Azure Machine Learning のしくみ
Azure Machine Learning を使用するには、Azure アカウントと Azure サブスクリプションが必要です。 サブスクリプションには Standard と Free の価格レベルがあり、サービスにアクセスするためのエンドポイントとサブスクリプション キーが提供されます。
クラウドまたはローカル コンピューター上の Azure Machine Learning には、Python ソフトウェア開発キット (SDK)、REST API、コマンド ライン インターフェイス (CLI) 拡張機能を使用してアクセスできます。 ローコードまたはノーコードのオプションを選択した場合、Azure Machine Learning スタジオを使用して、機械学習モデルのトレーニングとデプロイを迅速に行うことができます。
Azure Machine Learning によって、ワークスペース内の ML ライフサイクルに必要なすべてのリソースが管理されます。 ワークスペースは複数のユーザーで共有でき、ノートブック、トレーニング クラスター、パイプラインで利用できるコンピューティング リソースなどを含めることができます。 また、ワークスペースは、データ ストアの論理コンテナーでも、モデルや、モデル ライフ サイクル内の他のもののリポジトリでもあります。
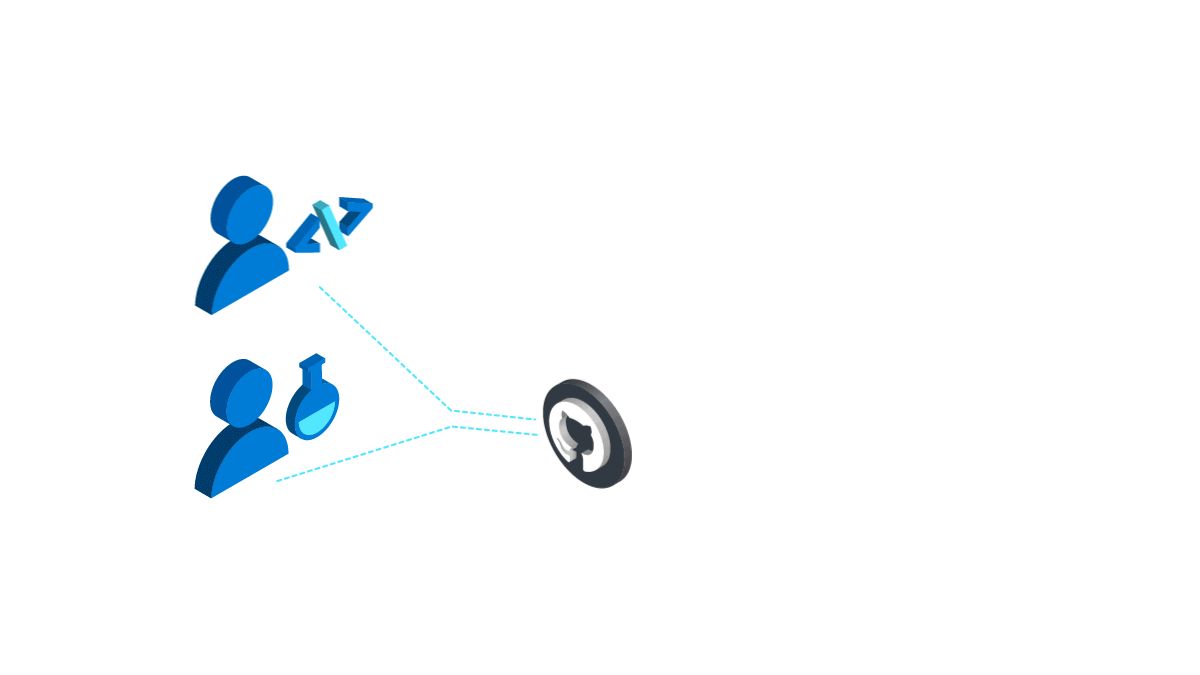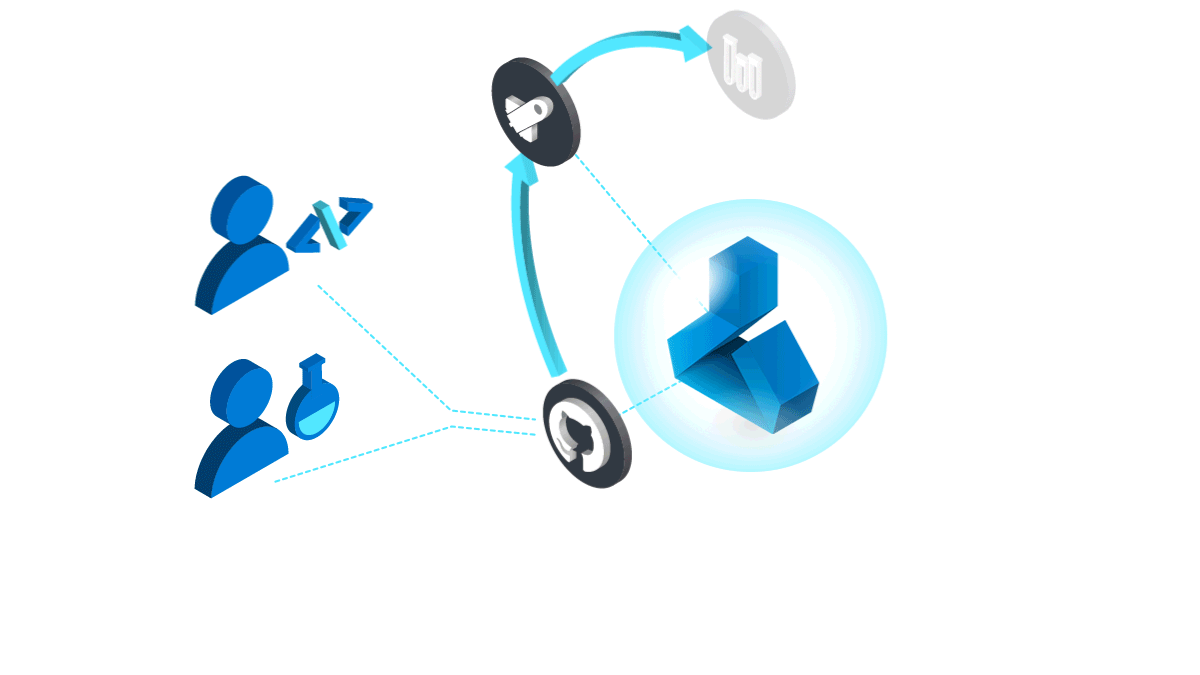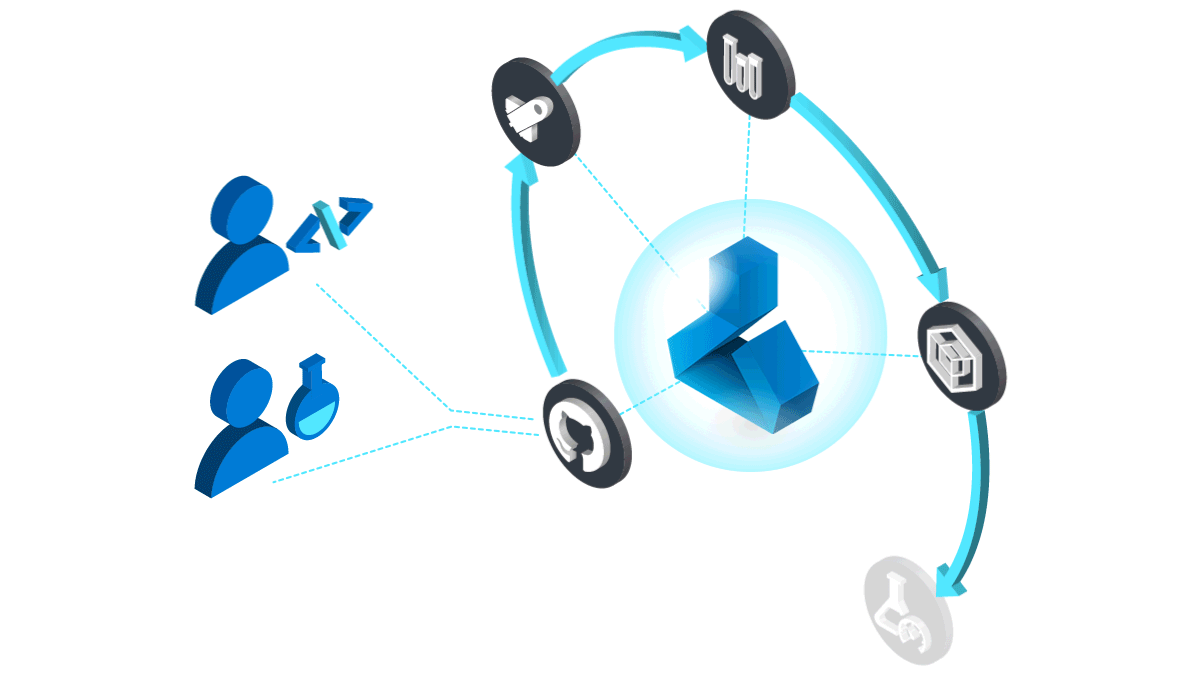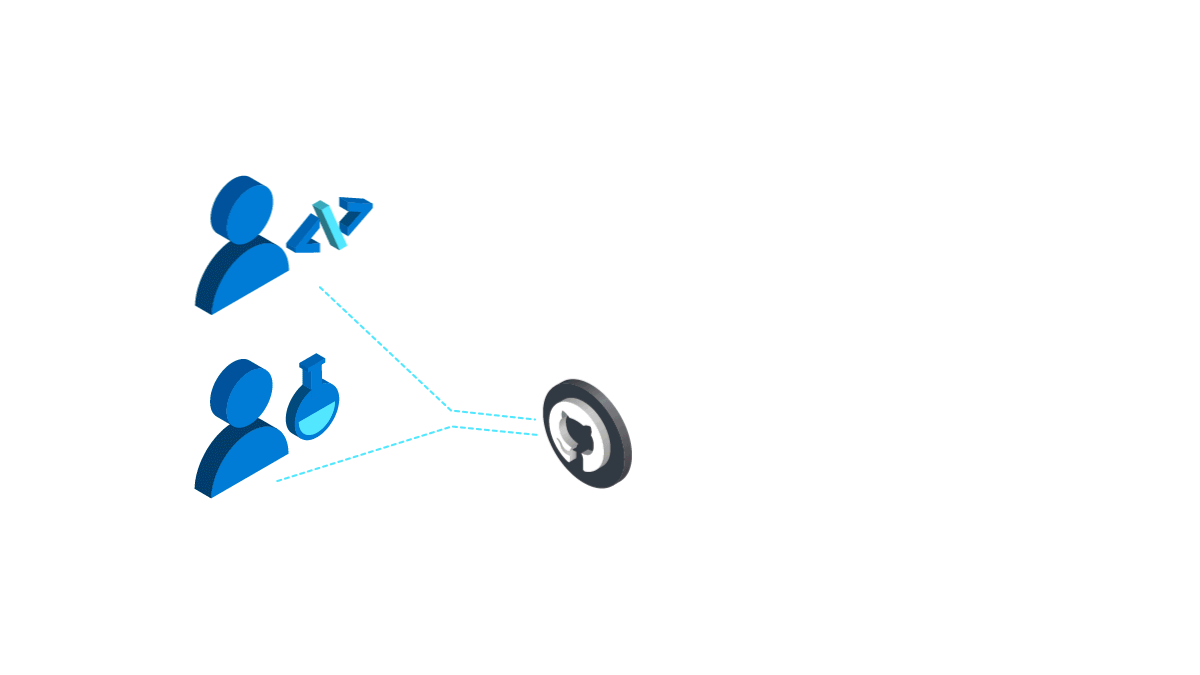
機械学習モデルを作成する方法
モデルは、SDK を使用して作成することも、ML フレームワークからインポートすることも、Azure Machine Learning スタジオを使用してコードなしで作成することもできます。 ワークスペースに接続すると、TensorFlow や PyTorch などの一般的なフレームワーク用に選別された環境を含んだパッケージが事前に読み込まれたさまざまな開発環境を選択できます。 続いてコンピューティング ターゲットを選択し、ローカルまたは仮想マシンでトレーニング スクリプトを実行して、モデルを作成することができます。 Azure Machine Learning 内のコンピューティング ターゲットでは、GPU と CPU のリソースを効率的に使用するようにジョブを自動的にスケールアップおよび管理できます。
実行の状態は、SDK、Azure Monitor、Azure Machine Learning スタジオからネイティブに、または MLFlow と TensorBoard を実行するパッケージをインストールすることで、ログして監視することができます。 続いて Azure スタジオまたはワークスペース内でトレーニングの実行を視覚的に表示して、結果やメトリックをドリルダウンすることができます。
次の例では、Azure Machine Learning スタジオの視覚エフェクトをカスタマイズして、グラフを追加し、データを比較し、フィルターを適用して結果とメトリックをより的確に分析する方法を確認できます。

実験
Azure Machine Learning でモデルをトレーニングするには、実験を実行します。これは、追跡対象のメトリックと出力を生成できるトレーニング スクリプトが実行されたときに行います。 別々のハイパーパラメーター、データ、コード、または設定を使用して、同じ実験を複数回実行できます。 ワークスペースには、環境内のスクリプトに関するログ、メトリック、出力、スナップショットなど、すべてのトレーニング実行の履歴が保持されます。 共同プロジェクトでは、実験ログは、進行状況を確認して追跡するための優れた方法です。 これらには、モデルを公開または変更しているユーザー、変更が行われた理由、モデルがいつ実稼働環境にデプロイされたか、または使用されたかを表示できます。
パイプライン
パイプラインとは、データの準備、トレーニング、テスト、デプロイを含めることのできる完全な機械学習タスクのワークフローです。 パイプラインには多くの用途があります。 モデルをトレーニングするパイプライン、リアルタイムで予測を行うパイプライン、またはデータをクリーンアップするだけのパイプラインを作成できます。 パイプライン内の各ステップは独立しているため、複数の人物が同時に同じパイプライン内の異なるステップを操作できます。 "Azure Machine Learning パイプライン" を使うと、入力が変更されたステップを再実行するだけなので時間を節約できます。ハイパーパラメーターやその他のステップを調整するだけであれば、ランタイムを大幅に短縮できます。 Azure Data Factory と Azure Pipelines のどちらにも、Azure Machine Learning のすぐに使用できるパイプラインが用意されているので、インフラストラクチャではなく機械学習に専念できます。
データ アセット
データ アセットは、データストア、パブリック URL、Azure Open Dataset から作成できます。 データ アセットを作成することにより、データ ソースの場所を参照します。これにより、元のデータを変更することなく、トレーニング セットとパイプラインのデータが保存されます。 その後、データ アセットの登録、バージョン管理、追跡、トレースを行って、チーム、ロール、実験間での再利用と共有を迅速に実現することができます。 また、再現可能な実験のバージョン管理も可能であるため、データの実行可能性とモデルのパフォーマンスをより適切に分析できます。
Azure Machine Learning では、増分更新を使用して新たに格納されたデータを定期的に確認できるので、新しいデータがデータストアに追加されたときにデータ アセットを自動的に更新できます。 T
ラベル付け
"データのラベル付け" は、ラベル付けタスクを作成、管理、監視するための一元的な場所です。 すべてのデータ ラベル付けプロジェクトは、Azure Machine Learning スタジオまたはワークスペース ダッシュボードから管理できます。そこでは、チーム メンバーが進行状況を確認し、共同のラベル付けプロジェクトに協力できます。 ここでは、人間参加型ラベル付けを行うことができ、チーム メンバーは手動でタグを追加して ML ラベル付けモデルをトレーニングできます。 十分な数のラベルが送信されると、分類モデルを使用してタグが予測されます。 チーム メンバーは、ML でタグ付けされたデータのインスタンスを承諾または拒否することで、ラベル付けモデルの精度をトレーニングできます。 最終的には、モデルは支援なしでデータにラベル付けできるようになります。
次に、Azure Machine Learning スタジオで進行中のラベル付けタスクの例を示します。

機械学習モデルのデプロイ
Azure Machine Learning では、デプロイ用の Docker コンテナーでモデルをパッケージ化して実行できます。 これらのコンテナーは実行スクリプトとは別のものであるため、スクリプトを変更せずに、改善されたモデルにすばやく交換または更新できます。
また、Open Neural Network Exchange (ONNX) 形式でモデルをダウンロードすることもできます。この形式により、iOS、Android、Linux など、可能性のあるデプロイ プラットフォームおよびデバイスで高い柔軟性がもたらされます。
Azure Machine Learning には、Python のパッケージや設定が事前に読み込まれた安定した環境を含む、事前パッケージ化されたコンテナー イメージが用意されています。 これらのコンテナー イメージは、TensorFlow や PyTorch などの一般的な機械学習フレームワークへのデプロイを最小限の設定で行うのに役立ちます。