分析データ処理を調べる
分析データ処理では、通常、履歴データまたはビジネス メトリックの膨大な量を格納する読み取り専用 (または read-mostly) システムが使用されます。 分析は、特定の時点のデータのスナップショットまたは一連のスナップショットに基づいて行うことができます。
分析処理システムの具体的な詳細はソリューションによって異なる場合がありますが、エンタープライズ規模の分析の一般的なアーキテクチャは次のようになります。
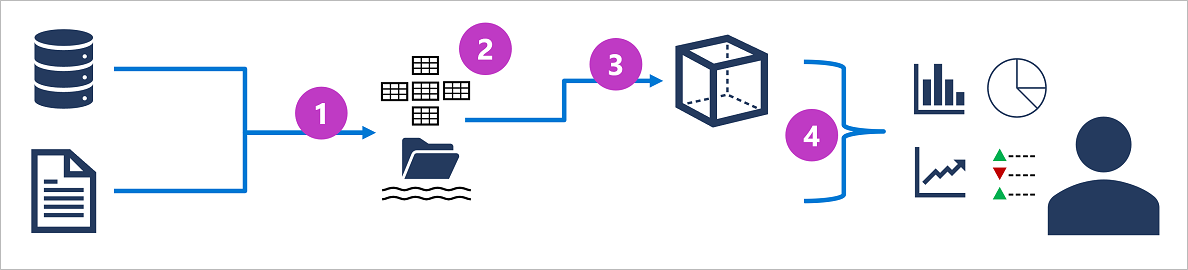
- オペレーショナル データは解析用に抽出され、変換され、データ レイクに読み込まれます (ETL)。
- データはテーブルのスキーマに読み込まれます。通常は、データ レイク内のファイルに対して表形式の抽象化を行う Spark ベースのデータ レイクハウス、または完全なリレーショナル型の SQL エンジンを備えたデータ ウェアハウスです。
- データ ウェアハウス内のデータを集計し、オンライン分析処理 (OLAP) モデル (キューブ) に読み込む場合があります。 ファクト テーブルの集計数値 ("メジャー") は、ディメンション テーブルからの "ディメンション" の交差部分に対して計算されます。 たとえば、売上収益は、日付、顧客、製品別に合計される場合があります。
- データ レイク、データ ウェアハウス、分析モデル内のデータに対してクエリを実行して、レポート、視覚化、ダッシュボードを生成することができます。
"データ レイク" は、大量のファイル ベースのデータを収集して分析する必要がある大規模データ分析処理シナリオで一般的です。
"データ ウェアハウス" は、読み取り操作用に最適化されたリレーショナル スキーマにデータを格納するための確立された方法です。主に、レポートとデータの視覚化をサポートするためのクエリが実行されます。 データ レイクハウスは、データ レイクの柔軟でスケーラブルなストレージと、データ ウェアハウスのリレーショナル クエリ セマンティクスを組み合わせた、より新しいイノベーションです。 テーブル スキーマでは、OLTP データ ソース内のデータの非正規化が必要となる場合があります (クエリの実行を高速化するための複製の導入)。
OLAP モデルは、分析ワークロード用に最適化された集計型のデータ ストレージです。 データ集計はさまざまなレベルのディメンションにまたがり、複数の階層レベルで集計を表示するために "ドリル アップまたはダウン" することができます。たとえば、地域別、市区町別、または個々の住所の合計売上を検索する場合などです。 OLAP データは事前に集計済みなので、それに含まれる概要を返すクエリをすばやく実行できます。
さまざまな種類のユーザーが、アーキテクチャ全体の異なるステージでデータ分析作業を実行する場合があります。 次に例を示します。
- データ サイエンティストは、データ レイク内のデータ ファイルを直接使用して、データの探索とモデル化を行う場合があります。
- データ アナリストは、複雑なレポートと視覚化を生成するために、データ ウェアハウス内のテーブルに直接クエリを実行できます。
- ビジネス ユーザーは、レポートまたはダッシュボードの形式で、分析モデル内で事前に集計済みのデータを使用する場合があります。