演習 - Azure Data Factory のラングリング データを使う
Azure Data Factory 内の Power Query 機能を使用すると、データを操作しラングリングできます。 これは、コードを記述せずにデータ準備を実行するために Azure Data Factory パイプラインのアクティビティとしてキャンバス デザイナーに追加できるデータ フロー オブジェクトです。 Spark や SQL Server などの従来のデータ準備テクノロジや、Python や T-SQL などの言語に精通していないユーザーも、クラウド規模のデータを繰り返し準備できるようになります。
Power Query 機能では、基本的なデータ準備のために、オンライン マッシュアップ エディターと呼ばれる、Excel の外観に似たグリッド型のインターフェイスを使用します。 また、このエディターでは、上級ユーザーが数式を使用してより複雑なデータ準備も実行できます。 まず、データにアクセスする前に、データ ソースへのリンクされたサービスを作成する必要があります
式は Power Query Online を操作し、データ ファクトリ ユーザーが Power Query M 関数を使用できるようにします。 その後、Power Query は、Online Mashup Editor によって生成された M 言語を、クラウド規模で実行するための Spark コードに変換します。
この機能により、データ エンジニアもデータ アナリストも、対話形式でデータセットを探索して準備することができます。 さらに、M 言語を対話的に操作し、結果を広いパイプラインのコンテキストで表示する前にプレビューすることもできます。
Azure Data Factory に Power Query アクティビティを追加するには、プラス アイコンをクリックし、ファクトリ リソース ウィンドウで [Power Query] を選択します。

ラングリング データ フローのソース データセットを追加し、シンク データセットを選択します。 以下のデータ ソースがサポートされています。
| コネクタ | データ形式 | 認証の種類 |
|---|---|---|
| Azure Blob Storage | CSV、Parquet | アカウント キー |
| Azure Data Lake Storage Gen1 | CSV | サービス プリンシパル |
| Azure Data Lake Storage Gen2 | CSV、Parquet | アカウント キー、サービス プリンシパル |
| Azure SQL データベース | SQL 認証 | |
| Azure Synapse Analytics | SQL 認証 |
ソースを選択したら、[作成] をクリックします。

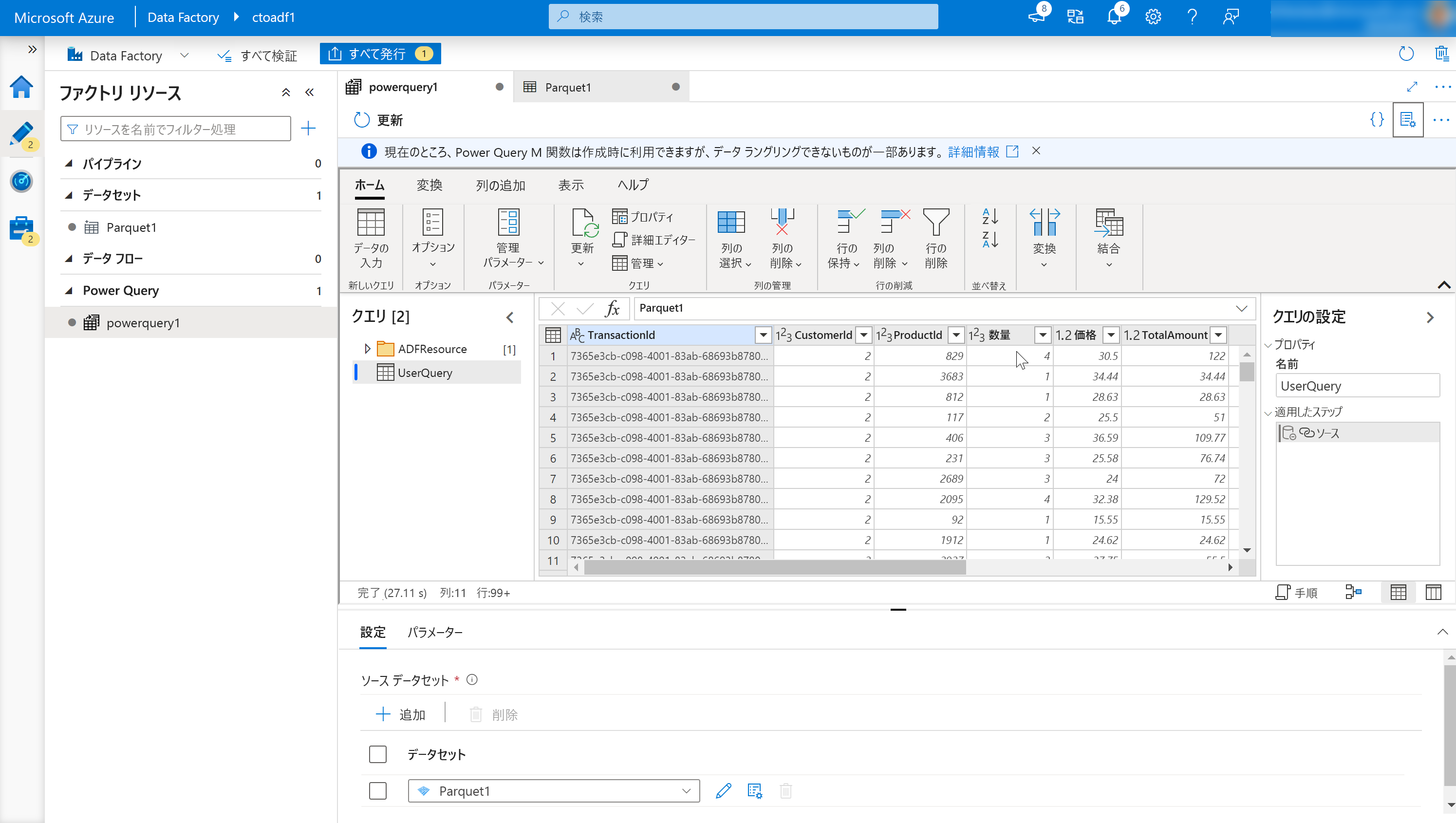
これで、オンライン マッシュアップ エディターが開きます。

これは、次のコンポーネントで構成されます。
データセットの一覧。
これには、データ ラングリングのソースとして定義されているデータセットが表示されます。
ラングリング関数ツール バー。
ツール バーには、データを操作するためにユーザーがアクセスできる、次のようなさまざまなデータ ラングリング関数が含まれています。
- 列を管理する。
- テーブルを変換する。
- 行を削減する。
- 列を追加する。
- テーブルを結合する。
各項目は状況依存であり、それぞれに固有のサブ関数が含まれています。
列見出し。
列の名前を変更できるだけでなく、列を右クリックすると、列を管理するための状況依存の項目が表示されます。
[設定]:
これにより、データ ソースとデータ シンクを追加または編集したり、ラングリング データ タスクの設定を変更したりできます。
ステップ ウィンドウ。
このウィンドウには、ラングリング出力に適用されたステップが表示されます。 図の例では、"Source" という名前のステップに "UserQuery" という名前のラングリング出力が適用されています。
Power Query 出力リスト。
定義されているデータ ラングリングの出力を一覧表示します。
[発行] ボタン。
作成された作業を発行できます。
Power Query タスクは、Copy アクティビティ タスクやマッピング データ フロー タスクと同じようにキャンバス デザイナーに追加でき、同じように管理および監視できます。
