データ形式を識別する
データは、情報の記録に使用される数値、説明、観察などのファクトのコレクションです。 このデータが編成されるデータ構造は、多くの場合、組織にとって重要な "エンティティ" (顧客、製品、販売注文など) を表します。 各エンティティには通常、1 つ以上の "属性" または特性があります (たとえば、顧客は名前、住所、電話番号などを持つ場合があります)。
データは "構造化"、"半構造化"、"非構造化" に分類することができます。
構造化データ
構造化データとは固定 "スキーマ" に準拠したデータであり、すべてのデータが同じフィールドとプロパティを持っています。 最も一般的に、構造化データ エンティティのスキーマは "表形式" です。つまり、データは、データ エンティティの各インスタンスを表す行と、エンティティの属性を表す列で構成される 1 つ以上のテーブルで表されます。 たとえば、次の図は Customer および Product エンティティの表形式のデータ表現を示しています。
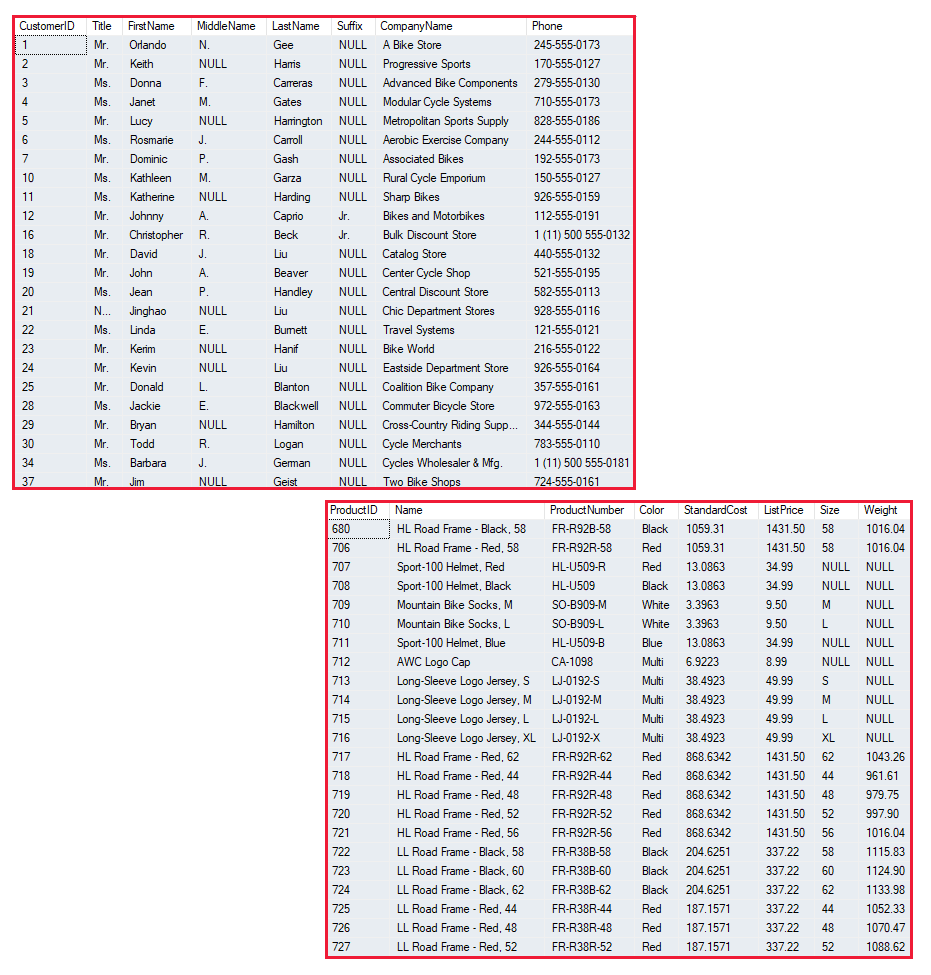
構造化データは、多くの場合、"リレーショナル" モデルのキー値を使用して複数のテーブルが参照できるデータベースに格納されます。詳細については後ほど説明します。
半構造化データ
"半構造化" データは、ある程度の構造を持つ情報ですが、エンティティ インスタンス間の一部のバリエーションを可能にする情報です。 たとえば、ほとんどの顧客はメール アドレスを持っている場合でも、複数のメール アドレスを持っている人もいれば、1 つも持っていない人もいます。
半構造化データの一般的な形式の 1 つが、JavaScript Object Notation (JSON) です。 以下の例は、顧客情報を表す JSON ドキュメントのペアを示します。 各顧客ドキュメントには住所と連絡先情報が含まれていますが、個別のフィールドは顧客によって異なります。
// Customer 1
{
"firstName": "Joe",
"lastName": "Jones",
"address":
{
"streetAddress": "1 Main St.",
"city": "New York",
"state": "NY",
"postalCode": "10099"
},
"contact":
[
{
"type": "home",
"number": "555 123-1234"
},
{
"type": "email",
"address": "joe@litware.com"
}
]
}
// Customer 2
{
"firstName": "Samir",
"lastName": "Nadoy",
"address":
{
"streetAddress": "123 Elm Pl.",
"unit": "500",
"city": "Seattle",
"state": "WA",
"postalCode": "98999"
},
"contact":
[
{
"type": "email",
"address": "samir@northwind.com"
}
]
}
Note
JSON は、半構造化データを表現できる多くの方法のうちの 1 つです。 ここでのポイントは、JSON 構文の詳細な調査ではなく、半構造化データ表現の柔軟な性質を示すことです。
非構造化データ
すべてのデータが構造化または半構造化されているわけではありません。 たとえば、ドキュメント、画像、オーディオおよびビデオ データ、バイナリ ファイルには、特定の構造がない場合があります。 この種のデータは "非構造化" データと呼ばれます。

データ ストア
組織は通常、エンティティの詳細 (顧客や製品など)、特定のイベント (販売取引など)、その他の情報をドキュメント、画像、その他の形式で記録するために、構造化、半構造化、または非構造化形式でデータを格納します。 保存されたデータは、後で分析とレポートのために取得できます。
一般的に使用されるデータ ストアには、次の 2 つの大きなカテゴリがあります。
- ファイル ストア
- データベース
以降のトピックで、これらの両方の種類のデータ ストアについて説明します。