正常性状態の収集、クエリ、視覚化
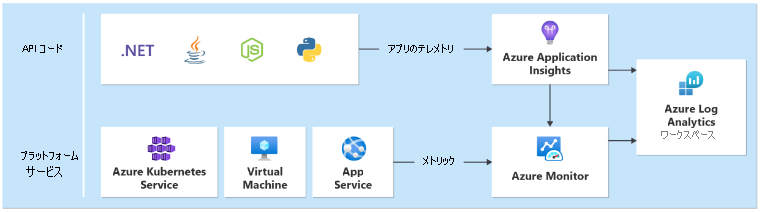
正常性モデルを正確に表すには、システムからさまざまなデータセットを収集する必要があります。 データセットには、アプリケーション コンポーネントおよび基になる Azure リソースからのログとパフォーマンス メトリックが含まれます。 データセット間でデータを関連付けて、システムの正常性を階層化して表現することが重要です。
コードとインフラストラクチャのインストルメント化
すべてのテレメトリが収集される 1 つの場所で、すべての運用データが格納されて使用できるようにするには、統合データ シンクが必要です。 たとえば、従業員によって Web ブラウザーでコメントが作成されたら、この操作を追跡し、要求が Catalog API を介して Azure Event Hubs に到達したことを確認することができます。 そこから、バックグラウンド プロセッサによってコメントが取得され、Azure Cosmos DB に格納されます。
Azure Monitor Log Analytics は、運用データを格納および分析するためのコア Azure ネイティブ統合データ シンクとして機能します。
Application Insights は、アプリケーション ログ、メトリック、トレースを収集するために、すべてのアプリケーション コンポーネントで推奨されるアプリケーション パフォーマンス監視 (APM) ツールです。 Application Insights は、各リージョンのワークスペース ベースの構成にデプロイされます。
サンプル アプリケーションでは、ネイティブ統合のためのバックエンド サービス用に Microsoft .NET 6 で Azure Functions が使用されています。 バックエンド アプリケーションは既に存在するため、Contoso Shoes では Azure に新しい Application Insights リソースのみを作成し、両方の関数アプリで
APPLICATIONINSIGHTS_CONNECTION_STRING設定を構成します。 Azure Functions ランタイムでは Application Insights ログ プロバイダーが自動的に登録されるため、テレメトリは追加の作業なしに Azure に表示されます。 よりカスタマイズされたログ記録を行うには、ILoggerインターフェイスを使用します。集中型データセットは、ミッション クリティカルなワークロードのアンチパターンです。 各リージョンには、専用の Log Analytics ワークスペースと Application Insights インスタンスが必要です。 グローバル リソースの場合は、個別のインスタンスを使用することをお勧めします。 コア アーキテクチャ パターンを確認するには、「Azure でのミッション クリティカルなワークロードのアーキテクチャ パターン」を参照してください。
分析と正常性の計算を容易にするために、各レイヤーでは同じ Log Analytics ワークスペースにデータを送信する必要があります。
正常性監視クエリ
Log Analytics、Application Insights、Azure Data Explorer ではすべて、クエリに Kusto 照会言語 (KQL) が使用されます。 KQL を使用してクエリを作成し、関数を使用してメトリックをフェッチし、正常性スコアを計算することができます。
正常性状態を計算する個々のサービスについては、次のサンプル クエリを参照してください。
Catalog API
次の例は、Catalog API クエリを示しています。
let _maxAge = 2d; // Include data only from the last two days
let _timespanStart = ago(_maxAge); // Start time for the time span
let _timespanEnd = now(-2m); // Account for ingestion lag by stripping the last 2m
// For time frame, compare the averages to the following threshold values
let Thresholds=datatable(MetricName: string, YellowThreshold: double, RedThreshold: double) [
"failureCount", 10, 50, // Failed requests, anything non-200, allow a few more than 0 for user-caused errors like 404s
"avgProcessingTime", 150, 500 // Average duration of the request, in ms
];
// Calculate average processing time for each request
let avgProcessingTime = AppRequests
| where AppRoleName startswith "CatalogService"
| where OperationName != "GET /health/liveness" // Liveness requests don't do any processing, including them would skew the results
| make-series Value = avg(DurationMs) default=0 on TimeGenerated from _timespanStart to _timespanEnd step 1m
| mv-expand TimeGenerated, Value
| extend TimeGenerated = todatetime(TimeGenerated), Value=toreal(Value), MetricName= 'avgProcessingTime';
// Calculate failed requests
let failureCount = AppRequests
| where AppRoleName startswith "CatalogService" // Liveness requests don't do any processing, including them would skew the results
| where OperationName != "GET /health/liveness"
| make-series Value=countif(Success != true) default=0 on TimeGenerated from _timespanStart to _timespanEnd step 1m
| mv-expand TimeGenerated, Value
| extend TimeGenerated = todatetime(TimeGenerated), Value=toreal(Value), MetricName= 'failureCount';
// Union all together and join with the thresholds
avgProcessingTime
| union failureCount
| lookup kind = inner Thresholds on MetricName
| extend IsYellow = iff(todouble(Value) > YellowThreshold and todouble(Value) < RedThreshold, 1, 0)
| extend IsRed = iff(todouble(Value) > RedThreshold, 1, 0)
| project-reorder TimeGenerated, MetricName, Value, IsYellow, IsRed, YellowThreshold, RedThreshold
| extend ComponentName="CatalogService"
Azure Key Vault
次の例は、Azure Key Vault クエリを示しています。
let _maxAge = 2d; // Include data only from the last two days
let _timespanStart = ago(_maxAge); // Start time for the time span
let _timespanEnd = now(-2m); // Account for ingestion lag by stripping the last 2m
// For time frame, compare the averages to the following threshold values
let Thresholds = datatable(MetricName: string, YellowThreshold: double, RedThreshold: double) [
"failureCount", 3, 10 // Failure count on key vault requests
];
let failureStats = AzureDiagnostics
| where TimeGenerated > _timespanStart
| where ResourceProvider == "MICROSOFT.KEYVAULT"
// Ignore authentication operations that have a 401. This is normal when using Key Vault SDK. First an unauthenticated request is made, then the response is used for authentication
| where Category=="AuditEvent" and not (OperationName == "Authentication" and httpStatusCode_d == 401)
| where OperationName in ('SecretGet','SecretList','VaultGet') or '*' in ('SecretGet','SecretList','VaultGet')
// Exclude Not Found responses because these happen regularly during 'Terraform plan' operations, when Terraform checks for the existence of secrets
| where ResultSignature != "Not Found"
// Create ResultStatus with all the 'success' results bucketed as 'Success'
// Certain operations like StorageAccountAutoSyncKey have no ResultSignature; for now, also set to 'Success'
| extend ResultStatus = case ( ResultSignature == "", "Success",
ResultSignature == "OK", "Success",
ResultSignature == "Accepted", "Success",
ResultSignature);
failureStats
| make-series Value=countif(ResultStatus != "Success") default=0 on TimeGenerated from _timespanStart to _timespanEnd step 1m
| mv-expand TimeGenerated, Value
| extend TimeGenerated = todatetime(TimeGenerated), Value=toreal(Value), MetricName="failureCount", ComponentName="Keyvault"
| lookup kind = inner Thresholds on MetricName
| extend IsYellow = iff(todouble(Value) > YellowThreshold and todouble(Value) < RedThreshold, 1, 0)
| extend IsRed = iff(todouble(Value) > RedThreshold, 1, 0)
カタログ サービス正常性スコア
最終的には、さまざまな正常性状態クエリを結び付けて、コンポーネントの正常性スコアを計算できます。 次のサンプル クエリは、カタログ サービス正常性スコアを計算する方法を示しています。
CatalogServiceHealthStatus()
| union AksClusterHealthStatus()
| union KeyvaultHealthStatus()
| union EventHubHealthStatus()
| where TimeGenerated < ago(2m)
| summarize YellowScore = max(IsYellow), RedScore = max(IsRed) by bin(TimeGenerated, 2m)
| extend HealthScore = 1 - (YellowScore * 0.25) - (RedScore * 0.5)
| extend ComponentName = "CatalogService", Dependencies="AKSCluster,Keyvault,EventHub" // These values are added to build the dependency visualization
| order by TimeGenerated desc
ヒント
Azure Mission-Critical Online GitHub リポジトリのその他のサンプル クエリを参照してください。
クエリ ベースのアラートを設定する
アラートは、正常性状態を反映するか影響を与える問題に直ちに注意を向けるものです。 正常性状態が低下 (黄色) 状態または異常 (赤) 状態に変化した場合は常に、責任を負うチームに通知を送信する必要があります。 ソリューションの正常性状態におけるビジネス レベルの変化をすぐに認識できるように、正常性モデルのルート ノードでアラートを設定します。 その後、正常性モデルの視覚化を参照して、詳細情報を取得し、トラブルシューティングを行うことができます。
この例では、Azure Monitor アラートを使用して、アプリケーションの正常性状態の変化に応じて自動アクションを推進します。
ダッシュボードを使用して視覚化する
コンポーネントの停止がシステム全体に及ぼす影響をすばやく把握できるように、正常性モデルを視覚化することが重要です。 正常性モデルの最終的な目標は、安定した状態からの逸脱に関する情報に基づいたビューを提供することで、迅速な診断を容易に行えるようにすることです。
システム正常性情報を視覚化する一般的な方法は、階層化された正常性モデル ビューと、ダッシュボードのテレメトリ ドリルダウン機能を組み合わせることです。
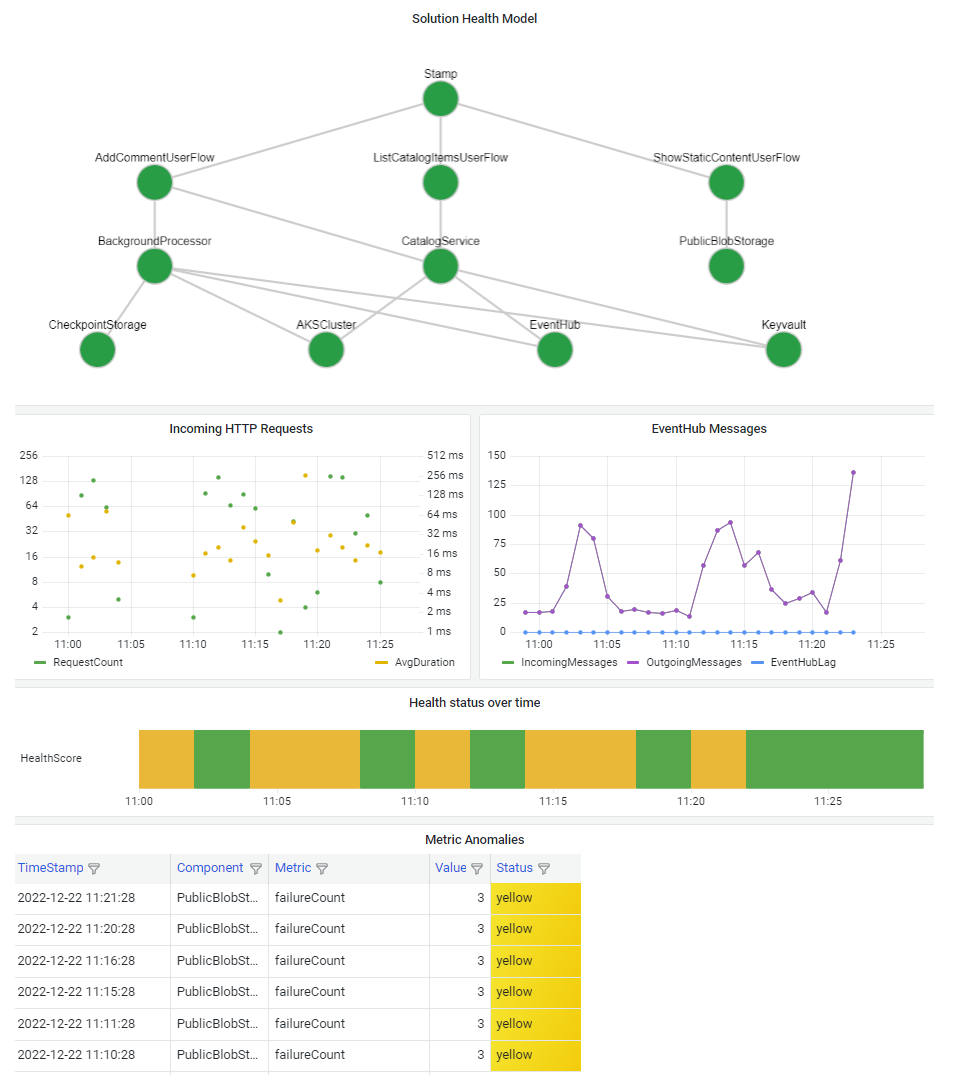
ダッシュボード テクノロジでは、正常性モデルを表すことができる必要があります。 一般的なオプションには、Azure ダッシュボード、Power BI、Azure Managed Grafana などがあります。