Azure Database for PostgreSQL にベクトルを格納する
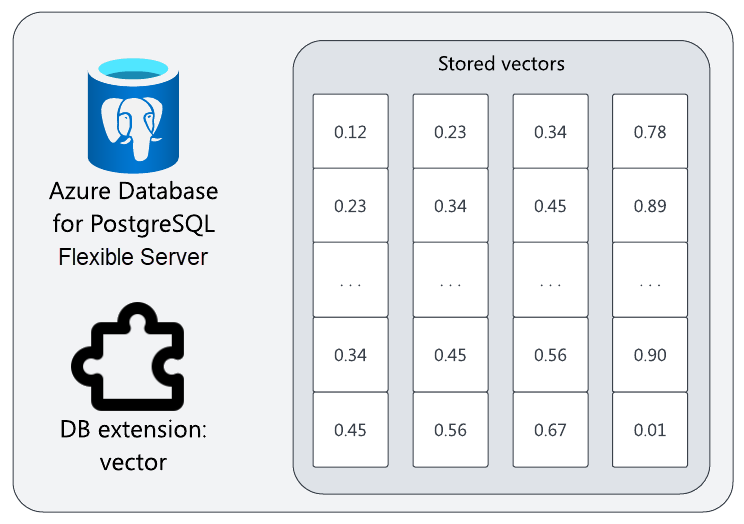
セマンティック検索を実行するには、埋め込みベクトルがベクトル データベースに格納されている必要があることを思い出してください。 Azure Database for PostgreSQL フレキシブル サーバーは、vector 拡張機能を備えたベクトル データベースとして使用できます。
vector の概要
オープンソースの vector 拡張機能は、ベクトル ストレージ、類似度クエリ、その他のベクトル操作を PostgreSQL に提供します。 有効にした後は、vector 列を作成して、他の列と共に埋め込み (または他のベクトル) を格納できます。
/* Enable the extension. */
CREATE EXTENSION vector;
/* Create a table containing a 3d vector. */
CREATE TABLE documents (id bigserial PRIMARY KEY, embedding vector(3));
/* Create some sample data. */
INSERT INTO documents (embedding) VALUES
('[1,2,3]'),
('[2,1,3]'),
('[4,5,6]');
既存のテーブルにベクトル列を追加できます。
ALTER TABLE documents ADD COLUMN embedding vector(3);
ベクトル データが用意できたら、通常のテーブル データと共にそれを確認できます。
# SELECT * FROM documents;
id | embedding
----+-----------
1 | [1,2,3]
2 | [2,1,3]
3 | [4,5,6]
vector 拡張機能では、.NET、Python、Java など、複数の言語がサポートされています。 詳しくは、GitHub リポジトリを参照してください。
C# で Npgsql を使ってベクトル [1, 2, 3] でドキュメントを挿入するには、次のようなコードを実行します。
var sql = "INSERT INTO documents (embedding) VALUES ($1)";
await using (var cmd = new NpgsqlCommand(sql, conn))
{
var embedding = new Vector(new float[] { 1, 2, 3 });
cmd.Parameters.AddWithValue(embedding);
await cmd.ExecuteNonQueryAsync();
}
ベクターの挿入と更新を行う
テーブルにベクトル列が含まれるようになったら、前に説明したように、ベクトル値を使って行を追加できます。
INSERT INTO documents (embedding) VALUES ('[1,2,3]');
COPY ステートメントを使ってベクトルを一括で読み込むこともできます (Python での完全な例を参照)。
COPY documents (embedding) FROM STDIN WITH (FORMAT BINARY);
標準列のようにベクトル列を更新できます。
UPDATE documents SET embedding = '[1,1,1]' where id = 1;
コサイン距離検索を実行する
vector 拡張機能には、ベクトル v1 と v2 の間のコサイン距離を計算する v1 <=> v2 演算子があります。 結果は 0 から 2 の間の数値で、0 は "意味的に同一" (距離なし) を意味し、2 は "意味的に反対" (最大距離) を意味します。
用語のコサイン距離と類似度を確認できます。 コサイン類似度は -1 から 1 の間であり、-1 は "意味的に反対" の意味、1 は "意味的に同一" の意味であることを思い出してください。similarity = 1 - distance に注意してください。
結果として、クエリを距離の昇順に並べ替えると最も近い (最も似ている) 結果が最初に返され、クエリを類似度の降順に並べ替えると最も似ている (最も近い) 結果が最初に返されます。
次に、ベクトルとその距離および類似度の概念をいくつか示します。 この計算は、次のようなものを実行して自分で計算できます。
SELECT '[1,1]' <=> '[-1,-1]';
次のベクトルについて考えます。
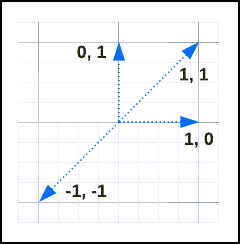
類似度と距離は次のとおりです。
| v1 | V2 | distance | 類似性 |
|---|---|---|---|
[1, 1] |
[1, 1] |
0 | 1 |
[1, 1] |
[-1, -1] |
2 | -1 |
[1, 0] |
[0, 1] |
1 | 0 |
ベクトル [2, 3, 4] に近い順序でドキュメントを取得するには、次のクエリを実行します。
SELECT
*,
embedding <=> '[2,3,4]' AS distance
FROM documents
ORDER BY distance;
結果:
id | embedding | distance
----+-----------+-----------------------
3 | [4,5,6] | 0.0053884541273605535
1 | [1,2,3] | 0.007416666029069763
2 | [2,1,3] | 0.05704583272761632
id=3 のドキュメントがクエリに最も似ており、そのすぐ後が id=1、最後が id=2 です。
最も似ている N 個のドキュメントを返すには、LIMIT N 句を SELECT クエリに追加します。 たとえば、最も似ているドキュメントを取得するには、次のようにします。
SELECT
*,
embedding <=> '[2,3,4]' AS distance
FROM documents
ORDER BY distance
LIMIT 1;
結果:
id | embedding | distance
----+-----------+-----------------------
3 | [4,5,6] | 0.0053884541273605535