Azure で SQL Server をデプロイするための PaaS オプションを説明する
サービスとしてのプラットフォーム (PaaS) は、クラウドですべてが揃った開発およびデプロイ環境を提供します。これは、単純なクラウドベースのアプリケーションと高度なエンタープライズ アプリケーションの両方に使用できます。
Azure SQL Database と Azure SQL Managed Instance は、Azure SQL 向けの PaaS オファリングの一部です。
Azure SQL Database - クラウド内の SQL Server エンジンに基づいて構築された製品ファミリの一部です。 開発者が新しいアプリケーション サービスときめの細かいデプロイ オプションを大規模に構築するのに、大きな柔軟性をもたらします。 SQL Database は、特定のワークロードに最適なオプションになる可能性のある、低メンテナンス ソリューションを提供します。
Azure SQL Managed Instance - フル マネージドのサービスと機能を提供するため、クラウドへのほとんどの移行シナリオに最適です。
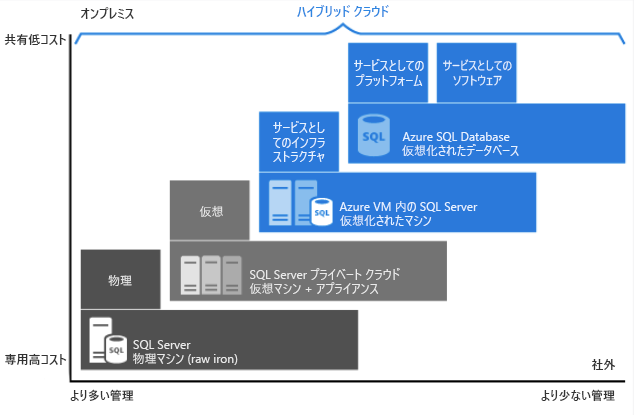
上記の図に示されているように、各オファリングは、インフラストラクチャに及ぼす一定水準の管理とコスト効率をもたらします。
デプロイ モデル
Azure SQL Database は 2 つの異なるデプロイ モデルで利用できます。
単一データベース - データベースごとのレベルで課金および管理される単一データベース。 各データベースを、スケールとデータ サイズの観点から、個別に管理します。 このモデルで展開された各データベースには、同じ論理サーバーに展開されている場合でも、それぞれに専用のリソースがあります。
エラスティック プール - 一連の共通のリソースを共有し、まとめて管理されるデータベースのグループ。 エラスティック プールでは、すべてのデータベース間でリソースが共有されるため、サービスとしてのソフトウェア アプリケーション モデルに対してコスト効率の高いソリューションを提供します。 DTU ベースの購入モデルまたは仮想コアベースの購入モデルに基づいてリソースを構成できます。
購入モデル
Azure では、すべてのサービスが物理ハードウェアによってサポートされており、次の 2 つの異なる購入モデルから選択できます。
データベース トランザクション ユニット (DTU)
DTU は、コンピューティング、ストレージ、および I/O リソースを組み合わせた数式に基づいて計算されます。 これは、構成済みのシンプルなリソース オプションを必要とするお客様に適しています。
DTU 購入モデルには、Basic、Standard、Premium など、いくつかの異なるサービス レベルがあります。 各レベルにはさまざまな機能があるため、このプラットフォームを選択する場合に幅広いオプションを利用できます。
パフォーマンスの面では、Basic レベルは負荷の低いワークロードに使用されますが、Premium は負荷の高いワークロード要件に使用されます。
コンピューティング リソースとストレージ リソースは DTU レベルに依存し、固定のストレージ制限、バックアップ保有期間、コストで、さまざまなパフォーマンス機能を提供します。
注意
DTU 購入モデルは、Azure SQL Database でのみサポートされます。
DTU 購入モデルについて詳しくは、「DTU ベースの購入モデルの概要」を参照してください。
仮想コア
仮想コア モデルでは、お客様の所与のワークロードに基づいて指定された数の仮想コアを購入できます。 仮想コアは、Azure SQL Database リソースを購入する際の既定の購入モデルです。 仮想コア データベースでは、データベースに提供されるコアの数とメモリおよびストレージの量との間に特定の関係があります。 仮想コア購入モデルは、Azure SQL Database と Azure SQL Managed Instance のいずれかでサポートされます。
仮想コア データベースも 3 つの異なるサービス レベルで購入できます。
General Purpose - このレベルは汎用のワークロードを対象としています。 こここでは Azure Premium Storage が利用されます。 待ち時間は Business Critical よりも長くなります また、次のコンピューティング レベルも提供します。
- Provisioned - コンピューティング リソースは事前に割り当てられます。 構成されている仮想コアに基づいて、1 時間単位で課金されます。
- Serverless - コンピューティング リソースは自動でスケーリングされます。 使用されている仮想コアに基づいて、1 秒単位で課金されます
Business Critical - このレベルは高パフォーマンスのワークロードを対象としていて、すべてのサービス レベルの中で待ち時間が最も短くなります。 このレベルでは、Azure BLOB ストレージではなくローカル SSD が利用されます。 これはまた、障害に対して最高の回復性を発揮するほか、レポートのワークロードの負荷を減らすために使用できる組み込みの読み取り専用データベース レプリカを提供します。
Hyperscale - Hyperscale データベースは、その他の Azure SQL Database サービスの上限である 4 TB をはるかに超えてスケーリングでき、最大 100 TB のデータベースをサポートする独自のアーキテクチャを備えています。
サーバーレス
お客様はなおも自分の Azure SQL データベースを接続先である論理サーバーにデプロイするため、"サーバーレス" という呼び方はやや紛らわしいかもしれません。 Azure SQL Database サーバーレスは、ワークロードの需要に基づいて所定のデータベースのリソースを自動的にスケールアップまたはダウンするコンピューティング レベルです。 ワークロードにコンピューティング リソースが必要でなくなったら、データベースは "一時停止" になります。データベースが非アクティブの状態である間は、ストレージのみ料金が課されます。 接続が試行されると、データベースが "再開" して利用可能になります。
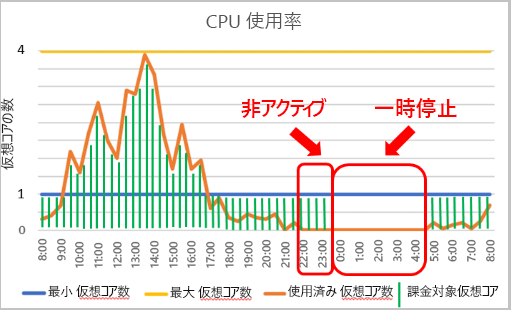
一時停止を制御する設定は自動一時停止の遅延と呼ばれ、その最小値は 60 分、最大値は 7 日になっています。 データベースはこの期間にわたってアイドル状態になると、一時停止します。
データベースは指定された時間にわたって非アクティブになると、後続の接続が試行されるまで一時停止します。 コンピューティングの自動スケール範囲と自動一時停止の遅延を構成すると、データベースのパフォーマンスとコンピューティング コストに影響します。
一時停止したデータベースへの接続では接続エラーが発生するため、サーバーレスを使用するアプリケーションはどれも、接続エラーに対処できるように構成され、再試行ロジックを備えている必要があります。
サーバーレスと Azure SQL Database の通常の仮想コア モデルのもう 1 つの違いは、サーバーレスでは仮想コアの最小および最大数を指定できる点です。 メモリと I/O の上限は指定された範囲に比例します。

上の画像は、Azure portal のサーバーレス データベースの構成画面を示しています。 最小値は仮想コアの半分から、最大値は 16 仮想コアまで選択できるオプションがあります。
Serverless は、次のようなバックグラウンド プロセスを常に実行する必要があるため、Azure SQL Database のすべての機能と完全に互換性があるわけではありません。
- geo レプリケーション
- 長期のバックアップ リテンション期間
- エラスティック ジョブのジョブ データベース
- SQL データ同期の同期データベース (データ同期は、データベースのグループ間でデータをレプリケートするサービスです)
Note
SQL Database Serverless は、現在、仮想コア購入モデルの General Purpose レベルでのみサポートされます。
バックアップ
サービスとしてのプラットフォーム サービスの最も重要な機能の 1 つにバックアップがあります。 この場合、バックアップはお客様の人手を要することなく自動的に行われます。 バックアップは Azure の BLOB geo 冗長ストレージに格納され、既定ではデータベースのサービス レベルに基づいて 7 から 35 日の期間、保有されます。 Basic と仮想コアのデータベースの保有期間は既定で 7 日に設定されています。仮想コア データベースでは、この値を管理者が調整できます。 保有期間は長期保有 (LTR) を構成することによって延長できます。これにより、バックアップを最大 10 年間、保有できます。
冗長性を確保するために、BLOB 読み取りアクセス geo 冗長ストレージを使用することもできます。 このストレージでは、お客様のデータベース バックアップを、基本設定のセカンダリ リージョンにレプリケートします。 さらに、必要に応じて、そのセカンダリ リージョンから読み取りを行うことができます。 データベースの手動バックアップはサポートされておらず、そうするための要求は一切プラットフォームによって拒否されることに注意してください。
データベースのバックアップは所定のスケジュールで実施されます。
- 完全 - 週に 1 回
- 差分 - 12 時間ごと
- ログ - トランザクション ログ アクティビティに応じて 5 から 10 分ごと
このバックアップ スケジュールは、ほとんどの回復ポイントまたは時間の目標 (RPO または RTO) のニーズを満たすはずです。しかし、お客様は各自で、それらが自社のビジネス要件を満たしているかどうかを評価する必要があります。
データベースの復元に利用できるいくつかのオプションがあります。 サービスとしてのプラットフォームの特性からして、T-SQL コマンド RESTORE DATABASE を実行するなど、従来型の方法を使用してデータベースを手動で復元することはできません。
どういった復元方法を実装するかにかかわらず、既存のデータベースの上に復元することはできません。 データベースを復元する必要がある場合は、復元プロセスを開始する前に既存のデータベースを削除するか名前変更しなければなりません。 さらに、復元時間は保証されておらず、プラットフォームのサービス レベルによって変わる可能性があることに注意してください。 復元プロセスをテストして、考えられる復元時間についてベースライン メトリックを取得することをお勧めします。
利用可能な復元オプションは以下のとおりです。
Azure portal を使用した復元 - Azure portal を使用する場合、データベースを同じ Azure SQL Database サーバーに復元するオプションがあります。または、任意の Azure リージョンの新しいサーバーに新しいデータベースを作成する復元を使用できます。
スクリプト言語を使用した復元 - データベースの復元には PowerShell と Azure CLI の両方を利用できます。
注意
Azure blob storage へのコピーのみのバックアップは、SQL Managed Instance で使用できます。 SQL Database では、この機能はサポートされていません。
自動バックアップの詳細については、「自動バックアップ - Azure SQL Database & Azure SQL Managed Instance」を参照してください。
アクティブな地理的レプリケーション
geo レプリケーションは、データベースを最大 4 つのセカンダリ レプリカに非同期的にレプリケートする事業継続機能です。 トランザクションがプライマリ (と同じリージョン内のそのレプリカ) にコミットされると、そのトランザクションはセカンダリに送信されて再現されます。 この通信は非同期的に行われるため、SQL Server が呼び出し元に制御を返す前にセカンダリ レプリカによってトランザクションがコミットされるのを呼び出し元アプリケーションが待機する必要はありません。
セカンダリ データベースは読み取り可能で、読み取り専用ワークロードの負荷を減らすために使用できます。これにより、プライマリ上のトランザクション ワークロードのリソースを解放したり、データをエンド ユーザーの近くに配置したりできます。 さらに、セカンダリ データベースは、プライマリと同じリージョン、または別の Azure リージョンに配置できます。
geo レプリケーションを使用する場合、フェールオーバーの開始はユーザーが手動で行うことも、アプリケーションから行うこともできます。 フェールオーバーが発生すると、プライマリとなったデータベースの新しいエンドポイントを反映するために、アプリケーションの接続文字列の更新が必要になる可能性があります。
フェールオーバー グループ
フェールオーバー グループは、geo レプリケーションで使用されるテクノロジを土台として構築されますが、接続用に単一のエンドポイントを提供します。 フェールオーバー グループを使用する大きな理由は、このテクノロジによって提供されるエンドポイントです。これは、適切なレプリカにトラフィックをルーティングするために利用できます。 アプリケーションはフェールオーバー後に接続文字列を変更せずに接続できます。