化インデックス キーになります。
また、行ロケーターにより、非クラスター化インデックス行の一意性も確保されます。 次の表では、データベース エンジンが非クラスター化インデックスに行ロケーターをどのように追加するかを説明しています。
| テーブルの種類です。 | 非クラスター化インデックスの種類 | 行ロケーター |
|---|---|---|
| ヒープ | ||
| 一意でない | キー列に追加される RID | |
| [一意] | 付加列に追加される RID | |
| 一意のクラスター化インデックス | ||
| 一意でない | キー列に追加されるクラスター化インデックス キー | |
| [一意] | 付加列に追加されるクラスター化インデックス キー | |
| 一意でないクラスター化インデックス | ||
| 一意でない | キー列に追加されるクラスター化インデックス キーと uniqueifier (存在する場合) | |
| [一意] | 付加列に追加されるクラスター化インデックス キーと uniqueifier (存在する場合) |
データベース エンジンは、非クラスター化インデックスに特定の列を 2 回格納することはありません。 ユーザーが非クラスター化インデックスを作成するときに指定したインデックス キーの順序は、常に優先されます。非クラスター化インデックスのキーに追加する必要のある行ロケーター列は、キーの最後、インデックス定義で指定された列の後に追加されます。 非クラスター化インデックス内のクラスター化インデックスのキー ベースの行ロケーター列は、インデックス定義で明示的に指定されているかどうかにかかわらず、クエリ オプティマイザーで使用できます。
以下の例は、行ロケーターが非クラスター化インデックスでどのように実装されるかを示しています。
| クラスター化したインデックス | 非クラスター化インデックス定義 | 行ロケーターを使用した非クラスター化インデックス定義 | 説明 |
|---|---|---|---|
キー列 (A、B、C) を含む一意のクラスター化インデックス |
キー列 (B、A) と付加列 (E、G) を含む一意でない非クラスター化インデックス |
キー列 (B、A、C) と付加列 (E、G) |
非クラスター化インデックスは一意ではないので、行ロケーターはインデックス キーに存在する必要があります。 行ロケーターの列 B と A はすでに存在しているので、列 c のみが追加されます。 列 c は、キー列リストの末尾に追加されます。 |
キー列 (A) を含む一意のクラスター化インデックス |
キー列 (B、C) と付加列 (A) を含む一意でない非クラスター化インデックス |
キー列 (B、C、A) |
非クラスター化インデックスは一意ではないので、行ロケーターはキーに追加されます。 列 A はまだキー列として指定されていないので、キー列リストの末尾に追加されます。 列 A は現在キー内にあるので、付加列として格納する必要はありません。 |
キー列 (A、B) を含む一意のクラスター化インデックス |
キー列 (C) を含む一意の非クラスター化インデックス |
キー列 (C) と付加列 (A、B) |
非クラスター化インデックスは一意なので、行ロケーターは付加列に追加されます。 |
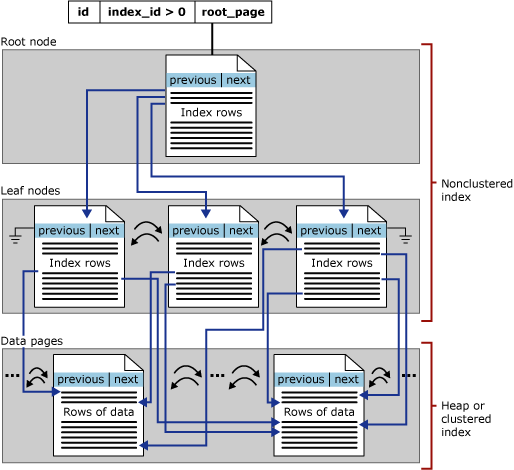
非クラスター化インデックスの場合、sys.partitions にはインデックスで使用されるパーティションごとに 1 つの行が含まれます。この場合、index_id > 1 となります。 既定では、非クラスター化インデックスのパーティションは 1 つです。 非クラスター化インデックスにパーティションが複数ある場合、各パーティションは、その特定のパーティションに対してインデックス行を保持する B+ ツリー構造になります。 たとえば、非クラスター化インデックスに 4 つのパーティションがある場合、4 つの B+ ツリー構造になります。この場合、パーティションごとに 1 つの B+ ツリーがあります。
非クラスター化インデックスのデータ型によっては、各非クラスター化インデックスの構造に 1 つ以上のアロケーション ユニットが含まれ、そこに特定のパーティションのデータが格納され、管理されます。 各非クラスター化インデックスには、インデックス B+ ツリーのページが格納されているパーティションごとに、少なくとも 1 つの IN_ROW_DATA アロケーション ユニットがあります。 また、非クラスター化インデックスにラージ オブジェクト (LOB) 列が含まれている場合は、パーティションごとに 1 つの LOB_DATA アロケーション ユニットもあります。 さらに、行サイズの上限である 8,060 バイトを超える可変長列が含まれている場合は、パーティションごとに 1 つの ROW_OVERFLOW_DATA アロケーション ユニットがあります。
次の図に、1 つのパーティション内の非クラスター化インデックスの構造を示します。
データベースの考慮事項
非クラスター化インデックスをデザインするときは、データベースの特性を考慮してください。
更新の必要が少なく、容量の大きいデータベースまたはテーブルの場合、クエリのパフォーマンスを向上させるには非クラスター化インデックスを多数作成するのが適しています。 テーブル全体の非クラスター化インデックスと比較してクエリのパフォーマンスが向上し、インデックスのストレージ コストとインデックスのメンテナンス コストが削減されるように、適切に定義されたデータのサブセットに対してフィルター選択されたインデックスを作成することを検討してください。
読み取り専用データが中心の意思決定支援システム アプリケーションおよびデータベースは、非クラスター化インデックスを多数作成するのが適しています。 クエリ オプティマイザーにより、最速のアクセス方法が判断するためにより多くのインデックスから選択でき、データベースの更新頻度が低いのでインデックスのメンテナンスによってパフォーマンスが低下することはありません。
テーブルの更新頻度が高いオンライン トランザクション処理 (OLTP) アプリケーションおよびデータベースに、インデックスを過度に作成することはお勧めしません。 また、インデックスの列数はできる限り抑えてください。
1 つのテーブルに多数のインデックスがあると、テーブル内のデータが変更された場合にインデックスをすべて調整する必要があるので、
INSERT、UPDATE、DELETE、およびMERGEの各ステートメントのパフォーマンスに影響します。
クエリの考慮事項
非クラスター化インデックスを作成する前に、データがどのようにアクセスされるかを理解しておいてください。 次に示す特徴があるクエリには非クラスター化インデックスを使用することを検討してください。
複数の
JOIN句またはGROUP BY句を使用する。結合操作やグループ化操作に使用する列の非クラスター化インデックスを複数作成し、外部キー列にクラスター化インデックスを作成してください。
大きな結果セットを返さないクエリ。
大きなテーブルから適切に定義された行のサブセットを返すクエリに対応するために、フィルター選択されたインデックスを作成してください。
ヒント
通常、
WHEREステートメントのCREATE INDEX句は、カバーされているクエリのWHERE句と一致します。完全一致を返すクエリの検索条件 (
WHERE句など) に頻繁に使用される列を含んでいます。ヒント
新しいインデックスを追加するときは、コストと利点を検討します。 既存のインデックスに追加クエリのニーズを統合する方が望ましい場合があります。 たとえば、既存のインデックスに 1 つまたは 2 つの余分なリーフ レベル列を追加すると複数の重要なクエリをカバーできる場合は、重要な各クエリを個別に完全にカバーする 1 つのインデックスを作成するのではなく、そのようにします。
列に関する考慮事項
次に示す特徴に 1 つ以上該当する列を考慮してください。
クエリを包括している。
インデックスにクエリのすべての列が含まれていると、パフォーマンスが向上します。 クエリ オプティマイザーではインデックス内ですべての列値を参照できるので、テーブルやクラスター化インデックスのデータにアクセスすることがなく、ディスク I/O 操作が少なくてすみます。 列数の多いインデックス キーを作成する代わりに、包括する列を追加するには、付加列インデックスを使用します。
テーブルにクラスター化インデックスがある場合、クラスター化インデックスに定義された列がテーブルの各非クラスター化インデックスに自動的に付加されます。 その結果、非クラスター化インデックスの定義にクラスター化インデックスの列を指定することなく、インデックスにはクエリで使用するすべての列が含まれることになります。 たとえば、あるテーブルの列
Cにクラスター化インデックスがある場合、列BおよびAの一意でない非クラスター化インデックスのキー値は列B、A、およびCとなります。 詳細については、非クラスター化インデックスアーキテクチャを参照してください。姓と名の組み合わせなど、多数の異なる値が格納されています (他の列にクラスター化インデックスが使用されている場合)。
1と0のみ など異なる値が少数しかない場合、テーブル スキャンを行う方が通常は効率的なので、ほとんどのクエリではインデックスが使用されません。 このようなデータの場合は、少数の行のみに含まれる異なる値に対してフィルター選択されたインデックスを作成することを検討してください。 たとえば、ほとんどの値が0の場合は、クエリ オプティマイザーで1を含むデータ行に対してフィルター選択されたインデックスを使用できます。
付加列の使用による非クラスター化インデックスの拡張
非クラスター化インデックスのリーフ レベルに非キー列を追加することにより、非クラスター化インデックスの機能を拡張できます。 非キー列を含めることにより、より多くのクエリをカバーする非クラスター化インデックスを作成できます。 これは、非キー列には次の利点があるためです。
非キー列には、インデックス キー列として許可されていないデータ型を設定できる。
これらはインデックス キー列の数やインデックス キーのサイズを計算するときに、データベース エンジンで考慮されません。
クエリ内のすべての列が、キー列または非キー列のいずれかとしてインデックスに含まれるているとき、非キー付加列を含むインデックスにより、クエリ パフォーマンスが大幅に向上します。 クエリ オプティマイザーではインデックス内のすべての列値を参照できるので、テーブルやクラスター化インデックスのデータにアクセスすることがなく、ディスク I/O 操作が少なくて済むため、パフォーマンスが向上します。
Note
クエリによって参照されるすべての列がインデックスに含まれているときは、一般的に、そのインデックスはクエリをカバーしていると呼ばれます。
キー列がインデックスのすべてのレベルに格納されている場合は、非キー列はリーフ レベルだけに格納されます。
サイズ制限を回避するための付加列の使用
非クラスター化インデックスに非キー列を含めることで、現在のインデックス サイズの制限 (最大 16 個のキー列と最大 900 バイトのインデックス キーのサイズ) を超えないようにすることができます。 インデックス キー列の数やインデックス キーのサイズを計算するときに、データベース エンジンでは非キー列が考慮されません。
たとえば、 Document テーブルにある次の列にインデックスを設定するとします。
Title NVARCHAR(50)
Revision NCHAR(5)
FileName NVARCHAR(400)
nchar と nvarchar の各データ型では文字ごとに 2 バイトが必要であるため、これら 3 つの列が含まれるインデックスは 900 バイトのサイズ制限を 10 バイト超えます (455 * 2)。 INCLUDE ステートメントの CREATE INDEX 句を使用することにより、インデックス キーを (Title, Revision) として定義し、 FileName を非キー列として定義できます。 その結果、インデックス キーのサイズが 110 バイト (55 2) になりましたが、インデックスには必要な列がすべて含まれています。 このようなインデックスは、次のステートメントで作成されます。
CREATE INDEX IX_Document_Title
ON Production.Document (Title, Revision)
INCLUDE (FileName);
GO
コード例に従っている場合は、この Transact-SQL ステートメントを使用してこのインデックスを削除できます。
DROP INDEX IX_Document_Title
ON Production.Document;
GO
付加列インデックスのガイドライン
付加列非クラスター化インデックスを設計するときは、次のガイドラインについて考慮してください。
非キー列は、
INCLUDEステートメントのCREATE INDEX句で定義されます。非キー列は、テーブルやインデックス付きビューの非クラスター化インデックスにのみ定義できます。
text、 ntext、および imageを除く、すべてのデータ型を使用できます。
決定的な計算列、および正確または不正確な計算列を、付加列にできます。 詳細については、「計算列のインデックス」を参照してください。
キー列と同様に、計算列が image、 ntext、および text の各データ型から派生している場合は、計算列のデータ型が非キー インデックス列として許可されている限り、非キー (付加) 列にできます。
INCLUDEリストとキー列リストの両方に、列名を指定することはできません。INCLUDEリスト内で列名を繰り返すことはできません。
列サイズのガイドライン
キー列は少なくとも 1 つ定義する必要があります。 非キー列の最大数は 1,023 列です。 これは、テーブルの最大列数から 1 を引いた数です。
非キーを除くインデックス キー列は、既存のインデックス サイズの制限 (最大 16 個のキー列、インデックス キーの合計サイズ 900 バイト) に従う必要があります。
すべての非キー列の合計サイズは、
INCLUDE句で指定された列のサイズによってのみ制限されます。たとえば、varchar(max) 列は 2 GB に制限されます。
列の変更のガイドライン
付加列として定義されたテーブル列を変更するときには、次の制限が適用されます。
インデックスを先に削除しない限り、非キー列をテーブルから削除できません。
次の操作以外に、非キー列は変更できません。
列の NULL 値の許容を
NOT NULLからNULLに変更します。varchar、 nvarchar、または varbinary の各列の長さを拡張します。
Note
これらの列の変更の制限は、インデックス キー列にも適用されます。
設計の推奨事項
検索や参照に使用される列のみがキー列になるように、大きなサイズのインデックス キーを使用して、非クラスター化インデックスを設計し直します。 クエリをカバーする他のすべての列を、非キー付加列にします。 その結果、クエリをカバーするために必要なすべての列を含むことができますが、インデックス キー自体は小さく、効率的です。
たとえば、次のクエリをカバーするインデックスを設計するとします。
SELECT AddressLine1, AddressLine2, City, StateProvinceID, PostalCode
FROM Person.Address
WHERE PostalCode BETWEEN N'98000' AND N'99999';
GO
クエリをカバーするには、インデックスに各列を定義する必要があります。 すべての列をキー列として定義でき、その場合キーのサイズは 334 バイトになります。 検索条件に使用されている唯一の列は、30 バイトの長さの PostalCode 列なので、より効果的な設計のインデックスにするには、キー列として PostalCode を定義し、他のすべての列を非キー列として含めます。
次のステートメントにより、クエリをカバーする付加列インデックスが作成されます。
CREATE INDEX IX_Address_PostalCode
ON Person.Address (PostalCode)
INCLUDE (AddressLine1, AddressLine2, City, StateProvinceID);
インデックスがクエリをカバーしていることを検証するには、インデックスを作成し、推定実行プランを表示します。
SELECT インデックスに対する IX_Address_PostalCode 演算子と Index Seek 演算子しか実行プランに表示されない場合、クエリはインデックスにカバーされます。
次のステートメントを使用して、インデックスを削除できます。
DROP INDEX IX_Address_PostalCode
ON Person.Address;
GO
パフォーマンスに関する考慮事項
不要な列は追加しないでください。 キーまたは非キーのインデックス列を追加しすぎると、次のようなパフォーマンス上の問題が発生することがあります。
1 ページに収まるインデックス行が少なくなります。 これにより、ディスク I/O が増加しキャッシュ効率が低下します。
インデックスを格納するために、さらに多くのディスク領域が必要になります。 特に、 varchar(max)、 nvarchar(max)、 varbinary(max)、または xml のデータ型を非キー インデックス列として追加すると、必要なディスク領域が大幅に増加します。 これは、列の値がインデックスのリーフ レベルにコピーされるためです。 そのため、列の値がインデックスとベース テーブルの両方に存在します。
インデックスのメンテナンスによって、基になるテーブルやインデックス付きビューに対する変更、挿入、更新、削除にかかる時間が長くなる場合があります。
データ変更によるパフォーマンスへの影響や追加ディスク領域の要件よりも、クエリのパフォーマンスから得られる利点の方が大きいかどうかを判断する必要があります。
一意インデックスのデザイン ガイドライン
一意インデックスを使用すると、インデックス キーの値が重複することがないので、テーブルのすべての行を一意にすることができます。 一意であることがデータ自体の特性である場合にだけ、一意インデックスを指定します。 たとえば、主キーが NationalIDNumber で、HumanResources.Employee テーブルの EmployeeID 列の値が必ず一意になるようにする場合は、UNIQUE 列で NationalIDNumber 制約を作成します。 ユーザーが複数の従業員に対してその列に同じ値を入力しようとすると、エラー メッセージが表示され、重複する値は入力されません。
複数列に一意インデックスを指定すると、インデックス キーの値の組み合わせはそれぞれ一意になります。 たとえば、 LastName列、 FirstName列、および MiddleName 列の組み合わせに一意インデックスを作成した場合、テーブル内の 2 つの行がこれらの列に対して同じ値の組み合わせを持つことはできません。
クラスター化インデックスと非クラスター化インデックスは共に一意インデックスにできます。 列のデータが一意である場合、1 つのテーブルに 1 つの一意クラスター化インデックスと、複数の一意非クラスター化インデックスを作成できます。
一意インデックスの利点を次に示します。
- 定義された列のデータの整合性が保証されます。
- クエリ オプティマイザーの役に立つ追加情報が提供されます。
PRIMARY KEY 制約または UNIQUE 制約を作成すると、指定した列に一意インデックスが自動的に作成されます。 UNIQUE 制約を作成することと、制約とは無関係の一意なインデックスを作成することの間に大きな違いはありません。 データ検証も同じ方式で行われ、クエリ オプティマイザーでは、制約によって作成された一意インデックスと手動で作成された一意インデックスは区別されません。 ただし、データの整合性を維持することを目的とした列には、列に UNIQUE 制約または PRIMARY KEY 制約を作成する必要があります。 この作業を行うことで、インデックスの目的が明確になります。
考慮事項
重複するキー値がデータに存在する場合は、一意なインデックス、
UNIQUE制約、またはPRIMARY KEY制約を作成できません。データが一意のときに一意性を強制する場合は、一意インデックスを作成する方が、同じ組み合わせの列に一意でないインデックスを作成するよりも、より効率的な実行プランを作成できる追加情報がクエリ オプティマイザーに提供されます。 この場合、一意インデックスを作成することをお勧めします (できるだけ
UNIQUE制約を作成することをお勧めします)。一意非クラスター化インデックスには、付加非キー列を含めることができます。 詳細については、「付加列インデックス」を参照してください。
フィルター選択されたインデックスのデザイン ガイドライン
フィルター選択されたインデックスは、最適化された非クラスター化インデックスであり、適切に定義されたデータのサブセットから選択するクエリに対応する際に特に適しています。 フィルター選択されたインデックスは、フィルター述語を使用して、テーブル内の一部の行にインデックスを作成します。 フィルター選択されたインデックスを適切にデザインすると、クエリのパフォーマンスが向上し、インデックスのメンテナンス コストを削減して、テーブル全体のインデックスと比較してインデックスのストレージ コストを削減することができます。
フィルター選択されたインデックスは、テーブル全体のインデックスよりも次の点で優れています。
クエリのパフォーマンスとプランの品質の向上
フィルター選択されたインデックスを適切にデザインすると、クエリのパフォーマンスと実行プランの品質が向上します。これは、このインデックスが、テーブル全体の非クラスター化インデックスよりも小さく、フィルター選択された統計情報を含むためです。 フィルター選択された統計情報は、フィルター選択されたインデックスの行のみを対象としているため、テーブル全体の統計情報よりも正確です。
インデックスのメンテナンス コストの削減
インデックスのメンテナンスが行われるのは、データ操作言語 (DML) ステートメントがインデックス内のデータに影響を与える場合のみです。 フィルター選択されたインデックスにより、インデックスのメンテナンス コストは、テーブル全体の非クラスター化インデックスと比較して削減されます。これは、フィルター選択されたインデックスは小さく、インデックス内のデータが影響を受けた場合にのみメンテナンスされるためです。 特に、含まれるデータにほとんど影響がない場合は、多数のフィルター選択されたインデックスを作成できます。 同様に、フィルター選択されたインデックスに頻繁に影響を受けるデータのみが含まれている場合は、インデックスのサイズを小さくすると、統計情報の更新コストが削減されます。
インデックスのストレージ コストの削減
テーブル全体のインデックスが不要な場合は、フィルター選択されたインデックスを作成すると、非クラスター化インデックスのディスク ストレージを削減できます。 ストレージ要件をあまり増やすことなく、テーブル全体の非クラスター化インデックスを複数のフィルター選択されたインデックスに置き換えることができます。
フィルター選択されたインデックスは、クエリが SELECT ステートメントで参照する、適切に定義されたデータのサブセットが列に含まれている場合に役立ちます。 次に例をいくつか示します。
NULL以外の値を少数しか含まないスパース列。- 複数のカテゴリのデータを含む異種列。
- 金額、時間、日付など、値の範囲を含む列。
- 列の値の単純な比較ロジックで定義されるテーブル パーティション。
フィルター選択されたインデックスのメンテナンス コストの削減は、そのインデックスに含まれる行数がテーブル全体のインデックスと比較して少ない場合に、最も明確になります。 フィルター選択されたインデックスにテーブル内のほとんどの行が含まれる場合は、テーブル全体のインデックスよりもメンテナンス コストがかかることがあります。 この場合は、フィルター選択されたインデックスではなく、テーブル全体のインデックスを使用する必要があります。
フィルター選択されたインデックスは 1 つのテーブルで定義され、単純な比較演算子のみをサポートします。 複数のテーブルを参照するフィルター式や複雑なロジックを含むフィルター式が必要な場合は、ビューを作成する必要があります。
設計上の考慮事項
フィルター選択されたインデックスを効果的にデザインするには、アプリケーションで使用されるクエリを把握し、そのクエリがデータのサブセットとどのように関連するかを理解することが重要です。 適切に定義されたサブセットを持つデータの例として、ほとんどが NULL 値の列、異種カテゴリの値を含む列、および異なる範囲の値を含む列が挙げられます。 次のデザインに関する考慮事項では、フィルター選択されたインデックスがテーブル全体のインデックスよりも優れている場合のさまざまなシナリオを示します。
ヒント
非クラスター化列ストア インデックスの定義で、フィルター適用条件の使用をサポートします。 OLTP テーブルに列ストア インデックスを追加することによるパフォーマンスへの影響を最小限に抑えるには、フィルター条件を使って、用して、運用ワークロードのコールド データのみに、非クラスター化列ストア インデックスを作成します。
データのサブセットのフィルター選択されたインデックス
クエリに関連する少数の値だけが列に含まれている場合、値のサブセットにフィルター選択されたインデックスを作成できます。 たとえば、列の値がほとんど NULL の場合に、クエリで常に NULL 以外の値を選択するときは、NULL 以外のデータ行にフィルター選択されたインデックスを作成できます。 作成したインデックスは、同じキー列に定義されているテーブル全体の非クラスター化インデックスよりも小さく、メンテナンス コストが少なくなります。
たとえば、AdventureWorks サンプル データベースには、2,679 行の Production.BillOfMaterials テーブルがあります。 EndDate 列では、NULL 以外の値を含む行は 199 行だけで、他の 2,480 行には NULL が含まれています。 次のフィルター選択されたインデックスは、インデックスで定義された列を返し、NULL で EndDate 以外の値を含む行のみを選択するクエリに対応します。
CREATE NONCLUSTERED INDEX FIBillOfMaterialsWithEndDate
ON Production.BillOfMaterials (ComponentID, StartDate)
WHERE EndDate IS NOT NULL;
GO
フィルター選択されたインデックス FIBillOfMaterialsWithEndDate は、次のクエリに対して有効です。 推定実行プランを表示して、クエリ オプティマイザーでフィルター選択されたインデックスが使用されたかどうかを確認します。
SELECT ProductAssemblyID, ComponentID, StartDate
FROM Production.BillOfMaterials
WHERE EndDate IS NOT NULL
AND ComponentID = 5
AND StartDate > '20080101';
GO
フィルター選択されたインデックスの作成方法およびフィルター選択されたインデックスの述語式の定義方法の詳細については、「フィルター選択されたインデックスの作成」を参照してください。
異種データのフィルター選択されたインデックス
テーブルに異種データの行が含まれている場合、1 つ以上のカテゴリのデータに対してフィルター選択されたインデックスを作成できます。
たとえば、 Production.Product テーブルに示される製品がそれぞれ ProductSubcategoryIDに割り当てられ、Bikes、Components、Clothing、Accessories の製品カテゴリに関連付けられています。 Production.Product テーブル内にあるこうしたカテゴリの列の値はあまり密接に関連していないので、異種カテゴリとなります。 たとえば、 Color、 ReorderPoint、 ListPrice、 Weight、 Class、および Style の各列には、各製品カテゴリで固有の特性があります。 サブカテゴリ 27 ~ 36 を含む付属品に対して頻繁に使用されるクエリがあるとします。 次の例に示すように、付属品のサブカテゴリにフィルター選択されたインデックスを作成することで、付属品に対するクエリのパフォーマンスを向上させることができます。
CREATE NONCLUSTERED INDEX FIProductAccessories
ON Production.Product (ProductSubcategoryID, ListPrice)
Include (Name)
WHERE ProductSubcategoryID >= 27 AND ProductSubcategoryID <= 36;
GO
フィルター選択されたインデックス FIProductAccessories は次のクエリに対応します。これは、クエリ結果がインデックスに含まれ、クエリ プランにベース テーブルの参照が含まれないためです。 たとえば、クエリ述語式 ProductSubcategoryID = 33 はフィルター選択されたインデックスの述語 ProductSubcategoryID >= 27 および ProductSubcategoryID <= 36のサブセットで、クエリ述語の ProductSubcategoryID 列と ListPrice 列はどちらもインデックスのキー列であり、名前は付加列としてインデックスのリーフ レベルに格納されます。
SELECT Name, ProductSubcategoryID, ListPrice
FROM Production.Product
WHERE ProductSubcategoryID = 33 AND ListPrice > 25.00;
GO
キー列
フィルター選択されたインデックスの定義にいくつかのキーまたは付加列を含めること、およびフィルター選択されたインデックスをクエリ オプティマイザーによってクエリ実行プランで選択するために必要な列だけを組み込むことをお勧めします。 クエリ オプティマイザーでは、フィルター選択されたインデックスがクエリに対応するかどうかに関係なく、フィルター選択されたインデックスがクエリに対して選択されます。 ただし、フィルター選択されたインデックスがクエリに対応する場合は、そのインデックスが選択される可能性は高くなります。
場合によっては、フィルター選択されたインデックスは、その式の列をキー列または付加列としてフィルター選択されたインデックスの定義に含めなくても、クエリに対応します。 次のガイドラインでは、フィルター選択されたインデックスの式の列をフィルター選択されたインデックスの定義でキー列または付加列にする必要がある場合について説明します。 次の例では、以前に作成したフィルター選択されたインデックス FIBillOfMaterialsWithEndDate を使用します。
フィルター選択されたインデックスの式がクエリ述語と同じであり、フィルター選択されたインデックスの式の列がクエリ結果と共に返されない場合、その式の列を、フィルター選択されたインデックスの定義でキー列または付加列にする必要はありません。 たとえば、クエリ述語がフィルター式と同じであり、 FIBillOfMaterialsWithEndDate がクエリ結果と共に返されないため、 EndDate は次のクエリに対応します。 FIBillOfMaterialsWithEndDate は、フィルター選択されたインデックスの定義のキー列または付加列として EndDate を必要としません。
SELECT ComponentID, StartDate FROM Production.BillOfMaterials
WHERE EndDate IS NOT NULL;
フィルター選択されたインデックスの式と異なるクエリ述語で比較に列が使用される場合は、フィルター選択されたインデックスの式の列を、フィルター選択されたインデックスの定義でキー列または付加列にする必要があります。 たとえば、 FIBillOfMaterialsWithEndDate は、フィルター選択されたインデックスから行のサブセットを選択するので、次のクエリに対して有効です。 ただし、 EndDate が比較 EndDate > '20040101'で使用されるため、次のクエリには対応していません。この比較は、フィルター選択されたインデックスの式と異なります。 クエリ プロセッサでは、 EndDateの値を参照せずにこのクエリを実行することはできません。 したがって、 EndDate をフィルター選択されたインデックスの定義でキー列または付加列にする必要があります。
SELECT ComponentID, StartDate FROM Production.BillOfMaterials
WHERE EndDate > '20040101';
フィルター選択されたインデックスの式の列がクエリ結果セットに含まれる場合、その列をフィルター選択されたインデックスの定義でキー列または付加列にする必要があります。 たとえば、 FIBillOfMaterialsWithEndDate はクエリ結果に含まれる EndDate 列を返すので、次のクエリに対応しません。 したがって、 EndDate をフィルター選択されたインデックスの定義でキー列または付加列にする必要があります。
SELECT ComponentID, StartDate, EndDate FROM Production.BillOfMaterials
WHERE EndDate IS NOT NULL;
テーブルのクラスター化インデックス キーは、フィルター選択されたインデックスの定義でキー列または付加列にする必要はありません。 クラスター化インデックス キーは、フィルター選択されたインデックスなど、すべての非クラスター化インデックスに自動的に含まれます。
FIBillOfMaterialsWithEndDate および FIProductAccessories の各インデックスを削除するには、次のステートメントを実行します。
DROP INDEX FIBillOfMaterialsWithEndDate
ON Production.BillOfMaterials;
GO
DROP INDEX FIProductAccessories
ON Production.Product;
GO
フィルター述語のデータ変換演算子
フィルター選択されたインデックスでは、その式に指定された比較演算子によって暗黙的または明示的なデータ変換が行われる場合、変換が比較演算子の左辺で行われると、エラーが発生します。 解決方法としては、比較演算子の右辺にデータ変換演算子 (CAST または CONVERT) を含む、フィルター選択されたインデックスの式を記述します。
次の例では、さまざまなデータ型が含まれるテーブルを作成します。
CREATE TABLE dbo.TestTable (
a INT,
b VARBINARY(4)
);
GO
次のフィルター選択されたインデックスの定義では、列 b は、定数 1 と比較するために、整数データ型に暗黙的に変換されます。 これにより、フィルター選択された述語の演算子の左辺で変換が行われるため、エラー メッセージ 10611 が生成されます。
CREATE NONCLUSTERED INDEX TestTabIndex ON dbo.TestTable (a, b)
WHERE b = 1;
GO
解決策として、次の例に示すように、右辺の定数を、列 b と同じ型になるように変換します。
CREATE INDEX TestTabIndex ON dbo.TestTable (a, b)
WHERE b = CONVERT(VARBINARY(4), 1);
GO
データ変換を比較演算子の左辺から右辺に移動すると、変換の意味が変わることがあります。 前の例では、CONVERT 演算子を右辺に追加したときに、整数の比較から varbinary の比較に変わりました。
この例で作成したオブジェクトを削除するには、次のステートメントを実行します。
DROP TABLE TestTable;
GO
列ストア インデックスのアーキテクチャ
列ストア インデックスは、列ストアと呼ばれる列指向データ形式を使用してデータを格納、取得、および管理するためのテクノロジです。 詳細については、「列ストア インデックス: 概要」を参照してください。
バージョン情報と新機能については、「列ストア インデックスの新機能」を参照してください。
これらの基本を理解すると、効果的に使用する方法を説明する、その他の列ストアの記事を理解しやすくなります。
データ ストレージでは列ストアと行ストアの圧縮を使用する
列ストア インデックスの説明では、データ ストレージの形式を強調する目的で行ストアと列ストアという用語を使用しています。 列ストア インデックスでは、両方の種類のストレージを使用します。
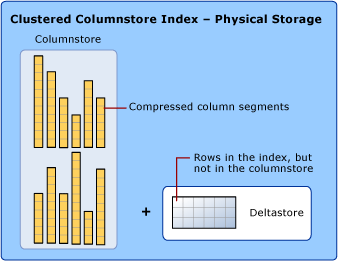
列ストア は、行と列を含むテーブルとして論理的に編成され、列方向のデータ形式で物理的に格納されているデータです。
列ストア インデックスでは、ほとんどのデータを列ストア形式で物理的に格納します。 列ストア形式では、データは列として圧縮および非圧縮されます。 クエリで要求されない行ごとに、その他の値を非圧縮する必要はありません。 このため、大規模なテーブルの列全体を高速にスキャンできます。
行ストア は、行と列を含むテーブルとして論理的に編成され、行方向のデータ形式で物理的に格納されているデータです。 これは、ヒープまたはクラスター化された B+ ツリー インデックスなどのリレーショナル テーブル データを格納する従来の方法です。
また、列ストア インデックスでは、デルタストアという行ストア形式で一部の行を物理的にも格納します。 デルタストア (デルタ行グループとも呼ばれます) は、列ストアへの圧縮に適合させるために、数が少なすぎる行を格納する場所です。 デルタ行グループはそれぞれ、クラスター化された B+ ツリー インデックスとして実装されます。
デルタストアは、列ストアに圧縮するには数が少なすぎる行を保持する場所です。 デルタストアは、行ストア形式で行を格納します。
列ストアの用語と概念の詳細については、列ストア インデックス:概要を参照してください。
操作は行グループと列セグメント上で実行される
列ストア インデックスでは、行を管理可能な単位にグループ化します。 これらの単位はそれぞれ、行グループと呼ばれます。 最適なパフォーマンスを得るため、行グループ内の行数は、高い圧縮率が実現される程度に多く、インメモリ操作の利点を得られる程度に少ないです。
たとえば、列ストア インデックスは、行グループで次の操作を実行します。
- 行グループを列ストアに圧縮します。 圧縮は、行グループ内の各列セグメントで実行されます。
- 削除されたデータの削除など、
ALTER INDEX ... REORGANIZE操作中に行グループをマージします。 ALTER INDEX ... REBUILD操作中に行グループを新規作成します。- 動的管理ビュー (DMV) の行グループの正常性と断片化に関するレポートを行います。
デルタストアは、デルタ行グループと呼ばれる 1 つ以上の行グループで構成されます。 各デルタ行グループは、クラスター化された B+ ツリー インデックスであり、小規模な一括読み込みと挿入が、行グループの行数が 1,048,576 に達するまで格納されます。この上限に達すると、組ムーバーと呼ばれるプロセスによって、閉じられた行グループが列ストアに自動的に圧縮されます。
行グループの状態の詳細については、「sys.dm_db_column_store_row_group_physical_stats」を参照してください。
ヒント
小さな行グループが多すぎると、列ストア インデックスの品質が低下します。 再編成操作を実行すると、削除された行を削除して圧縮された行グループを結合する方法を決定する内部しきい値ポリシーに従って、小さな行グループがマージされます。 マージ後は、インデックスの品質が改善されます。
SQL Server 2019 (15.x) 以降、タプル ムーバーは、内部しきい値で指定した所定の期間存在していたと判断された小さい OPEN デルタ行グループを自動的に圧縮したり、大量の行が削除された COMPRESSED 行グループをマージしたりするバックグラウンド マージ タスクによってサポートされています。
それぞれの列には、行グループごとにその値の一部が含まれます。 これらの値は列セグメントと呼ばれます。 それぞれの行グループには、テーブルの 1 つの列につき 1 つの列セグメントが含まれます。 それぞれの列には、行グループごとに 1 つの列セグメントがあります。
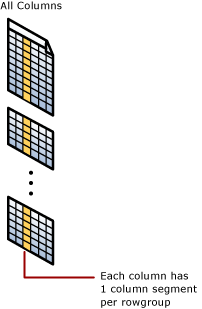
列ストア インデックスが行グループを圧縮する場合、各列セグメントを個別に圧縮します。 列全体を非圧縮する場合、列ストア インデックスでは、それぞれの行グループから列セグメントを 1 つ非圧縮するだけで列全体を非圧縮できます。
列ストアの用語と概念の詳細については、列ストア インデックス:概要を参照してください。
小規模の読み込みと挿入はデルタストアに移動される
列ストア インデックスは、一度に少なくとも 102,400 個の行を列ストア インデックスに圧縮することで、列ストア インデックスの圧縮とパフォーマンスを向上させています。 行を一括で圧縮するために、列ストア インデックスでは、小規模な読み込みを累積し、デルタストアに挿入します。 デルタストア操作は内部で処理されます。 列ストア インデックスは、正しいクエリ結果を返すために、列ストアとデルタストアの両方からのクエリ結果を結合します。
次の場合に、行はデルタストアに移動されます。
INSERT INTO ... VALUESステートメントで挿入された場合。- 一括読み込みの最後で 102,400 未満の場合。
- 更新済み。 更新はそれぞれ、削除および挿入として実装されます。
また、デルタストアでは、削除済みとしてマークされているが、列ストアから物理的に削除されていない、削除された行の ID の一覧も格納します。
列ストアの用語と概念の詳細については、列ストア インデックス:概要を参照してください。
デルタ行グループは、満杯になると列ストアに圧縮される
クラスター化列ストア インデックスでは、デルタ行グループごとに最大 1,048,576 個の列を収集してから、行グループを列ストアに圧縮します。 これにより、列ストア インデックスの圧縮が向上します。 デルタ行グループが行数の上限に達すると、OPEN 状態から CLOSED 状態に移行します。 組ムーバーというバックグラウンド プロセスによって、閉じられた行グループがチェックされます。 プロセスによって閉じている行グループが見つけられると、その行グループは圧縮され、列ストアに格納されます。
デルタ行グループが圧縮されると、既存のデルタ行グループは、参照がない場合は組ムーバーによって後で削除される TOMBSTONE 状態に移行します。また、新しい圧縮行グループは COMPRESSED とマークされます。
行グループの状態の詳細については、「sys.dm_db_column_store_row_group_physical_stats」を参照してください。
インデックスを再構築または再構成するには、ALTER INDEX を使用してデルタ行グループを列ストアに強制的に圧縮することができます。 圧縮中にメモリ負荷がある場合、列ストア インデックスは圧縮行グループ内の行数を減らす可能性があります。
列ストアの用語と概念の詳細については、列ストア インデックス:概要を参照してください。
各テーブル パーティションには、独自の行グループとデルタ行グループが含まれる
パーティション分割の概念は、クラスター化インデックス、ヒープ、および列ストア インデックスのすべてにおいて同じです。 テーブルのパーティション分割では、列の値の範囲に従って、テーブルをより小規模の列のグループに分割します。 通常、これはデータを管理するために使用されます。 たとえば、データの年ごとにパーティションを作成して、パーティションの切り替えを使用し、データをコストが低いストレージにアーカイブすることができます。 パーティションの切り替えは、列ストア インデックス上で動作するため、データのパーティションを別の場所に移動しやすくなります。
行グループは常に、テーブル パーティション内に定義されます。 列ストア インデックスがパーティション分割されると、各パーティションには独自の圧縮行グループとデルタ行グループが含まれます。
ヒント
列ストアからデータを削除する必要がある場合は、テーブルのパーティション分割の使用を検討してください。 不要になったパーティションの切り替えと切り捨ては、より小さな行グループを持つことによって生じる断片化の生成なしでデータを削除する効率的な方法です。
各パーティションに複数のデルタ行グループを含めることができる
各パーティションに複数のデルタ行グループを含めることができます。 列ストア インデックスでデータをデルタ行グループに追加する必要があり、デルタ行グループがロックされている場合、列ストア インデックスでは、さまざまなデルタ行グループのロックを取得しようとします。 使用できるデルタ行グループがない場合は、列ストア インデックスでは新しいデルタ行グループが作成されます。 たとえば、パーティションが 10 個のテーブルには、簡単に 20 個以上のデルタ行グループを含めることができます。
同じテーブルで列ストア インデックスと行ストア インデックスを結合する
非クラスター化インデックスには、基になるテーブルの行と列の一部または全体のコピーが含まれています。 インデックスはテーブルの 1 つ以上の列として定義され、行のフィルター処理条件をオプションで設定できます。
更新可能な非クラスター化列ストア インデックスを、行ストア テーブルに作成できます。 列ストア インデックスは、データのコピーを格納するため、追加のストレージが必要です。 ただし、列ストア インデックス内のデータは、行ストア テーブルが必要とするサイズよりも小さいサイズに圧縮されます。 これにより、同時に、列ストア インデックスの分析と行ストア インデックスのトランザクションを同時に実行できます。 行ストア テーブルでデータが変更されると列ストアが更新されるため、両方のインデックスが同じデータに対して作業を実行します。
列ストア インデックスでは、1 つ以上の非クラスター化行ストア インデックスを使用できます。 これにより、基になる列ストアで、効率的なテーブル シークを実行できます。 他のオプションも使用できます。 たとえば、行ストア テーブルで UNIQUE 制約を使用することで、主キー制約を適用できます。 一意でない値は行ストア テーブルに挿入できないため、データベース エンジンでその値を列ストアに挿入することはできません。
パフォーマンスに関する考慮事項
非クラスター化列ストア インデックスの定義で、フィルター適用条件の使用をサポートします。 OLTP テーブルに列ストア インデックスを追加することによるパフォーマンスへの影響を最小限に抑えるには、フィルター条件を使って、用して、運用ワークロードのコールド データのみに、非クラスター化列ストア インデックスを作成します。
インメモリ テーブルでは、列ストア インデックスを 1 つ使用できます。 これは、テーブルの作成時に作成することも、後で ALTER TABLE (Transact-SQL) を使用して追加することもできます。 SQL Server 2016 (13.x)より前のバージョンでは、列ストア インデックスを保持できたのはディスク ベースのテーブルのみでした。
詳細については、「列ストア インデックス - クエリ パフォーマンス」を参照してください。
設計ガイダンス
- 行ストア テーブルで、更新可能な非クラスター化列ストア インデックスを 1 つ使用できます。 SQL Server 2014 (12.x) より前のバージョンでは、非クラスター化列ストア インデックスは読み取り専用でした。
詳細については、「列ストア インデックス - 設計ガイダンス」を参照してください。
ハッシュ インデックスのデザイン ガイドライン
すべてのメモリ最適化テーブルには少なくとも 1 つのインデックスが必要です。このインデックスによって行が連結されるためです。 メモリ最適化テーブルでは、すべてのインデックスもメモリ最適化されます。 ハッシュ インデックスは、メモリ最適化テーブルで使用できるインデックスの種類の 1 つです。 詳細については、「メモリ最適化テーブルのインデックス」を参照してください。
適用対象: SQL Server、Azure SQL Database および Azure SQL Managed Instance
ハッシュ インデックスのアーキテクチャ
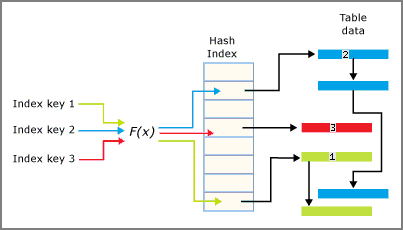
ハッシュ インデックスはポインターの配列で構成され、その配列の各要素はハッシュ バケットと呼ばれます。
- 各バケットは 8 バイトであり、キー エントリのリンク リストのメモリ アドレスを格納するために使用されます。
- 各エントリは、インデックス キーの値と、基になるメモリ最適化テーブル内の対応する行のアドレスです。
- 各エントリは、すべて現在のバケットにチェーンされたエントリのリンク リスト内の次のエントリを指します。
バケットの数は、インデックスの定義時に指定する必要があります。
- テーブルの行数または個別の値の数に対するバケット数の割合が低ければ低いほど、バケットの平均リンク リストは長くなります。
- 短いリンク リストは、長いリンク リストよりも高速で実行されます。
- ハッシュ インデックスのバケットの最大数は 1,073,741,824 です。
ヒント
データの適切な BUCKET_COUNT を決定するには、ハッシュ インデックスのバケット数の構成を参照してください。
ハッシュ関数はインデックス キー列に適用され、関数の結果によってキーがどのバケットに分類されるかが決まります。 各バケットには、ハッシュされたキー値がそのバケットにマップされている行へのポインターがあります。
ハッシュ インデックスに使用するハッシュ関数には、以下の特徴があります。
- データベース エンジンには、すべてのハッシュ インデックスに使用されるハッシュ関数が 1 つ用意されています。
- ハッシュ関数は決定的です。 入力キー値が同じであれば、常にハッシュ インデックスの同じバケットにマッピングされます。
- インデックス キーが違っても、同じハッシュ バケットにマッピングされることがあります。
- ハッシュ関数はバランスが取られます。つまり、通常、ハッシュ バケット上のインデックス キー値の分布は、平坦な線形分布ではなくポアソン分布またはベル カーブ分布に従います。
- ポアソン分布は均等な分布ではありません。 インデックス キーの値は、ハッシュ バケットで均等に分散されません。
- 2 つのインデックス キーが同じハッシュ バケットにマッピングされた場合には、ハッシュの競合となります。 ハッシュの競合が大量に発生した場合には、読み取り操作のパフォーマンスに影響を及ぼすおそれがあります。 現実的な目標は、バケットの 30% に 2 つの異なるキー値が含まれていることです。
ハッシュ インデックスとバケットの関係をまとめると、次の図のようになります。
ハッシュ インデックス バケット数を構成する
ハッシュ インデックスのバケット数はインデックス作成時に指定しますが、ALTER TABLE...ALTER INDEX REBUILD 構文を使用して変更することができます。
ほとんどの場合、バケット数は、理想的にはインデックス キーの個別の値の数の 1 から 2 倍の範囲内にします。
特定のインデックス キーに値がどれぐらいあるかは、予測できないこともあります。 BUCKET_COUNT値がキー値の実際の数の 10 倍以内であれば、パフォーマンスは通常まだ良好であり、低く見積もるよりは多く見積もりすぎるほうが一般的によい結果が得られます。
少なすぎるバケットには、次の短所があります。
- 個別のキー値のハッシュの競合の増加。
- 個別の値が、異なる個別の値を持つバケットの共有を強いられます。
- パケットごとの平均チェーン長が増えます。
- バケット チェーンが長ければ長いほど、インデックスでの等値検索の速度が遅くなります。
多すぎるバケットには、次の短所があります。
- バケット数が高すぎると、空のバケットを増やす結果になることがあります。
- 空のバケットは、フル インデックス スキャンのパフォーマンスに影響を与えます。 スキャンが普通に行われる場合は、インデックス キーの個別の値の数に近いバケット数を選択することを検討してください。
- 空のバケットは、それぞれが使用するのはわずか 8 バイトですが、メモリを使用します。
Note
バケットを追加しても、重複する値を共有するエントリのチェーンが短くなることはありません。 値の重複の割合は、ハッシュが適切なインデックスの種類であるかどうかを決定するために使用され、バケット数を計算するために使用されることはありません。
パフォーマンスに関する考慮事項
ハッシュ インデックスのパフォーマンスは次のようになります。
WHERE句の述語で、ハッシュ インデックス キーの各列の正確な値を指定する場合は極めて良好です。 ハッシュ インデックスは、非等値述語が指定されているとスキャンに戻ります。WHERE句の述語でインデックス キーの値の範囲を探す場合は、よくありません。WHERE句の述語で、2 列のハッシュ インデックス キーの最初の列について特定の値を指定し、キーの他の列については値を指定しない場合は、よくありません。
ヒント
述語はハッシュ インデックス キーのすべての列を含める必要があります。 ハッシュ インデックスでは、インデックスに対してシークを実行するための (ハッシュ用の) キーが必要です。
インデックス キーが 2 列で構成され、WHERE 句で最初の列しか指定されないと、データベース エンジンでハッシュ用とするキーが不完全になります。 この場合は、インデックス スキャン クエリ プランが作成されます。
ハッシュ インデックスを使用し、一意のインデックス キーの数が行の数より 100 倍 (またはそれ以上) 多い場合は、大きい行チェーンを回避するために bucket_count を増やすか、代わりに非クラスター化インデックスを使用することをお勧めします。
宣言に関する考慮事項
ハッシュ インデックスは、メモリ最適化テーブルにのみ存在できます。 これはディスク ベース テーブルには存在できません。
ハッシュ インデックスは、次のように宣言できます。
UNIQUE。そうしないと、既定の「一意でない」になります。NONCLUSTERED。これが既定値です。
次の構文の例では、CREATE TABLE ステートメント外でハッシュ インデックスを作成します。
ALTER TABLE MyTable_memop
ADD INDEX ix_hash_Column2 UNIQUE
HASH (Column2) WITH (BUCKET_COUNT = 64);
行のバージョンとガベージ コレクション
メモリ最適化テーブルでは、行が UPDATE による影響を受ける場合、テーブルで行の更新バージョンが作成されます。 更新トランザクションの間、他のセッションは行の前のバージョンを読み取ることができるため、行ロックに関連するパフォーマンスの低下を回避することができます。
ハッシュ インデックスに、更新に対応するための異なるバージョンのエントリも存在することがあります。
後で前のバージョンが不要になったときに、ガベージ コレクション (GC) スレッドがバケットとそのリンク リストを横断して、前のエントリをクリーンアップします。 GC スレッドのパフォーマンスは、リンク リストのチェーン長が短い場合に優れています。 詳細については、「インメモリ OLTP ガベージ コレクション」を参照してください。
メモリ最適化された非クラスター化インデックスのデザイン ガイドライン
非クラスター化インデックスは、メモリ最適化テーブルで使用できるインデックスの種類の 1 つです。 詳細については、「メモリ最適化テーブルのインデックス」を参照してください。
適用対象: SQL Server、Azure SQL Database および Azure SQL Managed Instance
インメモリ非クラスター化インデックスのアーキテクチャ
インメモリ非クラスター化インデックスは、2011 年に Microsoft Research が独自に考案した Bw ツリーというデータ構造を使用して実装されています。 Bw ツリーは、B ツリーのロックおよびラッチフリーのバリエーションです。 詳細については、「Bw ツリー: 新しいハードウェア プラットフォーム向けの B ツリー」を参照してください。
大まかに説明すると、Bw ツリーは、ページ ID (PidMap) で整理されたページのマップです。また、ページ ID (PidAlloc) と、ページ マップ内および相互にリンクされているページのセットを割り当て、再利用する機能があります。 これら 3 つの上位レベルのサブコンポーネントが、Bw ツリーの基本的な内部構造を構成します。
その構造は、各ページに並べ替えられたキー値のセットがあり、インデックス内にそれぞれが下位レベルを示すレベルがあり、リーフ レベルがデータ行を示すという点で、通常の B ツリーと似ています。 ただし、違いもいくつかあります。
ハッシュ インデックスと同様に、複数のデータ行 (バージョン) をまとめてリンクできます。 レベル間のページ ポインターは論理ページ ID です。これは、ページ マッピング テーブルのオフセットなので、各ページの物理アドレスがあります。
インデックス ページのインプレース更新はありません。 この目的のために新しいデルタ ページが導入されています。
- ページの更新のためにラッチやロックは必要ありません。
- インデックス ページは固定サイズではありません。
図の各非リーフ レベル ページのキー値は、示された子が含む最大値であり、各行にはそのページの論理ページ ID も含まれます。 リーフレベルのページには、キー値と共に、データ行の物理アドレスが含まれています。
ポイント ルックアップは、B ツリーと似ていますが、ページは 1 つの方向のみにリンクされているためSQL Server データベース エンジンは、B ツリーのように最低値ではなく、各非リーフ ページに子の最大値がある適切なページ ポインターに従います。
リーフレベルのページを変更する必要がある場合、SQL Server データベース エンジンはページ自体を変更しません。 その代わり、SQL Server データベース エンジンでは、変更を示す差分レコードが作成され、前のページに付加されます。 次に、前のページのページ マップ テーブル アドレスが、このページの物理アドレスになる差分レコードのアドレスに更新されます。
Bw ツリーの構造を管理するために必要な 3 つの操作があります。統合、分割、マージです。
差分の統合
差分レコードのチェーンが長くなると、インデックスの検索時に長いチェーンを横断することになるので、結果的に検索のパフォーマンスが遅くなる可能性があります。 要素数が既に 16 個のチェーンに新しい差分レコードが追加された場合、差分レコードの変更は参照されるインデックス ページに統合され、統合をトリガーした新しい差分レコードに示される変更を含むページが再構築されます。 新しく構築されたページのページ ID は同じですが、メモリ アドレスは新しくなります。
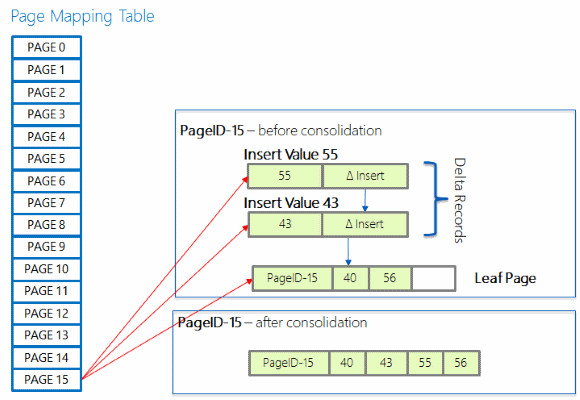
ページの分割
Bw ツリーのインデックス ページは、1 行の格納から最大 8 KB の格納まで必要に応じてサイズが大きくなります。 インデックス ページのサイズが 8 KB まで大きくなった後に新しく 1 行追加されると、インデックス ページは分割されます。 内部ページの場合は、別のキー値とポインターを追加する余地がなくなり、リーフ ページの場合は、すべての差分レコードを組み込んだ後に行のサイズが大きすぎてページに収まらなくなることを意味します。 リーフ ページのページ ヘッダーの統計情報は、差分レコードを統合するために必要な容量を追跡します。 この情報は、新しいデルタ レコードが追加されるたびに調整されます。
分割操作は、2 つのアトミック手順で実行されます。 次のダイアグラムでは、値が 5 のキーが挿入されるため、リーフページで分割が強制実行されます。現在のリーフレベル ページの末尾を示す非リーフページ (キー値 4) が存在しなくなります。

手順 1: P1 と P2 という新しい 2 ページを割り当て、新しく挿入された行を含め、以前の P1 ページの行をこれらの新しいページに分割します。 ページ マッピング テーブルの新しいスロットは、ページ P2 の物理アドレスを格納するために使用されます。 P1 と P2 というこれらのページは、まだ同時実行の操作にはアクセスできません。 さらに、P1 から P2 への論理ポインターがセットされます。 次に、1 つのアトミック手順でページ マッピング テーブルが更新され、ポインターが古い P1 から新しい P1 に変更されます。
手順 2: 非リーフ ページは P1 を指しますが、非リーフ ページから P2 への直接ポインターはありません。 P2 は P1 を介してのみ到達可能です。 非リーフ ページから P2 へのポインターを作成するには、新しい非リーフ ページ (内部インデックス ページ) を割り当て、古い非リーフ ページのすべての行をコピーし、P2 を示す新しい行を追加します。 この手順が完了したら、1 つのアトミック手順で、ページ マッピング テーブルを更新して、ポインターを古い非リーフ ページから新しい非リーフ ページに変更します。
ページのマージ
DELETE 操作の結果、ページのサイズが最大ページ サイズ (現在は 8 KB) の 10% 未満になるか、ページ上の行数が 1 になると、そのページは連続するページにマージされます。
ページから行が削除されると、その削除の差分データが追加されます。 さらに、インデックス ページ (非リーフ ページ) がマージ対象かどうかを判断するための確認が実行されます。 この確認で、行を削除した後の残領域が最大ページ サイズの 10パーセント未満になるかどうかが検証されます。 この条件を満たす場合、マージは 3 つのアトミック手順で実行されます。
次の図では、DELETE 操作でキー値 10 が削除されています。

手順 1: キー値 10 (青色の三角形) を表す差分ページが作成され、非リーフ ページ Pp1 内のそのポインターは新しい差分ページに設定されます。 さらに、特別なマージ差分ページ (緑色の三角形) が作成され、差分ページを示すようにリンクされます。 この段階では、両方のページ (差分ページとマージ差分ページ) は、同時のトランザクションには表示されません。 1 つのアトミック手順では、ページ マッピング テーブルのリーフレベル ページ P1 へのポインターはマージ差分ページを示すように更新されます。 この手順の後、10 のキー値 Pp1 のエントリはマージ差分ページを示すようになります。
手順 2: 非リーフ ページ 7 のキー値 Pp1 を表す行を削除し、キー値 10 のエントリが P1 を示すように更新する必要があります。 この処理を実行するために、新しい非リーフ ページ Pp2 が割り当てられ、キー値 Pp1 を表す行を除き、7 のすべての行がコピーされます。キー値 10 の行はページ P1 を示すように更新されます。 この処理が完了すると、1 つのアトミック手順で、Pp1 を示すページ マッピング テーブルのエントリは Pp2 を示すように更新されます。 Pp1 には到達できなくなります。
手順 3: リーフレベル ページ P2 と P1 はマージされ、差分ページは削除されます。 この処理を実行するために、新しいページ P3 が割り当てられ、P2 と P1 の行がマージされ、差分ページの変更は新しい P3 に含まれます。 次に、1 つのアトミック手順で、ページ P1 を示すページ マッピング テーブルのエントリは、ページ P3 を示すように更新されます。
パフォーマンスに関する考慮事項
非等値述語でメモリ最適化テーブルを照会する場合は、非クラスター化ハッシュ インデックスより非クラスター化インデックスのパフォーマンスが高くなります。
メモリ最適化テーブルの列は、ハッシュ インデックスと非クラスター化インデックスの両方に含めることができます。
非クラスター化インデックス キーの列に、多数の重複値がある場合は、更新、挿入、および削除に関してパフォーマンスが低下します。 このような状況でパフォーマンスを向上させる 1 つの方法は、インデックス キーの選択度が高い列を追加することです。