大規模言語モデルとは?
生成 AI アプリケーションでは、言語モデルが利用されます。これは、次のような自然言語処理 (NLP) タスクを実行するために使用できる、専門化された種類の機械学習モデルです:
- "センチメント" を決定する、または自然言語テキストを分類する。
- テキストを要約する。
- 意味上の類似性について複数のテキスト ソースを比較する。
- 新しい自然言語を生成する。
これらの言語モデルの背後にある数学的原理は複雑である可能性がありますが、それらを実装するために使用されるアーキテクチャの基礎知識があると、それらの仕組みをおおまかに理解するのに役立ちます。
トランスフォーマー モデル
自然言語処理用の機械学習モデルは、長年にわたって進化してきました。 今日の最先端の大規模言語モデルは、"トランスフォーマー" アーキテクチャに基づいています。このアーキテクチャは、NLP タスクをサポートするための "ボキャブラリ" のモデリングと特に言語の生成に成功していることが証明されているいくつかの手法に基づいて構築され、拡張されています。 トランスフォーマー モデルは大量のテキストを使用してトレーニングされます。これにより、モデルは、単語間の意味上の関係を表現し、それらの関係を使用して意味のあるテキストと推測されるシーケンスを決定できるようになります。 十分なボキャブラリを使用するトランスフォーマー モデルは、人間の応答と区別できないほど自然な言語応答を生成できます。
トランスフォーマー モデル アーキテクチャは、次の 2 つのコンポーネント ("ブロック") で構成されます。
- "エンコーダー" ブロック: トレーニングしているボキャブラリの意味的な表現を作成します。
- "デコーダー" ブロック: 新しい言語シーケンスを生成します。
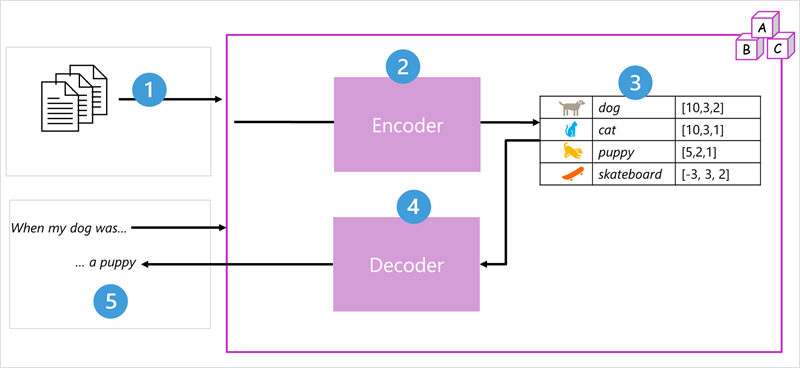
- モデルは大量の自然言語テキストでトレーニングされています。多くの場合、それらのテキストは、インターネットやその他の公的な情報源から供給されています。
- テキストのシーケンスは複数のトークン (たとえば、個々の単語) に分解され、エンコーダー ブロックは、アテンションと呼ばれる手法を使用してこれらのトークン シーケンスを処理してトークン間の関係を判断します (たとえば、どのトークンがシーケンス内の他のトークン、同じ文脈で一般的に使用されるさまざまなトークンなどの存在に影響を与えるか)。
- エンコーダーからの出力は、ベクトル (多値の数値配列) のコレクションであり、ベクトルの各要素はトークンの意味属性を表しています。 これらのベクトルは埋め込みと呼ばれます。
- デコーダー ブロックで、テキスト トークンの新しいシーケンスが処理され、エンコーダーから生成された埋め込みが使用されて適切な自然言語出力が生成されます。
- たとえば、"When my dog was" のような入力シーケンスが与えられたとすると、このモデルは、アテンション手法を使用して入力トークンと埋め込み内にエンコードされたセマンティック属性を分析し、この文の適切な補完 ("a puppy" など) を予測できます。
実際には、アーキテクチャの実装は個々に異なります。たとえば、検索エンジンをサポートするために Google によって開発された Bidirectional Encoder Representations from Transformers (BERT) モデルはエンコーダー ブロックのみを使用しますが、OpenAI によって開発された Generative Pretrained Transformer (GPT) モデルはデコーダー ブロックのみを使用します。
トランスフォーマー モデルのあらゆる側面について完全に説明するのは、このモジュールの範囲を超えていますが、トランスフォーマーのいくつかの主要な要素について説明することにより、トランスフォーマーで生成 AI がサポートされる方法を理解しやすくなります。
トークン化
トランスフォーマー モデルをトレーニングする最初の手順は、トレーニング テキストを "トークン" に分解することです。つまり、各一意のテキスト値を識別します。 わかりやすくするために、トレーニング テキスト内の個々の単語をそれぞれトークンとして考えることができます (ただし、実際には、単語の一部、または単語と句読点の組み合わせに対してトークンを生成できます)。
たとえば、次の文について考えてみましょう。
I heard a dog bark loudly at a cat
このテキストをトークン化するには、個々の単語を識別し、それらにトークン ID を割り当てることができます。 次に例を示します。
- I (1)
- heard (2)
- a (3)
- dog (4)
- bark (5)
- loudly (6)
- at (7)
- *("a" is already tokenized as 3)*
- cat (8)
これで、この文を次のトークンで表すことができるようになりました: {1 2 3 4 5 6 7 3 8}。 同様に、"I heard a cat" (猫の鳴き声を聞いた) という文は、{1 2 3 8} と表すことができます。
モデルのトレーニングを続けるに従って、トレーニング テキスト内の新しい各トークンが、適切なトークン ID でボキャブラリに追加されます。
- meow (9)
- skateboard (10)
- "など"
十分に大きなトレーニング テキストのセットを使用すると、何千ものトークンのボキャブラリを作成できます。
埋め込み
トークンを単純な ID として表す (基本的にはボキャブラリ内のすべての単語のインデックスを作成します) と便利かもしれませんが、単語の意味や単語間の関係は説明されません。 トークン間の意味上の関係をカプセル化するボキャブラリを作成するには、トークンの "埋め込み" と呼ばれるコンテキスト ベクトルを定義します。 ベクトルは、各数値要素が情報の特定の属性を表す情報の多値数値表現 (たとえば、[10, 3, 1]) です。 言語トークンの場合、トークンのベクトルの各要素はトークンの何らかの意味属性を表します。 言語モデルでは、ベクトルの要素の特定のカテゴリは、トレーニング中に、単語が一緒に、または同様の文脈でどの程度一般的に使用されるかに基づいて決定されます。
ベクトルは多次元空間の線を表し、複数の軸に沿った方向と距離を記述します (これらの振幅と大きさを呼び出すことで、数学者の友人を感心させることができます)。 トークンの埋め込みベクトル内の要素は、多次元空間のパスに沿ったステップを表すものと考えると便利です。 たとえば、3 つの要素を持つベクトルは、要素の値が前後、左右、上下に移動したことを示す 3 次元空間のパスを表します。 全体として、ベクトルは、原点から終点までのパスの方向と距離を記述します。
埋め込み空間でのトークンの要素はそれぞれそのトークンの意味属性を表しているため、意味が似ているトークンは、向きが似ているベクトル (つまり、それらは同じ方向を指している) になります。 コサイン類似度と呼ばれる手法は、2 つのベクトルの方向が似ているかどうか (距離には関係ない)、したがって意味的につながりのある単語を表しているかどうかを判断するために使用されます。 簡単な例として、トークンの埋め込みが、次のような 3 つの要素を持つベクトルで構成されているとします。
- 4 ("dog"): [10,3,2]
- 8 ("cat"): [10,3,1]
- 9 ("puppy"): [5,2,1]
- 10 ("skateboard"): [-3,3,2]
3 次元空間ではこれらのベクトルを次のように描くことができます:
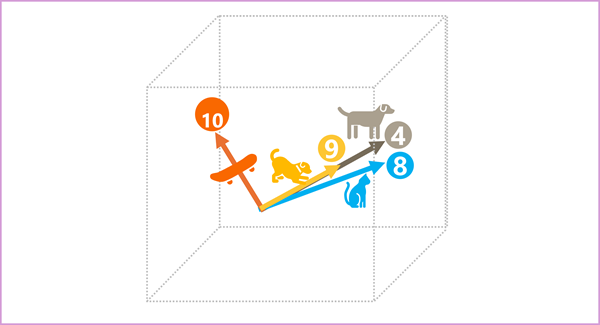
“dog” と “puppy” の埋め込みベクトルは、ほぼ同じ方向に沿ったパスを描いています。これは、“cat” の方向にもかなり似ています。 しかし、"skateboard" の埋め込みベクトルは、まったく異なる方向の過程を表します。
Note
前の例は、各埋め込みの次元が 3 つのみである単純なモデル例を示しています。 実際の言語モデルには、さらに多くの次元があります。
特定のトークン セットに対して適切な埋め込みを計算するには、Word2Vec などの言語モデリング アルゴリズムやトランスフォーマー モデルの "エンコーダー" ブロックなど、複数の方法があります。
Attention
トランスフォーマー モデルの "エンコーダー" および "デコーダー" ブロックには、モデルのニューラル ネットワークを形成する複数のレイヤーが含まれています。 これらすべてのレイヤーの詳細を調べる必要はありませんが、両方のブロックで使用される種類のレイヤーの 1 つ ("アテンション" レイヤー) を検討するとよいでしょう。 アテンションは、テキスト トークンのシーケンスを調べて、それらの間の関係の強さを定量化するために使用される手法です。 特に、"セルフアテンション" では、1 つの特定のトークンの周囲にある他のトークンがそのトークンの意味にどのように影響するかを考慮する必要があります。
エンコーダー ブロックでは、各トークンがコンテキストに照らし合わせて慎重に調べられ、ベクトル埋め込み用の適切なエンコードが決定されます。 ベクトル値は、トークンと、それと共に頻繁に出現する他のトークンとの間の関係に基づきます。 このコンテキスト化されたアプローチは、同じ単語が、それを使用する文脈に応じて複数の埋め込みを持つ可能性があることを意味します。たとえば、"the bark of a tree" (木の樹皮) は "I heard a dog bark" (犬のほえ声を聞いた) と異なるものを意味します。
デコーダー ブロックでは、アテンション レイヤーを使用してシーケンス内の次のトークンを予測します。 モデルには、生成されるトークンごとに、その時点までのトークンのシーケンスを考慮したアテンション レイヤーがあります。 このモデルでは、次のトークンを何にすべきかを検討する際、最も影響力のあるトークンがどれであるかを考慮します。 たとえば、"I heard a dog" というシーケンスがあるとすると、アテンション レイヤーでは、シーケンス内の次の単語を検討するときに、トークン "heard" と "dog" により大きな重みが割り当てられる可能性があります。
I heard a dog [bark]
アテンション レイヤーでは、実際のテキストではなく、トークンの数値ベクトル表現を操作していることに注意してください。 デコーダーでは、プロセスは、完成するテキストを表すトークン埋め込みのシーケンスから始まります。 まず、別の "位置エンコーディング" レイヤーで各埋め込みに値が追加されて、シーケンス内での位置が示されます。
- [1,5,6,2] (I)
- [2,9,3,1] (heard)
- [3,1,1,2] (a)
- [4,10,3,2] (dog)
トレーニング中の目標は、シーケンス内の最後のトークンのベクトルを、その前にあるトークンに基づいて予測することです。 アテンション レイヤーでは、シーケンス内のこれまでの各トークンに数値の "重み" が割り当てられます。 その値を使用して、重み付けされたベクトルの計算が実行され、次のトークンの考えられるベクトルを計算するために使用できる "アテンション スコア" が生成されます。 実際には、"マルチヘッド アテンション" と呼ばれる手法では、埋め込みのさまざまな要素を使用して複数のアテンション スコアが計算されます。 その後、ニューラル ネットワークを使用して、考えられるすべてのトークンが評価され、シーケンスを続ける最も可能性の高いトークンが決定されます。 このプロセスはシーケンス内の各トークンに反復的に続行され、これまでの出力シーケンスが次の反復の入力として回帰的に使用され、基本的に一度に 1 トークンずつ出力が構築されます。
次のアニメーションは、このしくみをシンプルに表したものです。アテンション レイヤーによって実際に実行される計算はこれよりも複雑ですが、原則はここに示されているように簡略化できます。

- トークン埋め込みのシーケンスは、アテンション レイヤーにフィードされます。 各トークンは、数値のベクトルとして表されます。
- デコーダーの目標は、シーケンス内の次のトークンを予測することです。これは、モデルのボキャブラリ内の埋め込みに合わせたベクトルでもあります。
- アテンション レイヤーでは、これまでのシーケンスを評価し、各トークンに重みを割り当てて、次のトークンに対する相対的な影響を表します。
- この重みは、アテンション スコアを使用して次のトークンの新しいベクトルを計算するために使用できます。 マルチヘッド アテンションでは、埋め込み内のさまざまな要素を使用して複数の代替トークンが計算されます。
- 完全に接続されたニューラル ネットワークでは、計算ベクトルのスコアを使用して、ボキャブラリ全体から最も可能性の高いトークンを予測します。
- 予測された出力は、これまでのシーケンスに追加され、次の反復の入力として使用されます。
トレーニング中に、トークンの実際のシーケンスがわかります。シーケンス内で、現在検討中のトークンの位置よりも後ろにあるものはマスクされているだけです。 他のニューラル ネットワークと同様に、トークン ベクトルの予測値がシーケンス内の次のベクトルの実際の値と比較され、損失が計算されます。 その後、損失を減らしモデルを改善するために、重みが段階的に調整されます。 推論 (新しいトークンのシーケンスの予測) に使用される場合、トレーニング済みのアテンション レイヤーでは、これまでのシーケンスと意味的に一致するモデルのボキャブラリ内で最も可能性の高いトークンを予測する重みが適用されます。
つまり、GPT-4 (ChatGPT や Bing の背後にあるモデル) などのトランスフォーマー モデルは、テキスト入力 (プロンプトと呼ばれます) を受け取り、構文的に正しい出力 (入力候補と呼ばれます) を生成するように設計されています。 実際、このモデルの "魔法" は、一貫した文をつなぎ合わせて文字列にできることです。 この能力はモデル側の "知識" や "知性" ではなく、豊富なボキャブラリと、意味のある単語のシーケンスを生成する能力を意味しています。 ただし、GPT-4 のような大規模な言語モデルを非常に強力にしているのは、トレーニングに使用された膨大な量のデータ (インターネットからの公開され、ライセンスされたデータ) とネットワークの複雑さです。 これにより、モデルは、モデルがトレーニングされたボキャブラリ内の単語間の関係に基づいて入力候補を生成できるようになります。多くの場合、同じプロンプトに対する人間の応答と区別できないほどの自然な出力が生成されます。