Azure HDInsight とは
HDInsight の機能と使用方法を確認しましょう。 この概要は、HDInsight がご自分の組織の要件に対応しているかどうかを評価するのに役立ちます。
ビッグ データとは
"ビッグ データ" という用語は、組織が収集する膨大な量の構造化 "および" 非構造化データを表します。 このデータは、組織にとって非常に有益である可能性があります。 特に、分析情報が得られるようにデータを分析できれば、組織はより適切に意思決定を行うことができます。 結果として、これらの意思決定によって、組織のさらなる成功につながる可能性があります。 たとえば、ビッグ データ分析を使用すると、商業組織は顧客の習慣を認識できるようになり、売上増加につながる可能性があります。
Azure HDInsight の定義
Azure HDInsight は、企業向けのフル マネージド、クラウドベースのオープンソース分析サービスです。 HDInsight を使用すると、ご自分のビッグ データを制御し、管理することができます。 HDInsight:
Hadoop コンポーネントのクラウド ディストリビューションです。
膨大な量のデータをより簡単に、より速く、よりコスト効率の高い方法で処理できるようします。
次のようなオープンソース フレームワークの使用をサポートしています。
- Hadoop
- Apache Spark
- Apache Hive
- Apache Kafka
Note
これらのフレームワークにより、抽出/変換/読み込み (ETL)、データ ウェアハウス、機械学習、IoT など、幅広いシナリオに対応できます。
HDInsight を使用することで、ビッグ データを扱っている組織は、いくつかの利点が得られます。 次の特徴を備えています。
オープンソース: さまざまなオープンソース フレームワーク用に最適化されたクラスターを作成できます。
高信頼: すべての運用ワークロードにエンドツーエンドの SLA を提供します。
スケーラブル: 需要の変化に応じてワークロードをスケーリングできます。
ヒント
必要に応じてクラスターを作成することにより、コストを削減できます。 支払うのは、使用した分だけです。
セキュア: 以下と統合することで、エンタープライズ データ資産を保護できます。
- Azure Virtual Network
- Azure の暗号化テクノロジ
- Microsoft Entra ID
準拠: 業界や行政上の一般的なコンプライアンス基準を満たしています。
監視中: Azure Monitor ログと統合して、単一のインターフェイスが提供されます。 単一のインターフェイスを使用して、すべてのクラスターを監視します。
ビッグ データの処理に役立つ HDInsight
HDInsight は、ビッグ データ処理を利用するさまざまなシナリオで使用できます。 データには、次のものがあります。
- 履歴データ: このデータは既に収集され、格納されています。
- リアルタイム データ: このデータは、ソースから直接ストリーミングされます。
次のカテゴリは、このデータの処理シナリオをまとめたものです。
- バッチ処理
- データ ウェアハウス
- IoT
- データ サイエンス
- ハイブリッド
次に、これらのカテゴリについて詳しく説明します。
バッチ処理
組織は、バッチ処理ジョブを使用して、詳細な分析ができるようにビッグ データを準備します。 通常、このプロセスは 3 つのステージを必要とします。
- 異種データ ソースからソース データ ファイルを読み取る。
- データを処理する。
- データをスケーラブルなストレージに書き込む。
Note
このプロセスは、ETL と呼ばれることがよくあります。
変換されたデータは、データ ウェアハウスまたはデータ サイエンスに使用できます。
ヒント
ETL の重要な要件は、コンピューティングのスケールアウトです。これにより、大規模なデータ ボリュームの処理が可能になります。
データ ウェアハウス
データ ウェアハウスにより、ビッグ データの分析を待機している間、格納しておくための場所が組織に提供されます。 データ ウェアハウスを使うと、次のことができます。
- データを格納します。
- 分析用にデータを準備します。
- 準備されたデータを構造化された形式で提供します。 その後、分析ツールを使用してデータのクエリを実行できます。
次の図は、HDInsight で Apache Hadoop を使用して複数のソースからデータを収集して格納する方法を示しています。 データの準備と分析が、Apache Spark と Apache Hive によって行われます。 最後に、データは、ビジネス インテリジェンス (BI) ツールで使用するためにモデル化されます。 データを視覚化するために Power BI が使用されています。
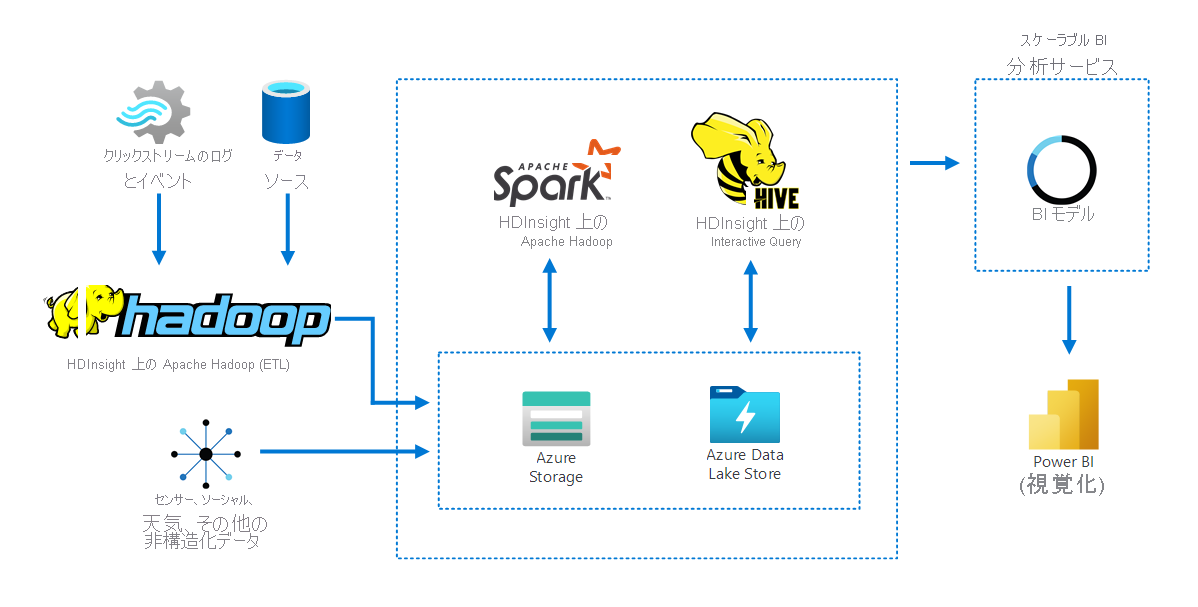
このシナリオには次のコンポーネントが含まれます。
- Apache Spark は並列処理フレームワークです。 メモリ内処理をサポートし、ビッグ データ分析アプリケーションのパフォーマンスを向上させることができます。
- HDInsight の Apache Hive は、Apache Hadoop 用のデータ ウェアハウス システムです。 Hive を使用すると、データの概要作成、クエリ、および分析を行うことができます。 これらのコンポーネントを使用して、あらゆる形式の構造化および非構造化データに対してペタバイト規模でクエリを実行できます。
ヒント
Hive クエリは、SQL に似たクエリ言語である HiveQL で記述します。
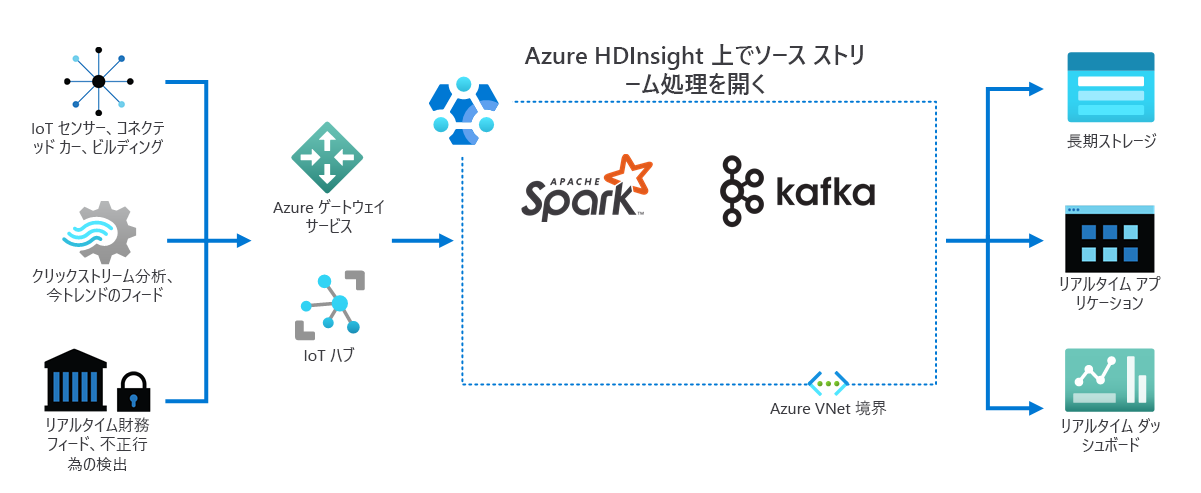
モノのインターネット
次の図に示すように、さまざまなデバイスやセンサーからリアルタイムで受信したストリーミング データが HDInsight によって処理されます。 この例では、Apache Spark、Apache Kafka など、いくつかのオープンソース フレームワークによってストリーム処理が提供されています。
Azure ゲートウェイ サービスと IoT ハブによって、さまざまなソースのデータが、これらのフレームワークに転送されます。 次に、データは、フレームワークによって処理され、以下に渡されます。
- 長期ストレージ。
- リアルタイム アプリ。
- リアルタイム ダッシュボード。
データ サイエンス
HDInsight を使用して、次のような一般的なデータサイエンス タスクを完了できます。
- データ インジェスト。
- 特徴エンジニアリング
- モデル化。
- モデルの評価。
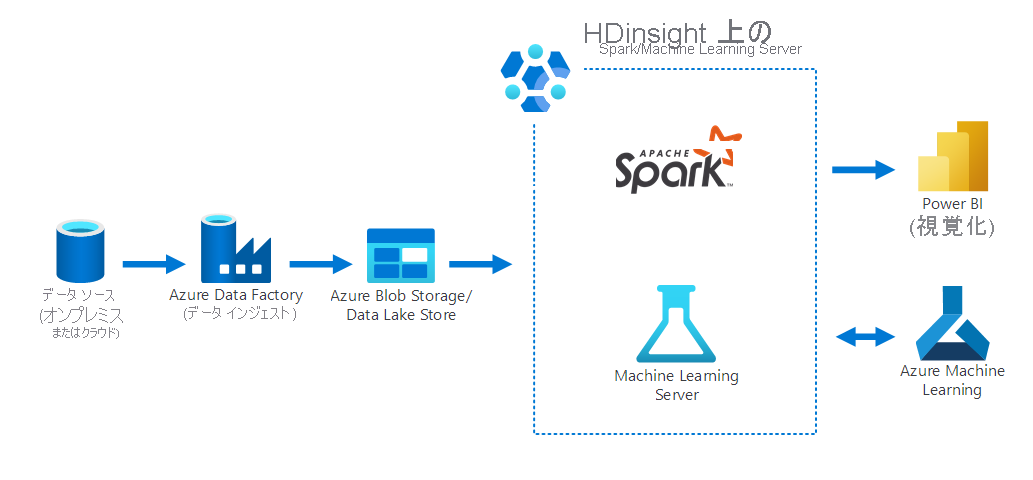
次の図は、データサイエンスのシナリオを示しています。
- データが、Azure Data Factory を使用して、オンプレミスのデータ ソースから収集されます。
- 取り込まれたデータは、次に Azure ストレージ (Azure Blob Storage または Data Lake Store) に格納されます。
- データは、HDInsight 上の Azure Spark によって処理され、Azure Machine Learning 用に準備されます。 また、データは、Power BI を使用して視覚化されます。
ハイブリッド
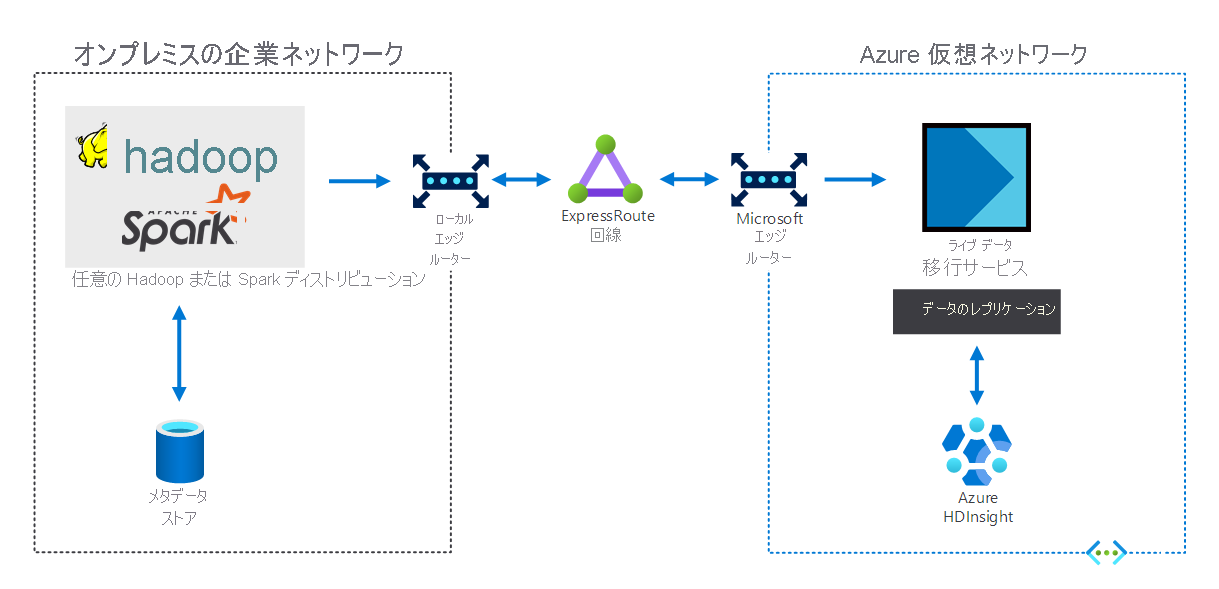
オンプレミスのビッグデータ インフラストラクチャを備えている組織は、HDInsight を使用して Azure に拡張できます。 これにより、Azure クラウドの高度な分析機能のメリットが得られます。 次の図は、ハイブリッド シナリオを示しています。
- オンプレミスのビッグデータ インフラストラクチャは、ローカル VM 上のメタデータ ストアと Hadoop または Spark ディストリビューションで構成されています。
- オンプレミスの企業ネットワーク環境と Azure 仮想ネットワークは、Azure ExpressRoute 回線で接続されています。
- オンプレミスから受信したデータは、Azure のライブ データ移行ツールによって、HDInsight にレプリケートされます。