Azure HDInsight のしくみ
ここでは、Azure HDInsight のしくみについて説明します。 次のコンポーネントについて、また、データ制御と管理を提供するためにそれらをどのように組み合わせるかについて説明します。
- Apache Hadoop
- HDInsight ストレージ
- HDInsight 処理
Apache Hadoop とは
Apache Hadoop は、HDInsight の中核となるクラウド分散型のデータ処理システムです。 3 つのコンポーネントがあり、次の表に説明を示します。
| Apache Hadoop コンポーネント | 説明 |
|---|---|
| HDFS | Hadoop システムのストレージが、Apache Hadoop 分散ファイル システム (HDFS) によって提供されます。 |
| YARN | システムの処理が、Apache Hadoop Yet Another Resource Negotiator (YARN) コンポーネントによって提供されます。 |
| MapReduce | MapReduce は、データの処理と分析を行うためのプログラミング モデルです。 |
コンポーネントとのやりとり
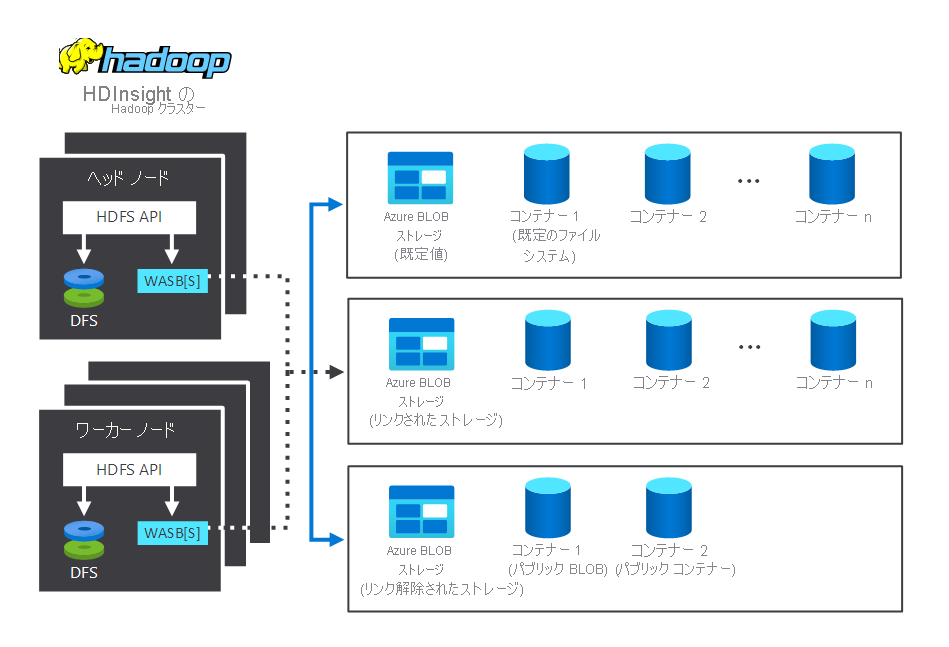
次の図は、一般的な HDInsight Hadoop クラスター内でやりとりするストレージと処理コンポーネントを示しています。 図には、次のコンポーネントが示されています。
- ヘッド ノードとワーカー ノード。ここで、処理が実行されます。
- ノード内の複数の Windows Azure Storage Blob (WASB) のストレージ センター。 HDFS により、これらのコンテナーとのやりとりが行われます。
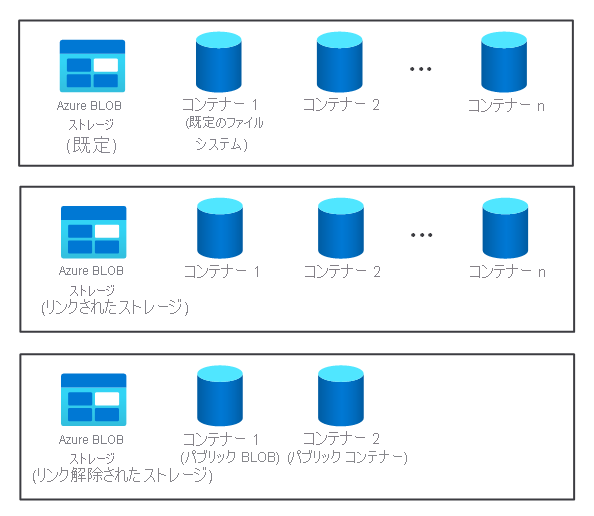
- 複数の既定、リンク、およびリンク解除されたストレージ コンテナー。 これらは 2 つのノードで使用できます。
次に、ストレージと処理のしくみについて説明します。
ストレージのしくみ
クラスターのストレージ コンポーネントは、HDInsight クラスターをプロビジョニングするときに自動的に作成されません。 代わりに、Azure Storage や Azure Data Lake などの HDFS に準拠したシステムによって提供されます。
クラスターのストレージ コンポーネントを処理コンポーネントから分離することには利点があります。 たとえば、計算にのみ使用される HDInsight クラスターは、データの損失を気にせずに安全に削除することができます。 HDInsight クラスターを追加する場合は、既定のファイル システムを定義する必要があります。
重要
Azure Storage には、既定のファイル システムとして BLOB コンテナーを指定する必要があります。
既定のファイル システムを提供すると、HDInsight で、ファイルを検索するときに相対的なファイル参照を確実に解決できるようになります。
ヒント
使用可能なストレージを増やす場合は、必要に応じて、追加のファイル システムのリンクとリンク解除を行うことができます。
処理のしくみ
データを処理するときに、HDInsight 上の Hadoop クラスターのコンピューティング コンポーネントが 2 つの論理領域に分割されます。 次の表は、この 2 つの領域について説明しています。
| コンポーネント | 説明 |
|---|---|
| ヘッド ノード | ヘッド ノードで、クライアント要求の受け入れと管理が行われ、ワーカー ノードに要求が渡されます。 |
| ワーカー ノード | ワーカー ノードで、データが処理されます。 |
注意
ヘッド ノードは、マスター ノードと呼ばれることもあります。
ほとんどのクラスターには、次の 2 つのヘッド ノードが含まれます。
- アクティブ ヘッド ノード。クライアント接続を管理します。
- パッシブ ヘッド ノード。アクティブ ノードがオフラインになった場合に回復力を提供します。
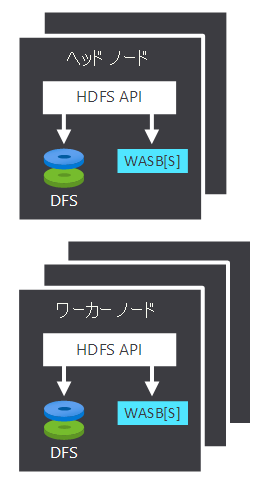
ヘッド ノードとワーカー ノードは両方とも、ローカルに接続された HDFS に直接接続することも、Azure BLOB または Azure Data Lake に格納されているデータにアクセスすることもできます。 何のデータが管理されるかは、次の 2 つの要因によって異なります。
- MapReduce プログラミング モデルで、データの扱い方がどのように定義されているか
- ヘッド ノードで、作業がどのように割り当てられているか
YARN とは
YARN によって、HDInsight クラスター内のリソース管理が実行されます。 データを処理するとき、このサービスを使用してリソースとジョブのスケジュールを管理します。
YARN は、HDFS と、HDInsight クラスターの計算システムの間にあります。 ヘッド ノードと連携して、クラスターのワーカー ノード全体にジョブを分散できます。 これにより、データ処理ジョブが並列に実行されるようにできます。