演習 - モデルを構築する
ここでは、モデルを構築してみましょう。 最初のステップは、データセットをダウンロードし、Azure サービスを作成することです。
サンドボックスをアクティブにする
サインインしてサンドボックスをアクティブにするプロセスの実行は、学習モジュールの範囲外です。 サインインすると、自動的にモジュールに戻ります。
サンドボックスをアクティブにするには:
[Sign in to activate Sandbox](サインインしてサンドボックスをアクティブにする) を選択します。 認証のための資格情報を入力します。
メッセージが表示されたら、[アクセス許可の確認] を選択します。
![[アクセス許可の確認] ボタンが強調表示されているサンドボックスを示すスクリーンショット。](../../advocates/cv-classify-bird-species/media/sandbox-review-permissions.png)
アクセス許可の設定を確認し、[同意する] を選択します。
![アクセス許可の詳細と [同意する] ボタンが強調表示されているサンドボックスを示すスクリーンショット。](../../advocates/cv-classify-bird-species/media/sandbox-accept-permissions.png)
[Sandbox activated!] (サンドボックスがアクティブになりました) というメッセージが表示され、学習モジュールを続けることができます。
データセットをダウンロードする
データは、機械学習モデルを作成するために必要な最初のものです。 このモデルのトレーニングには、Cornell Lab の NABirds データセットのサブセットを使用します。
データセットが含まれる zip ファイルをダウンロードします。
Web ブラウザーで、GitHub のデータセットにアクセスします。
[Download] を選択します。
![データセットの zip ファイルと [ダウンロード] ボタンが強調表示されている、Web ブラウザーでの GitHub を示すスクリーンショット。](../../advocates/cv-classify-bird-species/media/github-download-dataset.png)
zip ファイルがコンピューターにコピーされ、ダウンロードされたファイルの既定の場所に保存されます。
ダウンロードが完了したら、ファイルを解凍します。 後の手順で必要になるため、フォルダーの場所を記録しておきます。
Custom Vision API リソースを作成する
次に、Azure AI Custom Vision で API リソースを作成します。
Azure Portal で、 [リソースの作成] を選択します。
[Custom Vision] を見つけます。 検索結果の [Custom Vision] カードで、[作成] を選択します。
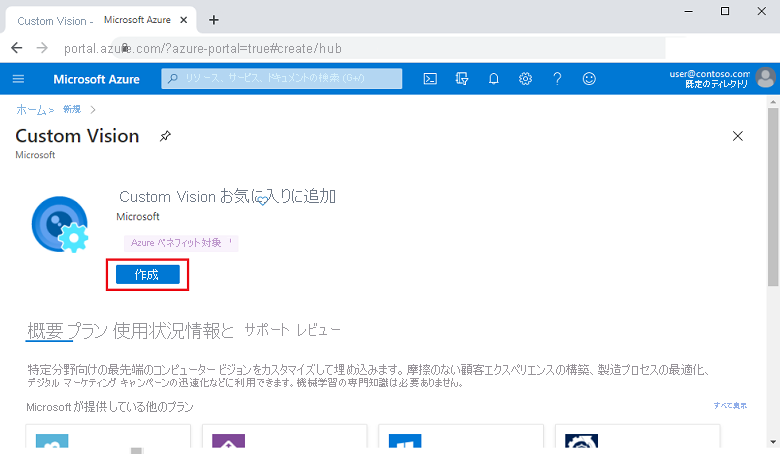
[基本] タブで、必要な値を入力または選択します。
Azure サブスクリプションを選択します。
新しいリソース グループを作成します。
[リソース グループ] の横にある [新規作成] リンクを選択します。
ダイアログ ボックスで、「BirdResourceGroup」と入力して [OK] を選択します。
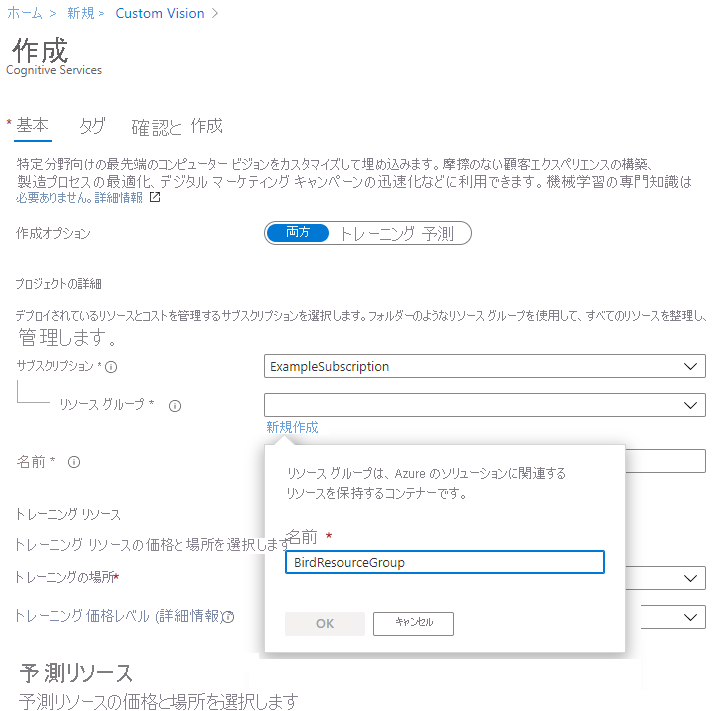
新しい Custom Vision サービス リソースの名前を入力します (たとえば BirdCustomVisionService)。
[インスタンスの詳細] で:
[リージョン] を [(米国) 米国中南部] に設定します。
英数字とハイフンのみを使って、リソースの [名前] を入力します。
[トレーニング リソース] の下で、[トレーニング価格レベル] を [Free F0 (2 Transactions per second…)](Free F0 (2 トランザクション/秒...)) に設定します。
[予測リソース] の下で、[予測価格レベル] を [Free F0 (2 Transactions per second…)](Free F0 (2 トランザクション/秒...)) に設定します。
[Review + create](レビュー + 作成) を選択します。
[作成] を選択します
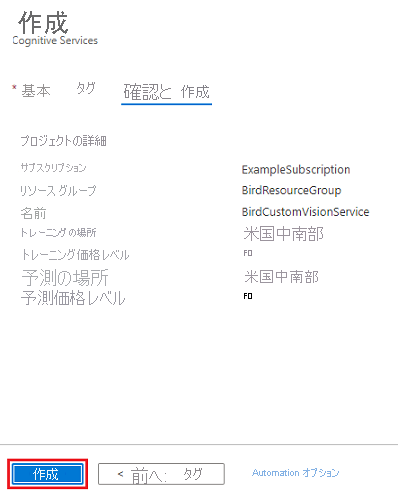
デプロイが完了したら、[リソース グループに移動] を選択します。
![[リソースに移動] ボタンが強調表示されている、Azure portal のデプロイ完了ページを示すスクリーンショット。](../../advocates/cv-classify-bird-species/media/azure-portal-deployment-finished.png)
この新しいリソース グループには、"トレーニング リソース" と "予測リソース" という 2 つのリソースが表示されます。